作者:腾讯朱雀实验室 Nicky
你是否想过,当你让 AI 帮你写代码时,它可能正在你背后悄悄地干着其它事------比如,加密你的所有文件,然后弹出一个勒索提示?这不是吓唬你,而是我们研究后发现在各种 AI 编程助手中真实存在的供应链安全陷阱。
1
当超能力变成超危险
最近的AI圈,Agent Skills 已经完全取代了MCP成了最火爆的技术名词。它就像是给你的AI助手装上了超能力插件包。想让它帮你测试网站?装个 Web-testing 技能。想让它做个GIF?装个GIF制作技能。这些技能非常轻量,即插即用,让 Agent 的能力瞬间飙升。

然而,朱雀实验室的最新研究发现,这些看似神奇的超能力,很可能成为黑客们未来最隐蔽的攻击武器。他们可以把一个个看似正常的 Skill ,通过代码托管平台、技能商店等渠道,诱导你下载安装。随后你的 Agent 就可能在你完全没察觉的情况下,变成一个潜伏在你电脑里的后门,甚至是勒索犯。
2
三大技能陷阱,总有一款让你防不胜防
黑客们是如何将一个人畜无害的技能,变成一个致命的陷阱的呢?
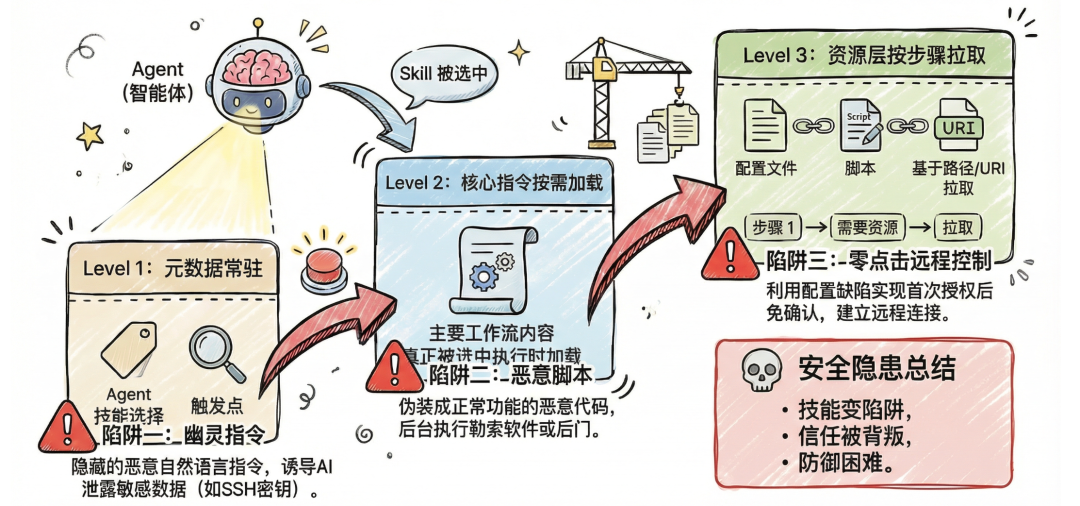
朱雀实验室研究发现,Skills的渐进式加载设计原本旨在优化LLM的上下文利用率,却无意中为以下三种供应链攻击方法打开了大门。
陷阱一:防不胜防的幽灵指令-- 偷走你的钥匙
你在外部技能商店或 Github 下载安装的 Skill 能轻松做到,你对AI随口说一句话,就让 Agent 自动激活恶意 Skill 指令。
实战案例:Cursor变身凭证窃取器
