目录
1:项目简介
因为本人使用的是jdk17、mysql8、springboot3.x 所以这里选择XXL-JOB3.X以上版本
这是的调度中心只有一个,执行器也是只有一个仅仅只作为案例演示
2:springboot3整合xxjob
2.1:导入依赖
XML
<!--导入xxl-job-core核心依赖 将springboot项目作为调度器-->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>3.3.2</version>
</dependency>2.2:配置xxl-jop文件
TypeScript
#xxljob配置
#调度中心地址 多个用逗号分隔 http://ip:端口/xxl-job-admin,http://ip:端口/xxl-job-admin
xxl.job.admin.addresses=http://127.0.0.1:8090/xxl-job-admin
#执行器AppName需要跟调度中心配置的吻合
xxl.job.executor.appname=xxlJop1
#执行器令牌需要跟调度中心配置的吻合 xxl.job.accessToken=hu_123
xxl.job.accessToken=hu_123
#执行器IP(默认为空表示自动获取)
xxl.job.executor.ip=
#执行器地址(默认为空表示自动获取)
xxl.job.executor.address=
#执行器端口(默认为9999,冲突则修改)
xxl.job.executor.port=9999
#执行器日志路径
xxl.job.executor.logpath=./data/applogs/xxl-job/jobhandler
#执行器日志保存天数
xxl.job.executor.logretentiondays=303:springboot项目代码
3.1:编写xxl-job的config
java
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
//xxl-job配置类
@Configuration
public class XxlJobConfig {
private static final Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job 执行器,配置初始化.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}3.2:编写xxl-job的执行器
这是一个简单的执行器
java
/**
* bean模式的调度任务
*/
@Component
public class MyJobHandlerBean1 {
Logger logger = LoggerFactory.getLogger(MyJobHandlerBean1.class);
private final UserService userService;
@Autowired
public MyJobHandlerBean1(UserService userService) {
this.userService = userService;
}
@XxlJob(value = "demoJobHandler1", init = "init", destroy = "destroy")
public String demoJobHandler1(String param) throws Exception {
String s = "TimeJob1执行器8091端口的MyJobHandlerBean1,有返回值是传递参数:"+param+":"+userService.list().toString();
logger.info(s);
return s;
}
public void init() {
logger.info("TimeJob1 执行器8091端口的MyJobHandlerBean1, init.");
}
public void destroy() {
logger.info("TimeJob1 执行器8091端口的MyJobHandlerBean1, destroy.");
}
}然后启动项目
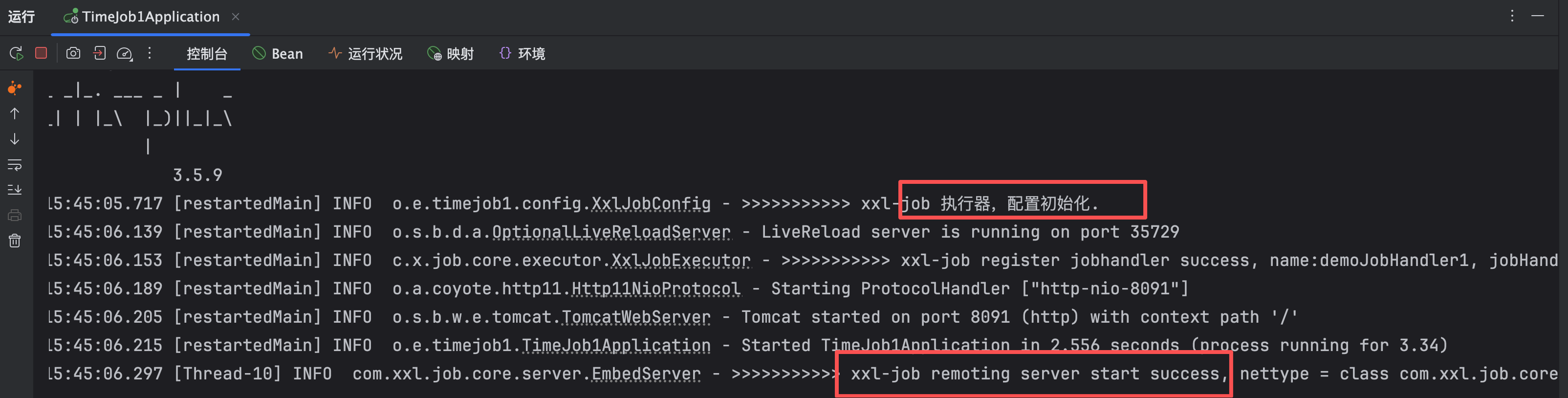
4:在调度中心配置
4.1:配置执行器
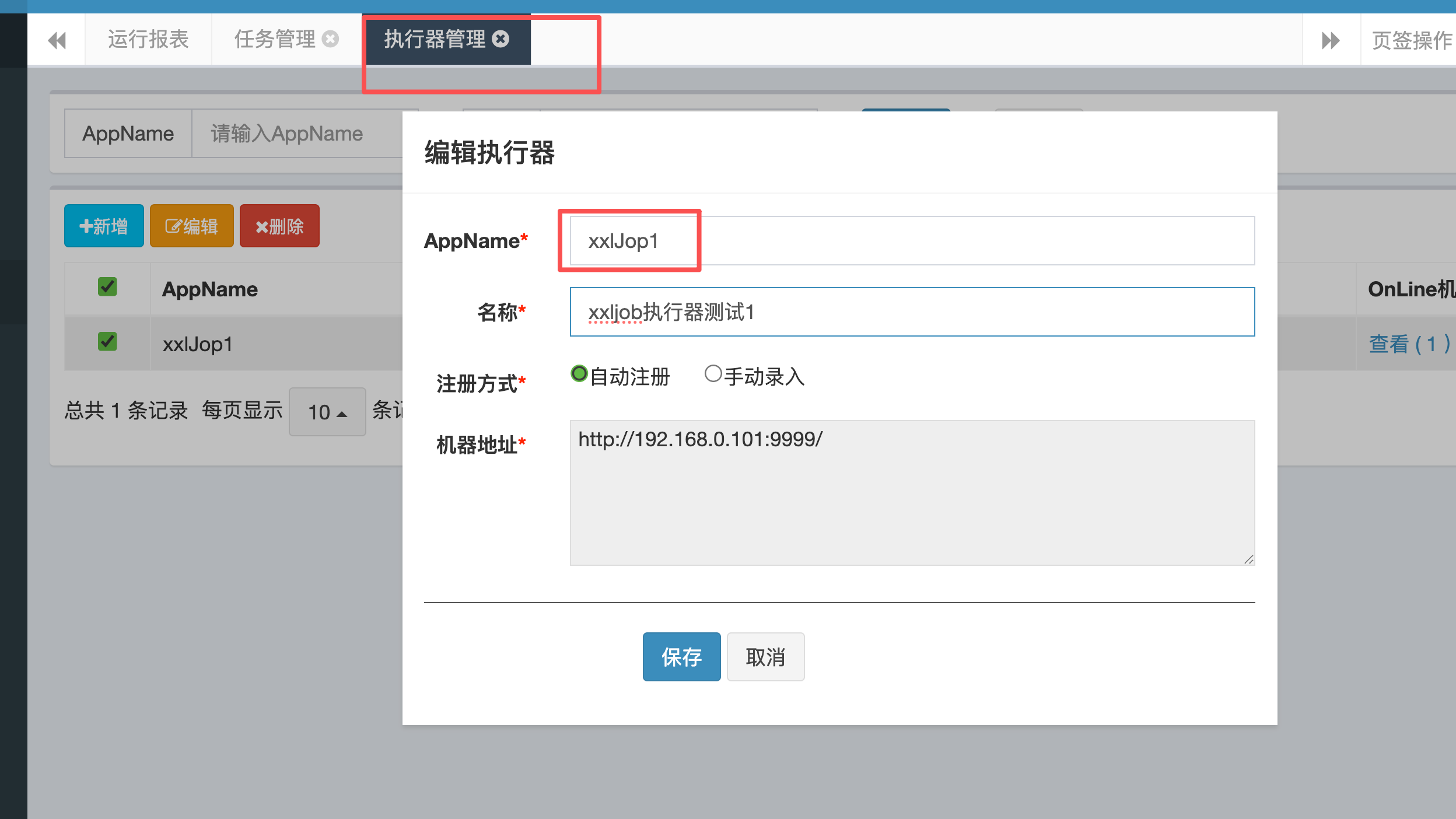
4.2:配置执行器
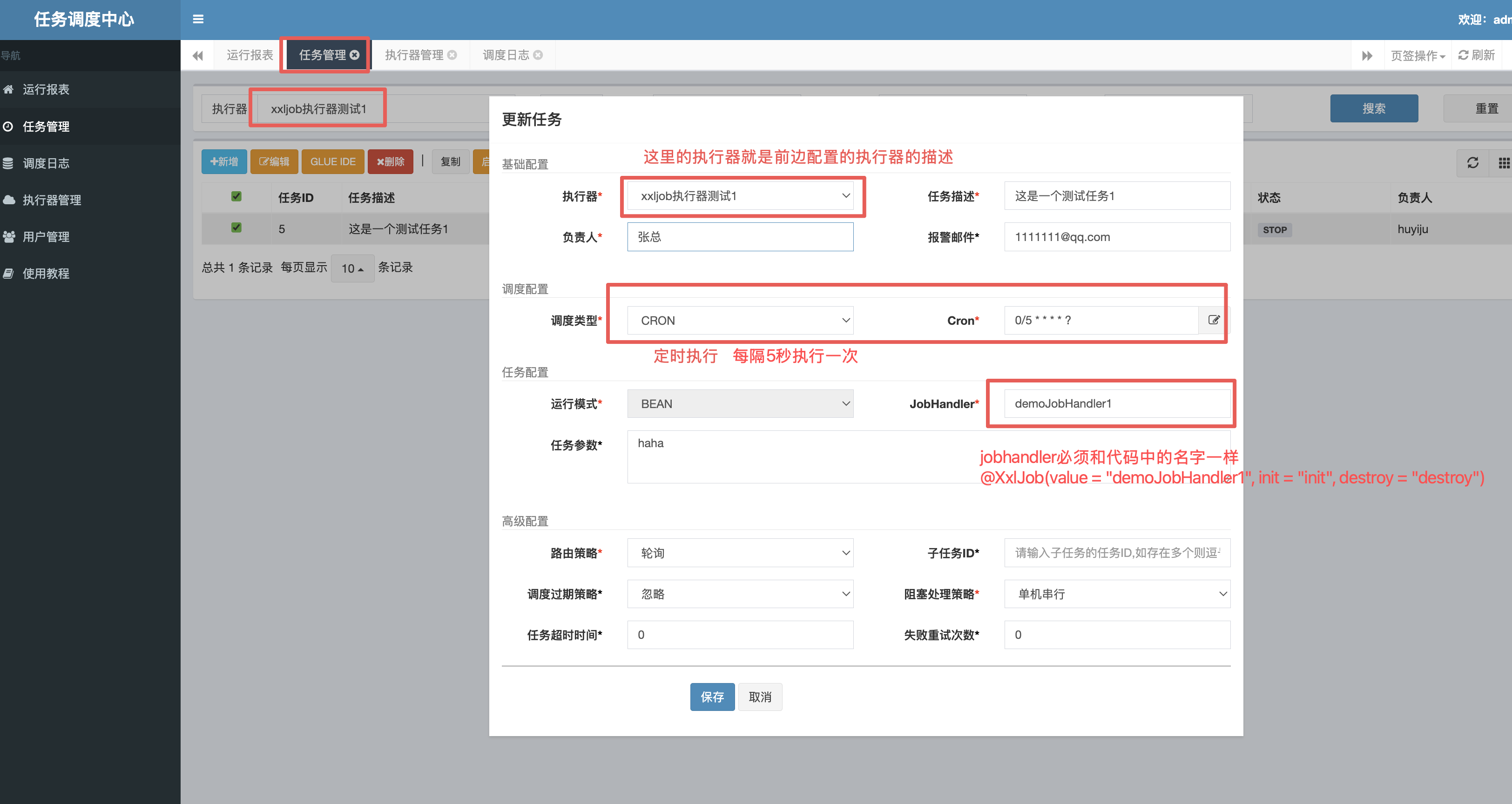
4.3:执行器开始执行
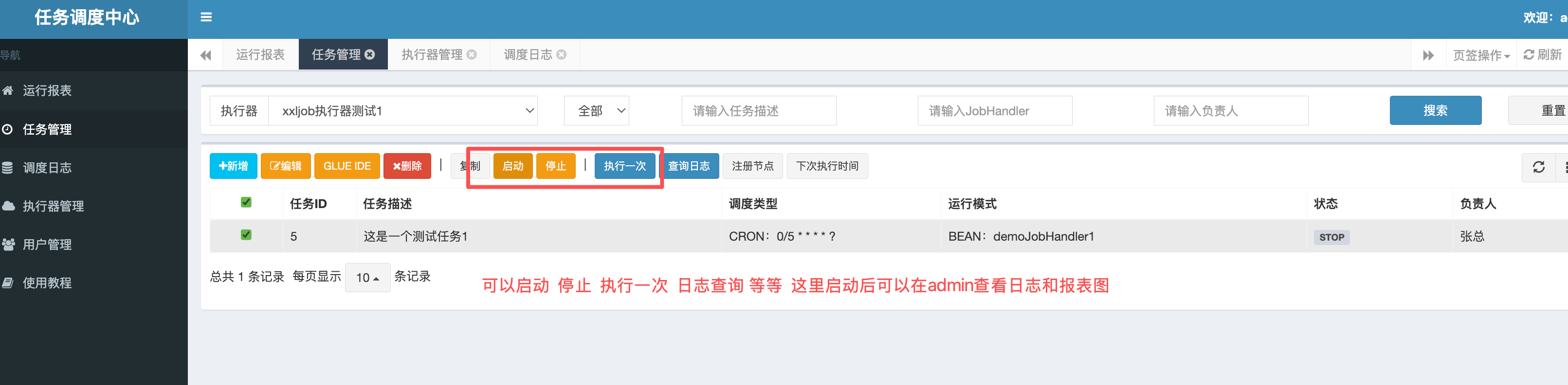
4.4:执行结果截图
