Guardrails(防护栏),也称为安全模式,是确保智能 Agent 安全、符合道德规范并按预期运行的关键机制, 特别是在 Agent 变得更加自主并集成到关键系统中的情况下。它们作为保护层,引导 Agent 的行为和输出, 防止有害、有偏见、无关或其他不良响应。这些防护栏可以在多个阶段实施,包括输入验证/清理以过滤恶意 内容、输出过滤/后处理以分析生成响应中的毒性或偏见、通过直接指令设置行为约束(提示词级别)、工具使用限制以约束 Agent 能力、用于内容审核的外部审核 API,以及通过"人机协同"机制实现的人工监督/干 预。
防护栏的主要目的不是限制 Agent 的能力,而是确保其运行稳健、可靠且有益。它们作为安全措施和指导机制,对构建负责任的 AI 系统、减轻风险以及通过确保可预测、安全和合规的行为来维护用户信任至关重要, 从而防止操纵并维护道德和法律标准。没有防护栏,AI 系统可能变得不受约束、不可预测且具有潜在危险。 为进一步缓解这些风险,可以使用计算密集度较低的模型作为快速额外保障,预先筛选输入或对主模型输出 进行双重检查,以发现策略违规。
实际应用与用例
Guardrails 应用于各种 Agent 应用场景:
-
・ 客户服务聊天机器人:防止生成冒犯性语言、不正确或有害的建议(例如医疗、法律建议)或离题响 应。Guardrails 可以检测有毒的用户输入,并指示机器人以拒绝或升级到人工的方式响应。
-
・ 内容生成系统:确保生成的文章、营销文案或创意内容符合准则、法律要求和道德标准,同时避免仇 恨言论、错误信息或露骨内容。Guardrails 可以涉及后处理过滤器,标记并删除有问题的短语。
-
・ 教育导师/助手:防止Agent提供不正确的答案、推广有偏见的观点或进行不当对话。这可能涉及内容 过滤和遵守预定义的课程。
-
・ 法律研究助手:防止 Agent 提供明确的法律建议或充当持证律师的替代品,而是引导用户咨询法律专 业人士。
-
・ 招聘和人力资源工具:通过过滤歧视性语言或标准,确保候选人筛选或员工评估的公平性并防止偏见。
-
・ 社交媒体内容审核:自动识别和标记包含仇恨言论、错误信息或暴力内容的帖子。
-
・ 科学研究助手:防止Agent捏造研究数据或得出缺乏支持的结论,强调需要实证验证和同行评审。
在这些场景中,防护栏作为防御机制发挥作用,保护用户、组织和 AI 系统的声誉。
构建可靠的 Agent
构建可靠的 AI Agent 要求我们应用与管理传统软件工程相同的严谨性和最佳实践。我们必须记住,即使是确 定性代码也容易出现错误和不可预测的涌现行为,这就是为什么容错、状态管理和健壮测试等原则一直至关重要。我们不应将 Agent 视为全新的东西,而应将它们视为比以往任何时候都更需要这些经过验证的工程学 科的复杂系统。
检查点和回滚模式是一个完美的例子。鉴于自主 Agent 管理复杂状态并可能朝着意外方向发展,实施检查点 类似于设计具有提交和回滚能力的事务系统------这是数据库工程的基石。每个检查点都是一个经过验证的状 态,Agent 工作的成功"提交",而回滚是容错的机制。这将错误恢复转变为主动测试和质量保证策略的核 心部分。
然而,强大的 Agent 架构不仅仅是一个模式。其他几个软件工程原则也很关键:
-
・ 模块化和关注点分离:一个单体的、无所不能的 Agent 是脆弱的且难以调试。最佳实践是设计一个较 小的、专门的 Agent 或工具协作的系统。例如,一个 Agent 可能是数据检索专家,另一个是分析专 家,第三个是用户沟通专家。这种分离使系统更容易构建、测试和维护。多 Agent 系统中的模块化通过支持并行处理来增强性能。这种设计提高了灵活性和故障隔离,因为可以独立优化、更新和调试各 个 Agent。结果是 AI 系统具有可扩展性、鲁棒性和可维护性。
-
・ 通过结构化日志记录实现可观测性:可靠的系统是您可以理解的系统。对于 Agent 来说,这意味着实 施深度可观测性。工程师不仅需要看到最终输出,还需要捕获 Agent 整个"思维链"的结构化日志------ 它调用了哪些工具、收到了什么数据、下一步的推理以及其决策的置信度得分。这对于调试和性能调 优至关重要。
-
・ 最小权限原则:安全至关重要。Agent 应该被授予执行其任务所需的绝对最小权限集。设计用于总结 公共新闻文章的 Agent 应该只能访问新闻 API,而不能读取私人文件或与其他公司系统交互。这大大 限制了潜在错误或恶意利用的"爆炸半径"。
通过整合这些核心原则------容错、模块化设计、深度可观测性和严格的安全性------我们从简单地创建一个功 能性 Agent 转向工程化一个具有弹性的、生产级的系统。这确保了 Agent 的操作不仅有效,而且稳健、可审计和值得信赖,满足任何精心设计的软件所需的高标准。
概览
内容:随着智能 Agent 和 LLM 变得更加自主,如果不加约束,它们可能会带来风险,因为它们的行为可能 是不可预测的。它们可能生成有害、有偏见、不道德或事实不正确的输出,可能造成现实世界的损害。这些系统容易受到对抗性攻击,这些攻击旨在绕过其安全协议。没有适当的控制,Agent 系统可能会 以意想不到的方式行事,导致用户信任的丧失,并使组织面临法律和声誉损害。
原因: Guardrails 或安全模式提供了一个标准化的解决方案来管理 Agent 系统固有的风险。它们作为一个 多层防御机制,确保 Agent 安全、符合道德规范并与其预期目的保持一致地运行。这些模式在各个阶段实 施,包括验证输入以阻止恶意内容和过滤输出以捕获不良响应。高级技术包括通过提示词设置行为约束、限 制工具使用,以及为关键决策集成人机协同监督。最终目标不是限制 Agent 的实用性,而是引导其行为,确 保它值得信赖、可预测且有益。
经验法则: Guardrails 应该在任何 AI Agent 的输出可能影响用户、系统或业务声誉的应用中实施。对于面 向客户的角色(例如聊天机器人)、内容生成平台以及处理金融、医疗保健或法律研究等领域敏感信息的系 统中的自主 Agent 来说,它们至关重要。使用它们来执行道德准则、防止错误信息的传播、保护品牌安全并 确保法律和监管合规。
