1. 一句话理解 Flink 的部署:一套"积木",多种"拼法"
无论你用哪种部署方式,Flink 集群里永远绕不开三个核心角色:
- Client:把作业编译成 JobGraph 并提交
- JobManager:负责调度与协调(集群大脑)
- TaskManager:真正执行算子的工作节点(干活的人)
可以把它理解成:
- Client 负责"把你写的代码变成一张可执行的图,然后交给集群"
- JobManager 负责"把图拆成任务、分配资源、处理容错和恢复"
- TaskManager 负责"真正跑 Source / Transform / Sink 等算子"
2. 参考架构:Flink 集群的最小闭环
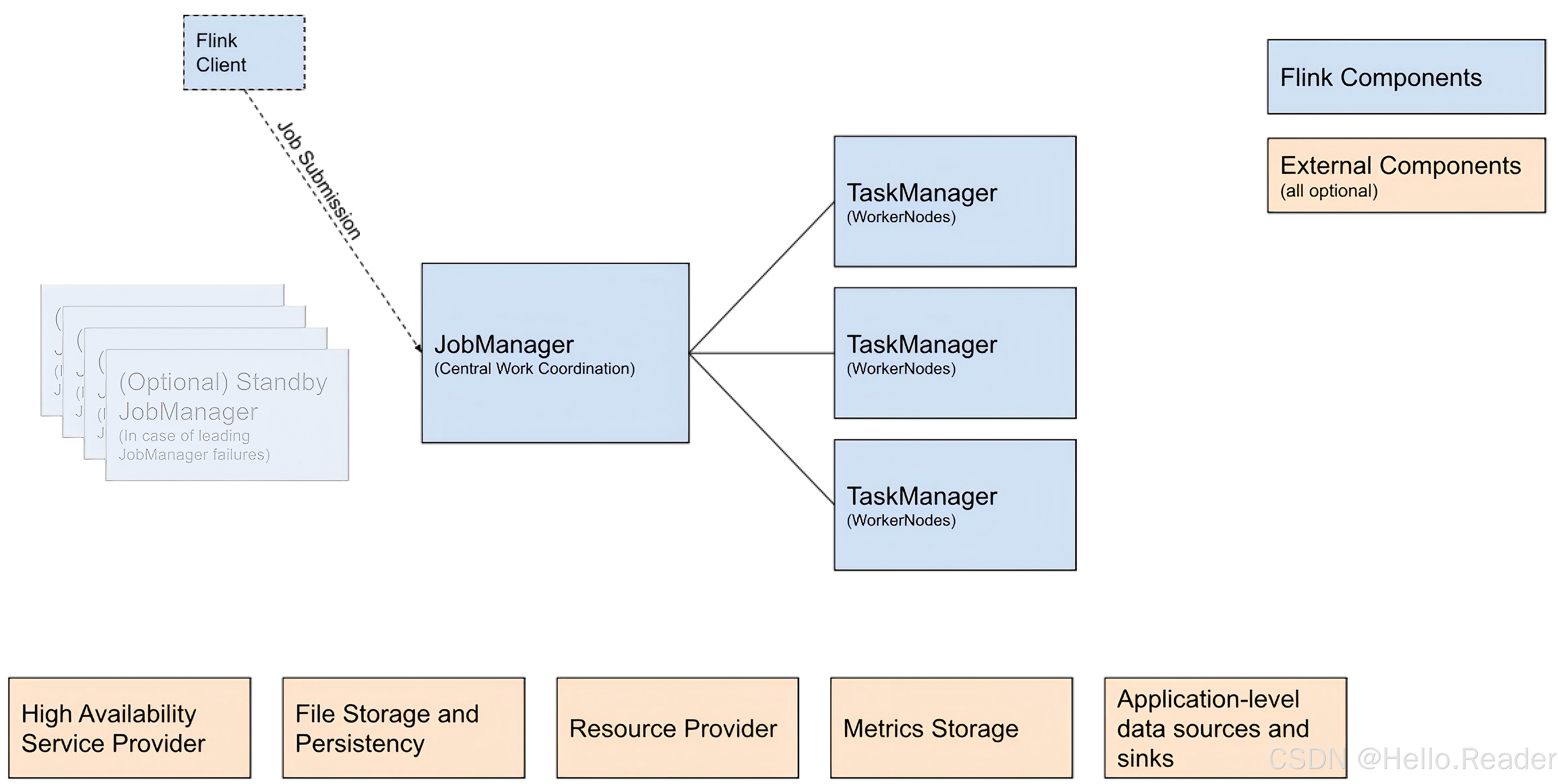
核心要点:Client 永远存在(只是可能在你本机,也可能在集群端),JobManager 是"协调者",TaskManager 是"执行者"。
3. 组件拆解:部署时你真正要选的是哪些"实现"