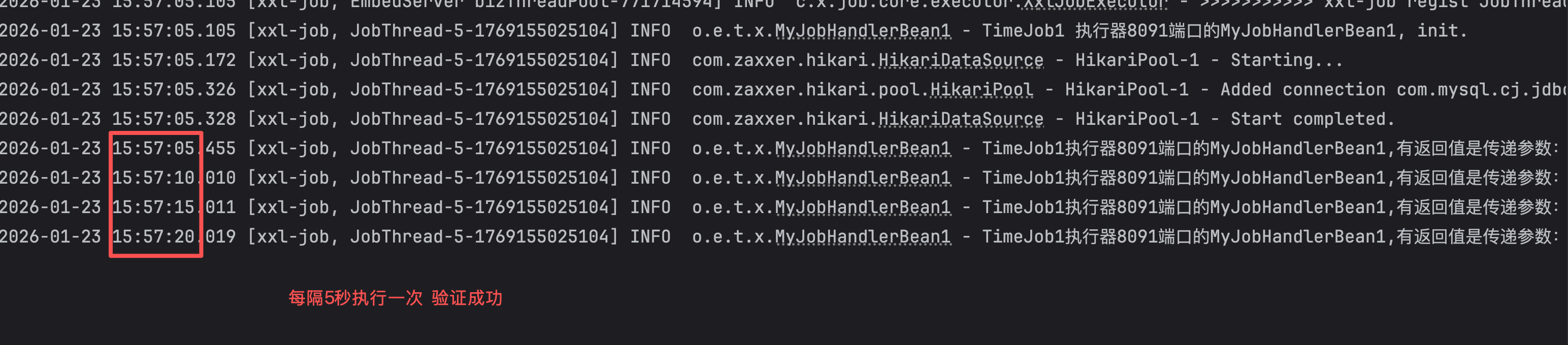
springboot的项目是执行器,可以执行一会重启,就会发现,重启后该项目会重新注册到调度中心,即使项目重启了,定时任务也能接着执行
5:======分割线、集群=====
在之前我们只是简单的演示了单个调度器、后台的springboot执行器也是只有一个,这在实际开发中是不可能的,后台都是集群我们接着演示集群下的各种功能,可以将上边的项目启动两个实例 端口是8091、8092
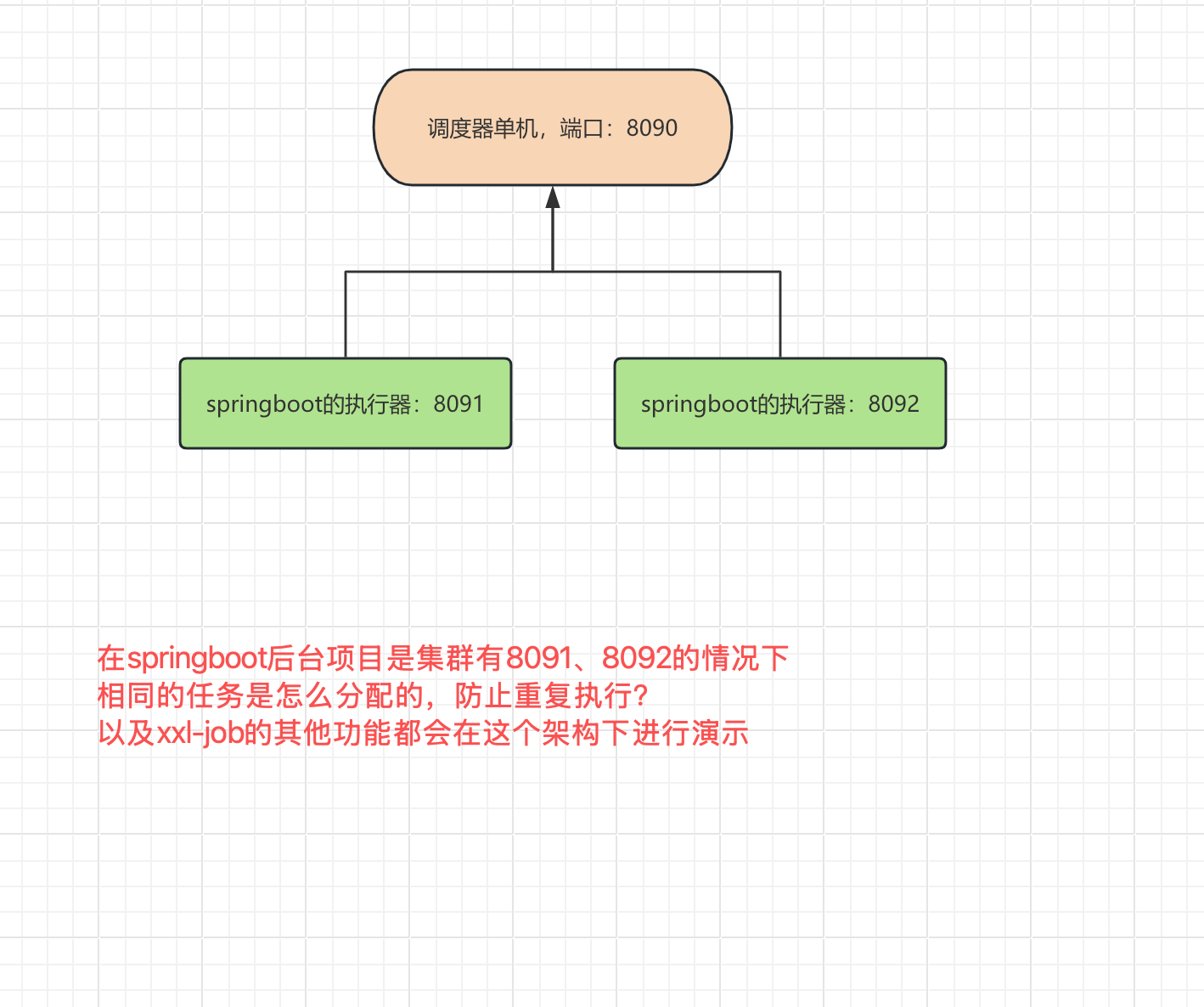
6:集群的任务展示
由于集群的代码都是一样的这里就不重复粘贴了,读者可以重启多个项目设置成不同的端口
7:集群怎么实现防重复执行
7.1:调度器实现
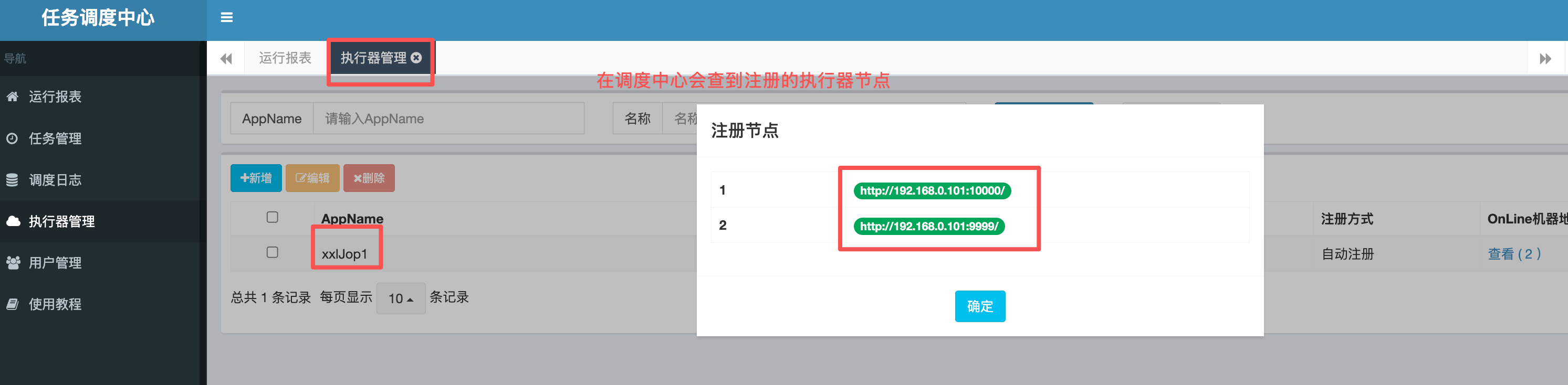
在传统的集群中我们可以想到数据库锁的方式,集群去获取锁,谁获取到了锁,谁执行定时任务。
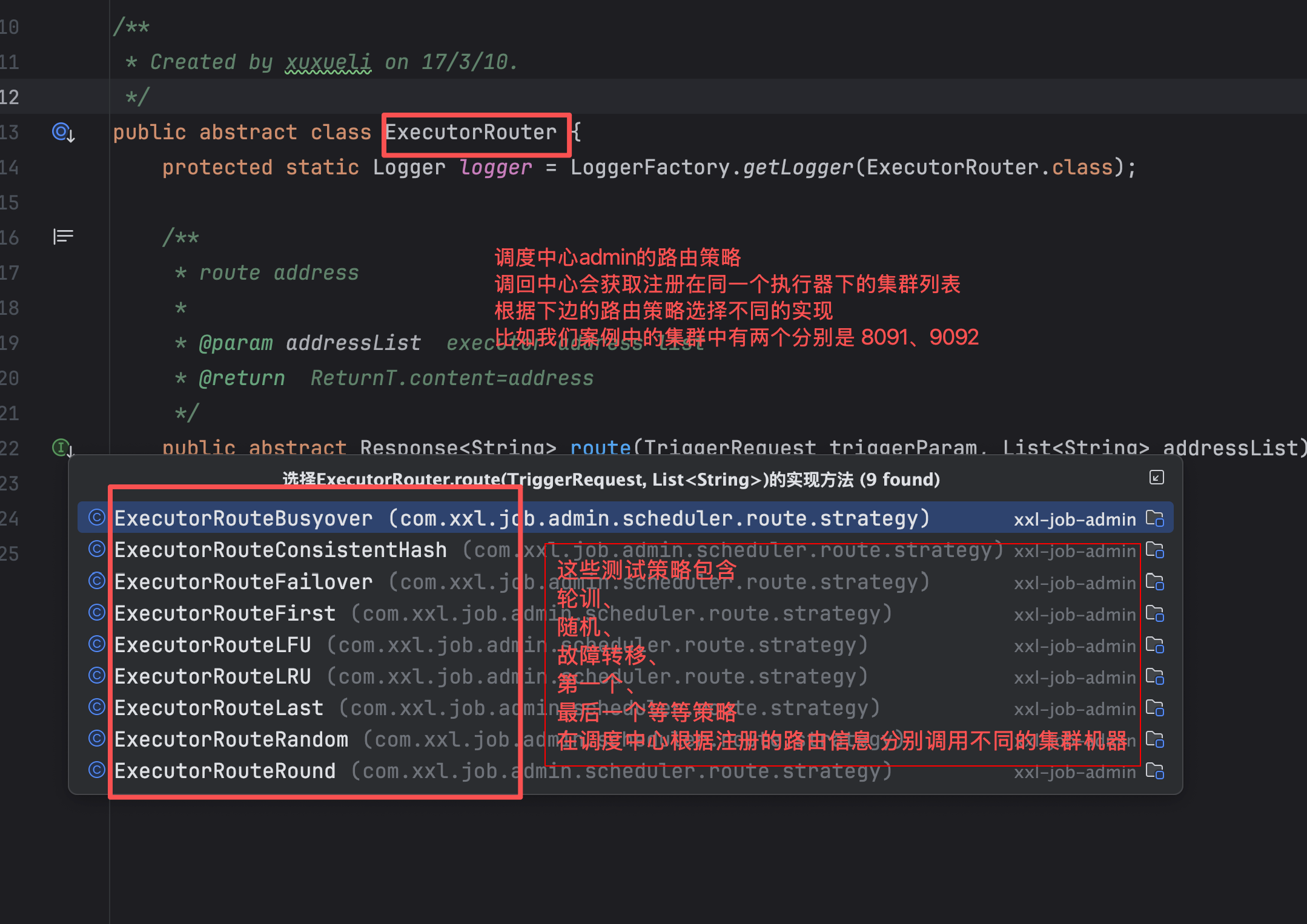
但是xxl-job实际上CS架构。在调度中心admin(服务端)会获取到注册的执行器(客户端),根据执行器集群列表,根据不同的策略,调度中心根据设置的定时任务规则去调用执行器,也就是我们的集群服务,调度中心注册节点如图
调度中心的路由源码ExecutorRouter
7.2:执行器实现
handler.execute(); // 执行核心业务逻辑这段代码就会执行我们注解定义的方法了
TypeScript
package com.xxl.job.core.thread;
import com.xxl.job.core.openapi.model.CallbackRequest;
import com.xxl.job.core.openapi.model.TriggerRequest;
import com.xxl.job.core.context.XxlJobContext;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.executor.XxlJobExecutor;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.log.XxlJobFileAppender;
import com.xxl.tool.response.Response;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.util.Date;
import java.util.Set;
import java.util.concurrent.*;
/**
* 任务执行线程类(核心)
* 作用:为每个任务ID创建唯一的执行线程,负责接收触发请求、防重、串行执行任务、处理超时/异常、回调结果
* 核心设计:单任务单线程 + 队列串行消费 + logId去重,保证单节点内同一任务不并发/重复执行
* @author xuxueli 2016-1-16 19:52:47
*/
public class JobThread extends Thread{
// 日志记录器:用于打印线程运行日志,便于问题排查
private static final Logger logger = LoggerFactory.getLogger(JobThread.class);
// 核心标识:任务ID(一个JobThread对应一个jobId,单任务单线程的核心依据)
private int jobId;
// 任务处理器:封装实际的业务执行逻辑(如Bean模式的JobHandler、GLUE脚本处理器)
private IJobHandler handler;
// 任务触发请求队列:所有触发请求先入队,由单线程串行消费,保证串行执行
private LinkedBlockingQueue<TriggerRequest> triggerQueue;
// 去重集合:基于ConcurrentHashMap实现的线程安全Set,防止同一TRIGGER_LOG_ID重复触发
// TRIGGER_LOG_ID是调度中心触发任务时生成的唯一标识,避免重复推送同一请求
private Set<Long> triggerLogIdSet;
// 线程停止标记(volatile保证多线程可见性):控制线程优雅退出,而非强制中断
private volatile boolean toStop = false;
// 线程停止原因:记录停止的具体原因(如手动终止、空闲超时)
private String stopReason;
// 任务运行状态标记:标记当前线程是否正在执行任务(用于外部感知状态)
private boolean running = false;
