目录
[一、 项目背景](#一、 项目背景)
源码获取方式在文章末尾
一、 项目背景
项目实现的核心思路
将复杂问题拆解为多个简单模块,每个模块聚焦单一功能。优先选择成熟开源工具或框架,避免重复造轮子。开发过程中采用渐进式迭代,逐步完善功能。
技术选型建议
选择学习曲线平缓的技术栈,如Python+Django/Flask用于Web开发,Vue.js/React用于前端界面。数据库方面MySQL或PostgreSQL都是稳定易用的选择。云服务可考虑阿里云/腾讯云的基础套餐。
开发流程优化
采用敏捷开发模式,将大需求分解为2周左右的小周期。每日进行简短站会同步进度,使用Jira/Trello等工具管理任务。代码版本控制推荐Git+GitHub/GitLab组合。
文档与协作规范
建立清晰的API文档标准,使用Swagger/YAPI等工具自动生成。代码注释率保持在30%以上,关键算法需有详细说明。团队统一编码风格,ESLint/Prettier等工具可辅助格式化。
测试与部署策略
单元测试覆盖率不低于70%,接口测试使用Postman自动化。采用CI/CD流水线自动构建部署,Docker容器化保证环境一致性。监控方面接入Prometheus+Grafana基础指标看板。
常见问题解决方案
技术瓶颈时优先查阅官方文档和Stack Overflow。性能问题从数据库索引和缓存入手优化。团队协作问题通过明确接口契约和定期代码Review解决。保持每周技术分享交流机制。
持续改进方法
每个迭代周期预留20%时间处理技术债务。建立用户反馈快速响应通道,重要需求48小时内给出方案。定期评估技术架构,每季度进行系统性优化升级。
二、技术思路
系统架构遵循分层解耦设计原则:
数据层:基于Scrapy-Redis构建分布式爬虫,突破微博反爬机制,实现多节点异步抓取,数据清洗后持久化至MySQL集群,采用时序分区表优化海量文本存储;
