目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
** 选题指导:**
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的银行卡号图像识别模型算法研究
选题背景意义
银行卡作为现代金融体系的重要组成部分,其卡号识别技术在移动支付、金融服务等领域具有广泛应用需求。随着移动互联网的快速发展,用户通过手机拍摄银行卡照片进行信息录入的场景日益增多,传统的手动输入方式不仅效率低下,还容易出现输入错误,影响用户体验和金融交易安全性。因此,开发高效、准确的银行卡号自动识别系统具有重要的现实意义。深度学习技术的兴起为图像识别领域带来了革命性的变化。卷积神经网络在图像特征提取方面展现出强大能力,循环神经网络和注意力机制在序列识别任务中取得了显著成果。这些技术的发展为银行卡号识别提供了新的解决方案,能够有效应对复杂背景、光照变化、卡片形变等实际应用中常见的挑战。相比传统的模板匹配、特征提取等方法,基于深度学习的识别算法具有更高的准确率和更好的泛化能力。

研究将围绕银行卡号图像识别展开,首先分析现有文本检测和识别算法的不足,然后针对银行卡号识别的特点进行算法改进。在检测阶段,使用改进的EAST算法,通过引入ASPP模块扩大感受野,提高字符区域定位的准确性;在识别阶段,改进ASTER网络,结合CTC和注意力机制的解码方式,提升字符识别的精度和鲁棒性。研究将构建包含多种场景的银行卡号图像数据集,设计完整的识别流程,实现从图像输入到卡号输出的端到端处理。通过实验验证改进算法的有效性,为实际应用提供技术支持。
数据集构建
数据获取
银行卡号图像数据集的构建需要考虑数据的多样性和真实性,以确保训练出的模型具有良好的泛化能力。数据获取将采用多种方式相结合的方法,首先通过实际拍摄真实银行卡来获取原始图像数据。拍摄过程中将使用不同型号的智能手机,在不同光照条件下(如室内自然光、弱光、强光等)、不同角度(如正面、倾斜、旋转等)、不同背景(如桌面、背包、钱包等)进行拍摄,以模拟实际应用中的各种场景。除了实际拍摄外,还将收集公开的银行卡号图像数据集,如ICDAR等国际文本检测与识别竞赛中的相关数据集。这些公开数据集通常包含经过专业标注的图像数据,能够为模型训练提供高质量的样本。同时,还可以通过数据增强技术生成更多的训练样本,如随机裁剪、旋转、缩放、亮度调整、对比度调整等,以扩大数据集规模,提高模型的鲁棒性。
为了确保数据的多样性,将收集不同类型的银行卡图像,包括借记卡、信用卡、储蓄卡等,涵盖不同银行、不同卡面设计的卡片。同时,还将考虑卡片的新旧程度,包括全新卡片、有磨损的卡片、有污渍的卡片等,以模拟实际应用中可能遇到的各种情况。通过这些方式,将构建一个包含多种场景、多种类型、多种状态的银行卡号图像数据集,为后续的模型训练和测试提供可靠的数据支持。
数据格式与类别
收集到的原始图像数据将统一转换为JPEG格式,以保证数据的一致性和兼容性。图像分辨率将根据实际应用场景进行设置,考虑到移动设备拍摄的图像分辨率通常较高,将统一调整为512×512像素的尺寸,既能够保留足够的图像细节,又不会增加模型训练的计算负担。根据银行卡号的特点,将数据分为不同类别进行管理。首先按照卡片类型进行分类,包括借记卡、信用卡、储蓄卡等;然后按照卡号长度进行分类,如16位卡号、17位卡号、19位卡号等;还可以按照卡号的字体类型进行分类,如宋体、黑体、等线体等。这些分类信息将作为元数据存储在数据集中,便于后续的数据分析和模型训练。
每个图像样本将包含图像文件和对应的标注文件。标注文件将采用JSON格式,包含图像的基本信息(如文件名、尺寸、类别等)和卡号的详细信息(如字符内容、字符位置、字符大小等)。这种格式便于计算机程序读取和处理,能够提高数据处理的效率和准确性。同时,标注文件的结构将设计得尽可能简洁明了,便于人工检查和修改。
数据标注
数据标注是构建高质量数据集的关键步骤,直接影响模型的训练效果。标注工作将分为两个主要阶段:字符区域定位标注和字符内容识别标注。字符区域定位标注需要标注出银行卡号中每个字符的外接矩形或四边形坐标,以确定字符在图像中的位置;字符内容识别标注需要标注出每个字符的具体内容,如数字、字母等。
标注工作将采用专业的图像标注工具进行,如LabelImg、VGG Image Annotator等。这些工具提供了直观的图形界面,能够提高标注效率和准确性。标注过程中,将严格遵循标注规范,确保标注结果的一致性和可靠性。对于模糊不清的图像样本,将进行人工审核,避免错误标注对模型训练产生负面影响。
为了保证标注质量,将采用多人标注和交叉验证的方式。首先由多名标注人员对同一批图像进行独立标注,然后对标注结果进行比较和分析,找出不一致的地方进行讨论和修正。通过这种方式,能够有效降低标注错误率,提高数据集的质量。同时,还将定期对标注人员进行培训,提高他们的标注技能和专业知识,确保标注工作的顺利进行。
数据处理