// 空闲次数:记录线程空闲的轮次,用于判断是否销毁空闲线程(节省资源)
private int idleTimes = 0;
/**
* 构造方法:初始化任务线程(核心:绑定jobId和处理器,初始化队列/去重集合)
* @param jobId 任务唯一标识
* @param handler 任务处理器(执行业务逻辑)
*/
public JobThread(int jobId, IJobHandler handler) {
this.jobId = jobId;
this.handler = handler;
// 初始化无界阻塞队列(LinkedBlockingQueue默认容量Integer.MAX_VALUE,线程安全)
this.triggerQueue = new LinkedBlockingQueue<TriggerRequest>();
// 初始化线程安全的去重Set(ConcurrentHashMap.newKeySet()比HashSet+同步锁性能更高)
this.triggerLogIdSet = ConcurrentHashMap.newKeySet();
// 设置线程名称:包含jobId和时间戳,便于日志排查(如区分不同任务的线程)
this.setName("xxl-job, JobThread-"+jobId+"-"+System.currentTimeMillis());
}
/**
* 获取任务处理器(外部调用,如更新处理器时使用)
*/
public IJobHandler getHandler() {
return handler;
}
/**
* 核心方法:将触发请求推入队列(触发任务执行的入口)
* 关键逻辑:先去重(logId),再入队,保证同一触发请求不重复处理
* @param triggerParam 触发请求参数(包含logId、任务参数、超时时间等)
* @return 响应结果(成功/重复触发失败)
*/
public Response<String> pushTriggerQueue(TriggerRequest triggerParam) {
// 第一步:logId去重(核心防重)
// Set.add()返回false表示已存在该logId,直接返回重复触发失败
if (!triggerLogIdSet.add(triggerParam.getLogId())) {
logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId());
return Response.of(XxlJobContext.HANDLE_CODE_FAIL, "repeate trigger job, logId:" + triggerParam.getLogId());
}
// 第二步:合法请求入队(队列线程安全,无需额外加锁)
triggerQueue.add(triggerParam);
return Response.ofSuccess(); // 返回成功
}
/**
* 标记线程停止(优雅关闭)
* @param stopReason 停止原因(用于回调结果时说明)
*/
public void toStop(String stopReason) {
/**
* 设计备注:
* Thread.interrupt()仅能终止线程的阻塞状态(wait/join/sleep),无法终止运行中的线程;
* 因此通过volatile修饰的toStop标记控制线程循环退出,保证任务执行完成后优雅关闭。
*/
this.toStop = true;
this.stopReason = stopReason;
}
/**
* 外部感知线程状态:判断任务是否正在执行,或队列中有待执行请求
* 用途:调度中心查询任务状态、判断是否可终止等
*/
public boolean isRunningOrHasQueue() {
return running || triggerQueue.size()>0;
}
/**
* 线程核心执行逻辑(整个JobThread的核心)
* 流程:初始化处理器 → 循环消费队列 → 执行任务(处理超时/异常) → 回调结果 → 优雅停止 → 销毁处理器
*/
@Override
public void run() {
// 第一步:初始化任务处理器(执行器启动时调用,如初始化数据库连接、加载配置等)
try {
handler.init();
} catch (Throwable e) {
logger.error("JobThread handler init error", e); // 初始化异常日志
}
// 第二步:核心循环(消费触发队列,直到标记停止)
while(!toStop){
running = false; // 重置运行状态
