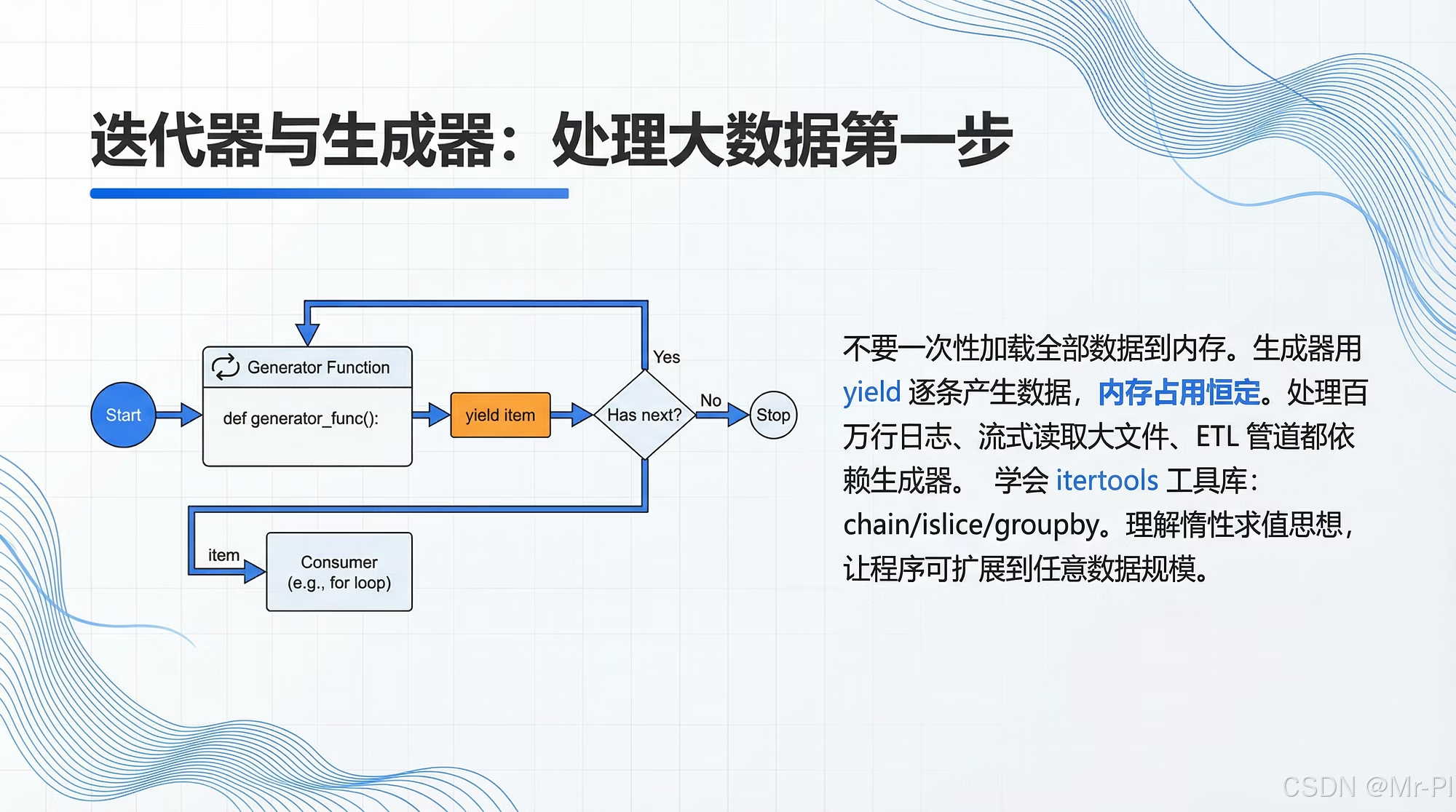
第十六章 迭代器与生成器:处理大数据的第一步
-
- [0. 本章目标与适用场景](#0. 本章目标与适用场景)
- [1. 先把三个概念说清:Iterable / Iterator / Generator](#1. 先把三个概念说清:Iterable / Iterator / Generator)
-
- [1.1 可迭代对象(Iterable)](#1.1 可迭代对象(Iterable))
- [1.2 迭代器(Iterator)](#1.2 迭代器(Iterator))
- [1.3 生成器(Generator)](#1.3 生成器(Generator))
- [2. 为什么生成器是处理大数据的第一步?](#2. 为什么生成器是处理大数据的第一步?)