原始图像数据在用于模型训练之前,需要进行一系列的预处理操作,以提高数据质量和模型训练效果。首先进行图像灰度化处理,将彩色图像转换为灰度图像,减少数据维度,提高计算效率。然后进行图像二值化处理,将灰度图像转换为黑白图像,突出字符区域,抑制背景噪声。图像去噪处理是数据预处理的重要环节,将采用高斯滤波、中值滤波等方法去除图像中的噪声点,提高图像的清晰度。同时,还将进行图像增强处理,如直方图均衡化、对比度调整、亮度调整等,以改善图像的视觉效果,提高字符的辨识度。对于存在形变的图像,将进行几何校正处理,如透视变换、仿射变换等,将形变的字符区域恢复为正常形状。除了上述处理步骤外,还将进行数据归一化处理,将图像像素值缩放到0-1之间,以提高模型训练的收敛速度和稳定性。同时,还将进行数据增强处理,生成更多的训练样本,如随机裁剪、旋转、缩放、翻转、亮度调整、对比度调整等。这些数据增强技术能够有效扩大数据集规模,提高模型的泛化能力,减少过拟合现象的发生。
数据集划分
为了保证模型训练和测试的准确性,将数据集划分为训练集、验证集和测试集三部分。训练集用于模型的训练过程,验证集用于模型训练过程中的参数调整和性能评估,测试集用于模型训练完成后的最终性能评估。数据集划分将采用随机抽样的方式,确保各部分数据的分布均匀。具体划分比例为:训练集占70%,验证集占15%,测试集占15%。这样的划分比例既能够保证训练集有足够的样本数量用于模型训练,又能够保证验证集和测试集有足够的样本数量用于模型评估。在划分数据集时,将考虑数据的多样性和代表性,确保各部分数据都包含不同类型、不同场景、不同状态的银行卡号图像。同时,还将确保训练集、验证集和测试集之间没有重叠,避免模型在测试过程中遇到训练过的样本,影响测试结果的准确性。通过合理的数据集划分,能够有效评估模型的性能,为后续的模型优化提供可靠的依据。
功能模块介绍
图像预处理模块
图像预处理是银行卡号识别系统的第一步,其目的是提高输入图像的质量,为后续的文本检测和识别提供良好的基础。原始图像可能存在各种问题,如光照不均匀、噪声干扰、图像模糊、几何形变等,这些问题会严重影响后续模块的处理效果。因此,图像预处理模块需要采用多种技术手段,对输入图像进行优化处理。
首先进行图像灰度化处理,将彩色图像转换为灰度图像,减少数据维度,提高计算效率。灰度化处理可以保留图像的亮度信息,同时去除颜色信息对后续处理的干扰。然后进行图像二值化处理,将灰度图像转换为黑白图像,突出字符区域,抑制背景噪声。二值化处理可以使用全局阈值法、局部阈值法或自适应阈值法,根据图像的具体情况选择合适的方法。
图像去噪处理是预处理的重要环节,将采用高斯滤波、中值滤波、双边滤波等方法去除图像中的噪声点,提高图像的清晰度。高斯滤波适合去除高斯噪声,中值滤波适合去除椒盐噪声,双边滤波可以在去除噪声的同时保持图像的边缘信息。同时,还将进行图像增强处理,如直方图均衡化、对比度调整、亮度调整等,以改善图像的视觉效果,提高字符的辨识度。对于存在形变的图像,将进行几何校正处理,如透视变换、仿射变换等,将形变的字符区域恢复为正常形状。
文本检测模块
文本检测模块的任务是从预处理后的图像中定位出银行卡号的字符区域。银行卡号通常由一串连续的数字和字母组成,位于卡片的特定位置,但由于拍摄角度、光照条件等因素的影响,字符区域可能会发生倾斜、旋转或变形,增加了检测的难度。因此,文本检测模块需要具备良好的定位能力和鲁棒性。
将采用改进的EAST算法进行文本检测。EAST算法是一种端到端的文本检测算法,具有检测速度快、准确率高的特点。改进的EAST算法将引入ASPP模块,通过多个不同膨胀率的卷积核并行处理特征图,扩大感受野,提高对不同尺寸字符的检测能力。同时,使用ResNet-50作为特征提取网络,提取更丰富的图像特征,提高检测的准确性。
检测过程包括特征提取、特征融合和输出层三个部分。特征提取部分使用ResNet-50网络提取图像的多尺度特征;特征融合部分将不同尺度的特征进行融合,形成具有丰富语义信息的特征图;输出层生成文本区域的概率图和几何形状信息。为了提高检测的准确性,将使用平衡交叉熵损失和IOU损失作为损失函数,平衡正负样本比例,优化模型参数。检测结果将通过非极大值抑制等方法进行优化和筛选,去除冗余的检测框,得到最终的字符区域定位结果。
文本识别模块
文本识别模块的任务是从检测到的字符区域中识别出具体的字符内容。银行卡号通常由数字和少量字母组成,字符之间的间距较小,且可能存在字体变化、字符磨损等情况,增加了识别的难度。因此,文本识别模块需要具备良好的字符识别能力和鲁棒性。
将采用改进的ASTER网络进行文本识别。ASTER网络是一种端到端的文本识别网络,具有处理透视变形字符的能力。改进的ASTER网络将结合CTC和注意力机制的解码方式,提高字符识别的精度和鲁棒性。CTC解码方式不需要对齐标签,适合处理变长序列;注意力机制可以自动关注输入序列中与当前输出相关的部分,提高识别的准确性。
识别过程包括特征提取、特征序列生成和解码三个部分。特征提取部分使用ResNet-45网络提取字符区域的视觉特征;特征序列生成部分将二维特征图转换为一维特征序列;解码部分使用CTC+attention的联合解码机制,将特征序列转换为字符序列。为了提高识别的准确性,将使用复合损失函数,结合CTC损失和注意力损失,优化模型参数。识别结果将通过语言模型等方法进行优化和验证,提高识别的正确性。
算法理论
卷积神经网络
卷积神经网络是深度学习领域中应用最广泛的图像特征提取算法之一,其核心思想是通过卷积操作自动学习图像的多层次特征。卷积神经网络的结构通常包括输入层、卷积层、池化层、全连接层和输出层等部分,其中卷积层和池化层是其最具特色的组成部分。
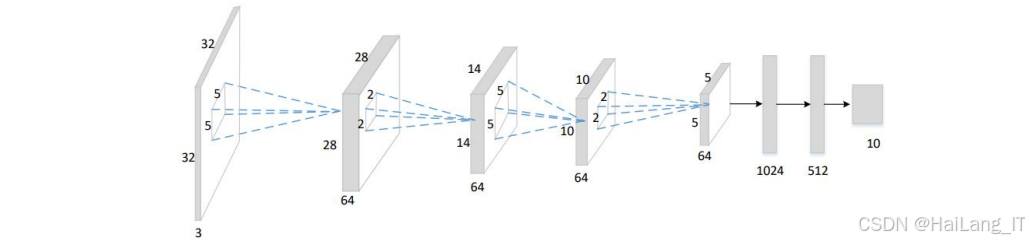
