第一步:准备数据
肾小球分割-深度学习图像分割数据集
肾小球分割数据,可直接应用到一些常用深度学习分割算法中,比如FCN、Unet、SegNet、DeepLabV1、DeepLabV2、DeepLabV3、DeepLabV3+、PSPNet、RefineNet、HRnet、Mask R-CNN、Segformer、DUCK-Net模型等
数据集总共有2575对图片,数据质量非常高,甚至可应用到工业落地的项目中


第二步:搭建模型
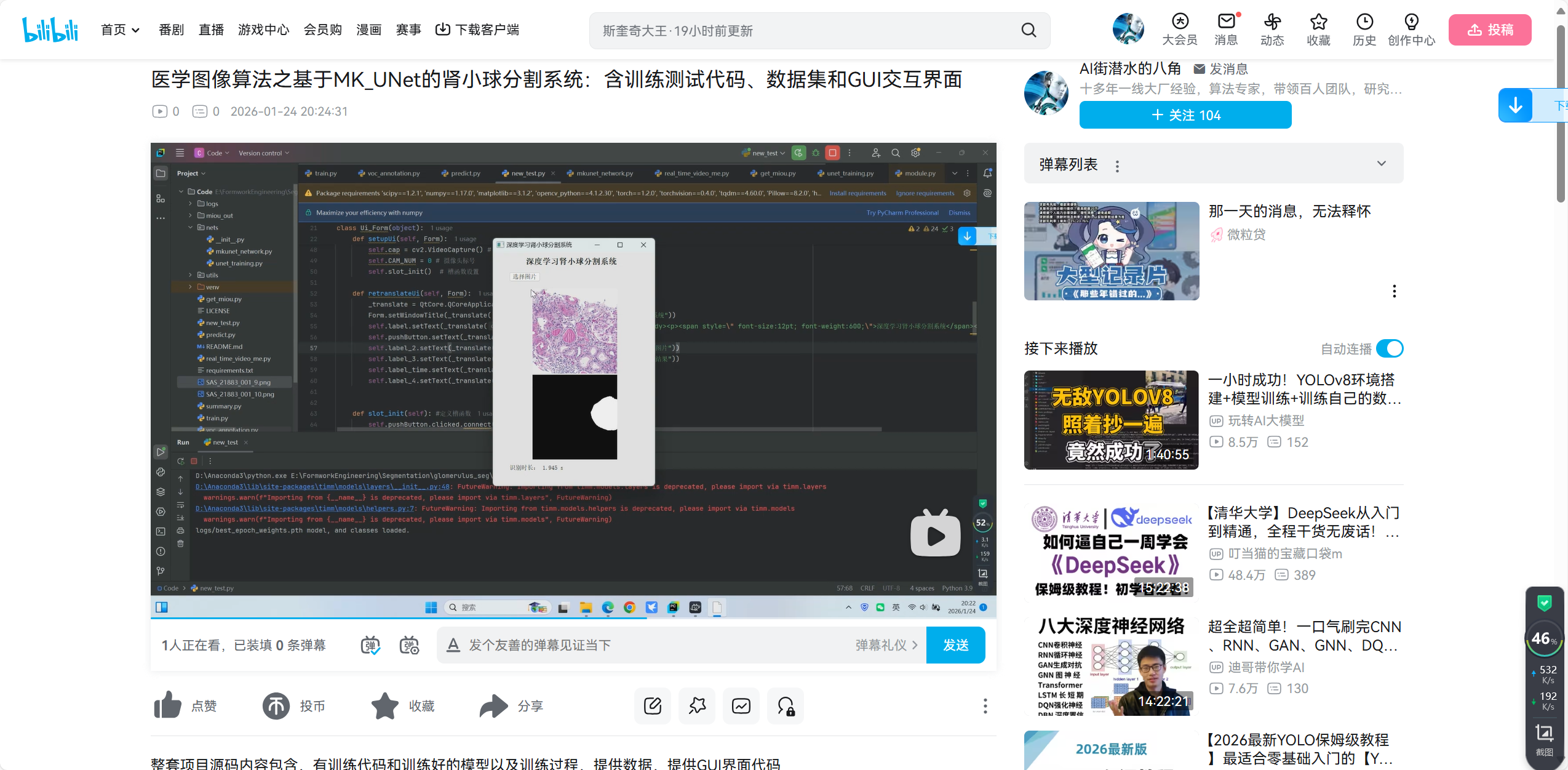
本文选择MK_UNet,其网络结构分别如下:
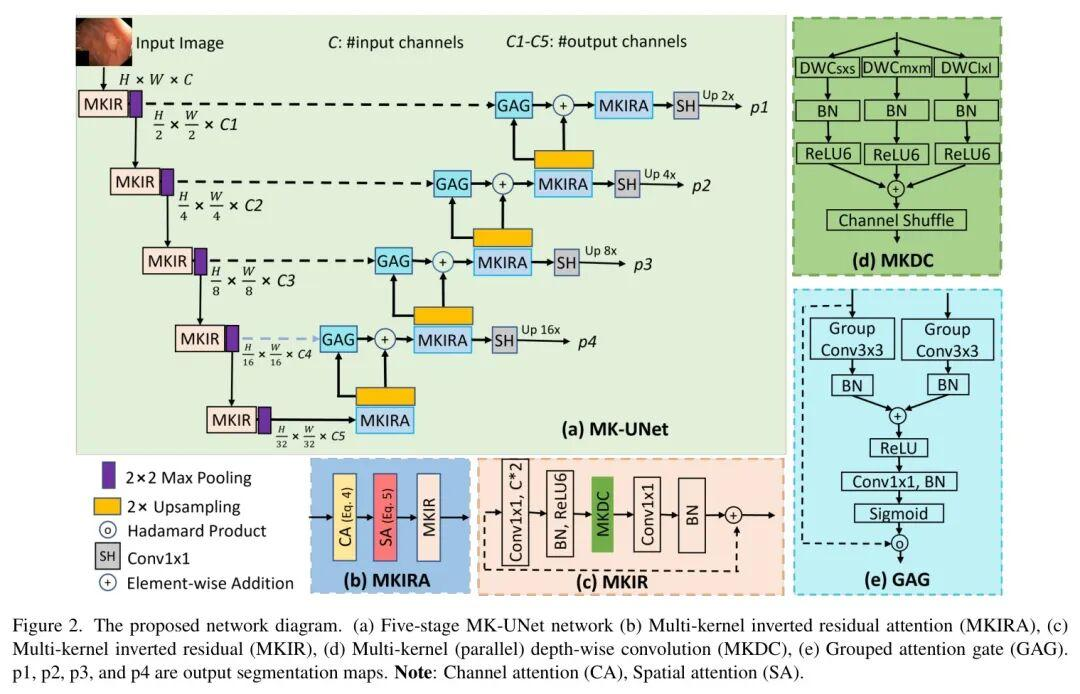
第三步:训练代码
1)损失函数为:dice_loss + focal_loss
2)网络代码:
python
class MK_UNet(nn.Module):
def __init__(self, num_classes=1, in_channels=3, channels=[16, 32, 64, 96, 160], depths=[1, 1, 1, 1, 1],
kernel_sizes=[1, 3, 5], expansion_factor=2, gag_kernel=3, **kwargs):
super().__init__()
self.encoder1 = mk_irb_bottleneck(in_channels, channels[0], depths[0], 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.encoder2 = mk_irb_bottleneck(channels[0], channels[1], depths[1], 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.encoder3 = mk_irb_bottleneck(channels[1], channels[2], depths[2], 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.encoder4 = mk_irb_bottleneck(channels[2], channels[3], depths[3], 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.encoder5 = mk_irb_bottleneck(channels[3], channels[4], depths[4], 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.AG1 = GroupedAttentionGate(F_g=channels[3], F_l=channels[3], F_int=channels[3] // 2,