计算层:基于SnowNLP的情感分析模型进行并行化改造,通过Celery任务队列实现异步计算,结合规则引擎(如正则匹配表情符号、网络缩略语)增强短文本特征提取;
服务层:采用Flask+Swagger构建RESTful API,支持OAuth2.0鉴权与流量控制,通过Redis缓存热点查询结果,响应时间低于200ms;
应用层:前端采用Vue.js+ECharts实现交互式可视化,支持情感演化热力图、主题词共现网络、用户影响力拓扑等多模态分析视图。
三、算法介绍
核心算法基于SnowNLP库,其情感分析模块通过训练中文语料库构建概率模型,计算文本情感得分(0-1,趋近1为正面)。针对微博短文本特性,优化了分词算法并融入网络新词库提升准确率。结合TF-IDF提取关键词,通过LDA主题模型聚类分析热点话题,最终融合情感与主题结果实现多粒度舆情解读。
四、项目创新
1、轻量级实时分析:结合Flask与SnowNLP实现低延迟处理,支持动态数据更新;
2、多维度可视化:引入地域分布、用户画像叠加情感数据,突破单一文本分析局限;
3、自适应模型优化:针对微博表情符号、网络用语设计规则引擎,补强SnowNLP在非规范文本中的情感判断能力,提升准确率。
五、开发技术介绍
编辑器:Pycharm
前端框架:HTML,CSS,JAVASCRIPT,Echarts
数据处理框架:FLASK
数据存储:Mysql
编程语言:Python
舆情分析算法:snowNlp舆情分析算法
数据可视化:Echarts
六、项目展示
登录/注册  项目注册
项目注册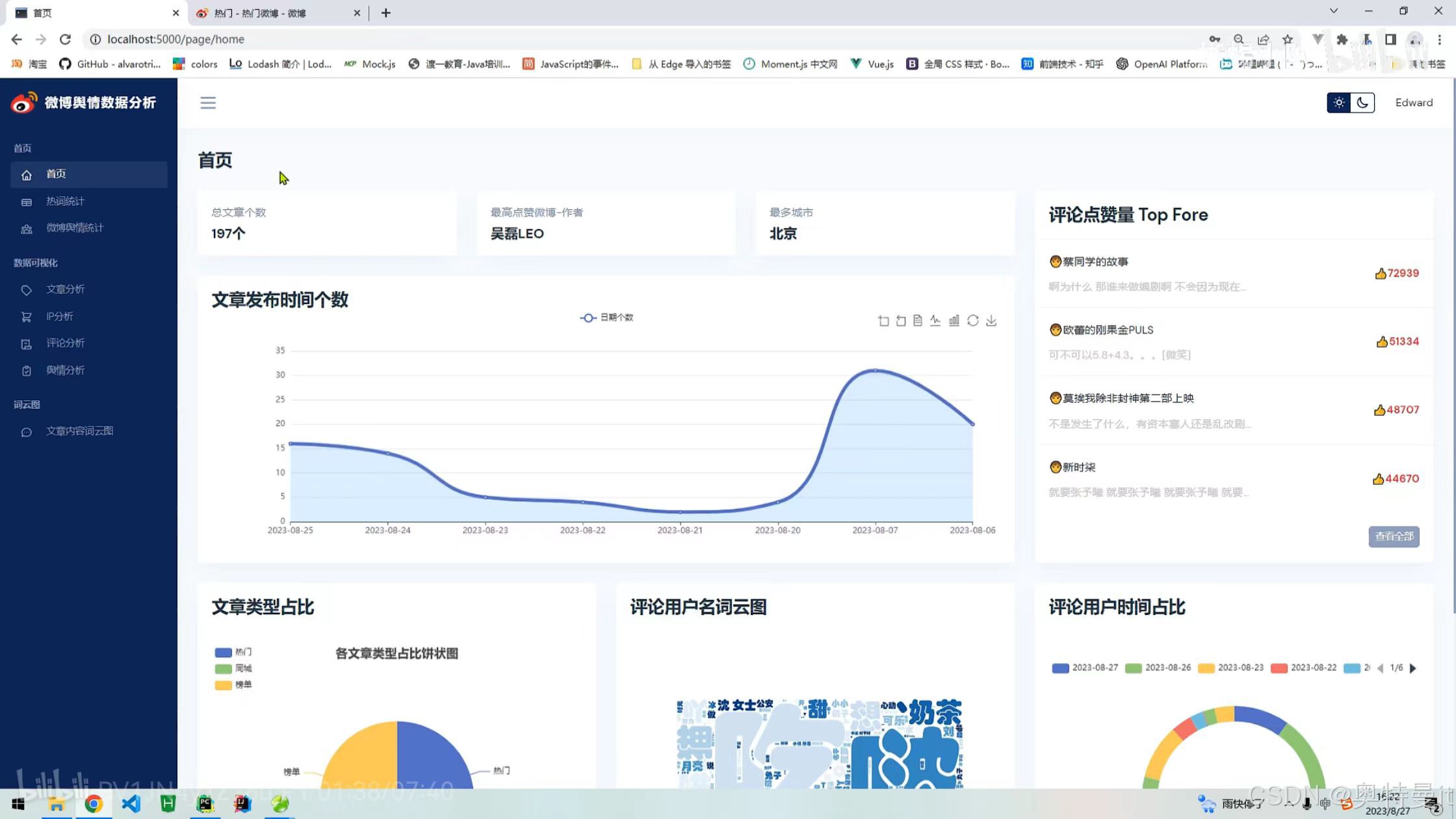
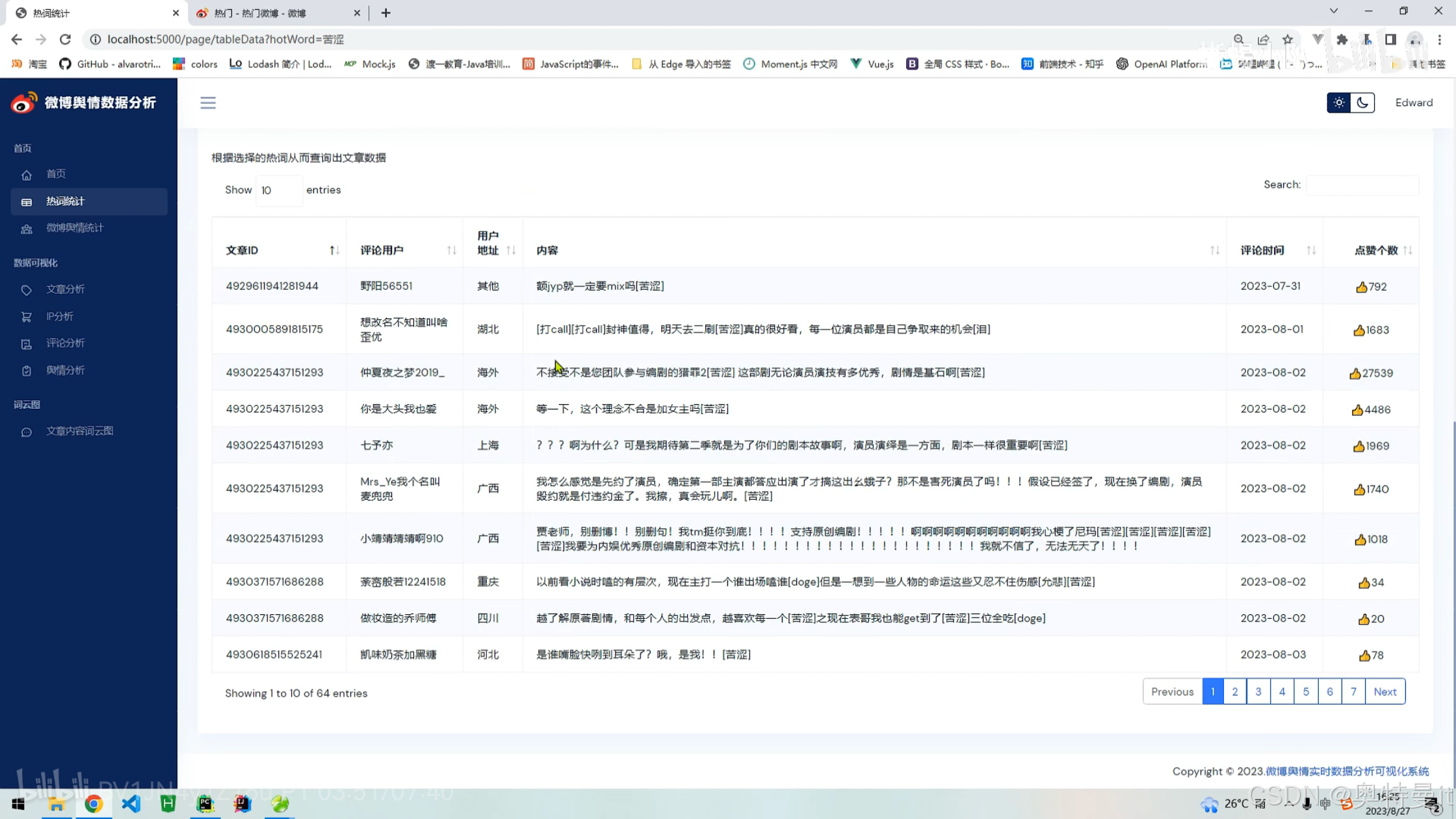