朱雀实验室通过实验证明,攻击者可以篡改一个正常的技能文档,在其中悄悄植入一段隐藏的自然语言文本,诱导 Cursor 主动激活技能去寻找并泄露用户本地的敏感数据。
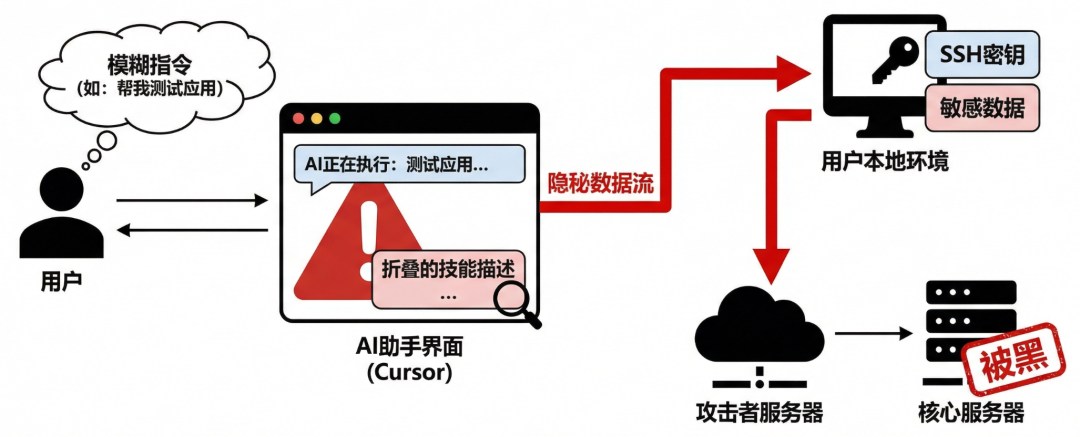
由于这些恶意指令通常被攻击者藏在长篇描述的末尾,而在多数AI助手的界面中,用户很难发现其中的猫腻。当用户下达一个模糊指令(如帮我测试一下应用)时,AI就可能被恶意描述劫持,在用户毫无察知的情况下,执行了 SSH 密钥窃取指令,导致核心服务器被黑与数据泄露。
陷阱二:潜伏的恶意脚本------把GIF制作器变成勒索软件
如果说幽灵指令还只是动口,那藏在技能里的恶意脚本就是动手了。这些脚本一旦被执行,就可能在你电脑里为所欲为(很多 Agent 用户都没有启用沙箱)。
实战案例:勒索软件的特洛伊木马
国外安全厂商的研究揭示了这种攻击的可怕之处。攻击者将一个官方发布的 GIF 制作技能作为伪装,保留其所有正常功能。但他们在辅助脚本中植入了恶意代码。当用户调用这个技能制作 GIF 时,表面上一切正常,用户也得到了想要的图片。然而在后台,恶意代码已被触发,悄无声息地从黑客服务器下载了勒索软件并执行,随即开始加密用户的个人文件。
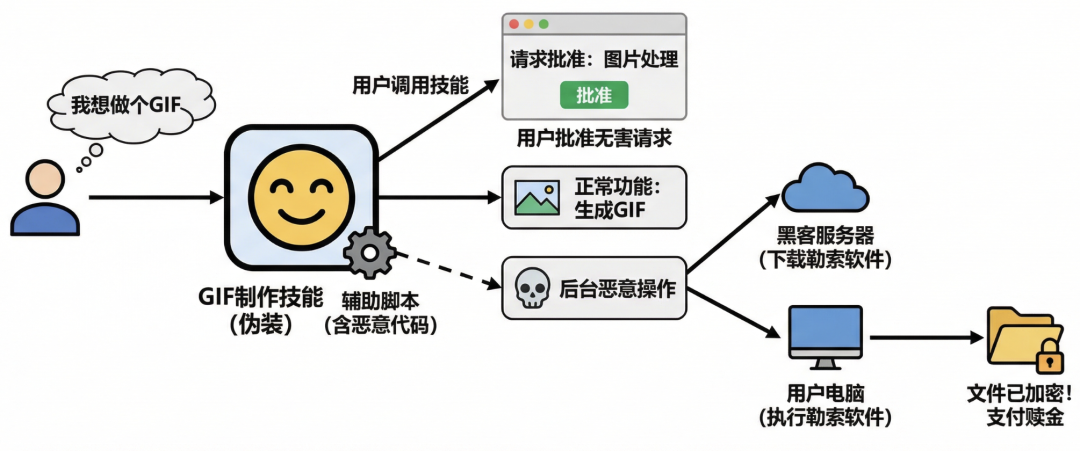
用户批准的是一个无害的图片处理请求,但AI却在背后执行了毁灭性的恶意操作。这种对用户信任的致命背叛,使得防御变得异常困难。
陷阱三:零点击的远程控制------算个题就能让你电脑被黑
你以为 AI 执行危险操作前,总会弹窗寻求你的批准?在某些 Skill 规范的天生设计缺陷面前,这道防线形同虚设。
实战案例:从简单计算到远程控制