kernel_size=gag_kernel, groups=channels[3] // 2)
self.AG2 = GroupedAttentionGate(F_g=channels[2], F_l=channels[2], F_int=channels[2] // 2,
kernel_size=gag_kernel, groups=channels[2] // 2)
self.AG3 = GroupedAttentionGate(F_g=channels[1], F_l=channels[1], F_int=channels[1] // 2,
kernel_size=gag_kernel, groups=channels[1] // 2)
self.AG4 = GroupedAttentionGate(F_g=channels[0], F_l=channels[0], F_int=channels[0] // 2,
kernel_size=gag_kernel, groups=channels[0] // 2)
self.decoder1 = mk_irb_bottleneck(channels[4], channels[3], 1, 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.decoder2 = mk_irb_bottleneck(channels[3], channels[2], 1, 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.decoder3 = mk_irb_bottleneck(channels[2], channels[1], 1, 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.decoder4 = mk_irb_bottleneck(channels[1], channels[0], 1, 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.decoder5 = mk_irb_bottleneck(channels[0], channels[0], 1, 1, expansion_factor=expansion_factor,
dw_parallel=True, add=True, kernel_sizes=kernel_sizes)
self.CA1 = ChannelAttention(channels[4], ratio=16)
self.CA2 = ChannelAttention(channels[3], ratio=16)
self.CA3 = ChannelAttention(channels[2], ratio=16)
self.CA4 = ChannelAttention(channels[1], ratio=8)
self.CA5 = ChannelAttention(channels[0], ratio=4)
self.SA = SpatialAttention()
self.out1 = nn.Conv2d(channels[2], num_classes, kernel_size=1)
self.out2 = nn.Conv2d(channels[1], num_classes, kernel_size=1)
self.out3 = nn.Conv2d(channels[0], num_classes, kernel_size=1)
self.out4 = nn.Conv2d(channels[0], num_classes, kernel_size=1)
def forward(self, x):
if x.shape[1] == 1:
x = x.repeat(1, 3, 1, 1)
B = x.shape[0]
### Encoder
### Stage 1
out = F.max_pool2d(self.encoder1(x), 2, 2)
t1 = out
### Stage 2
out = F.max_pool2d(self.encoder2(out), 2, 2)
t2 = out
### Stage 3
out = F.max_pool2d(self.encoder3(out), 2, 2)
t3 = out
### Stage 4
out = F.max_pool2d(self.encoder4(out), 2, 2)
t4 = out
### Bottleneck
out = F.max_pool2d(self.encoder5(out), 2, 2)
### Stage 4
out = self.CA1(out) * out
out = self.SA(out) * out
out = F.relu(F.interpolate(self.decoder1(out), scale_factor=(2, 2), mode='bilinear'))
t4 = self.AG1(g=out, x=t4)
out = torch.add(out, t4)
### Stage 3
out = self.CA2(out) * out