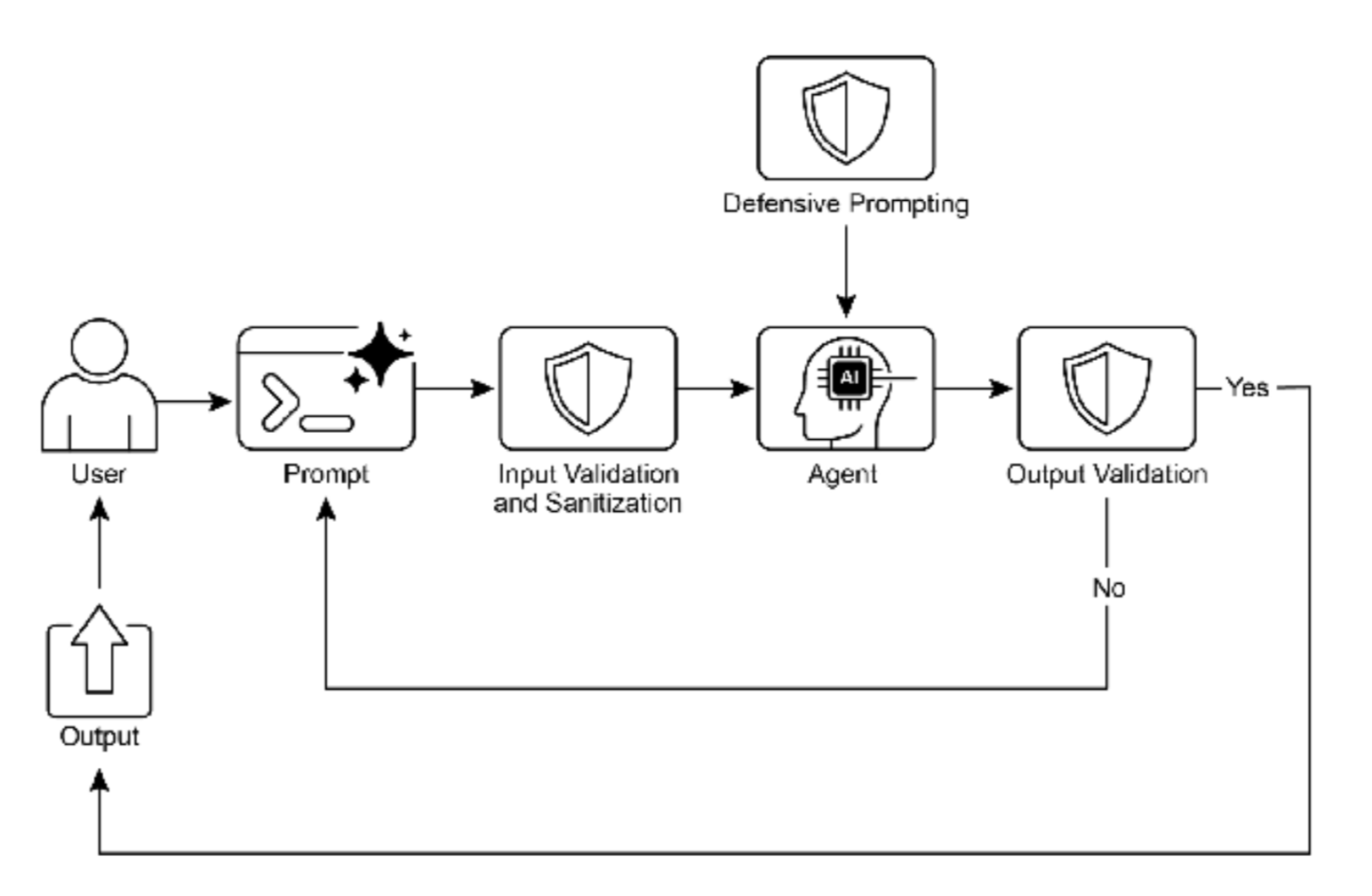
图 1:Guardrail 设计模式
关键要点
-
・ Guardrails 对于通过防止有害、有偏见或离题的响应来构建负责任、符合道德规范和安全的 Agent 至 关重要。
-
・ 它们可以在各个阶段实施,包括输入验证、输出过滤、行为提示词、工具使用限制和外部审核。
-
・ 不同guardrail技术的组合提供了最强大的保护。
-
・ Guardrails需要持续的监控、评估和改进,以适应不断演变的风险和用户交互。
-
・ 有效的guardrails对于维护用户信任和保护Agent及其开发者的声誉至关重要。
-
・ 构建可靠的、生产级 Agent 的最有效方法是将它们视为复杂软件,应用与传统系统几十年来相同的经 过验证的工程最佳实践------如容错、状态管理和健壮测试。
用例DEMO
我们将模拟以下场景:
-
1、客户服务聊天机器人:使用内容过滤器防止生成冒犯性语言。
-
2、内容生成系统:使用后处理过滤器确保生成内容符合准则。
-
3、教育导师/助手:确保答案正确且不包含不当内容。
由于实际中Guardrails可能涉及多个层面(输入过滤、输出过滤、中间验证等),我们将通过创建自定义的"拦截器"或"过滤器"来演示。
假设我们有一个简单的AI服务,我们将围绕它构建防护栏。
步骤:
a. 首先,我们需要定义一个AI服务(例如,使用LangChain4j的ChatLanguageModel)。
b. 然后,我们将创建一些防护栏类,这些类可以在调用AI服务之前过滤用户输入,并在生成之后过滤输出。
c. 最后,我们将这些防护栏与AI服务组合在一起。
由于时间关系,我们不会连接到真实的AI模型,而是使用模拟响应。但代码结构将展示如何集成防护栏。
我们选择三个场景,分别编写示例代码:
示例1:客户服务聊天机器人 - 输入和输出过滤,防止有毒内容。
示例2:内容生成系统 - 输出过滤,确保生成内容不包含限制言论等。
示例3:教育导师/助手 - 输出验证,确保答案正确(这里我们模拟一个简单的答案验证器)。
请注意,这些示例仅用于演示概念,实际防护栏可能需要更复杂的逻辑(如使用额外的分类模型)。
以下是一个客户服务聊天机器人的完整示例,包含输入验证和输出防护机制。
一、客户服务聊天机器人Guardrails实现
- 项目依赖配置(Maven pom.xml)
XML
<dependencies>
<!-- LangChain4j 核心 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.31.0</version>
</dependency>
<!-- 使用OpenAI作为LLM提供商 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.31.0</version>
</dependency>
<!-- 用于内容审查的模块 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-hugging-face</artifactId>
<version>0.31.0</version>
</dependency>
</dependencies>- 核心防护栏实现类
java
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.V;
import dev.langchain4j.service.spring.AiService;
import java.util.Arrays;
import java.util.List;
/**
* 客户服务聊天机器人防护栏实现
* 防止:冒犯性语言、有害建议、离题响应
*/
public class CustomerServiceGuardrails {
// 1. 输入防护:检测有毒内容
public static class InputGuardrail {
private static final List<String> TOXIC_KEYWORDS = Arrays.asList(
"愚蠢", "白痴", "去死", "垃圾", "废物",
"hate", "idiot", "stupid", "kill", "die"
);
private static final List<String> DANGEROUS_TOPICS = Arrays.asList(
"自杀方法", "如何制作炸弹", "非法药物",
"self-harm", "bomb making", "illegal drugs"
);
public GuardrailResult validateInput(String userInput) {
GuardrailResult result = new GuardrailResult();
// 检测有毒关键词
for (String keyword : TOXIC_KEYWORDS) {
if (userInput.toLowerCase().contains(keyword.toLowerCase())) {
result.setBlocked(true);
result.setReason("检测到不当语言,请使用文明用语");
result.setAction(GuardrailAction.REJECT);
return result;
}
}
// 检测危险话题
for (String topic : DANGEROUS_TOPICS) {
if (userInput.toLowerCase().contains(topic.toLowerCase())) {
result.setBlocked(true);