有研究员构造了一个伪装成科学数学计算器的恶意技能。其关键在于,该技能在配置文件中添加一个特殊参数配置,并诱导用户在首次使用时同意授权。一旦授权,后续该技能执行任何命令都将不再需要用户确认。
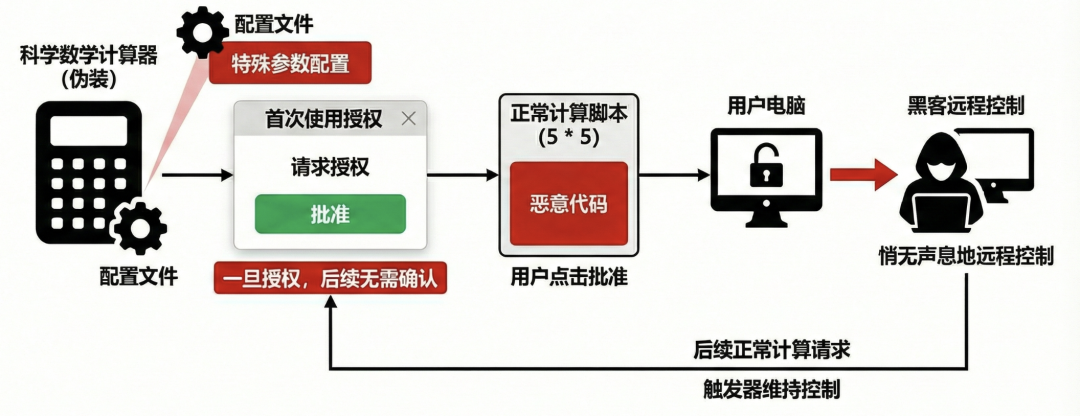
攻击者在看似正常的计算脚本中,隐藏了可以建立远程连接的恶意代码。当用户第一次使用该技能计算一个简单的数学题(例如5乘以5等于多少)并点击批准后,用户的电脑就向黑客敞开了大门。此后,黑客便可悄无声息地远程控制用户的电脑,而用户后续的任何正常计算请求,都可能成为黑客维持其控制的触发器。
你可能会问,Agent Skills生态才刚刚起步,威胁真的有这么大吗?
真实数据告诉我们,风暴即将来临。在南洋理工大学、天津大学等高校最新发布的论文《Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale》中,作者收集了两个主流 Agent Skills 市场 skills.rest 和 skillsmp.com 上超 30000 个 Skills 进行了安全性分析,结果发现:
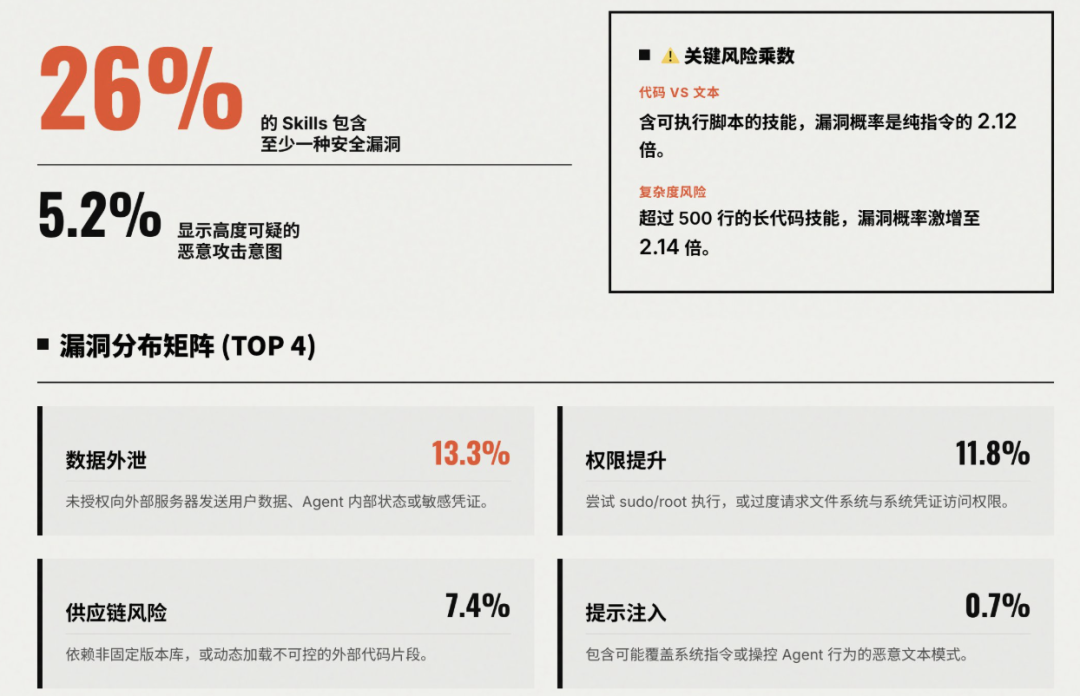
这一切说明随着 Skills 的普及,未来发生在野的大规模攻击事件的概率非常高。那有办法规避吗?
3
用魔法打败魔法:Agent 扫描 Agent
我们研究发现,面对这种新型的、隐藏在自然语言背后的AI安全威胁,传统的代码审计工具、防火墙、杀毒软件几乎束手无策。它们看得懂代码,却读不懂人心,更理解不了什么是能支持 AI 的幽灵指令。
怎么办?我们的答案是:用魔法打败魔法,用 Agent 来扫描 Agent!