out = self.SA(out) * out
out = F.relu(F.interpolate(self.decoder2(out), scale_factor=(2, 2), mode='bilinear'))
p1 = F.interpolate(self.out1(out), scale_factor=(8, 8), mode='bilinear')
t3 = self.AG2(g=out, x=t3)
out = torch.add(out, t3)
out = self.CA3(out) * out
out = self.SA(out) * out
out = F.relu(F.interpolate(self.decoder3(out), scale_factor=(2, 2), mode='bilinear'))
p2 = F.interpolate(self.out2(out), scale_factor=(4, 4), mode='bilinear')
t2 = self.AG3(g=out, x=t2)
out = torch.add(out, t2)
out = self.CA4(out) * out
out = self.SA(out) * out
out = F.relu(F.interpolate(self.decoder4(out), scale_factor=(2, 2), mode='bilinear'))
p3 = F.interpolate(self.out3(out), scale_factor=(2, 2), mode='bilinear')
t1 = self.AG4(g=out, x=t1)
out = torch.add(out, t1)
out = self.CA5(out) * out
out = self.SA(out) * out
out = F.relu(F.interpolate(self.decoder5(out), scale_factor=(2, 2), mode='bilinear'))
p4 = self.out4(out)
return p4 # [p4, p3, p2, p1]第四步:统计一些指标(训练过程中的loss和miou)
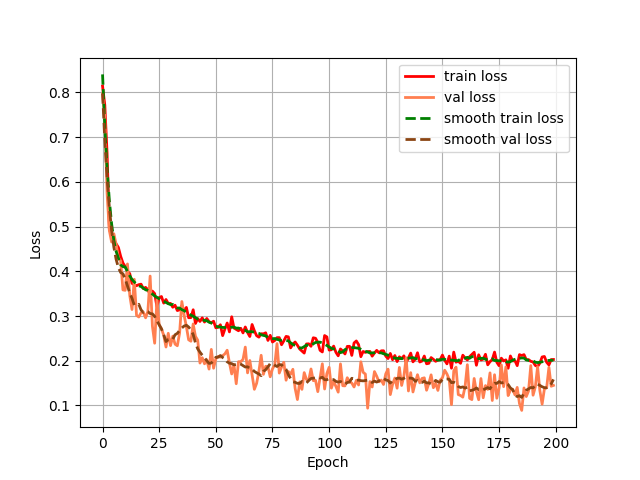
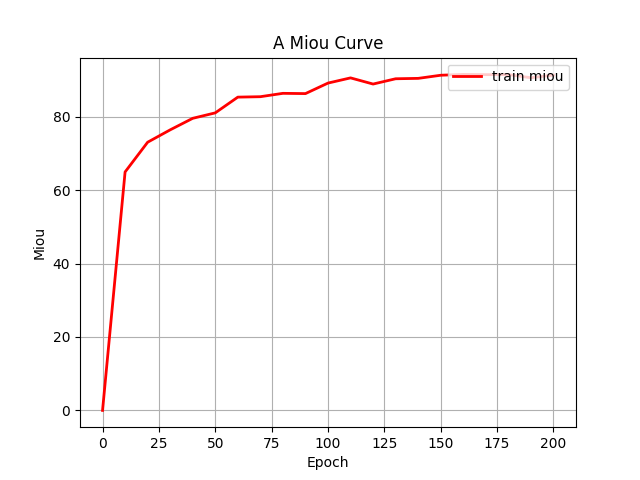

第五步:搭建GUI界面

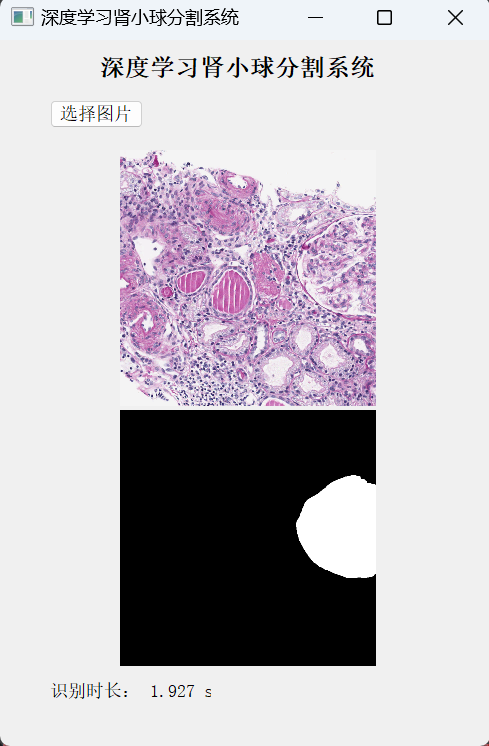
第六步:整个工程的内容
项目完整文件下载请见演示与介绍视频的简介处给出:➷➷➷
https://www.bilibili.com/video/BV1SqzkBvEuM/