卷积层通过卷积核与输入图像进行卷积操作,提取图像的局部特征。卷积核是一个小尺寸的权重矩阵,通过滑动窗口的方式在输入图像上进行扫描,每个位置的输出是卷积核与对应区域的点积之和。卷积操作可以有效地捕捉图像的边缘、纹理等局部特征,同时通过参数共享和局部连接的方式减少模型参数数量,提高计算效率。卷积层的输出通常会经过非线性激活函数(如ReLU函数),增加模型的非线性表达能力。池化层的主要作用是对卷积层的输出进行下采样,减少特征图的尺寸,降低计算复杂度,同时增强模型的平移不变性。常用的池化方法包括最大池化和平均池化,最大池化选择每个区域的最大值作为输出,平均池化选择每个区域的平均值作为输出。全连接层将池化层的输出特征向量进行整合,通过全连接的方式将特征映射到输出空间,最后通过输出层得到分类或回归结果。卷积神经网络在图像分类、目标检测、图像分割等任务中取得了显著成果,是图像识别领域的核心技术之一。
循环神经网络
循环神经网络是一类专门处理序列数据的神经网络模型,其核心思想是通过循环连接保存历史信息,使网络能够处理变长序列数据。循环神经网络的结构与传统神经网络类似,但在隐藏层之间增加了循环连接,使得当前时刻的隐藏状态不仅取决于当前时刻的输入,还取决于上一时刻的隐藏状态。
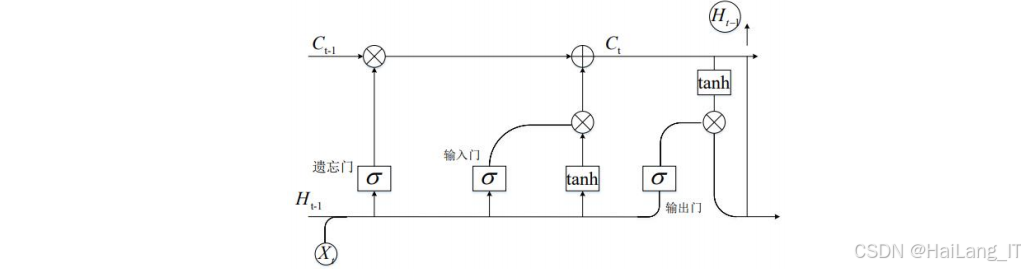
基本的循环神经网络单元由输入门、遗忘门和输出门组成。输入门控制当前时刻的输入信息有多少会被保存到记忆单元中,遗忘门控制上一时刻的记忆信息有多少会被保留,输出门控制记忆单元中的信息有多少会被输出到当前时刻的隐藏状态中。这种门控机制使得循环神经网络能够有效地捕捉序列数据中的长期依赖关系,避免了传统循环神经网络中常见的梯度消失和梯度爆炸问题。
长短期记忆网络是循环神经网络的一种改进形式,通过引入记忆单元和门控机制,解决了传统循环神经网络在处理长期依赖关系时的困难。LSTM网络能够有效地学习序列数据中的长期依赖关系,在自然语言处理、语音识别、时间序列预测等任务中取得了广泛应用。在银行卡号识别任务中,LSTM网络可以用于处理字符序列的上下文信息,提高字符识别的准确性。
EAST文本检测算法
EAST文本检测算法是一种端到端的场景文本检测算法,具有检测速度快、准确率高的特点。EAST算法的设计理念是将文本检测任务转化为像素级的分割任务,直接预测文本区域的几何形状,避免了传统文本检测算法中复杂的后处理步骤。
EAST算法的网络结构主要包括特征提取网络、特征融合网络和输出层三个部分。特征提取网络通常使用预训练的卷积神经网络(如VGG、ResNet等),用于提取图像的多尺度特征。特征融合网络将不同尺度的特征进行融合,形成具有丰富语义信息的特征图,提高对不同尺寸文本的检测能力。输出层包括两个分支,分别预测文本区域的概率图和几何形状信息,几何形状信息可以是旋转矩形或四边形的坐标。
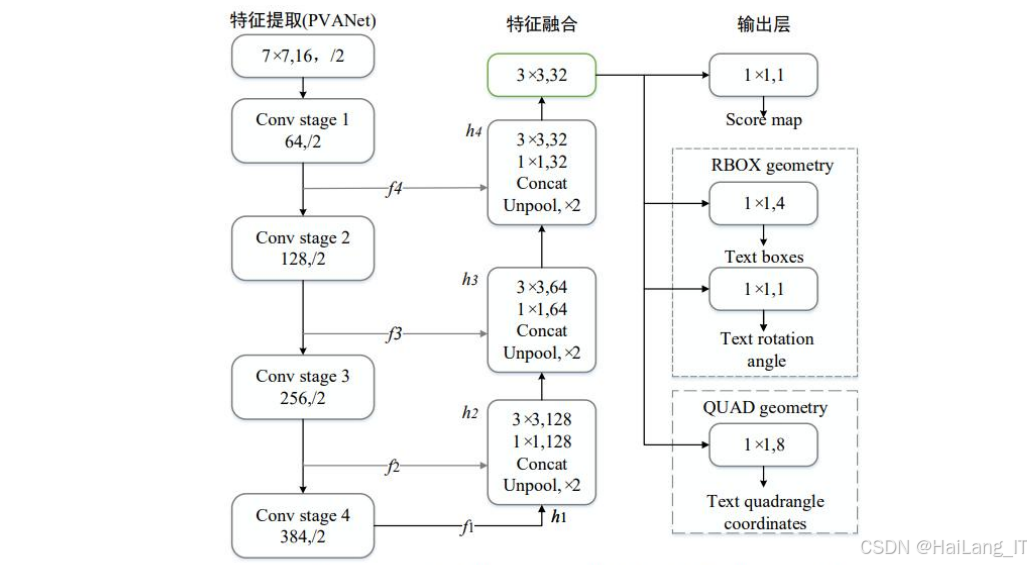
EAST算法的损失函数由两部分组成,分别是文本区域的分类损失和几何形状的回归损失。分类损失通常使用平衡交叉熵损失,用于处理正负样本不平衡的问题;回归损失根据输出几何形状的不同而有所不同,对于旋转矩形通常使用IOU损失,对于四边形通常使用smoothed-L1损失。改进的EAST算法将引入ASPP模块,通过多个不同膨胀率的卷积核并行处理特征图,扩大感受野,提高对不同尺寸字符的检测能力。同时,使用ResNet-50作为特征提取网络,提取更丰富的图像特征,提高检测的准确性。
ASTER字符识别算法
ASTER字符识别算法是一种端到端的场景文本识别算法,具有处理透视变形字符的能力。ASTER算法的设计理念是通过空间变换网络对输入图像进行校正,然后使用序列识别网络对校正后的图像进行识别,从而提高对变形文本的识别能力。
ASTER算法的网络结构主要包括空间变换网络和序列识别网络两个部分。空间变换网络由定位网络和网格生成器组成,定位网络预测空间变换的参数,网格生成器根据这些参数生成采样网格,然后通过采样操作对输入图像进行校正。序列识别网络通常使用卷积神经网络和循环神经网络的组合,卷积神经网络用于提取校正后图像的视觉特征,循环神经网络用于处理序列特征并生成字符序列。
ASTER算法的解码方式通常使用注意力机制,通过计算当前时刻输出与输入序列中各个位置的注意力权重,自动关注输入序列中与当前输出相关的部分,提高识别的准确性。改进的ASTER算法将结合CTC和注意力机制的解码方式,CTC解码方式不需要对齐标签,适合处理变长序列;注意力机制可以自动关注输入序列中与当前输出相关的部分,提高识别的准确性。同时,使用复合损失函数,结合CTC损失和注意力损失,优化模型参数,提高识别的精度和鲁棒性。
注意力机制
注意力机制是一种模拟人类视觉注意力的机制,其核心思想是在处理序列数据时,自动关注输入序列中与当前输出相关的部分,从而提高模型的性能。注意力机制最初在机器翻译任务中提出,后来被广泛应用于自然语言处理、计算机视觉等领域。注意力机制的基本原理是通过计算查询向量与键向量之间的相似度,得到注意力权重,然后使用权重对值向量进行加权求和,得到注意力输出。在文本识别任务中,查询向量通常是当前时刻的隐藏状态,键向量和值向量通常是输入序列的特征向量。注意力权重表示当前时刻输出与输入序列中各个位置的相关程度,权重越高表示相关程度越高。

注意力机制可以分为软注意力和硬注意力两种类型,软注意力对所有输入位置分配权重,硬注意力只对一个或几个输入位置分配权重。软注意力是可微分的,可以通过梯度下降进行训练,而硬注意力是不可微分的,需要使用强化学习等方法进行训练。在银行卡号识别任务中,注意力机制可以用于提高字符识别的准确性,特别是对于模糊、磨损的字符,注意力机制可以自动关注字符的关键部分,提高识别的鲁棒性。