idleTimes++; // 空闲次数+1(每轮循环无任务则累加)
TriggerRequest triggerParam = null;
try {
// 从队列获取触发请求:阻塞3秒(避免空轮询消耗CPU)
// 为什么不用take()?因为take()会永久阻塞,无法检测toStop标记,导致线程无法退出
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
// 有触发请求时,执行任务逻辑
if (triggerParam!=null) {
running = true; // 标记任务正在运行
idleTimes = 0; // 重置空闲次数
triggerLogIdSet.remove(triggerParam.getLogId()); // 移除去重Set中的logId(释放资源)
// 1. 生成任务日志文件名(格式:logPath/yyyy-MM-dd/logId.log)
String logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());
// 2. 初始化任务上下文(绑定logId、参数、日志文件等,供业务逻辑调用)
XxlJobContext xxlJobContext = new XxlJobContext(
triggerParam.getJobId(),
triggerParam.getExecutorParams(),
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
logFileName,
triggerParam.getBroadcastIndex(),
triggerParam.getBroadcastTotal());
XxlJobContext.setXxlJobContext(xxlJobContext); // 放入ThreadLocal,业务逻辑可随时获取
// 3. 记录任务开始日志(输出到日志文件,供调度中心查看)
XxlJobHelper.log("<br>----------- xxl-job job execute start -----------<br>----------- Param:" + xxlJobContext.getJobParam());
// 4. 执行任务(区分超时控制/普通执行)
if (triggerParam.getExecutorTimeout() > 0) {
// 场景1:任务设置了超时时间 → 用FutureTask控制超时
Thread futureThread = null;
try {
// 创建FutureTask封装任务执行逻辑
FutureTask<Boolean> futureTask = new FutureTask<Boolean>(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
// 重新绑定上下文(子线程需独立上下文)
XxlJobContext.setXxlJobContext(xxlJobContext);
handler.execute(); // 执行核心业务逻辑
return true;
}
});
futureThread = new Thread(futureTask);
futureThread.start(); // 启动子线程执行
// 等待任务执行,超时则抛出TimeoutException
Boolean tempResult = futureTask.get(triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);
} catch (TimeoutException e) {
// 超时处理:记录日志 + 标记任务失败
XxlJobHelper.log("<br>----------- xxl-job job execute timeout");
XxlJobHelper.log(e);
XxlJobHelper.handleTimeout("job execute timeout ");
} finally {
// 无论是否超时,中断子线程(释放资源)
futureThread.interrupt();
}
} else {
// 场景2:无超时设置 → 直接执行任务
handler.execute();
}
// 5. 校验执行结果(防止业务逻辑未设置处理结果)
if (XxlJobContext.getXxlJobContext().getHandleCode() <= 0) {
XxlJobHelper.handleFail("job handle result lost."); // 标记失败
} else {
// 截断过长的处理信息(避免回调数据过大)
