概述
Dify API 使用 Flask-SQLAlchemy 作为 ORM 框架,通过 SQLAlchemy 与 PostgreSQL 数据库进行交互。本文档详细说明数据库连接、Session 管理和缓存机制的工作原理。
技术栈
-
ORM 框架: Flask-SQLAlchemy (基于 SQLAlchemy)
-
数据库: PostgreSQL
-
连接池: SQLAlchemy Connection Pool
-
并发模型: Gevent (协程)
-
Session 管理: scoped_session (线程/协程本地存储)
架构组件
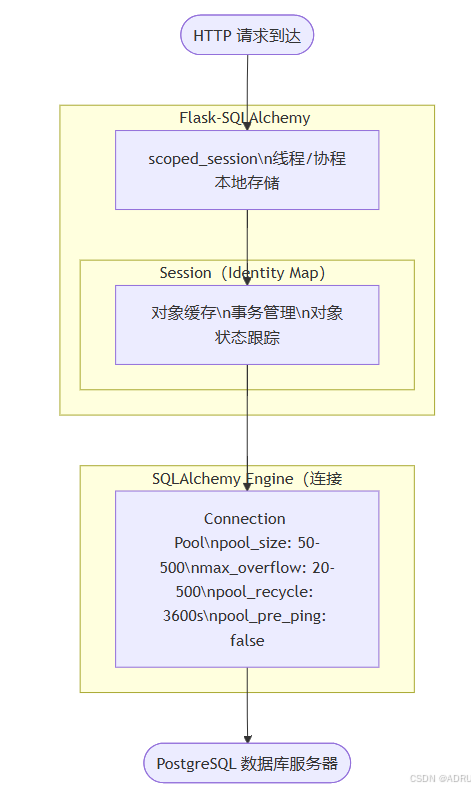
1. 数据库连接层
2. 关键组件说明
Flask-SQLAlchemy (`db`)
# models/engine.py from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy(metadata=metadata)
-
作用: Flask 扩展,封装 SQLAlchemy 功能
-
Session 管理: 使用 `scoped_session` 实现请求级别的 Session
-
配置: 通过 Flask 应用配置传递
scoped_session
-
作用: 为每个线程/协程创建独立的 Session 实例
-
存储方式: 使用线程本地存储 (Thread Local Storage)
-
生命周期: 与请求生命周期绑定
Session (Identity Map)
-
作用: 管理数据库查询和对象状态
-
Identity Map: 确保同一主键的对象在同一 Session 中只有一个实例
-
缓存范围: Session 级别(请求级别)
Connection Pool
-
作用: 管理数据库连接的创建、复用和回收
-
配置位置: `configs/middleware/init.py`
-
默认配置:
-
pool_size: 50 -
max_overflow: 20 -
pool_recycle: 3600 秒 -
pool_pre_ping: false
数据库连接方式
1. 标准方式:`db.session`
# 方式 1: 直接使用 db.session app_model = db.session.query(App).filter(App.id == app_id).first()
特点:
-
使用 Flask-SQLAlchemy 管理的 Session
-
Session 通过
scoped_session实现线程/协程本地存储 -
在请求结束时,Flask-SQLAlchemy 会自动调用
db.session.remove()
- 在 Gevent 环境下可能存在问题(见下文)
生命周期:
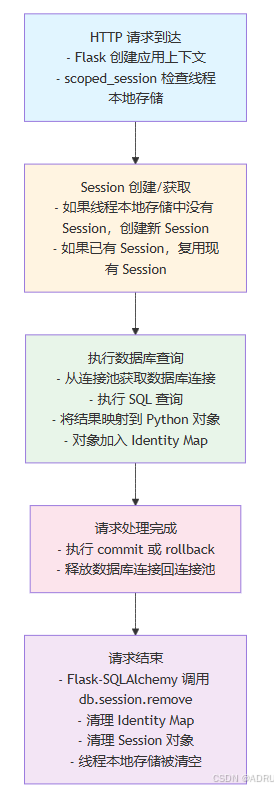
HTTP 请求到达 ↓ Flask 应用上下文创建 ↓ db.session 获取(从 scoped_session 获取或创建) ↓ 执行查询操作 ↓ 请求结束 ↓ Flask-SQLAlchemy 调用 db.session.remove() ↓ Session 被清理(理论上)
2. 显式方式:`with Session()`
# 方式 2: 显式创建 Session from sqlalchemy.orm import Session with Session(db.engine, expire_on_commit=False) as session: app_model = session.query(App).filter(App.id == app_id).first()
特点:
-
显式创建独立的 Session 对象
-
使用
with语句自动管理 Session 生命周期 -
每次都会创建新的 Session,不受 scoped_session 影响
- 推荐在 Gevent 环境下使用
生命周期
with Session(...) 进入 ↓ 创建新的 Session 对象 ↓ 执行查询操作 ↓ with 语句退出 ↓ Session 自动关闭和清理
3. 连接池配置
# configs/middleware/__init__.py SQLALCHEMY_POOL_SIZE: 50 # 连接池大小 SQLALCHEMY_MAX_OVERFLOW: 20 # 超出池大小的最大连接数 SQLALCHEMY_POOL_RECYCLE: 3600 # 连接回收时间(秒) SQLALCHEMY_POOL_PRE_PING: false # 连接前是否 ping
连接池工作原理:
-
连接获取: 从连接池获取可用连接,如果没有可用连接且未达到 `max_overflow`,则创建新连接