相关代码介绍
图像预处理模块代码
图像预处理是银行卡号识别系统的基础环节,其目的是提高输入图像的质量,为后续的文本检测和识别提供良好的基础。图像预处理模块需要实现灰度化、二值化、去噪、增强等功能,以处理原始图像中可能存在的光照不均匀、噪声干扰、图像模糊等问题。
灰度化处理将彩色图像转换为灰度图像,减少数据维度,提高计算效率。二值化处理将灰度图像转换为黑白图像,突出字符区域,抑制背景噪声。去噪处理使用高斯滤波、中值滤波等方法去除图像中的噪声点,提高图像的清晰度。图像增强处理使用直方图均衡化、对比度调整等方法,改善图像的视觉效果,提高字符的辨识度。
以下是图像预处理模块的核心代码示例,展示了如何实现灰度化、二值化、去噪等功能:
python
import cv2
import numpy as np
class ImagePreprocessor:
def __init__(self):
self.kernel_size = (3, 3)
self.sigma = 1.0
self.threshold_value = 127
self.max_value = 255
def to_gray(self, image):
"""
将彩色图像转换为灰度图像
"""
if len(image.shape) == 3:
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return image
def to_binary(self, gray_image):
"""
将灰度图像转换为二值图像
"""
_, binary_image = cv2.threshold(
gray_image, self.threshold_value, self.max_value, cv2.THRESH_BINARY
)
return binary_image
def denoise(self, image):
"""
对图像进行去噪处理
"""
return cv2.GaussianBlur(image, self.kernel_size, self.sigma)
def enhance_contrast(self, image):
"""
增强图像对比度
"""
if len(image.shape) == 3:
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
v = clahe.apply(v)
hsv = cv2.merge((h, s, v))
return cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
else:
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
return clahe.apply(image)
def preprocess(self, image):
"""
完整的图像预处理流程
"""
# 灰度化
gray = self.to_gray(image)
# 去噪
denoised = self.denoise(gray)
# 增强对比度
enhanced = self.enhance_contrast(denoised)
# 二值化
binary = self.to_binary(enhanced)
return binary该代码定义了一个ImagePreprocessor类,包含灰度化、二值化、去噪、增强对比度等方法,以及一个完整的preprocess方法,实现了图像预处理的完整流程。通过这些方法,可以对输入图像进行全面的预处理,提高图像质量,为后续的文本检测和识别提供良好的基础。
在实际应用中,可以根据具体情况调整预处理参数,如阈值、卷积核大小、高斯模糊的标准差等,以适应不同的图像质量和光照条件。同时,可以根据需要添加其他预处理方法,如几何校正、图像缩放等,以进一步提高预处理效果。
改进EAST算法代码
改进EAST算法是银行卡号识别系统的核心模块之一,其目的是从预处理后的图像中定位出银行卡号的字符区域。改进EAST算法引入了ASPP模块,通过多个不同膨胀率的卷积核并行处理特征图,扩大感受野,提高对不同尺寸字符的检测能力。同时,使用ResNet-50作为特征提取网络,提取更丰富的图像特征,提高检测的准确性。
改进EAST算法的网络结构包括特征提取网络、ASPP模块、特征融合网络和输出层四个部分。特征提取网络使用ResNet-50提取图像的多尺度特征;ASPP模块通过多个不同膨胀率的卷积核并行处理特征图,扩大感受野;特征融合网络将不同尺度的特征进行融合,形成具有丰富语义信息的特征图;输出层生成文本区域的概率图和几何形状信息。
以下是改进EAST算法的核心代码示例,展示了如何实现特征提取、ASPP模块、特征融合等功能:
python
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import (
Conv2D, BatchNormalization, Activation, Add, UpSampling2D,
Concatenate, Lambda
)
def aspp_module(input_tensor, output_stride):
"""
ASPP模块定义