下面把部署文档里的 building blocks 用"职责-实现"的方式梳理一遍。
3.1 Client:你用什么方式提交作业?
常见实现包括:
- Command Line Interface(CLI)
- REST Endpoint
- SQL Client
- Python REPL
工程实践上:开发阶段 SQL Client 非常高效;生产阶段通常通过 CI/CD + CLI/REST 提交,或者平台化系统调用 REST。
3.2 JobManager:核心差异在"运行模式 + 资源提供方 + HA"
JobManager 的实现与运行环境强相关,常见的资源提供方/部署环境:
- Standalone(纯 JVM 进程方式,最"裸")
- Kubernetes
- YARN
而 JobManager 还涉及"作业提交模式":Application Mode 与 Session Mode(下面会重点讲)。
3.3 TaskManager:算子都跑在这里
TaskManager 是干活的 JVM 进程(或 Pod/Container)。你的并行度、资源隔离、反压、吞吐,很多都最终落在 TaskManager 的资源与调度上。
3.4 外部组件(可选但生产必备)
高可用(High Availability Service Provider)
用于 JobManager 故障时更快 failover,多 JM standby 做备份。常见实现:
- Zookeeper
- Kubernetes HA
Checkpoint / 状态持久化(File Storage and Persistency)
流作业容错的关键:Checkpoint 需要外部文件系统持久化(例如 S3/HDFS/对象存储等,具体看你所用 FileSystem 支持)。
Metrics 存储
Flink 会报内部指标,你的作业也可以报自定义指标。生产必配,否则排障像盲人摸象。
应用级外部数据源/下游
Kafka、S3、Elasticsearch、Cassandra 等不属于 Flink 集群组件,但对性能影响巨大。一个非常实际的经验是:数据与计算尽量靠近部署(网络路径短、抖动小),性能和稳定性都会更好。
4. Repeatable Resource Cleanup:作业结束后资源清理的"可重试机制"
当一个作业进入终态(finished/failed/cancelled),Flink 会清理与作业相关的外部资源;如果清理失败,会按配置重试,直到成功或达到最大重试次数。达到上限仍失败,会留下"脏状态",需要人工清理。重新用同一个 JobID 启动作业,会继续触发清理流程而不是立刻重新跑。
文档里还点名了一个已知问题:完成的 Checkpoint 在 subsume 时删除失败的场景,当前不在 repeatable cleanup 覆盖范围内,需要手工删,对应 FLINK-26606。