result.setReason("该话题涉及安全风险,已自动转接人工客服");
result.setAction(GuardrailAction.ESCALATE);
return result;
}
}
result.setBlocked(false);
return result;
}
}
// 2. 输出防护:验证AI响应
public static class OutputGuardrail {
private static final List<String> MEDICAL_ADVICE_TRIGGERS = Arrays.asList(
"医生", "药品", "治疗", "诊断", "症状",
"doctor", "medicine", "treatment", "diagnosis"
);
private static final List<String> LEGAL_ADVICE_TRIGGERS = Arrays.asList(
"法律", "律师", "诉讼", "合同", "违法",
"lawyer", "lawsuit", "contract", "illegal"
);
public GuardrailResult validateOutput(String aiResponse, String userQuery) {
GuardrailResult result = new GuardrailResult();
// 检测是否在提供医疗建议
boolean hasMedicalContext = false;
for (String trigger : MEDICAL_ADVICE_TRIGGERS) {
if (userQuery.contains(trigger) || aiResponse.contains(trigger)) {
hasMedicalContext = true;
break;
}
}
if (hasMedicalContext) {
// 检查AI是否在尝试提供具体医疗建议
if (aiResponse.contains("建议你") &&
(aiResponse.contains("服用") || aiResponse.contains("诊断"))) {
result.setBlocked(true);
result.setReason("AI不能提供医疗建议,请咨询专业医生");
result.setCorrectedResponse("我理解您可能需要医疗建议,但作为AI助手,我不能提供具体的医疗指导。请咨询有资质的医疗专业人士。");
return result;
}
}
// 检测是否在提供法律建议
boolean hasLegalContext = false;
for (String trigger : LEGAL_ADVICE_TRIGGERS) {
if (userQuery.contains(trigger) || aiResponse.contains(trigger)) {
hasLegalContext = true;
break;
}
}
if (hasLegalContext && aiResponse.contains("你应该") &&
(aiResponse.contains("起诉") || aiResponse.contains("违反"))) {
result.setBlocked(true);
result.setReason("AI不能提供法律建议");
result.setCorrectedResponse("我理解您有法律方面的疑问,但具体的法律建议需要咨询执业律师。我可以帮您查找相关的法律信息或推荐法律咨询服务。");
return result;
}
result.setBlocked(false);
return result;
}
}
// 3. 定义AI服务接口(使用LangChain4j的@AiService)
@AiService
interface CustomerServiceBot {
@SystemMessage("""
你是一个专业的客户服务助手,专注于回答产品使用、技术支持、
订单查询和一般信息咨询。对于以下类型的问题,你必须拒绝回答
或建议用户咨询专业人士:
1. 医疗健康建议
2. 法律建议
3. 财务投资建议
4. 涉及危险或非法活动的内容
如果用户使用不文明语言,请礼貌地拒绝继续服务。
""")
String chat(@UserMessage String userMessage);
}
// 4. 防护栏包装器:整合输入输出防护
public static class GuardedCustomerService {
private final ChatLanguageModel model;
private final CustomerServiceBot bot;
private final InputGuardrail inputGuardrail;
private final OutputGuardrail outputGuardrail;
public GuardedCustomerService(String apiKey) {
this.model = OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-3.5-turbo")
.temperature(0.3)
.maxTokens(500)
.build();
// 使用LangChain4j的AiService代理
this.bot = AiServices.create(CustomerServiceBot.class, model);
this.inputGuardrail = new InputGuardrail();
this.outputGuardrail = new OutputGuardrail();
}
public String processQuery(String userInput) {