"""
# 全局平均池化
img_pool = tf.reduce_mean(input_tensor, axis=[1, 2], keepdims=True)
img_pool = Conv2D(256, (1, 1), padding='same', use_bias=False)(img_pool)
img_pool = BatchNormalization()(img_pool)
img_pool = Activation('relu')(img_pool)
img_pool = UpSampling2D(size=(input_tensor.shape[1], input_tensor.shape[2]),
interpolation='bilinear')(img_pool)
# 1x1卷积
conv_1x1 = Conv2D(256, (1, 1), padding='same', use_bias=False)(input_tensor)
conv_1x1 = BatchNormalization()(conv_1x1)
conv_1x1 = Activation('relu')(conv_1x1)
# 3x3膨胀卷积,膨胀率为6
conv_3x3_d6 = Conv2D(256, (3, 3), padding='same', dilation_rate=6, use_bias=False)(input_tensor)
conv_3x3_d6 = BatchNormalization()(conv_3x3_d6)
conv_3x3_d6 = Activation('relu')(conv_3x3_d6)
# 3x3膨胀卷积,膨胀率为12
conv_3x3_d12 = Conv2D(256, (3, 3), padding='same', dilation_rate=12, use_bias=False)(input_tensor)
conv_3x3_d12 = BatchNormalization()(conv_3x3_d12)
conv_3x3_d12 = Activation('relu')(conv_3x3_d12)
# 3x3膨胀卷积,膨胀率为18
conv_3x3_d18 = Conv2D(256, (3, 3), padding='same', dilation_rate=18, use_bias=False)(input_tensor)
conv_3x3_d18 = BatchNormalization()(conv_3x3_d18)
conv_3x3_d18 = Activation('relu')(conv_3x3_d18)
# 特征融合
concatenated = Concatenate()([img_pool, conv_1x1, conv_3x3_d6, conv_3x3_d12, conv_3x3_d18])
output = Conv2D(256, (1, 1), padding='same', use_bias=False)(concatenated)
output = BatchNormalization()(output)
output = Activation('relu')(output)
return output
def build_modified_east_model(input_shape=(512, 512, 3)):
"""
构建改进EAST模型
"""
# 输入层
inputs = tf.keras.Input(shape=input_shape)
# 使用ResNet50作为特征提取网络
base_model = ResNet50(include_top=False, weights='imagenet', input_tensor=inputs)
# 获取多尺度特征
x1 = base_model.get_layer('conv2_block3_out').output # 128x128x512
x2 = base_model.get_layer('conv3_block4_out').output # 64x64x1024
x3 = base_model.get_layer('conv4_block6_out').output # 32x32x2048
x4 = base_model.get_layer('conv5_block3_out').output # 16x16x2048
# 在顶层特征上应用ASPP模块
x4 = aspp_module(x4, output_stride=16)
# 特征融合
# 上采样x4并与x3融合
x4_up = UpSampling2D(size=(2, 2), interpolation='bilinear')(x4)
x3 = Conv2D(512, (1, 1), padding='same', use_bias=False)(x3)
x3 = BatchNormalization()(x3)
x3 = Activation('relu')(x3)
x3 = Add()([x3, x4_up])
# 上采样x3并与x2融合
x3_up = UpSampling2D(size=(2, 2), interpolation='bilinear')(x3)
x2 = Conv2D(256, (1, 1), padding='same', use_bias=False)(x2)