String tempHandleMsg = XxlJobContext.getXxlJobContext().getHandleMsg();
tempHandleMsg = (tempHandleMsg!=null&&tempHandleMsg.length()>50000)
?tempHandleMsg.substring(0, 50000).concat("...")
:tempHandleMsg;
XxlJobContext.getXxlJobContext().setHandleMsg(tempHandleMsg);
}
// 6. 记录任务结束日志
XxlJobHelper.log("<br>----------- xxl-job job execute end(finish) -----------<br>----------- Result: handleCode="
+ XxlJobContext.getXxlJobContext().getHandleCode()
+ ", handleMsg = "
+ XxlJobContext.getXxlJobContext().getHandleMsg()
);
} else {
// 无触发请求时:判断空闲次数是否超过阈值(30轮×3秒=90秒)
if (idleTimes > 30) {
// 队列为空时销毁线程(避免并发触发导致jobId丢失)
if(triggerQueue.isEmpty()) {
XxlJobExecutor.removeJobThread(jobId, "excutor idle times over limit.");
}
}
}
} catch (Throwable e) {
// 异常处理:捕获所有执行异常,标记任务失败
if (toStop) {
XxlJobHelper.log("<br>----------- JobThread toStop, stopReason:" + stopReason);
}
// 记录异常堆栈信息
StringWriter stringWriter = new StringWriter();
e.printStackTrace(new PrintWriter(stringWriter));
String errorMsg = stringWriter.toString();
// 标记任务失败
XxlJobHelper.handleFail(errorMsg);
XxlJobHelper.log("<br>----------- JobThread Exception:" + errorMsg + "<br>----------- xxl-job job execute end(error) -----------");
} finally {
// 第三步:回调执行结果给调度中心(无论成功/失败/超时/异常)
if(triggerParam != null) {
if (!toStop) {
// 正常执行完成 → 回调实际执行结果
TriggerCallbackThread.pushCallBack(new CallbackRequest(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.getXxlJobContext().getHandleCode(),
XxlJobContext.getXxlJobContext().getHandleMsg() )
);
} else {
// 线程被终止 → 回调失败结果(说明被终止)
TriggerCallbackThread.pushCallBack(new CallbackRequest(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.HANDLE_CODE_FAIL,
stopReason + " [job running, killed]" )
);
}
}
}
}
// 第四步:处理队列中剩余的触发请求(线程停止时,未执行的请求回调失败)
while(triggerQueue !=null && !triggerQueue.isEmpty()){
TriggerRequest triggerParam = triggerQueue.poll();
if (triggerParam!=null) {
TriggerCallbackThread.pushCallBack(new CallbackRequest(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.HANDLE_CODE_FAIL,
stopReason + " [job not executed, in the job queue, killed.]")