System.out.println("用户输入: " + userInput);
// 第一步:输入验证
GuardrailResult inputCheck = inputGuardrail.validateInput(userInput);
if (inputCheck.isBlocked()) {
System.out.println("输入被拦截: " + inputCheck.getReason());
switch (inputCheck.getAction()) {
case REJECT:
return "抱歉,您的查询包含不当内容。请重新表述您的问题。";
case ESCALATE:
return "您的问题已转接给人工客服,请稍等...";
case CORRECT:
return inputCheck.getCorrectedResponse();
default:
return "系统暂时无法处理您的请求。";
}
}
// 第二步:调用AI模型
String aiResponse;
try {
aiResponse = bot.chat(userInput);
System.out.println("AI原始响应: " + aiResponse);
} catch (Exception e) {
return "抱歉,AI服务暂时不可用。";
}
// 第三步:输出验证
GuardrailResult outputCheck = outputGuardrail.validateOutput(aiResponse, userInput);
if (outputCheck.isBlocked()) {
System.out.println("输出被拦截: " + outputCheck.getReason());
return outputCheck.getCorrectedResponse();
}
return aiResponse;
}
}
// 5. 辅助类定义
public static class GuardrailResult {
private boolean blocked;
private String reason;
private String correctedResponse;
private GuardrailAction action = GuardrailAction.REJECT;
// getters and setters
public boolean isBlocked() { return blocked; }
public void setBlocked(boolean blocked) { this.blocked = blocked; }
public String getReason() { return reason; }
public void setReason(String reason) { this.reason = reason; }
public String getCorrectedResponse() { return correctedResponse; }
public void setCorrectedResponse(String correctedResponse) {
this.correctedResponse = correctedResponse;
}
public GuardrailAction getAction() { return action; }
public void setAction(GuardrailAction action) { this.action = action; }
}
public enum GuardrailAction {
REJECT, // 拒绝请求
CORRECT, // 纠正响应
ESCALATE, // 转接人工
ALLOW // 允许通过
}
}- 使用示例和测试
java
public class GuardrailsDemo {
public static void main(String[] args) {
// 初始化防护服务
CustomerServiceGuardrails.GuardedCustomerService service =
new CustomerServiceGuardrails.GuardedCustomerService("your-api-key");
// 测试案例1:有毒输入
System.out.println("=== 测试1: 有毒输入 ===");
String response1 = service.processQuery("你们的产品真是垃圾,白痴设计的!");
System.out.println("响应: " + response1);
// 测试案例2:医疗建议请求
System.out.println("\n=== 测试2: 医疗建议请求 ===");
String response2 = service.processQuery("我头痛应该吃什么药?");
System.out.println("响应: " + response2);
// 测试案例3:合法咨询
System.out.println("\n=== 测试3: 合法咨询 ===");
String response3 = service.processQuery("我的订单状态如何查询?");
System.out.println("响应: " + response3);
// 测试案例4:法律建议请求
System.out.println("\n=== 测试4: 法律建议请求 ===");
String response4 = service.processQuery("有人违反合同,我应该怎么起诉?");
System.out.println("响应: " + response4);