x2 = BatchNormalization()(x2)
x2 = Activation('relu')(x2)
x2 = Add()([x2, x3_up])
# 上采样x2并与x1融合
x2_up = UpSampling2D(size=(2, 2), interpolation='bilinear')(x2)
x1 = Conv2D(128, (1, 1), padding='same', use_bias=False)(x1)
x1 = BatchNormalization()(x1)
x1 = Activation('relu')(x1)
x1 = Add()([x1, x2_up])
# 输出层
# 文本区域概率图
score_map = Conv2D(1, (1, 1), activation='sigmoid', name='score_map')(x1)
# 文本区域几何形状信息(旋转矩形)
geo_map = Conv2D(5, (1, 1), name='geo_map')(x1)
# 构建模型
model = tf.keras.Model(inputs=inputs, outputs=[score_map, geo_map])
return model该代码定义了改进EAST算法的核心结构,包括ASPP模块和模型构建函数。ASPP模块通过多个不同膨胀率的卷积核并行处理特征图,扩大感受野,提高对不同尺寸字符的检测能力。模型构建函数使用ResNet-50作为特征提取网络,获取多尺度特征,并通过ASPP模块和特征融合网络,生成文本区域的概率图和几何形状信息。
在实际应用中,可以根据具体情况调整ASPP模块的膨胀率、卷积核大小、输出通道数等参数,以适应不同的字符尺寸和检测要求。同时,可以根据需要调整特征融合的方式和输出层的设计,以进一步提高检测的准确性和鲁棒性。
改进ASTER算法代码
改进ASTER算法是银行卡号识别系统的另一个核心模块,其目的是从检测到的字符区域中识别出具体的字符内容。改进ASTER算法结合了CTC和注意力机制的解码方式,提高字符识别的精度和鲁棒性。同时,使用ResNet-45作为特征提取网络,提取更丰富的字符区域特征,提高识别的准确性。
改进ASTER算法的网络结构包括特征提取网络、特征序列生成网络、双向LSTM网络和CTC+attention解码网络四个部分。特征提取网络使用ResNet-45提取字符区域的视觉特征;特征序列生成网络将二维特征图转换为一维特征序列;双向LSTM网络处理特征序列,捕捉序列上下文信息;CTC+attention解码网络将特征序列转换为字符序列,结合CTC和注意力机制的优势,提高识别的准确性和鲁棒性。
以下是改进ASTER算法的核心代码示例,展示了如何实现特征提取、双向LSTM网络、CTC+attention解码机制等功能:
python
import tensorflow as tf
from tensorflow.keras.layers import (
Conv2D, BatchNormalization, Activation, MaxPooling2D, Add,
Bidirectional, LSTM, Dense, Reshape, TimeDistributed, Lambda
)
def residual_block(input_tensor, filters, kernel_size=(3, 3), stride=1):
"""
残差块定义
"""
shortcut = input_tensor
# 第一卷积层
x = Conv2D(filters, kernel_size, strides=stride, padding='same', use_bias=False)(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第二卷积层
x = Conv2D(filters, kernel_size, strides=1, padding='same', use_bias=False)(x)
x = BatchNormalization()(x)
# 快捷连接
if stride != 1 or shortcut.shape[-1] != filters:
shortcut = Conv2D(filters, (1, 1), strides=stride, padding='same', use_bias=False)(shortcut)
shortcut = BatchNormalization()(shortcut)
# 残差连接
x = Add()([x, shortcut])
x = Activation('relu')(x)
return x
def build_resnet45(input_shape=(32, 100, 3)):
"""
构建ResNet-45特征提取网络
"""
inputs = tf.keras.Input(shape=input_shape)
# 初始卷积层
x = Conv2D(64, (3, 3), strides=1, padding='same', use_bias=False)(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 残差块组
# 第一组:3个残差块,64通道
for _ in range(3):