);
}
}
// 第五步:销毁任务处理器(释放资源,如关闭数据库连接、清理缓存等)
try {
handler.destroy();
} catch (Throwable e) {
logger.error("JobThread handler destroy error", e);
}
// 日志记录:线程停止完成
logger.info(">>>>>>>>>>> xxl-job JobThread stoped, hashCode:{}", Thread.currentThread());
}
}7.3:防重复执行总结
调度器中根据注册地址、定时规则、路由规则来指定的调用执行器。
执行器中也就是我们的springboot项目根据源,单任务单线程一个jobId对应一个JobThread,由XxlJobExecutor维护映射关系从根本上避免多线程并发执行同一任务触发请求去重ConcurrentHashMap.newKeySet()存储logId,入队前校验防止调度中心重复推送同一触发请求队列串行消费LinkedBlockingQueue存储触发请求,单线程while循环逐个消费保证任务按触发顺序串行执行,无需显式加锁优雅停止volatile修饰的toStop标记控制循环退出,而非强制中断线程保证正在执行的任务完成后再停止,避免数据不一致超时控制FutureTask + get(timeout)实现任务超时终止防止单个任务执行时间过长占用线程资源空闲线程销毁空闲次数超过 30 轮(90 秒)且队列为空时,自动移除线程节省服务器资源,避免大量空闲线程占用内存全链路结果回调无论成功 / 失败 / 超时 / 终止,都通过TriggerCallbackThread回调调度中心保证调度中心能实时感知任务执行状态,回调调度中心,将异常或者成功返回,插入日志,便于查询调度结果哦。
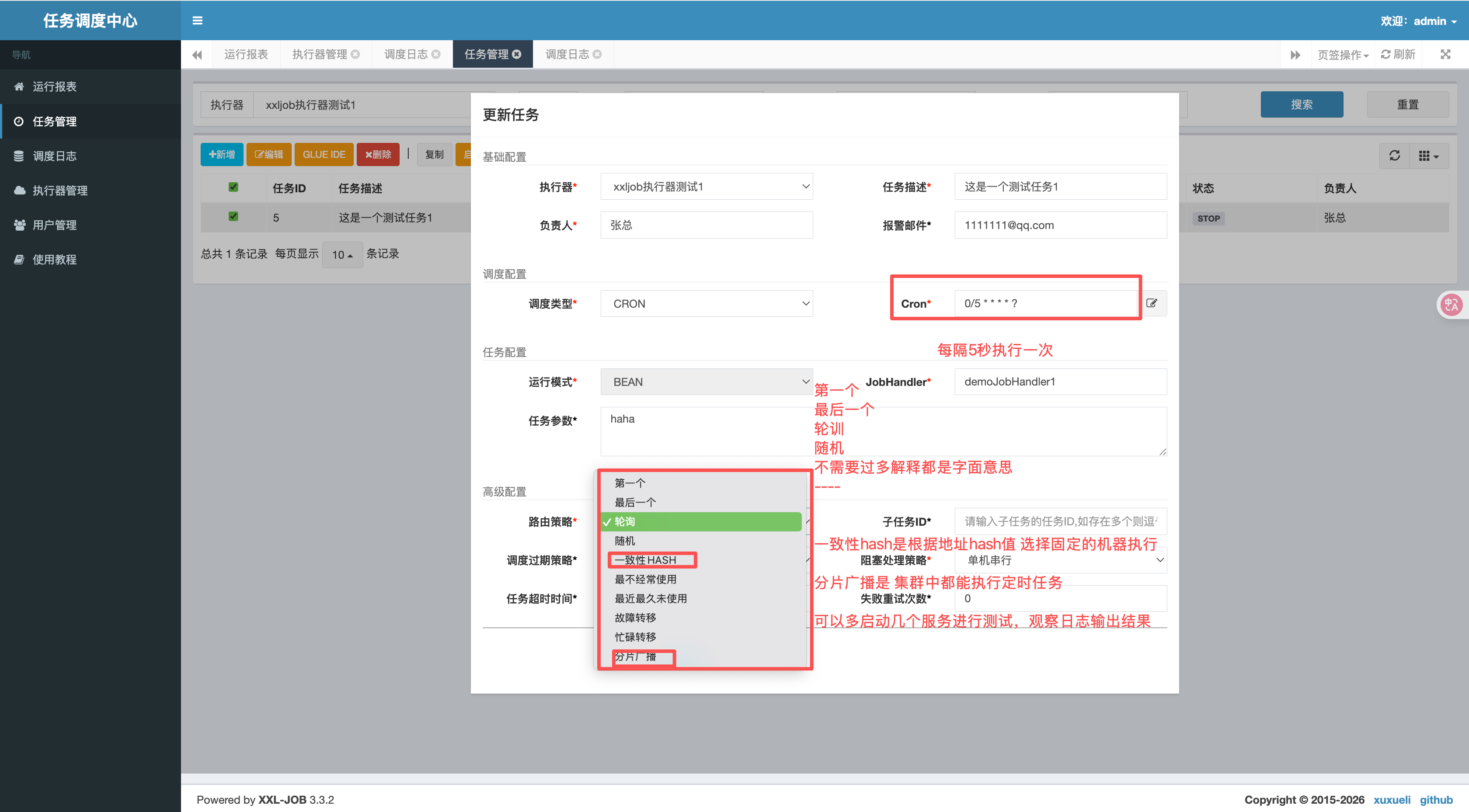
8:不同的路由策略测试