}
}二、内容生成系统Guardrails实现
java
/**
* 内容生成系统防护栏
* 确保生成内容符合准则和法律要求
*/
public class ContentGenerationGuardrails {
// 1. 后处理过滤器
public static class ContentFilter {
private static final List<String> HATE_SPEECH_PATTERNS = Arrays.asList(
"所有[某群体]都", "[某群体]是低等的", "消灭[某群体]"
);
private static final List<String> MISINFO_PATTERNS = Arrays.asList(
"绝对有效", "100%治愈", "官方隐瞒", "独家秘方"
);
public FilterResult filterContent(String generatedContent) {
FilterResult result = new FilterResult(generatedContent, true);
// 仇恨言论检测
for (String pattern : HATE_SPEECH_PATTERNS) {
if (containsPattern(generatedContent, pattern)) {
result.setApproved(false);
result.addIssue("检测到可能的仇恨言论模式");
result.setFilteredContent(
removeSensitiveParts(generatedContent, pattern)
);
}
}
// 错误信息检测
for (String pattern : MISINFO_PATTERNS) {
if (containsPattern(generatedContent, pattern)) {
result.setApproved(false);
result.addIssue("检测到未经证实的主张");
}
}
// 露骨内容检测(简单示例)
if (containsExplicitContent(generatedContent)) {
result.setApproved(false);
result.addIssue("内容不适合所有受众");
result.setFilteredContent("[部分内容因不适合所有受众已被过滤]");
}
return result;
}
private boolean containsPattern(String content, String pattern) {
// 实际实现应使用更复杂的NLP模型
return content.toLowerCase().contains(pattern.toLowerCase());
}
private boolean containsExplicitContent(String content) {
String[] explicitKeywords = {"成人内容", "暴力描述", "血腥细节"};
for (String keyword : explicitKeywords) {
if (content.contains(keyword)) return true;
}
return false;
}
private String removeSensitiveParts(String content, String pattern) {
// 简化实现 - 实际应使用更智能的文本替换
return content.replaceAll("(?i)" + pattern, "[内容已过滤]");
}
}
// 2. 内容生成服务
public static class SafeContentGenerator {
private final ChatLanguageModel model;
private final ContentFilter filter;
public SafeContentGenerator(String apiKey) {
this.model = OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4")
.temperature(0.7)
.build();
this.filter = new ContentFilter();
}
public GeneratedContent generateArticle(String topic, String style) {
// 第一步:生成内容
String prompt = String.format(
"以%s风格写一篇关于'%s'的文章,确保内容准确、客观、适合所有受众。",
style, topic
);
String rawContent = model.generate(prompt);
// 第二步:后处理过滤
FilterResult filterResult = filter.filterContent(rawContent);
// 第三步:记录和审计
logGeneration(topic, filterResult);
return new GeneratedContent(
filterResult.isApproved() ? rawContent : filterResult.getFilteredContent(),
filterResult.isApproved(),
filterResult.getIssues()
);
}
private void logGeneration(String topic, FilterResult result) {
// 记录生成日志,用于审计和模型改进
System.out.printf("主题: %s, 审核状态: %s, 问题: %s%n",