x = residual_block(x, 64)
# 第二组:4个残差块,128通道
x = residual_block(x, 128, stride=2)
for _ in range(3):
x = residual_block(x, 128)
# 第三组:6个残差块,256通道
x = residual_block(x, 256, stride=2)
for _ in range(5):
x = residual_block(x, 256)
# 第四组:6个残差块,512通道
x = residual_block(x, 512, stride=2)
for _ in range(5):
x = residual_block(x, 512)
return tf.keras.Model(inputs=inputs, outputs=x)
def build_modified_aster_model(input_shape=(32, 100, 3), num_classes=37):
"""
构建改进ASTER模型
"""
# 输入层
inputs = tf.keras.Input(shape=input_shape)
# 特征提取网络
feature_extractor = build_resnet45(input_shape)
features = feature_extractor(inputs)
# 将二维特征图转换为一维特征序列
# 假设输出形状为(batch_size, height, width, channels)
# 我们需要将其转换为(batch_size, width, height * channels)
features = Reshape((-1, features.shape[1] * features.shape[3]))(features)
# 双向LSTM网络
x = Bidirectional(LSTM(256, return_sequences=True))(features)
x = Bidirectional(LSTM(256, return_sequences=True))(x)
# CTC解码分支
ctc_output = TimeDistributed(Dense(num_classes + 1, activation='softmax'), name='ctc_output')(x)
# Attention解码分支
# 注意力层
attention = tf.keras.layers.Attention()([x, x])
attention_output = TimeDistributed(Dense(num_classes + 1, activation='softmax'), name='attention_output')(attention)
# 构建模型
model = tf.keras.Model(inputs=inputs, outputs=[ctc_output, attention_output])
return model
def ctc_loss_function(y_true, y_pred):
"""
CTC损失函数
"""
batch_len = tf.cast(tf.shape(y_true)[0], dtype='int64')
input_length = tf.cast(tf.shape(y_pred)[1], dtype='int64')
label_length = tf.cast(tf.shape(y_true)[1], dtype='int64')
input_length = input_length * tf.ones(shape=(batch_len, 1), dtype='int64')
label_length = label_length * tf.ones(shape=(batch_len, 1), dtype='int64')
return tf.keras.backend.ctc_batch_cost(y_true, y_pred, input_length, label_length)该代码定义了改进ASTER算法的核心结构,包括残差块、ResNet-45特征提取网络、双向LSTM网络和CTC+attention解码网络。残差块是ResNet-45的基本组成单元,通过残差连接解决了深度神经网络中的梯度消失问题。ResNet-45特征提取网络用于提取字符区域的视觉特征;双向LSTM网络用于处理特征序列,捕捉序列上下文信息;CTC+attention解码网络用于将特征序列转换为字符序列,结合CTC和注意力机制的优势,提高识别的准确性和鲁棒性。
在实际应用中,可以根据具体情况调整ResNet-45的深度、双向LSTM的隐藏单元数、输出通道数等参数,以适应不同的字符识别要求。同时,可以根据需要调整CTC+attention解码机制的设计,以进一步提高识别的准确性和鲁棒性。此外,还可以使用复合损失函数,结合CTC损失和注意力损失,优化模型参数,提高识别的精度和鲁棒性。
重难点和创新点
重难点
银行卡号识别系统的设计与实现面临多个技术重难点,需要综合考虑图像质量、字符形态、环境干扰等多种因素。首先,复杂背景下的字符检测是系统设计的首要难点。银行卡图像可能包含各种背景干扰,如桌面纹理、阴影、光照不均匀等,这些因素会严重影响字符区域的检测精度。传统的文本检测算法在处理复杂背景时容易产生误检和漏检,因此需要设计更鲁棒的特征提取和分类方法。