- [3. 先看一个"典型翻车"与"工程修复"](#3. 先看一个“典型翻车”与“工程修复”)
-
- [3.1 翻车写法:全量读入](#3.1 翻车写法:全量读入)
- [3.2 修复写法:文件本身就是迭代器](#3.2 修复写法:文件本身就是迭代器)
- [4. 生成器的三种常用写法(工程里最常见)](#4. 生成器的三种常用写法(工程里最常见))
-
- [4.1 生成器函数:可读性最好](#4.1 生成器函数:可读性最好)
- [4.2 生成器表达式:一行写完](#4.2 生成器表达式:一行写完)
- [4.3 `yield from`:把生成器拆模块](#4.3
yield from:把生成器拆模块)
- [5. 用 Mermaid 把"流式 pipeline"结构画出来](#5. 用 Mermaid 把“流式 pipeline”结构画出来)
- [6. 写一个可复用的"清洗-过滤-映射"链路](#6. 写一个可复用的“清洗-过滤-映射”链路)
-
- [6.1 解析层:只负责"吐干净对象"](#6.1 解析层:只负责“吐干净对象”)
- [6.2 过滤层:只负责"保留需要的样本"](#6.2 过滤层:只负责“保留需要的样本”)
- [6.3 映射层:只负责"变换结构"](#6.3 映射层:只负责“变换结构”)
- [7. 批处理:把"逐条"变成"按批",喂给模型更现实](#7. 批处理:把“逐条”变成“按批”,喂给模型更现实)
- [8. itertools:别重复造轮子,但要会用](#8. itertools:别重复造轮子,但要会用)
-
- [8.1 `islice`:只取前 N 条做抽样调试](#8.1
islice:只取前 N 条做抽样调试) - [8.2 `chain`:拼接多个流](#8.2
chain:拼接多个流) - [8.3 `groupby`:按 key 分组(注意必须先排序)](#8.3
groupby:按 key 分组(注意必须先排序))
- [8.1 `islice`:只取前 N 条做抽样调试](#8.1
- [9. 常见坑:生成器"只能消费一次"](#9. 常见坑:生成器“只能消费一次”)
- [10. 何时不该用生成器?两条红线](#10. 何时不该用生成器?两条红线)
- [11. 一个"可交付"的大数据处理模板(你可以直接复用)](#11. 一个“可交付”的大数据处理模板(你可以直接复用))
- [12. 小结](#12. 小结)
- 下一章
你有没有写过这种代码:
pd.read_csv()一把梭,文件 8GB,直接把内存打爆。- 把日志全读进 list 再处理,处理到一半机器开始交换分区,速度断崖式下跌。
- 训练前做预处理,先把所有样本算完再喂模型,结果"等一天还没开始训练"。
这些问题的共同点不是"算法不够高级",而是:数据量一大,你还在用"把所有东西一次性装进内存"的思路。
这一章,我们用迭代器与生成器,帮你完成一次关键的思维升级:
从"批量一次性处理" → 到 "流式逐条处理(streaming)"。
这是你从脚本写手走向数据/AI工程师的第一步。
0. 本章目标与适用场景
学完你应该能做到:
- 解释清楚:可迭代对象、迭代器、生成器分别是什么
- 用生成器把"全量加载"改成"流式处理"
- 用
yield写出可组合的数据处理 pipeline - 理解惰性计算(lazy evaluation)与内存占用的关系
- 掌握常用工具:
itertools、生成器表达式、yield from - 在数据/AI任务里落地:大文件读取、日志清洗、批量推理、训练数据喂入
1. 先把三个概念说清:Iterable / Iterator / Generator
1.1 可迭代对象(Iterable)
你能对它写:
python
for x in obj:
...它就叫 Iterable,比如:list、dict、set、str、文件对象、pandas 的某些结果等。
形式化一点:实现了 __iter__() 的对象就是 iterable。
1.2 迭代器(Iterator)
迭代器是"真正负责一个个吐元素"的东西,它必须同时满足:
- 有
__iter__() - 有
__next__()
你可以手动取:
python
it = iter([1, 2, 3])
next(it) # 1
next(it) # 2当耗尽时会抛 StopIteration。
1.3 生成器(Generator)
生成器是"写起来像函数,运行起来像迭代器"的结构。
核心关键字:yield
python
def gen():
yield 1
yield 2gen() 返回的不是结果,而是一个可迭代的生成器对象。
2. 为什么生成器是处理大数据的第一步?