topic,
result.isApproved() ? "通过" : "未通过",
String.join(", ", result.getIssues())
);
}
}
// 3. 数据类
public static class FilterResult {
private final String originalContent;
private String filteredContent;
private boolean approved;
private final List<String> issues;
public FilterResult(String originalContent, boolean initiallyApproved) {
this.originalContent = originalContent;
this.filteredContent = originalContent;
this.approved = initiallyApproved;
this.issues = new ArrayList<>();
}
// getters and setters
public String getOriginalContent() { return originalContent; }
public String getFilteredContent() { return filteredContent; }
public void setFilteredContent(String filteredContent) {
this.filteredContent = filteredContent;
}
public boolean isApproved() { return approved; }
public void setApproved(boolean approved) { this.approved = approved; }
public List<String> getIssues() { return issues; }
public void addIssue(String issue) { issues.add(issue); }
}
public static class GeneratedContent {
private final String content;
private final boolean passedGuardrails;
private final List<String> warnings;
public GeneratedContent(String content, boolean passedGuardrails, List<String> warnings) {
this.content = content;
this.passedGuardrails = passedGuardrails;
this.warnings = warnings;
}
// getters
public String getContent() { return content; }
public boolean isPassedGuardrails() { return passedGuardrails; }
public List<String> getWarnings() { return warnings; }
}
}三、法律研究助手Guardrails实现
java
/**
* 法律研究助手防护栏
* 防止提供明确法律建议,强调咨询专业人士
*/
public class LegalResearchGuardrails {
@AiService
interface LegalResearchAssistant {
@SystemMessage("""
你是一个法律信息检索助手,不是执业律师。
你可以:
1. 解释法律概念和术语
2. 提供法律程序的一般信息
3. 引用相关的法律法规
4. 建议进一步的研究方向
你不能:
1. 提供具体的法律建议
2. 预测案件结果
3. 推荐具体的行动方案
4. 替代律师的专业判断
所有响应必须以免责声明结尾。
""")
String research(@UserMessage String legalQuestion);
}
public static class LegalGuardrail {
public String addDisclaimers(String aiResponse) {
String disclaimer = "\n\n--- 重要免责声明 ---\n" +
"本回答仅提供一般法律信息,不构成法律建议。\n" +
"您的具体情况可能需要专业的法律分析。\n" +
"对于重要的法律事务,请咨询有执业资格的律师。\n" +
"-----------------------------------";
// 检查是否已包含免责声明
if (!aiResponse.contains("免责声明") && !aiResponse.contains("法律建议")) {
return aiResponse + disclaimer;
}
return aiResponse;
}
public boolean isSeekingLegalAdvice(String query) {
String[] advicePatterns = {
"我应该怎么做", "我该起诉吗", "我能赢吗",
"我的权利是什么", "具体建议", "should I sue",
"what should I do", "will I win"
};
for (String pattern : advicePatterns) {
if (query.toLowerCase().contains(pattern.toLowerCase())) {
return true;
}
}
return false;
