文章目录
-
- 1.大模型基石Transformer架构
-
- [1.Transformer模型工作流程-Step 1](#1.Transformer模型工作流程-Step 1)
- [2.Transformer模型工作流程-Step 2](#2.Transformer模型工作流程-Step 2)
- [3.Transformer工作流程-Step 3](#3.Transformer工作流程-Step 3)
- 4.Transformer模型结构
- 2.通用大模型和金融大模型介绍
- 3.总结与思考
1.大模型基石Transformer架构
翻译背景
- 原始语句 杰瑞将要访问中国
- 机器翻译 Jerry visits China
- 优秀翻译
- Jerry is going to visit China
- Jerry will visit China
翻译模型早期架构
- decoder 将Jerry will visit China每个单词转换成语义向量然后交由神经网络处理最后交由decoder进行解码
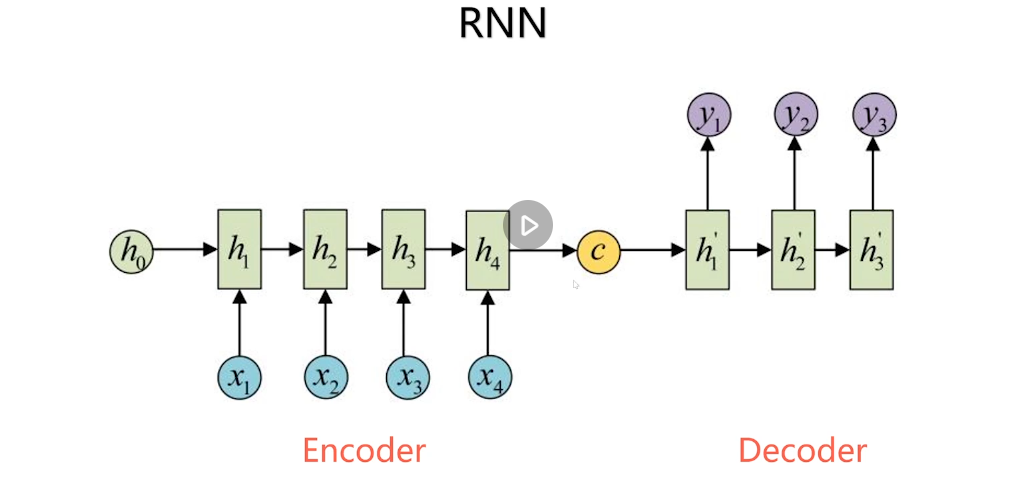
RNN-Seq2Seq(sequence to sequence )
- c:固定长度的语向量
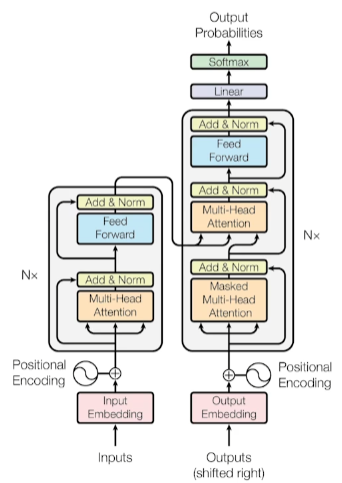
Transformer
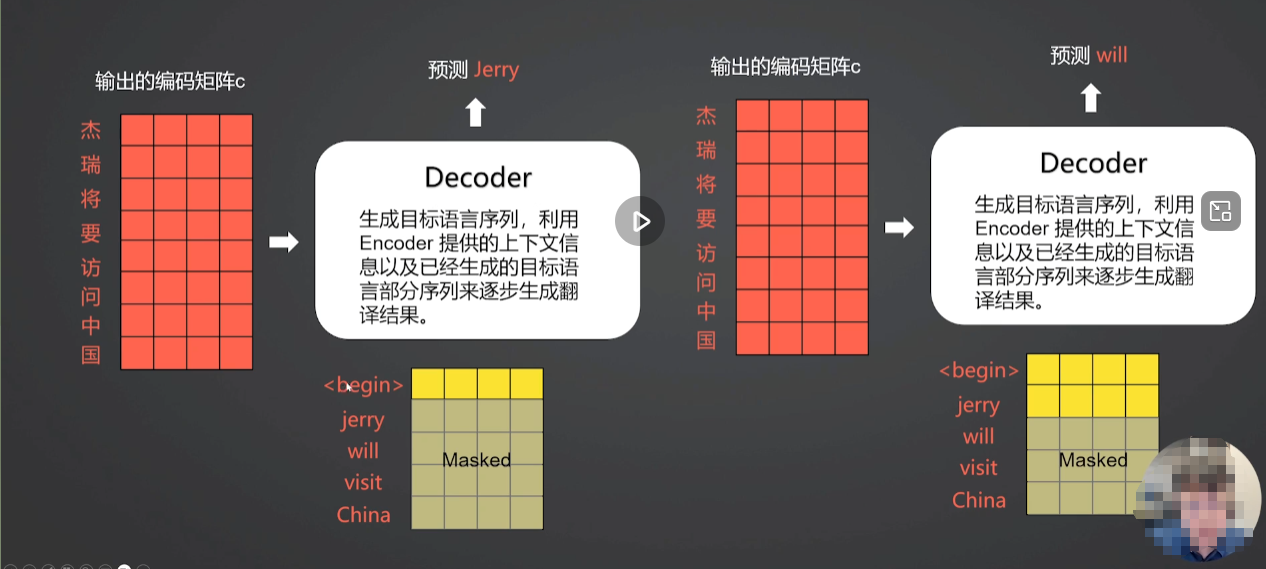
Encoder:对输入的源语言序列进行编码,提取其语义信息
Decoder:生成目标语言序列,利用Encoder提供的上下文信息以及已经生成的目标语言部分序列来逐步生成翻译结果。
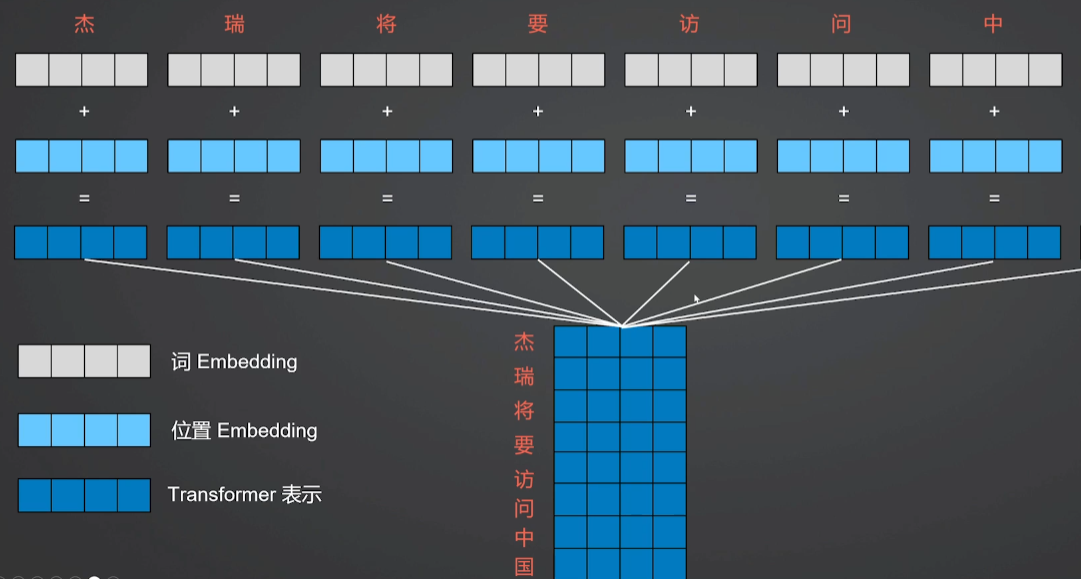
1.Transformer模型工作流程-Step 1