-
连接复用: 同一 Session 内的多个查询可能复用同一个连接
-
连接回收: 连接使用超过 `pool_recycle` 时间后,会被自动回收
-
连接检查: 如果启用 `pool_pre_ping`,会在使用前检查连接是否有效
Session 生命周期
1. 标准生命周期(无 Gevent)
2. Gevent 环境下的特殊行为
关键问题: Gevent 使用协程而非线程,可能影响线程本地存储的行为。
# app.py from gevent import monkey monkey.patch_all() # 这会 patch 线程本地存储
影响:
-
线程本地存储可能被复用: Gevent 的协程切换可能导致线程本地存储被意外复用
-
Session 清理可能失效: `db.session.remove()` 可能不会按预期清理 Session
-
Identity Map 可能保留: 上次请求的对象可能残留在 Identity Map 中
实际测试结果:
-
db.session.remove()后,Session ID 仍然相同 -
不调用
remove()时,Session 被复用 -
App 对象从 Identity Map 中获取,可能返回旧数据
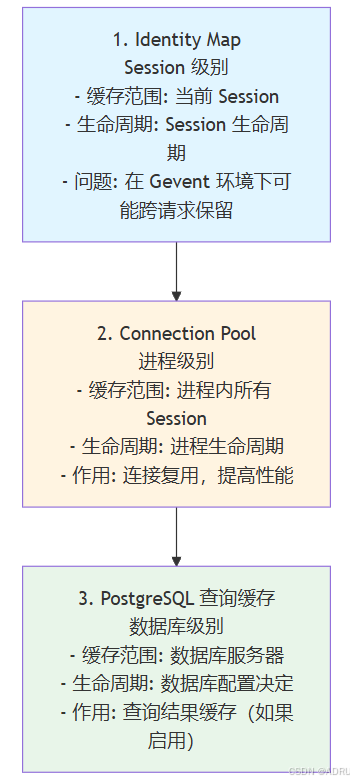
缓存机制
1. Identity Map(对象级缓存)
定义: Identity Map 是 SQLAlchemy Session 的核心机制,确保在同一 Session 中,同一个数据库记录(通过主键标识)只有一个 Python 对象实例。
工作原理:
第一次查询: session.query(App).filter(App.id == "123").first() → 从数据库查询 → 创建 App 对象 → 对象加入 Identity Map (key: (App, "123")) 第二次查询(同一 Session): session.query(App).filter(App.id == "123").first() → 检查 Identity Map → 发现已有对象 (App, "123") → 直接返回缓存的对象(不查询数据库)
缓存范围:
-
Session 级别: 只在当前 Session 内有效
-
请求级别: 在标准 Flask 应用中,Session 与请求生命周期绑定
-
不跨请求: 理论上不同请求的 Session 是独立的
缓存生命周期:
Session 创建 ↓ Identity Map 初始化(空) ↓ 执行查询 ↓ 对象加入 Identity Map ↓ 后续查询从 Identity Map 获取(如果存在) ↓ Session 关闭/清理 ↓ Identity Map 清空
2. 连接池缓存
定义: 连接池缓存数据库连接,避免频繁创建和销毁连接。
缓存范围:
-
进程级别: 连接池在进程启动时创建,进程内所有 Session 共享
-
跨请求: 不同请求的 Session 可能复用同一个数据库连接
连接生命周期:
进程启动 ↓ 创建连接池(pool_size 个连接) ↓ 请求到达 ↓ 从连接池获取连接 ↓ 执行查询 ↓ 释放连接回连接池 ↓ 连接在池中保持(直到 pool_recycle 或进程结束)
3. 缓存层级总结
与 PostgreSQL/MySQL 的区别
1. 连接方式差异
|----|------------|-------|
| 特性 | PostgreSQL | MySQL |
| 驱动 | psycopg2 / psycopg3 | mysqlclient / PyMySQL |
| 连接字符串 | `postgresql://...` | `mysql://...` |
| Gevent 支持 | psycogreen (需要 patch) | 原生支持较好 |
| 连接池 | SQLAlchemy 统一管理 | SQLAlchemy 统一管理 |
结论: 在 SQLAlchemy 层面,PostgreSQL 和 MySQL 的使用方式基本相同,主要区别在于底层驱动。
2. Session 管理差异
|----|------------|-------|
| 特性 | PostgreSQL | MySQL |
| Session 管理 | SQLAlchemy 统一管理 | SQLAlchemy 统一管理 |
| Identity Map | 完全相同 | 完全相同 |
| 连接池 | 完全相同 | 完全相同 |
结论: Session 管理机制与数据库类型无关,完全由 SQLAlchemy 统一管理。
3. Gevent 兼容性差异
PostgreSQL:
# app.py import psycogreen.gevent psycogreen.gevent.patch_psycopg() # 需要显式 patch
MySQL:
# MySQL 驱动通常原生支持 Gevent,无需额外 patch
影响: PostgreSQL 在 Gevent 环境下需要额外的 patch,可能影响线程本地存储的行为。
4. 实际差异总结
|----|------------|-------|----|
| 方面 | PostgreSQL | MySQL | 说明 |
| ORM 使用 | 完全相同 | 完全相同 | SQLAlchemy 统一接口 |
| Session 管理 | 完全相同 | 完全相同 | SQLAlchemy 统一管理 |
| 连接池 | 完全相同 | 完全相同 | SQLAlchemy 统一管理 |
| Gevent 支持 | 需要 patch | 原生支持 | 可能影响 Session 清理 |
| 性能 | 相似 | 相似 | 主要取决于连接池配置 |
结论: 在 SQLAlchemy 层面,PostgreSQL 和 MySQL 的使用方式基本相同。主要区别在于底层驱动和 Gevent 兼容性。
实际测试结果分析
测试场景
通过自定义脚本进行了实际测试,结果如下:
1. with Session() 方式
测试结果:
-
Session ID 不同:
139927218906912vs139927291491392 -
App 对象 ID 不同:
139927218666624vs139927218661056 -
Identity Map 独立: 每次都是新的空 Map
结论:
-
✅ 每次创建新 Session
-
✅ App 对象不同
-
✅ 不受 Gevent 影响
2. db.session 方式
测试结果:
-
第一次查询: Session ID =
139927452964656 -
调用
remove()后: Session ID =139927452964656(相同!) -
第三次查询(不调用 remove): Session ID =
139927452964656(相同!) -
App 对象被复用:
app_objects_are_same: true
关键发现:
-
❌
db.session.remove()后 Session ID 仍然相同 -
❌ 不调用
remove()时 Session 被复用 -
❌ App 对象从 Identity Map 中获取,可能返回旧数据
结论:
-
在 Gevent 环境下,
db.session的 Session 清理机制失效 -
Session 和 Identity Map 可能跨请求保留
-
这解释了为什么在
wraps_cached.py中可能拿到上次请求的缓存数据
3. refresh() 行为
测试结果:
-
refresh()后对象 ID 不变(符合预期) -
属性值从数据库重新加载
结论:
-
✅
refresh()可以强制从数据库重新加载对象 -
✅ 这是解决缓存问题的有效方法
最佳实践建议
1. 推荐方式:使用`with Session()`
# 推荐:显式创建 Session from sqlalchemy.orm import Session with Session(db.engine, expire_on_commit=False) as session: app_model = session.query(App).filter(App.id == app_id).first() if app_model: session.refresh(app_model) # 可选:强制刷新
优点:
-
✅ 每次创建新 Session,避免复用
-
✅ 自动管理 Session 生命周期
-
✅ 不受 Gevent 影响
-
✅ 代码清晰,易于理解
2. 如果使用`db.session`,必须调用 `refresh()`
# 可接受:但需要 refresh app_model = db.session.query(App).filter(App.id == app_id).first() if app_model: db.session.refresh(app_model) # 必须:强制刷新
原因:
-
在 Gevent 环境下,
db.session可能被复用 -
Identity Map 可能保留上次请求的对象
-
refresh()强制从数据库重新加载,确保数据最新
3. 连接池配置说明
-
pool_size: 根据实际并发量设置,避免过大导致数据库连接数过多 -
max_overflow: 处理突发流量 -
pool_recycle: 定期回收连接,避免长时间连接导致的超时问题 -
pool_pre_ping: 在使用前检查连接是否有效,避免使用已断开的连接