}
public String redirectToProfessional(String query) {
return "我理解您正在寻求具体的法律指导。作为AI助手,我不能提供法律建议。\n" +
"建议您:\n" +
"1. 咨询当地律师协会获取律师推荐\n" +
"2. 联系法律援助机构(如果符合条件)\n" +
"3. 访问当地法院的自助服务中心\n\n" +
"对于一般法律信息,我可以帮您解释相关概念。";
}
}
public static class GuardedLegalAssistant {
private final LegalResearchAssistant assistant;
private final LegalGuardrail guardrail;
public GuardedLegalAssistant() {
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey("your-api-key")
.modelName("gpt-4")
.temperature(0.1) // 低温度确保更准确的回答
.build();
this.assistant = AiServices.create(LegalResearchAssistant.class, model);
this.guardrail = new LegalGuardrail();
}
public String handleLegalQuery(String userQuery) {
System.out.println("法律查询: " + userQuery);
// 检测是否在寻求法律建议
if (guardrail.isSeekingLegalAdvice(userQuery)) {
System.out.println("检测到寻求法律建议的请求 - 触发防护栏");
return guardrail.redirectToProfessional(userQuery);
}
// 调用AI进行研究
String rawResponse;
try {
rawResponse = assistant.research(userQuery);
} catch (Exception e) {
return "无法处理您的法律查询。请稍后重试或咨询法律专业人士。";
}
// 添加必要的免责声明
return guardrail.addDisclaimers(rawResponse);
}
}
}四、防护栏最佳实践总结
- 分层防护策略
java
public class MultiLayerGuardrailSystem {
/**
* 实现多层防护策略
*/
public static class MultiLayerGuardrail {
// 第一层:输入验证
public boolean validateInput(String input) {
// 检查长度、格式、基本安全性
return !input.isEmpty() && input.length() < 1000;
}
// 第二层:意图识别
public String detectIntent(String input) {
// 使用分类模型识别用户意图
if (input.contains("如何") && input.contains("制作")) {
return "POTENTIALLY_DANGEROUS";
}
return "SAFE";
}
// 第三层:上下文检查
public boolean checkContext(Context context) {
// 检查对话历史、用户身份等
return context.getUserTrustLevel() > TRUST_THRESHOLD;
}
// 第四层:输出过滤
public String filterOutput(String output, String intent) {
// 基于意图的针对性过滤
if ("POTENTIALLY_DANGEROUS".equals(intent)) {
return applyStrictFiltering(output);
}
return output;
}
// 第五层:审计日志
public void auditInteraction(String input, String output,
String userId, boolean passed) {
// 记录所有交互用于后续分析和改进
AuditLog log = new AuditLog(input, output, userId,
new Date(), passed);
auditRepository.save(log);
}
}
}- 监控和评估框架
java
public class GuardrailMonitoring {
/**
* 防护栏性能监控
*/
@Service
public class GuardrailMetrics {
private final MeterRegistry meterRegistry;
// 关键指标
public void recordInputBlocked(String guardrailType) {
meterRegistry.counter("guardrail.input.blocked",
"type", guardrailType).increment();
}
public void recordOutputCorrected(String correctionType) {
meterRegistry.counter("guardrail.output.corrected",
"type", correctionType).increment();
}
public void recordFalsePositive() {