第一个:字面意思
最后一个:字面意思
轮训:字面意思
随机:字面意思
一致性哈希:将集群注册进行hash,固定的hash值执行,也就是固定机器执行
最不常用:字面意思
最近最久未使用:字面意思
故障转移:按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
忙碌转移:按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
分片广播:集群中的所有服务都会执行
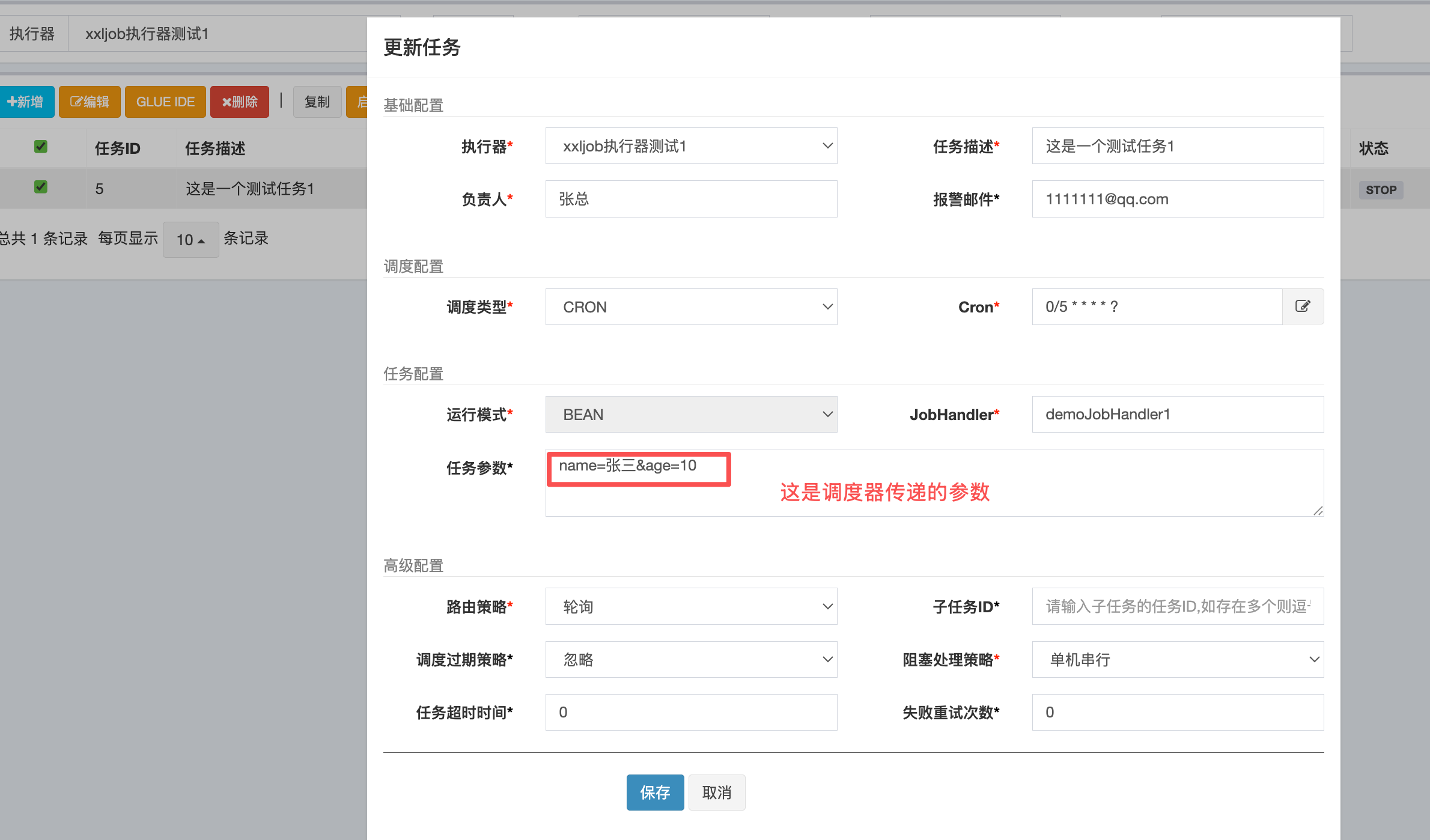
9:调度器传递参数到执行器
9.1:调度器配置
9.2:执行器代码
执行器XxlJobHelper获取参数,有很多方法输出的是字符串
TypeScript
@XxlJob(value = "demoJobHandler1", init = "init", destroy = "destroy")
public String demoJobHandler1() throws Exception {
//XxlJobHelper 获取参数 name=张三&age=10 字符串传递
String name = XxlJobHelper.getJobParam();
String s = "TimeJob1执行器8091端口的MyJobHandlerBean1,有返回值是传递参数的name:"+name+":"+userService.list().toString();
logger.info(s);
return s;
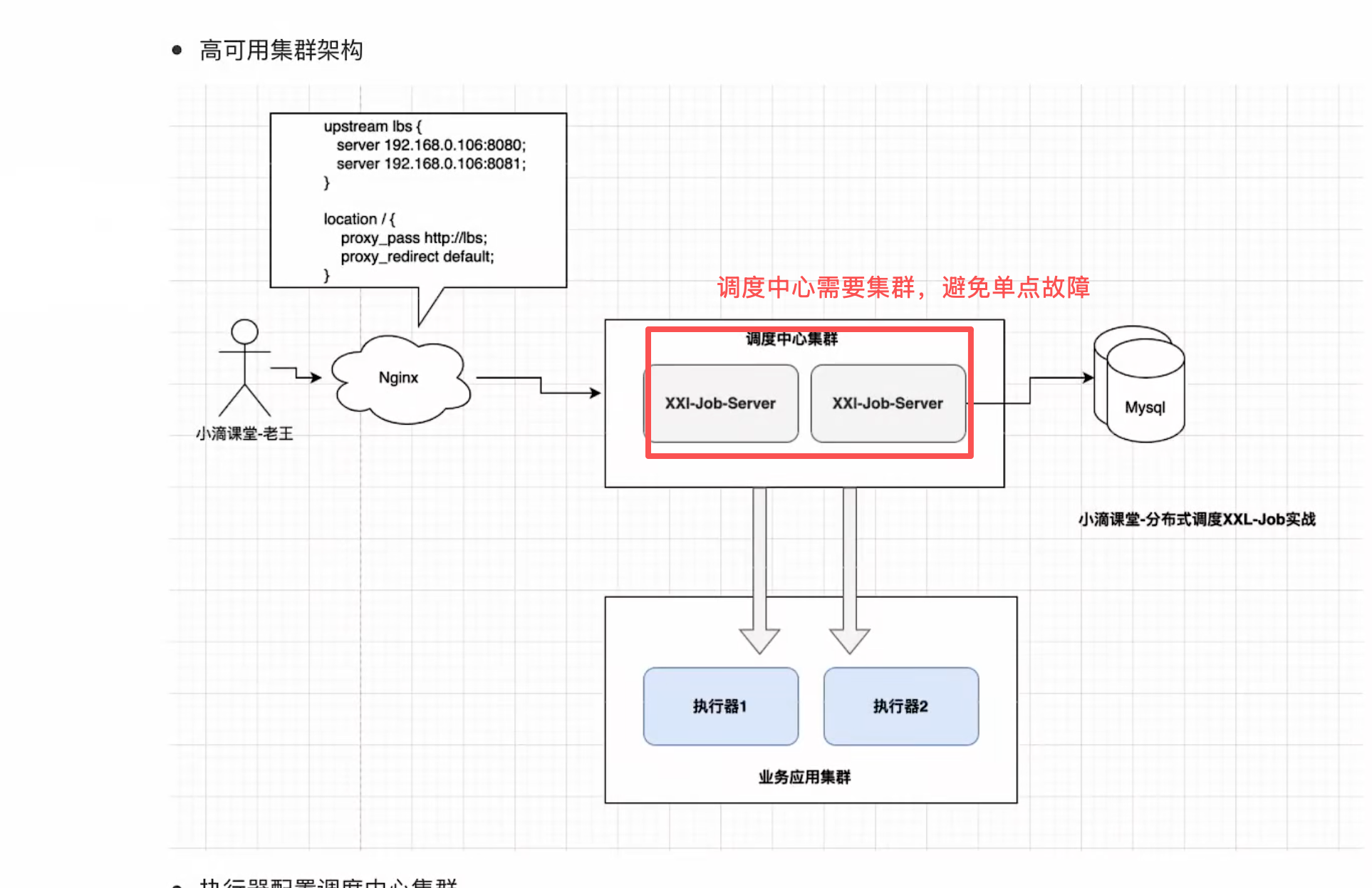
}10:调度中心HA(高可用)
也就是启动两个调度中心,ip、端口不一样就行,然后执行器的调度中心地址配置多个。
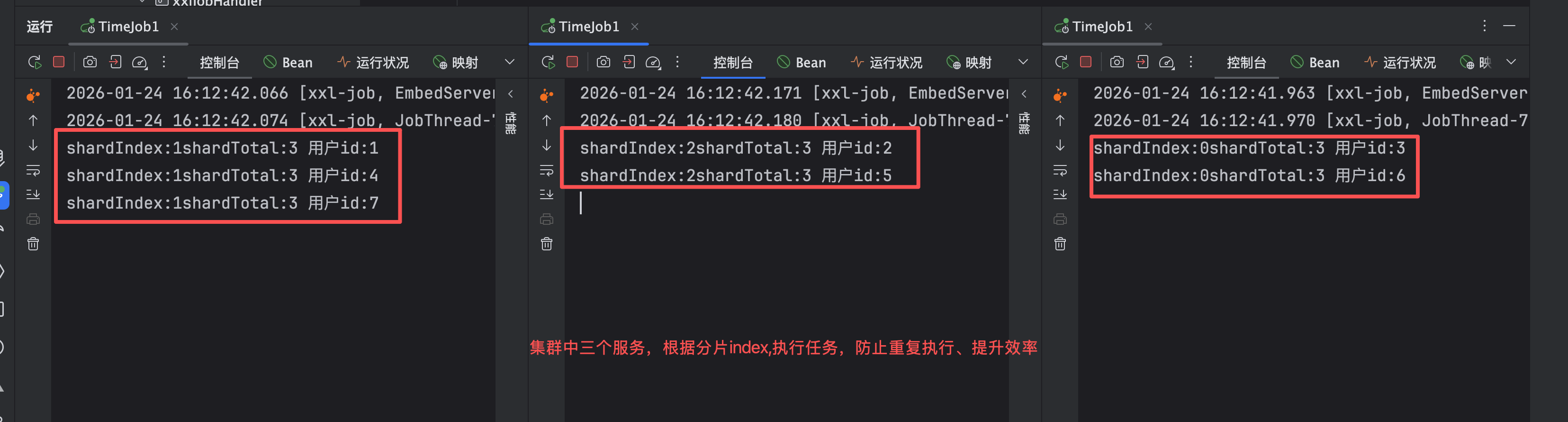
11:分片模式