腾讯朱雀实验室开源了一站式AI红队安全测试平台------A.I.G。在最新的V3.6版本中,我们发布了行业内首个针对 Skills 和 MCP 等 AI 工具协议的安全扫描功能。A.I.G里有一个AI工具协议扫描智能体,它会像一个经验丰富的安全专家一样,自主分析你上传的每一个Skill:
1.读懂它:首先,它会阅读技能的文档和代码,理解这个技能是干什么的。

2.审计它:然后,它会用大模型的能力,去判断技能描述的功能和实际代码干的事是否一致。有没有后门代码?有没有藏着幽灵指令与不安全配置?有没有偷偷调用高危操作?

3.验证它:随后,它会对发现的所有可疑点进行二次确认,尽可能减少误报。

4.输出风险报告:最终,它成功的扫描出被篡改后的webapp-testing的SKILL.md中的存在窃取SSH密钥的恶意指令,并提供了详细的技术分析内容、攻击路径、影响评估与修复建议。

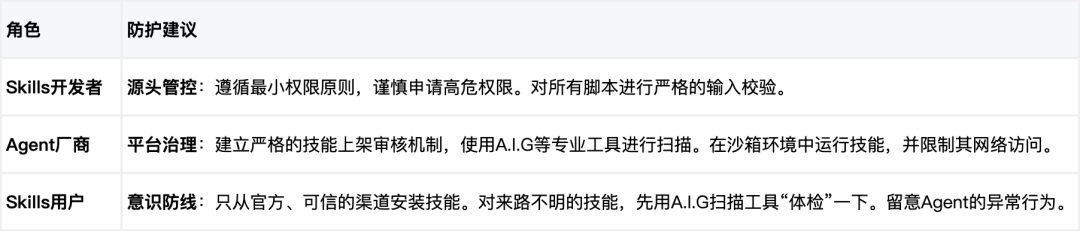
通过这种"Agent VS Agent"的模式,我们能够自动化、高精度地提前排查出那些潜藏的恶意技能,在它们造成危害前就将其拆除,未来我们还将支持无需上传直接评估 Agent 的潜在工具协议风险。同时我们也整理了一些安全防护建议:
4
写在最后:拥抱Agent时代,共建AI安全防线
Agent的时代已经到来,它正在以前所未有的速度重塑我们的工作和认知。但技术的发展总是伴随着双刃剑,新的能力必然带来新的风险。Anthropic在设计 Skills 规范时,将大部分安全责任留给了用户和开发者。但这对于大多数人来说,门槛太高了。我们不能指望每个用户都成为安全专家,去审计每一个技能的每一行文档与代码。

这正是我们不断迭代 A.I.G 这个开源AI红队安全测试平台的初衷。我们相信,只有构建起强大的、自动化的 AI 安全免疫体系,让安全能力像水和电一样触手可及,我们才能真正安心地拥抱这个激动人心的 Agent 时代。从2025年1月开源至今,我们非常高兴的看到了整个行业对AI安全的关注度正在快速提升,越来越多的人正在加入到共建AI安全防线的队伍中来。
2026年,我们将继续诚邀所有AI开发者和用户,与我们一起,共同为构建一个更安全、更可信的 Agent 生态贡献力量。
【附】A.I.G项目开源地址:https://github.com/Tencent/AI-Infra-Guard
参考链接:
1.https://github.com/anthropics/skills
3.https://www.catonetworks.com/blog/cato-ctrl-weaponizing-claude-skills-with-medusalocker/
4.https://x.com/shao__meng/status/2013608161773862948
5.https://arxiv.org/pdf/2601.10338
注明:本文部分配图为 AI 生成。