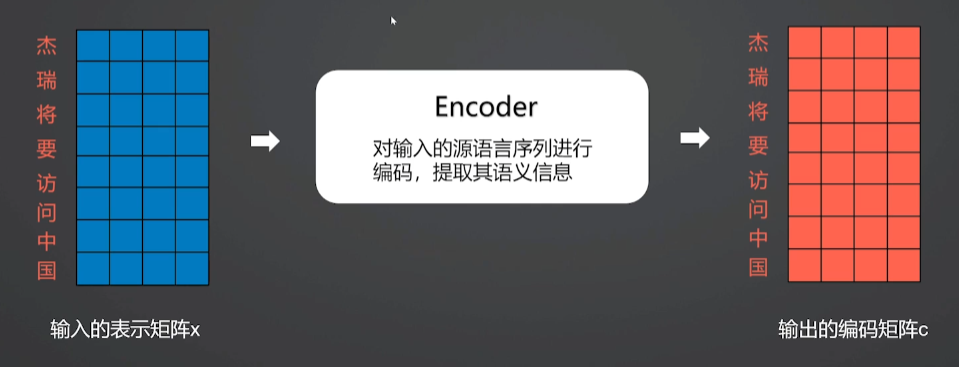
2.Transformer模型工作流程-Step 2
将第一步得到的单词表示向量矩阵传入Encoder,经过Encoder后可以得到句子所有单词的编码信息矩阵c(attention自注意力机制)
3.Transformer工作流程-Step 3
4.Transformer模型结构
-
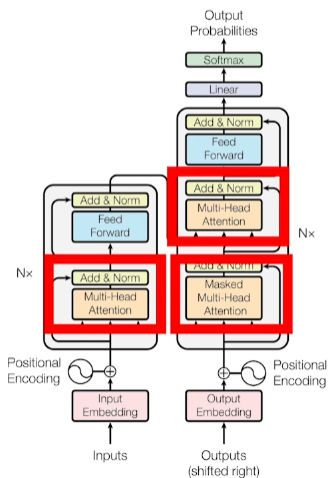
Encoder包含一个Multi-Head Attention
-
Decoder包含两个Multi-Head Attention,其中一个用到Masked
-
Multi-Head Attention上方还包含一个Add & Norm层
-
Add表示残差连接,用于防止网络退化
-
Norm表示Layer Normalization, 用于对每一层的激活值进行归一化
-
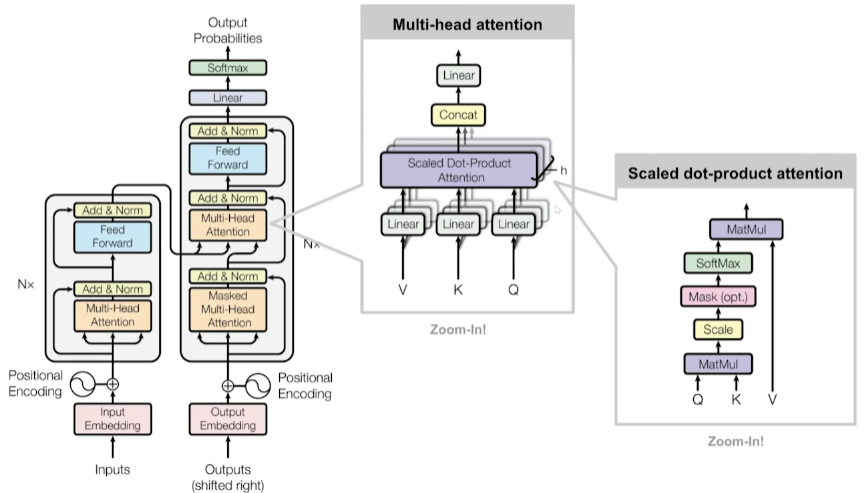
一个Multi-Head Attention由多个Self-Attention组成
Transformer模型结构-Self-Attention
- Self-Attention机制帮助模型对输入序列中的不同位置建立关联
- Multi-Head Attention多头注意力机制允许模型同时关注不同位置的信息。
Transformer-优点
- 放弃RNN循环层,摒弃RNN隐状态。
- 解决RNN长距离依赖,完全使用注意力机制捕捉输入和输出之间的关系。
- 显著提高并行化和速度
2.通用大模型和金融大模型介绍
1.通用大模型代表-GPT
- GPT-1 2018·1.17亿参数·Transformer模型首次应用
- GPT-2 2019·15亿参数·文本能力显著提高
- GPT-3 2020·1750亿参数·执行复杂任务·代码编写·多轮对话