 热词统计
热词统计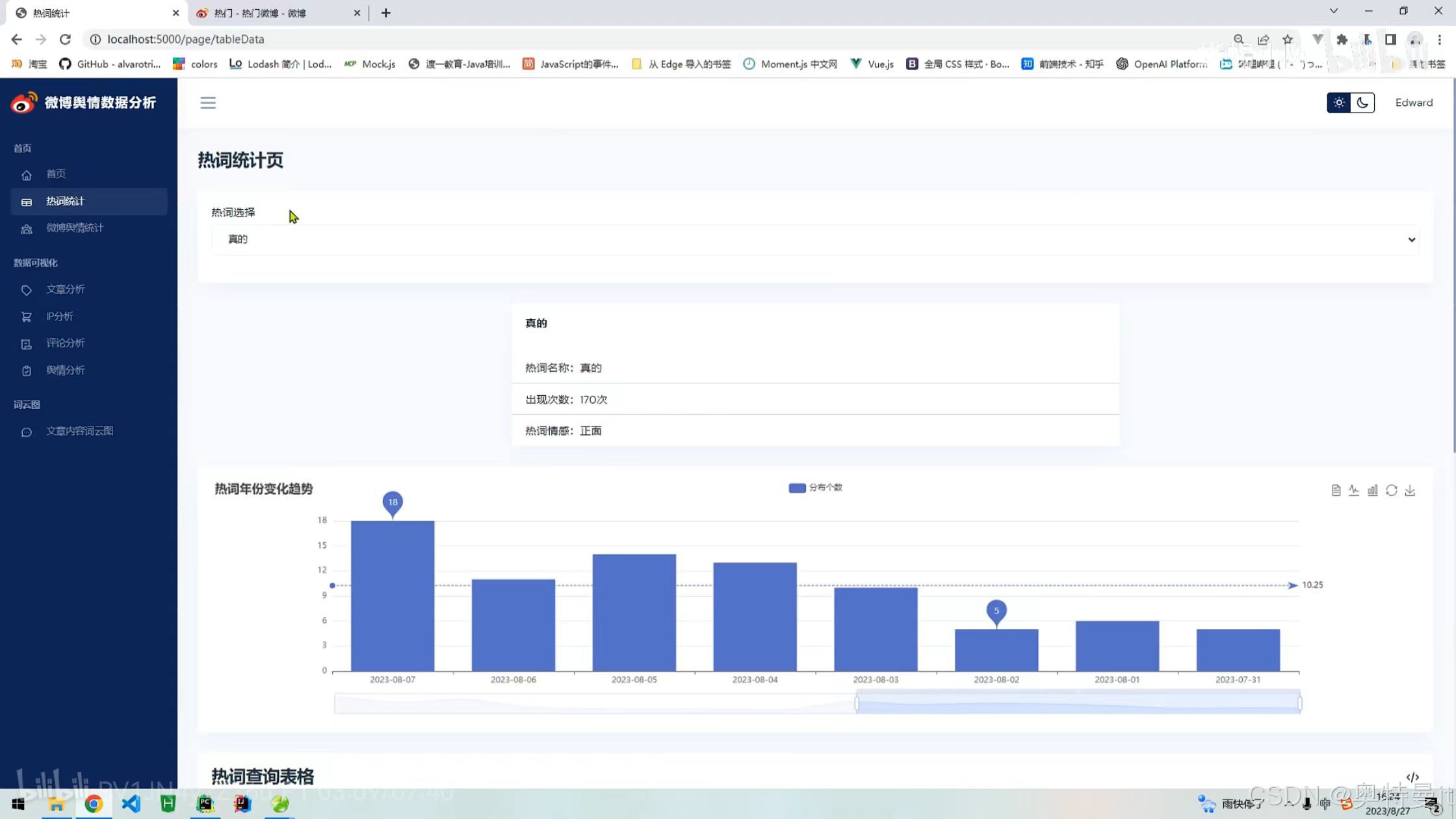
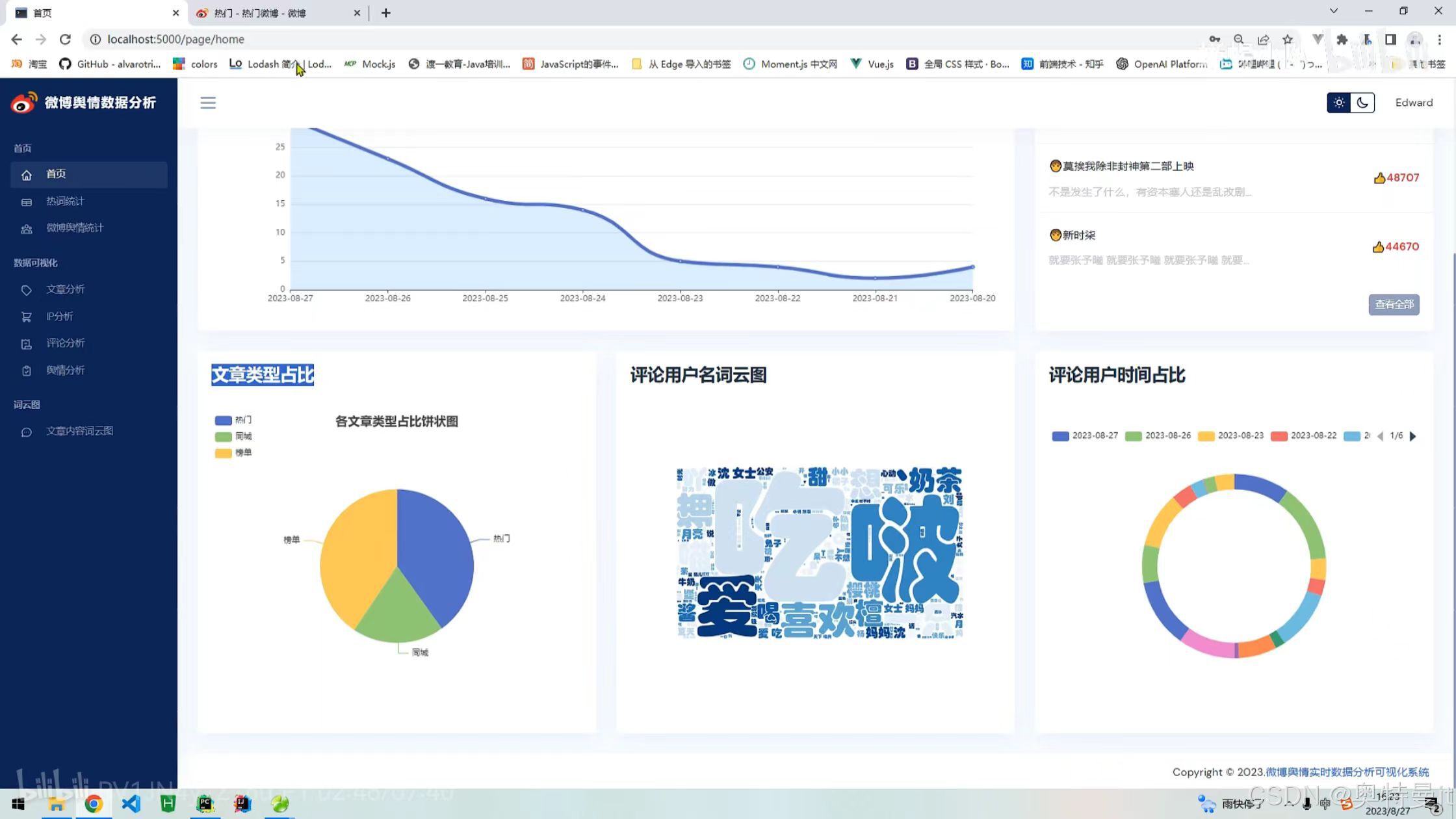
 微博舆情统计
微博舆情统计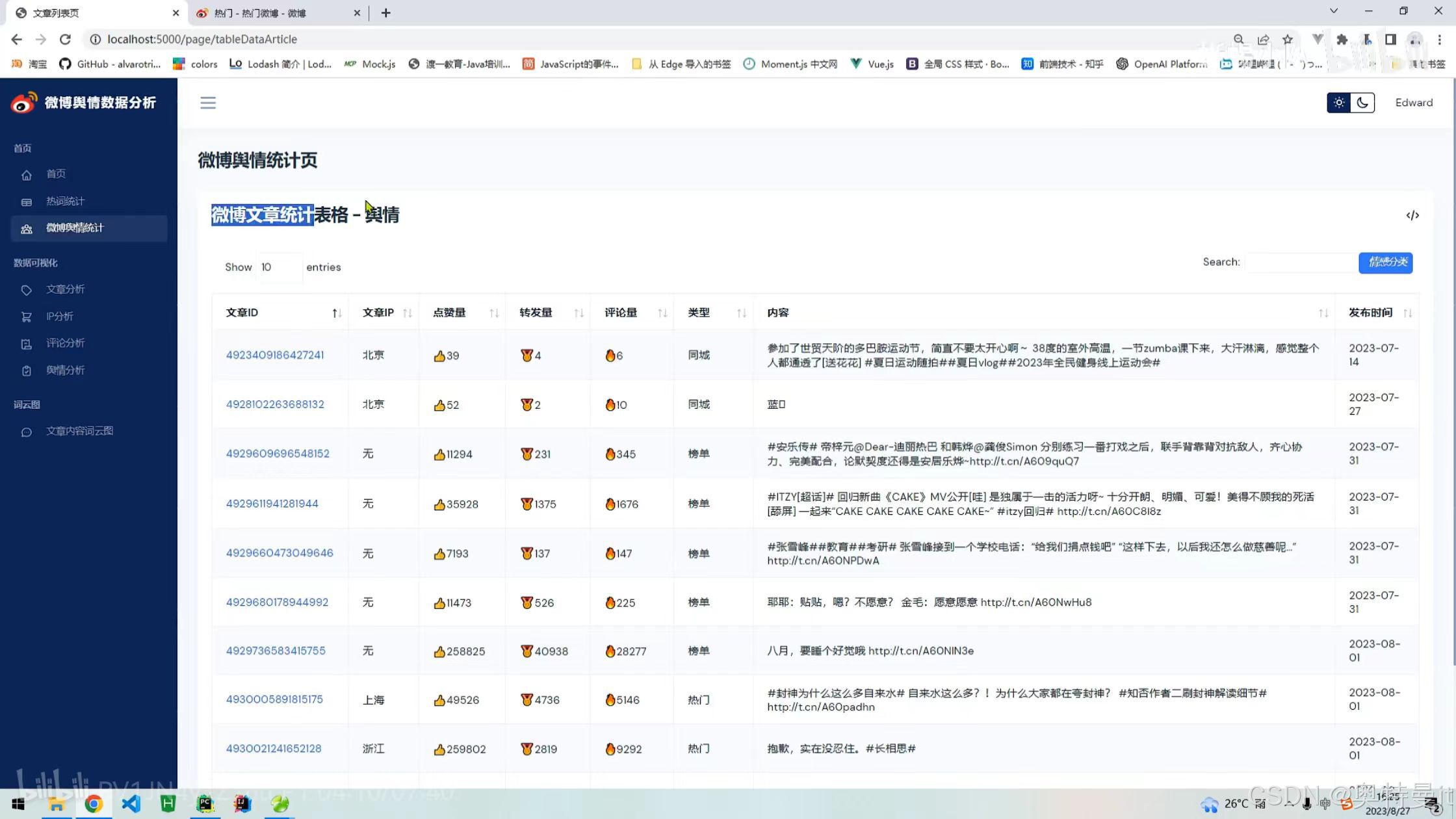 文章分析
文章分析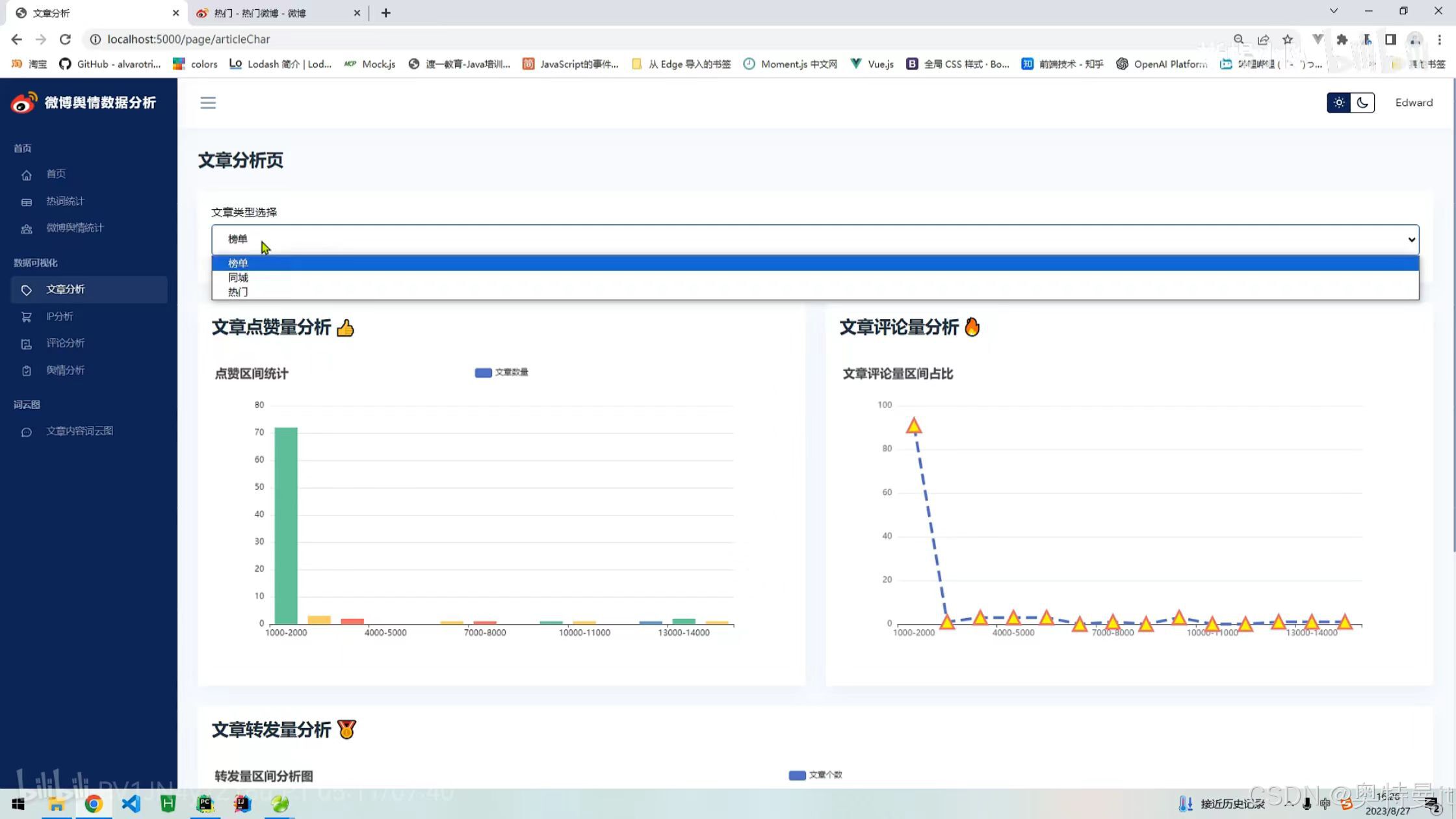 IP/位置分析
IP/位置分析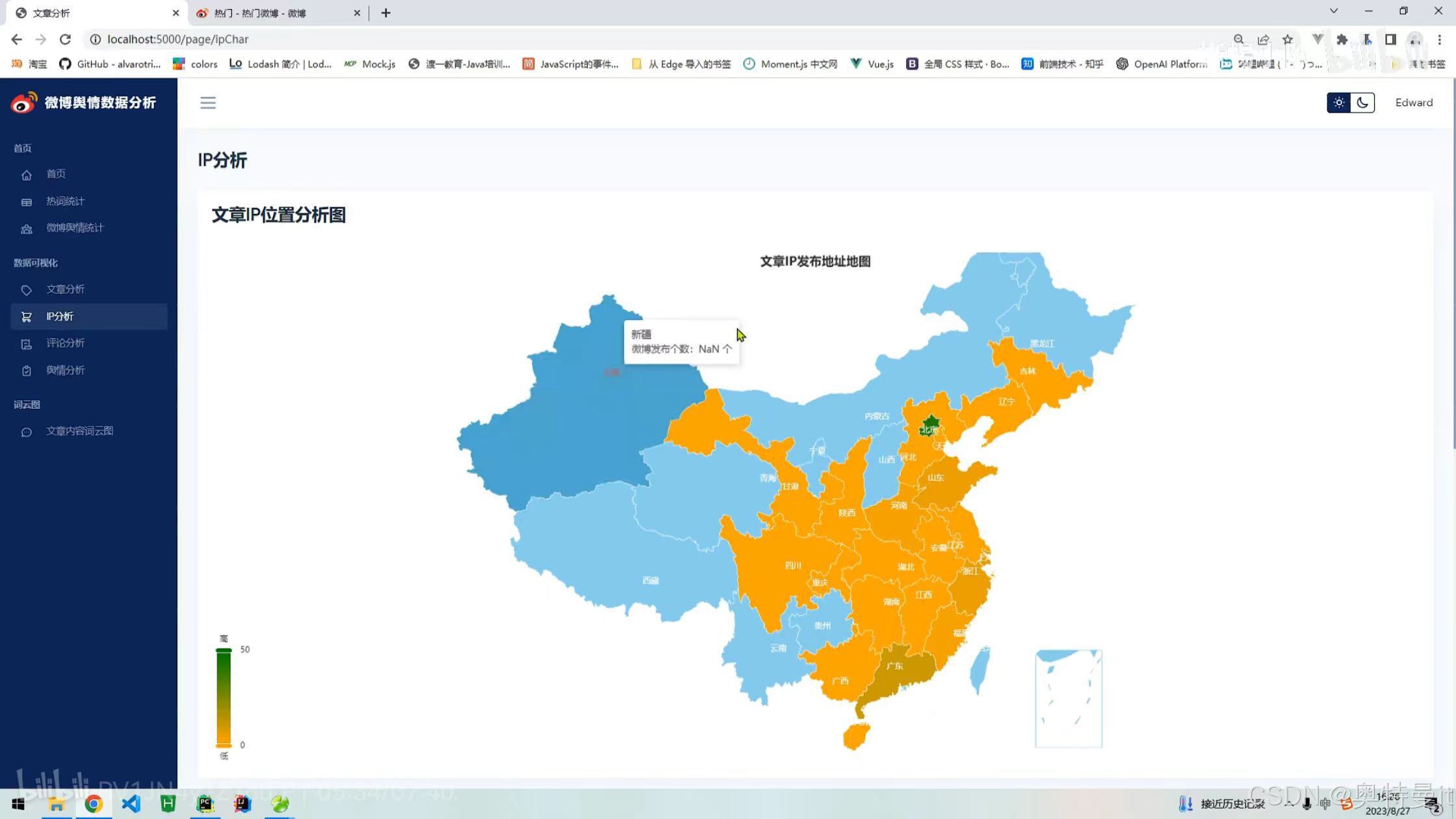 评论分析
