1 背景
VGG由牛津大学视觉几何组(Visual Geometry Group)的研究员Karen Simonyan、Andrew Zisserman于2014年提出,并发布于论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》。该网络在 ILSVRC-2014(ImageNet大规模视觉识别挑战赛,ImageNet Large Scale Visual Recognition Challenge)上获得了第二名,虽不敌当时的冠军GoogleNet,但其在深度设计和参数优化方面为后续模型提供了关键参考。
2 原理
VGG的核心思想就是VGG块,如下图所示,将连续的一个或多个卷积层与后面的汇聚层组合打包成一个块,使得网络结构得到了进一步统一,大大减少了深层网络的复杂性。原先由若干卷积层、汇聚层和全连接层组合实现的网络在引入块的思想后,简化为若干个VGG块+全连接层的两段结构。

具体来看,一个VGG块中的卷积层和汇聚层都是"预制菜",为了统一封装,卷积层中的卷积核大小固定为3*3,填充固定为2,步幅固定为1,根据前面的知识可知,经过这样一个卷积层以后特征图的大小不变(n+2-3)/1+1=n);汇聚层的窗口大小固定为2*2,步幅固定为2,同理,特征图经过该汇聚层以后大小减半((n-2)/2+1=n/2)。另一方面,多个3*3的卷积层的堆叠可以在获得更大感受野的同时经过更多的激活函数,比单纯的5*5、7*7等大卷积核的效果更好。
3 实现
3.1 模型定义
下述代码实现了VGG块的定义。可以看到,VGG块中可以调节的参数只有卷积层数、输入通道数和输出通道数,其中对于通道数量上的变换是在第一个卷积层完成的。
python
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)下面定义的超参数用于控制每个VGG块的卷积层数和输出通道数。
python
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))下面代码利用上述超参数实现了VGG,由于该实现中包含8个卷积层(1+1+2+2+2)和三个全连接层,所以叫做VGG-11。
python
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)下面代码展示了每一层的BCHW,由于封装了多个VGG块,每个VGG块会被看成一个层,只展示一个输出结果。
python
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)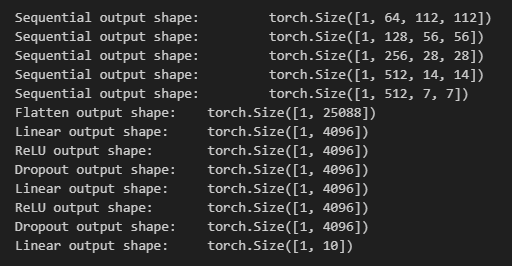
3.2模型训练
由于VGG-11的计算量较大,所以这里实现了一个参数规模更小的模型,做法就是将超参数conv_arch中的通道数缩小4倍('//'符号在整数除法中表示除完后向下取整)。
python
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
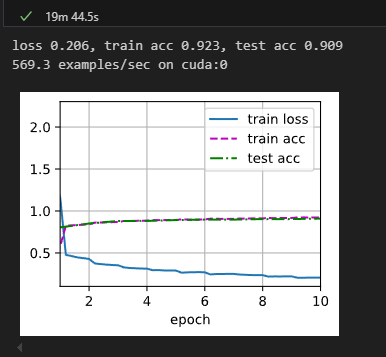
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())