我们知道分片模式会把任务分到集群中的每一台机器,假如有一个定时任务给所有的注册用户推送大促信息,但是如果走轮训定时任务的话,由于一个服务执行耗时很久,这个时候我们需要分片模式,让集群中每一台服务都去在执行,减少压力,提高效率。但是需要根据集群的总数跟任务量取模,防止同一个用户重复执行
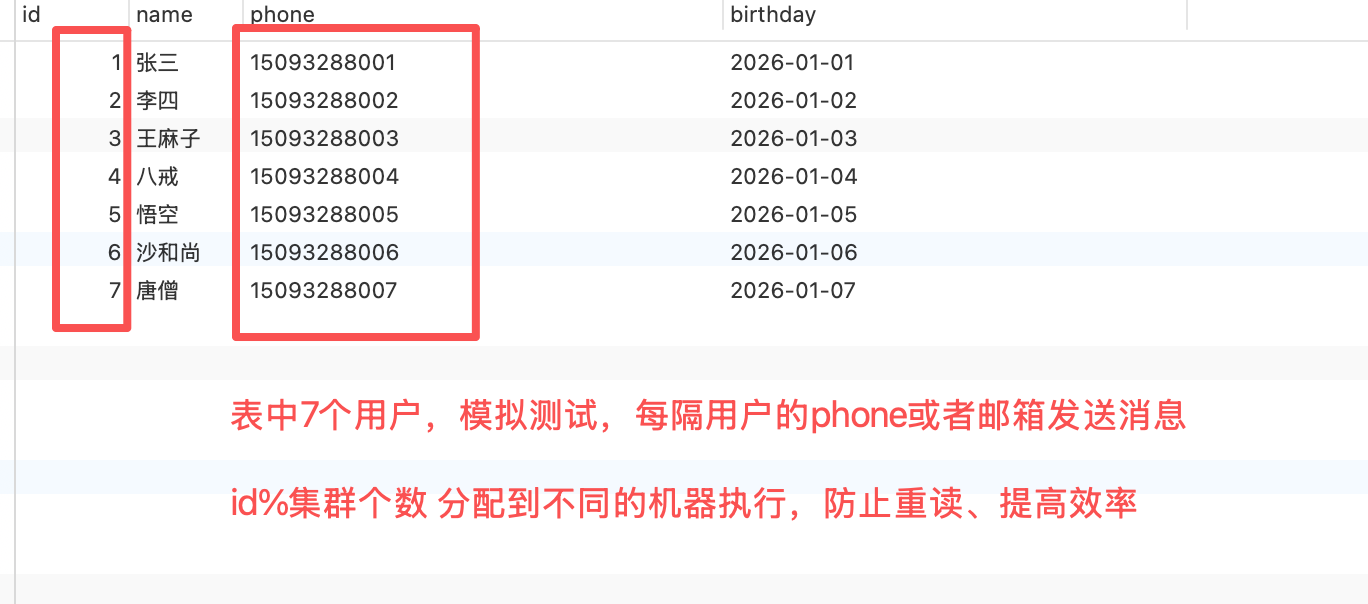
Java代码:
java
/**
* 这是模拟多用户的分片任务
* 后台启动三台机器模拟分片任务
*/
@XxlJob(value = "shardingHandler1")
public void shardingHandler1() throws Exception {
val shardIndex = XxlJobHelper.getShardIndex();//分片序号
val shardTotal = XxlJobHelper.getShardTotal();//分片总数
logger.info("TimeJob1 执行器8091端口的shardingHandler1, shardIndex:"+shardIndex+", shardTotal:"+shardTotal);
val list = userService.list();
//根据分片index和total,过滤list
for (int i = 0; i < list.size(); i++) {
if (list.get(i).getId() % shardTotal == shardIndex) {
System.out.println("shardIndex:"+shardIndex+"shardTotal:"+shardTotal+" 用户id:"+list.get(i).getId());
}
}
}在调度中心配置定时任务
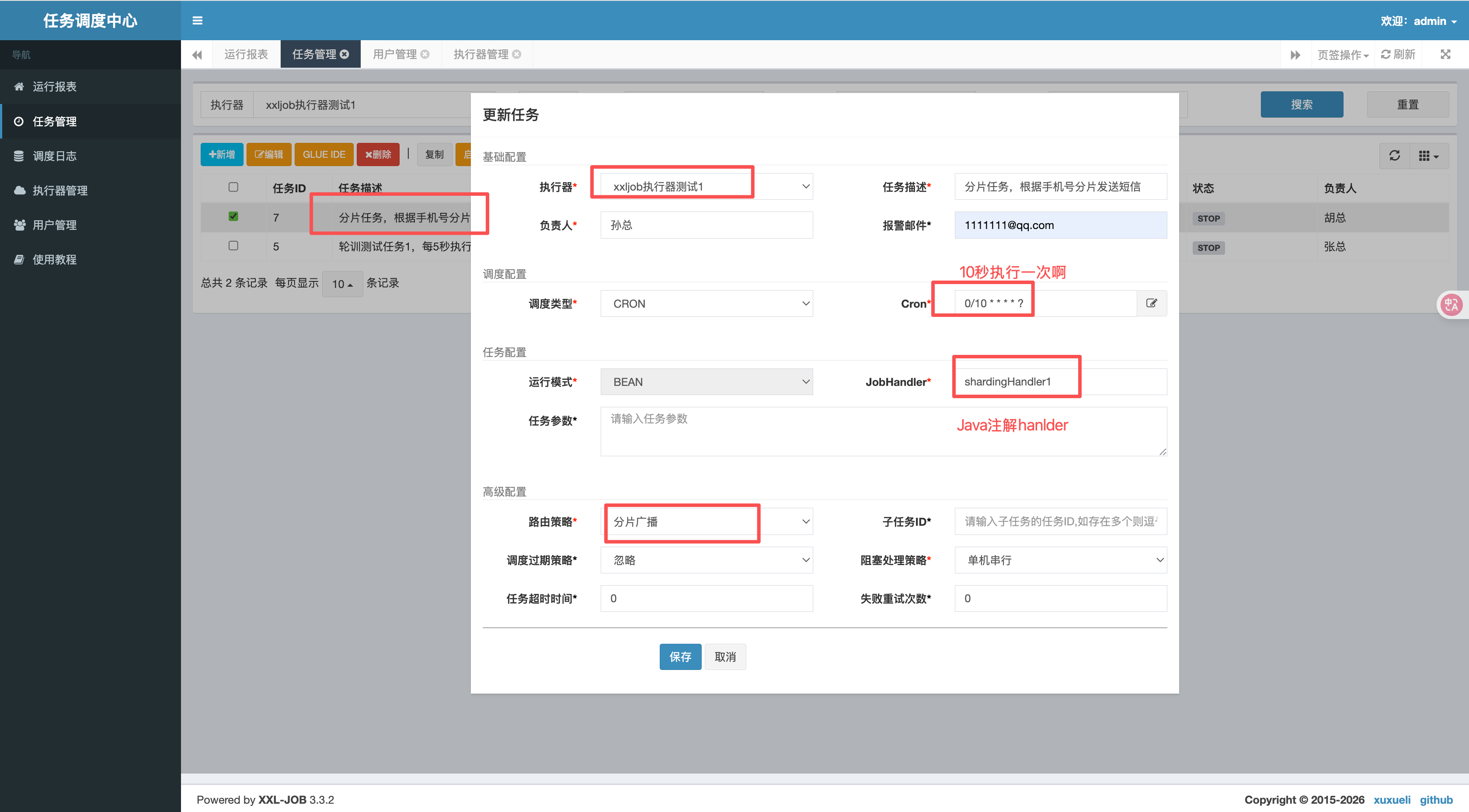
三个服务截图启动三次,端口不一致就行