meterRegistry.counter("guardrail.false.positive").increment();
}
public void recordEscalation() {
meterRegistry.counter("guardrail.escalation").increment();
}
}
/**
* 定期评估和优化
*/
@Scheduled(cron = "0 0 1 * * ?") // 每天凌晨1点运行
public void evaluateGuardrailPerformance() {
// 1. 分析误报率
double falsePositiveRate = calculateFalsePositiveRate();
// 2. 检查漏报情况
List<AuditLog> falseNegatives = findFalseNegatives();
// 3. 调整敏感度阈值
if (falsePositiveRate > MAX_ALLOWED_FALSE_POSITIVE) {
adjustSensitivity(falsePositives);
}
// 4. 更新关键词/模式列表
updatePatternsBasedOnNewThreats();
}
}五、部署和配置建议
- 配置文件示例
XML
# application-guardrails.yml
guardrails:
customer-service:
input-validation:
enabled: true
toxic-words-file: /config/toxic-words.txt
max-input-length: 1000
output-filtering:
enabled: true
medical-advice:
action: reject
message: "请咨询医疗专业人士"
legal-advice:
action: redirect
redirect-to: "/legal-professionals"
content-generation:
hate-speech:
detection-model: bert-hate-speech
threshold: 0.8
action: filter
misinformation:
fact-checking-api: "https://factcheck.example.com"
required: true
monitoring:
audit-logging:
enabled: true
retention-days: 90
metrics:
export-to: prometheus
update-frequency: 30s- 测试策略
java
public class GuardrailTestSuite {
@Test
public void testToxicInputDetection() {
GuardedCustomerService service = new GuardedCustomerService("test-key");
// 测试各种有毒输入
String[] toxicInputs = {
"你这个愚蠢的机器人",
"产品真是垃圾",
"我要投诉你们这群白痴"
};
for (String input : toxicInputs) {
String response = service.processQuery(input);
assertTrue(response.contains("不当内容") ||
response.contains("重新表述"));
}
}
@Test
public void testMedicalAdviceGuardrail() {
// 测试医疗建议防护
String medicalQuery = "我发烧39度应该吃什么药?";
String response = service.processQuery(medicalQuery);
assertTrue(response.contains("不能提供医疗建议"));
assertTrue(response.contains("咨询医生"));
assertFalse(response.contains("建议你服用"));
}
}这些代码示例展示了如何使用LangChain4j实现多层防护栏系统。关键要点:
-
1、防御深度:实现输入验证、意图识别、输出过滤等多层防护
-
2、可配置性:通过配置文件调整防护策略和敏感度
-
3、可观测性:建立完整的监控、审计和评估体系
-
4、持续改进:基于实际使用数据不断优化防护规则
实际部署时,建议:
-
1、根据具体业务需求定制防护规则
-
2、定期审查和更新关键词/模式列表
-
3、建立人工审核流程处理边缘案例
-
4、监控防护栏性能,平衡安全性和用户体验
结论
实施有效的 guardrails 代表了对负责任的 AI 开发的核心承诺,超越了单纯的技术执行。这些安全模式的战 略性应用使开发者能够构建既稳健又高效的智能 Agent,同时优先考虑可信度和有益结果。采用分层防御机 制,整合从输入验证到人工监督的各种技术,可以产生一个对意外或有害输出具有弹性的系统。持续评估和 改进这些 guardrails 对于适应不断演变的挑战并确保 Agent 系统的持久完整性至关重要。最终,精心设计的 guardrails 使 AI 能够以安全有效的方式服务于人类需求。
参考文献
-
GoogleAISafetyPrinciples:https://ai.google/principles/
-
OpenAIAPIModerationGuide:https://platform.openai.com/docs/guides/moderation
-
Promptinjection:https://en.wikipedia.org/wiki/Prompt_injection