工程含义很明确:生产上一定要把 checkpoint 目录、权限、对象存储一致性策略、清理重试策略配置好,否则会留下大量历史 checkpoint 占满存储。
5. Deployment Modes:Application Mode vs Session Mode,怎么选?
Flink 支持两种执行应用的模式:
- Application Mode
- Session Mode
它们的核心差异在三点:
- 集群生命周期与资源隔离
- main() 方法在客户端执行还是在集群端执行
- 多作业/多提交的行为差异与限制
5.1 Application Mode:每个应用一个"专属集群",main() 在 JobManager 上执行
Application Mode 的思路是:集群只服务一个应用(application granularity 的隔离),而且 main() 方法由 JobManager 执行。这样带来几个直接收益:
- 资源隔离更强:一个应用一套集群资源
- 部署/恢复更快:不需要像传统模式那样通过 RPC 分发 user jars(前提是 user jars 已经在 Flink 分发包的 classpath/usrlib 上)
- Client 不再是重资源节点:下载依赖、构图、发包的压力由集群承担
但也有关键约束:
- 你的应用 jar 需要"随 Flink 分发包一起"放到所有组件可见的 classpath/usrlib
- registerCachedFile() 之类注册的路径要对 JobManager 可访问
- 支持 multi-execute()(多次 execute/executeAsync),但 High Availability 仅支持 single-execute() 的场景
- executeAsync() 多作业并行时,只要其中一个作业被 cancel,会导致所有作业停止并关闭 JobManager
一句话:Application Mode 更像"作业级隔离 + 平台化交付"的主力模式,但你要接受它对作业打包/分发与运行行为的约束。
5.2 Session Mode:共享集群,多作业共用资源,main() 在客户端执行
Session Mode 假设集群已启动,多个作业共享同一套 TaskManager 资源:
优点:
- 不需要为每个作业拉起一套新集群,资源开销低
- 提交快,适合多团队共享与交互式场景(例如 SQL 平台)
风险与代价:
- 资源争抢:作业之间互相影响
- 故障影响面大:某个作业把 TaskManager 搞挂,跑在同一个 TM 上的所有作业都受影响
- 恢复风暴:集群里多个作业同时恢复时,会一起狂读 checkpoint 文件系统,可能拖垮外部存储
- JobManager 负载更大:要管理更多作业与状态
一句话:Session Mode 适合多租共享、平台化 SQL、开发测试或成本敏感场景,但生产上要非常重视隔离与限流,否则容易出现"一个作业拖垮全场"。
6. 选型指南:你到底该用哪种模式?
给你一个很实用的决策表:
- 你希望"作业之间强隔离",并且能接受把应用 jar 随 Flink 分发、平台化交付:选 Application Mode
- 你有一个共享集群,很多作业要频繁提交/停止/调试(尤其 SQL 场景):选 Session Mode
- 你担心单作业异常带来集群级事故:优先 Application Mode
- 你对资源利用率极致敏感、作业数量多且都很"乖":Session Mode 更省
如果你是生产核心链路(实时数仓、风控、核心指标)且 SLA 高,默认建议 Application Mode;如果你是"统一 SQL 平台"或"开发自助查询",Session Mode 更自然。
7. 生产落地 Checklist:从"能跑"到"能稳"
按上线顺序给一个清单,你照着过一遍,基本能避开 80% 的坑。
7.1 集群与模式
- 明确:Application 还是 Session
- 明确:资源提供方(Standalone / K8s / YARN)
- 明确:是否需要多租户与隔离策略(队列、命名空间、配额)
7.2 HA 与元数据
- 是否启用 HA(Zookeeper 或 K8s HA)
- standby JobManager 数量与 failover 目标时间
- JobResultStore / 清理策略(避免 dirty artifacts)
7.3 Checkpoint 与状态
- 外部存储选型(HDFS/S3/对象存储)
- checkpoint 目录权限、生命周期、清理重试策略
- 关注 CompletedCheckpoint 清理异常的运维预案(尤其提到的 FLINK-26606 风险)
7.4 Metrics 与可观测
- Metrics reporter 接入(Prometheus/Influx/Graphite 等)
- 关键指标面板:吞吐、反压、checkpoint 时长、失败率、重启次数、TM/JM 资源
7.5 外部系统(数据源/下游)
- Kafka/S3/ES/Hive/HBase 等与 Flink 的网络拓扑尽量就近
- 外部系统容量与限流要评估(尤其 Session Mode 下更容易出现"恢复风暴")
- 关键链路要做压测与故障演练(网络抖动、对象存储慢、ZK 抖动)
8. 小结
Flink 部署选型的本质不是"我用 K8s 还是 YARN",而是你要在以下维度做权衡:
- 资源隔离 vs 资源复用
- 故障影响面 vs 运维复杂度
- 提交体验(交互式)vs 平台化交付
- 恢复速度与外部系统压力
Application Mode 把隔离做到应用粒度,适合生产关键链路;Session Mode 把共享做到极致,适合平台化与交互式场景,但要强管控、强观测。