评论分析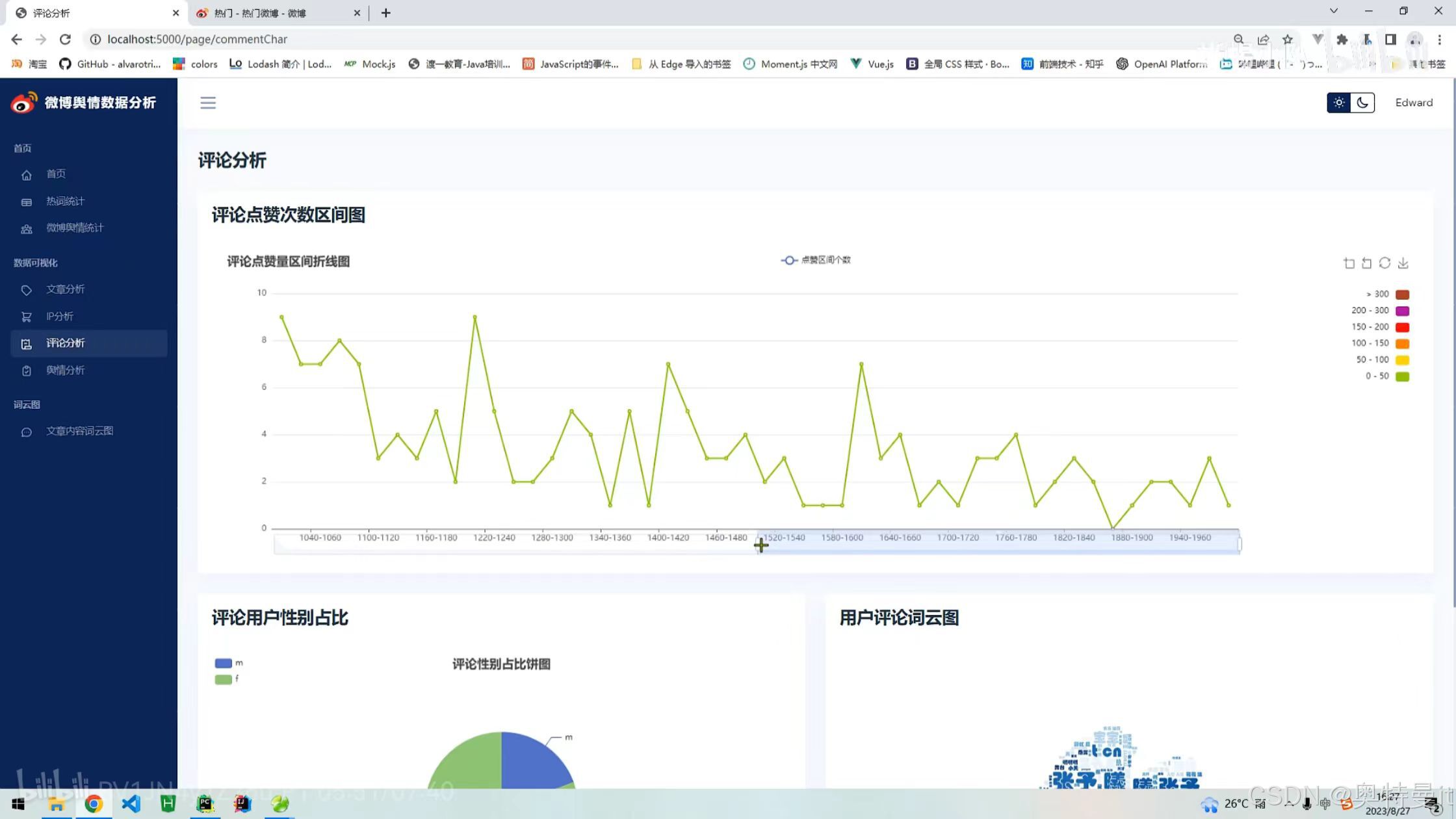 舆情分析
舆情分析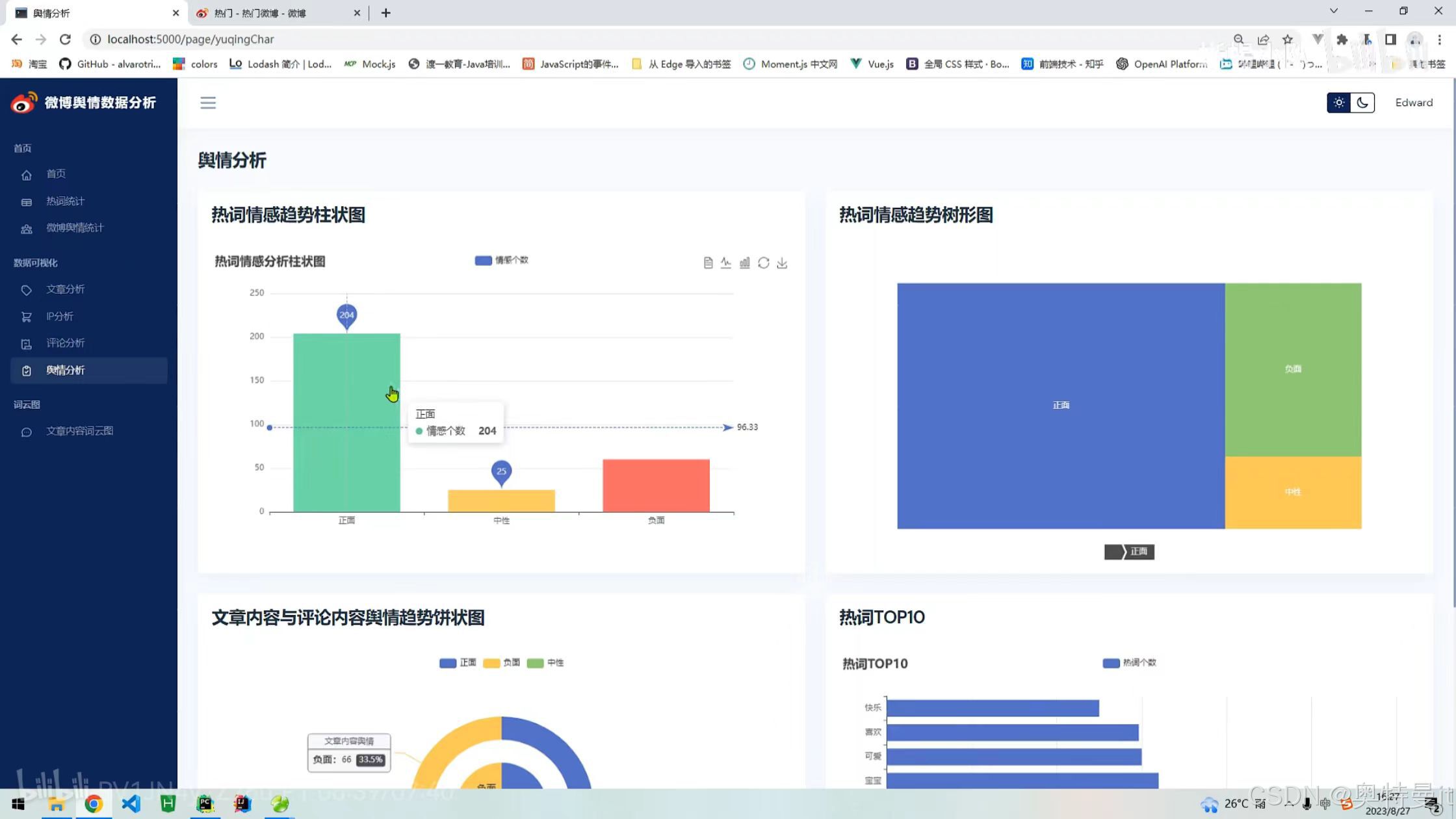
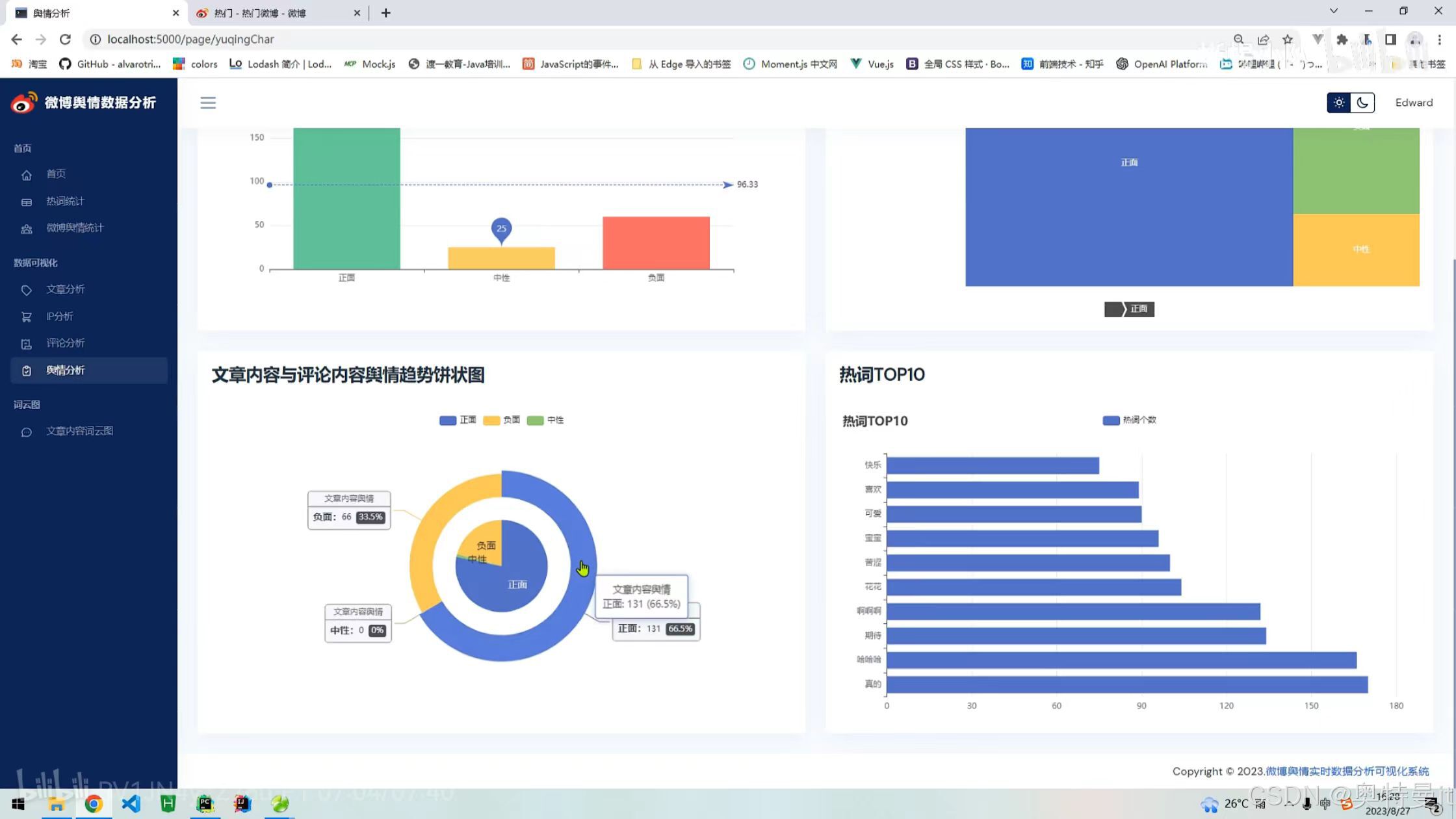 文章内容词云图
文章内容词云图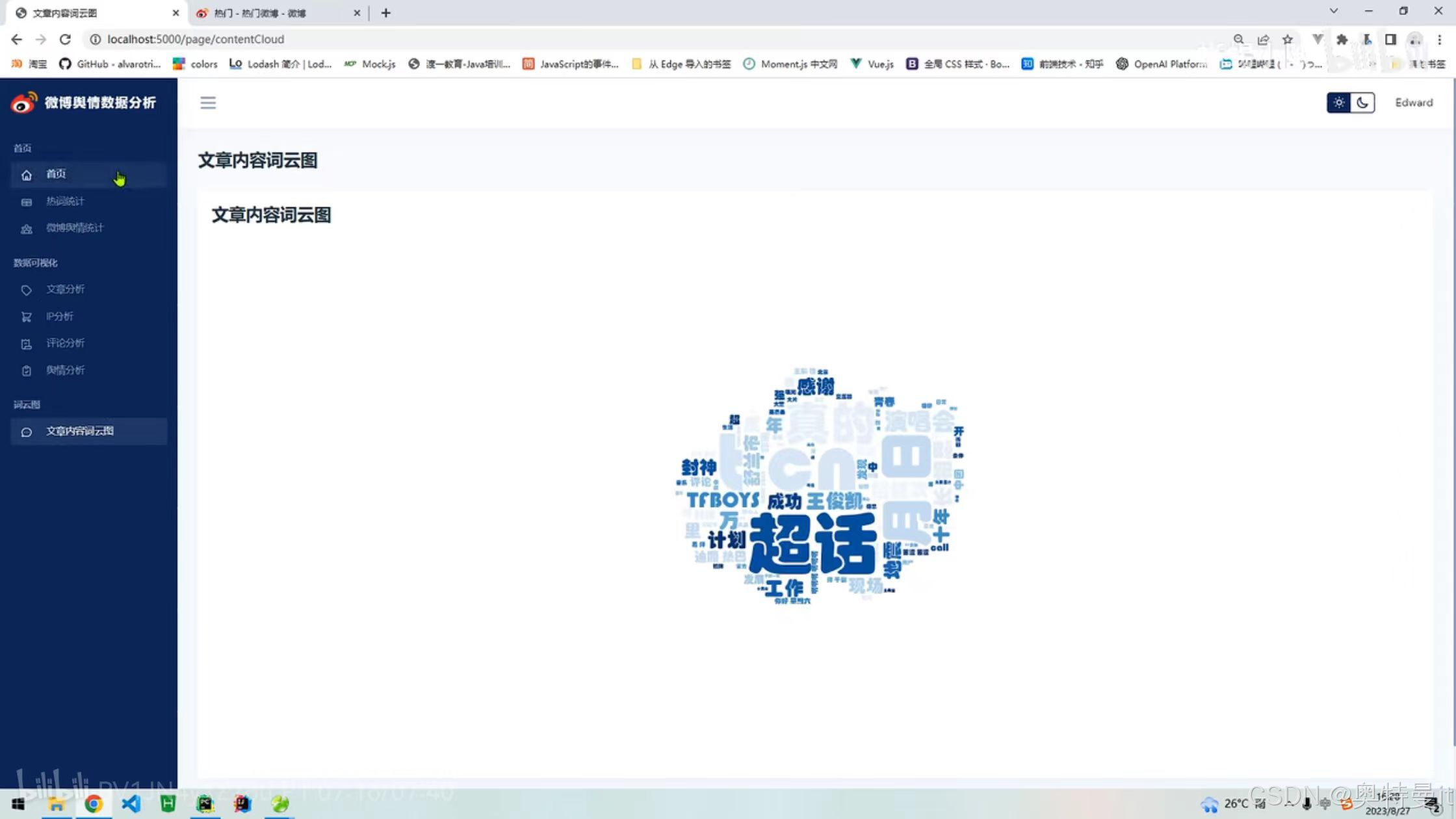
七、启动文档 
八、权威教学视频链接
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。