其次,变形字符的识别是系统实现的另一大挑战。银行卡在使用过程中可能会发生弯曲、磨损、污渍等情况,导致字符变形、模糊或部分遮挡。这些变形字符的识别难度远高于标准字符,需要模型具有更强的特征学习和泛化能力。传统的字符识别算法依赖于固定的字符模板,难以适应变形字符的识别需求,因此需要采用深度学习技术,通过大量的变形样本训练,提高模型对变形字符的识别能力。
第三,多尺度字符的处理也是系统设计的重要难点。不同银行卡的字符大小、间距可能存在差异,同一银行卡在不同拍摄距离和角度下,字符的尺度也会发生变化。这些多尺度字符需要检测算法具有良好的尺度不变性,能够准确检测不同尺度的字符区域。同时,识别算法也需要适应不同尺度的字符输入,保持较高的识别精度。
最后,模型的效率与精度平衡是系统实现的关键考量。银行卡号识别系统通常需要在移动设备或嵌入式系统上运行,对模型的计算资源和运行时间有严格限制。如何在保证识别精度的同时,降低模型的参数量和计算复杂度,是系统设计的重要挑战。需要采用模型压缩、量化、剪枝等技术,优化模型结构,提高模型的推理效率。
创新点
针对银行卡号识别系统的技术难点,设计了一系列创新的技术方案,提高系统的检测精度和识别鲁棒性。首先,在文本检测模块引入ASPP模块,通过多个不同膨胀率的卷积核并行处理特征图,扩大感受野,提高对不同尺寸字符的检测能力。ASPP模块可以捕捉多尺度的上下文信息,增强特征表示能力,从而提高对小字符和大字符的检测精度。
其次,在文本识别模块结合CTC和注意力机制的解码方式,充分发挥两种解码方式的优势。CTC解码方式不需要对齐标签,适合处理变长序列,能够快速解码;注意力机制可以自动关注输入序列中与当前输出相关的部分,提高识别的准确性。通过结合两种解码方式,可以在保证解码速度的同时,提高识别的精度和鲁棒性。
第三,采用多模态特征融合策略,综合利用图像的视觉特征和文本的语义特征,提高识别的准确性。视觉特征包括字符的形状、纹理、颜色等信息,语义特征包括字符的上下文关系、语法规则等信息。通过多模态特征融合,可以弥补单一特征的不足,提高模型的识别能力,特别是对于模糊、磨损的字符。
第四,设计了多样化的数据增强策略,扩充训练数据集,提高模型的泛化能力。数据增强策略包括几何变换(旋转、缩放、平移、扭曲等)、颜色变换(亮度、对比度、饱和度调整等)、噪声添加(高斯噪声、椒盐噪声等)、字符遮挡等。通过这些数据增强策略,可以模拟各种实际场景下的银行卡图像,提高模型对复杂环境的适应能力。
第五,采用端到端的模型设计,简化系统流程,提高系统的整体性能。端到端模型将文本检测和识别集成到一个统一的网络中,避免了传统方法中检测和识别分开处理的误差累积问题。同时,端到端模型可以通过联合训练,优化整体性能,提高系统的检测精度和识别效率。
相关文献
1 Long S, He X, Yao C. Scene text detection and recognition: The deep learning eraJ. International Journal of Computer Vision, 2021, 129(1): 161-184.
2 Zhou X, Yao C, Wen H, et al. EAST: An efficient and accurate scene text detectorC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 2642-2651.
3 Shi B, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognitionJ. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(11): 2298-2304.
4 Li Y, Wang P, Shen C. Scene text detection with deformable rotation-invariant CNNJ. IEEE Transactions on Image Processing, 2020, 29: 500-513.
5 Yu D, Li X, Zhang C. Attention-guided scene text recognition with dynamic context fusionJ. Pattern Recognition Letters, 2021, 149: 1-7.
6 Zhang X, Yang X, Li Y. Scene text recognition with transformerJ. Neurocomputing, 2022, 476: 16-25.
7 Chen L, Wang X, Liu J. Multi-scale feature fusion for scene text detectionJ. Journal of Visual Communication and Image Representation, 2023, 92: 103897.
8 Wang Y, Zhang L, Li Z. Scene text recognition with adaptive attention mechanismJ. Pattern Recognition, 2024, 143: 109760.