- GPT-4 2023·1.8万亿参数·支持多模态-文本和图像·进一步提升理解和生成能力
2.开源大模型代表-LLaMA
- LLaMA1 2023年2月 7B-65B, 在小模型上表现优异
- LLaMA2 2023年7月 训练数据增加40% ,可供商业使用
- LLaMA3 2024年4月 80亿-4050亿参数 性能接近与GPT-4 ,推理、编程代码生成和指令执行方面进行显著优化
- LLaMA3.1
2024年7月
多语言支持,上下文窗口提升
·
3.国产开源大模型代表-DeepSeek
- DeepSeek LLM 2024年1月 包含670亿参数,从零开始在2万亿,token上进行训练
- DeepSeekV2 2024年5月 采用Mixture-of-Experts (MoE)架构,实现了显著的性能提升
- DeepSeekV3 2024年12月 显著提升了知识类任务和生成速度
- DeepSeekR1 2025年1月 采用强化学习技术提升模型推理能力
4.金融大模型-FinGPT
FINGPT
https://github.com/AI4Finance-Foundation/FinGPT
金融数据高度动态变化,FinGPT使用微调技术低成本纳入新数据
使用RLHF人类强化学习技术学习个人偏好(风险规避水平,投资习惯,个性化机器人顾问)
- FinGPT V1 2023年6月 基于ChatGLM2,Finetuning LoRA
- FinGPT V3.2 2023年10月 基于LLama2-7b
- FinGPT V3.3 2023年10月 基于LLama2-13b
3.总结与思考
- CNN和RNN在翻译场景上存在什么问题?
- Transformer的核心组件有哪一些?
- 为何Transformer能解决长距离的问题?
- Transformer为何能加速模型训练?