因为它把"内存模型"从:
- 先把所有数据装进内存再处理
变成:
- 每次只处理一条(或一小批),处理完就丢掉
可以用一个抽象式理解:
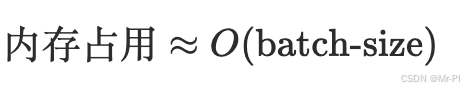
而不是:
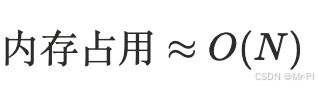
当 N 很大时,这就是生死线。
3. 先看一个"典型翻车"与"工程修复"
3.1 翻车写法:全量读入
python
with open("big.log", "r", encoding="utf-8") as f:
lines = f.readlines() # 内存爆点
for line in lines:
handle(line)3.2 修复写法:文件本身就是迭代器
python
with open("big.log", "r", encoding="utf-8") as f:
for line in f: # 流式
handle(line)很多人以为这是"语法差异",其实是内存模型差异。
4. 生成器的三种常用写法(工程里最常见)
4.1 生成器函数:可读性最好
python
def read_lines(path: str):
with open(path, "r", encoding="utf-8") as f:
for line in f:
yield line.rstrip("\n")4.2 生成器表达式:一行写完
python
lines = (line.rstrip("\n") for line in open(path, encoding="utf-8"))适合短逻辑,但不适合复杂异常处理(工程里别滥用)。
4.3 yield from:把生成器拆模块
python
def read_files(paths):
for p in paths:
yield from read_lines(p)你会发现 pipeline 可以像搭积木一样组合起来。
5. 用 Mermaid 把"流式 pipeline"结构画出来
你现在处理大数据的正确姿势通常是:
数据源
文件/DB/API
读取器
iterator
清洗器
yield 过滤/解析
特征/转换
yield 映射
批处理
batcher
下游
模型推理/写库/统计
核心思想:每一层都不要返回"大列表",而是返回"可迭代流"。
6. 写一个可复用的"清洗-过滤-映射"链路
假设你要处理日志:每行 JSON,偶尔有脏行。
6.1 解析层:只负责"吐干净对象"
python
import json
from typing import Iterator, Optional, Dict, Any
def parse_json_lines(path: str) -> Iterator[Dict[str, Any]]:
with open(path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
try:
yield json.loads(line)
except json.JSONDecodeError:
# 工程策略:跳过脏行,或者计数上报
continue6.2 过滤层:只负责"保留需要的样本"
python
def filter_events(rows: Iterator[dict], *, event: str) -> Iterator[dict]:
for r in rows:
if r.get("event") == event:
yield r6.3 映射层:只负责"变换结构"
python
def to_features(rows: Iterator[dict]) -> Iterator[tuple]:
for r in rows:
yield (r.get("user_id"), r.get("item_id"), r.get("ts"))组合起来:
python
rows = parse_json_lines("big.log")
rows = filter_events(rows, event="click")
features = to_features(rows)
for feat in features:
consume(feat)这类分层是"可维护"的关键:每层都可单测、可替换、可观测。
7. 批处理:把"逐条"变成"按批",喂给模型更现实
模型推理通常按 batch 更快。我们写一个通用 batcher:
python
from typing import Iterable, Iterator, List, TypeVar
T = TypeVar("T")
def batcher(it: Iterable[T], batch_size: int) -> Iterator[List[T]]:
batch: List[T] = []
for x in it:
batch.append(x)
if len(batch) >= batch_size:
yield batch
batch = []
if batch:
yield batch应用:批量推理
python
for batch in batcher(features, batch_size=256):
preds = model_infer(batch)
write_out(preds)工程直觉:
- 上游生成器负责省内存
- batcher 负责利用吞吐
- 下游负责落库或统计
8. itertools:别重复造轮子,但要会用
8.1 islice:只取前 N 条做抽样调试
python
from itertools import islice
sample = list(islice(features, 10))8.2 chain:拼接多个流
python
from itertools import chain
all_rows = chain(parse_json_lines("a.log"), parse_json_lines("b.log"))8.3 groupby:按 key 分组(注意必须先排序)
python
from itertools import groupby
rows = sorted(rows, key=lambda r: r["user_id"])
for uid, grp in groupby(rows, key=lambda r: r["user_id"]):
...工程提醒:groupby 常被误用。不排序就 group,会得到碎片组。
9. 常见坑:生成器"只能消费一次"
这是最容易踩的坑之一:
python
g = (x for x in range(3))
list(g) # [0,1,2]
list(g) # [] 已耗尽工程建议:
- 若你需要"多次遍历",就把数据落地(list/文件/缓存)。
- 若你只需要"单次管道",生成器是最佳选择。
10. 何时不该用生成器?两条红线
-
你需要随机访问 (比如反复取第 i 个元素)
生成器不适合,应该落地为 list/数组/索引结构。
-
你需要多次复用同一批数据 (训练/评测多轮)
用生成器读取"源数据",但中间结果通常要落盘或缓存,不要每轮重新算一遍。
11. 一个"可交付"的大数据处理模板(你可以直接复用)
read_source()
parse/clean
validate/schema check
transform/features
batcher
infer/train
write sink + metrics
建议你每个节点都留一个"观测点":
- 计数:输入多少、跳过多少、输出多少
- 错误:解析失败、字段缺失、类型漂移
- 性能:吞吐、耗时、峰值内存
12. 小结
迭代器与生成器的核心价值不在语法,而在工程能力:
- 让你从"全量读入"升级到"流式处理"
- 让数据链路可组合、可维护、可扩展
- 让你的程序在数据规模上具备真正的弹性
你从这一章开始,就已经在做"面向大数据的工程设计"了。
你现在最痛的是哪类"数据太大"的场景?
- 本地大 CSV/日志处理内存爆
- 批量推理太慢,想做流式 + batch
- 训练数据管道需要可复用的 iterator 接口
- 从数据库/消息队列读取需要 backpressure 思路
下一章
《第十七章 常见算法套路:排序/查找/滑窗/计数(够用即可)》