Flink部署模式与运行模式与历史服务器
简介
Flink 是一个多功能框架,以混合搭配的方式支持许多不同的部署场景。
JobManager 将工作分发到 TaskManager,其中运行实际运算符(例如源、转换和接收器)。
Flink的官网上有一段话Overview | Apache Flink
Flink can execute applications in one of three ways:
in Application Mode,
in a Per-Job Mode,
in Session Mode.
The above modes differ in:
the cluster lifecycle and resource isolation guarantees
whether the application's main() method is executed on the client or on the cluster.大意为:
Flink 可以通过以下三种方式之一执行应用程序:
- 在应用程序模式下,
- 在单作业模式下,
- 在会话模式下。
上述模式的不同之处在于:
- 集群生命周期和资源隔离保障
- 应用程序的方法是在客户端上还是在集群上执行。
main()
Session Mode
会话模式:
我们需要先启动一个集群,保持一个会话,在这个会话当中通过客户端提交作业。
集群启动的时候所有的资源已经确定,所以提交的作业会竞争集群中的资源。
特点
- 需要启动集群
- 多个作业共享集群资源
- 作业之间相互影响
- 取消作业不会对集群产生影响
适用场景:单个规模小、执行时间短的大量作业
Per-Job Mode
单作业模式(已经过时了)
在我们了解了会话模式以后发现一个问题,就是任务提交到集群以后,作业自由的竞争资源,很容易发生碰撞,为了确保任务的隔离性,于是发明了但作业模式;
要注意的是Flink本身无法直接这样运行,所以单作业一般需要借助一些外部框架,比如说YARN;
特点
- 不需要先启动集群
- 每个作业启动一个集群
- 作业之间互不影响
- 取消作业集群停止
不利于应用的整体性;有可能某些任务崩了,但是任务之间互不察觉
Application Mode
应用模式(推荐)
前面的两种模式都是在客户端上执行,然后由客户端提交给JobManager的,这种方式客户端需要占用大量的网络带宽,把二进制数据发给JobManager,加上很多情况下我们提交的作业的作用是同一个客户端。会造成节点资源的消耗;
所以我们直接把任务提交到JobManager上运行,所以,一个任务配一个JobManager,所以任务完成以后,JobManager就关闭了;
特点
取消作业会对集群产生影响,确保了我们应用的完整型;
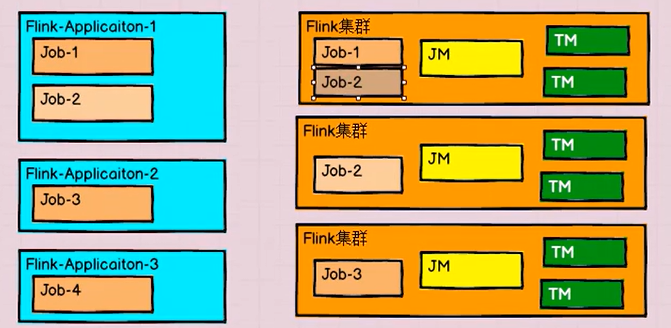
应用模式和单作业模式都是提交作业之后才创建集群,单作业需要客户端提交;而应用模式是直接由JobManager执行程序;
Standalone运行模式
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
会话模式部署
我们在上一节中使用的就是StandLone模式的会话模式
提前启动集群,并通过Web页面客户端提交任务
单作业模式部署
Flink的Standalone集群并不支持单作业模式部署
应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本
环境准备
环境准备。在被监听节点中执行以下命令启动netcat。
[root@jobmanager ~]# nc -lk 8888进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
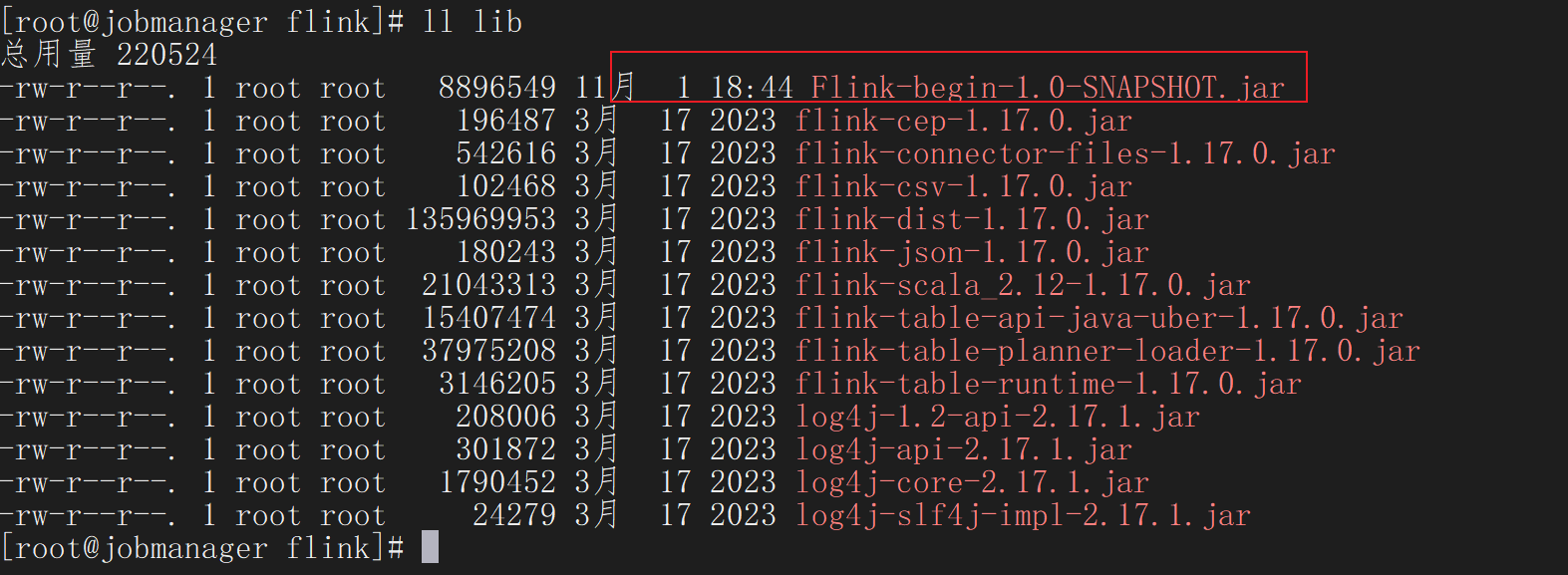
启动JobManager
shell
bin/standalone-job.sh start --job-classname com.KangKing.start01.Flink_UnBound_Stream启动TaskManager
bin/taskmanager.sh start
shell
[root@jobmanager flink]# bin/standalone-job.sh start --job-classname com.KangKing.start01.Flink_UnBound_Stream
Starting standalonejob daemon on host jobmanager.
[root@jobmanager flink]# bin/taskmanager.sh start
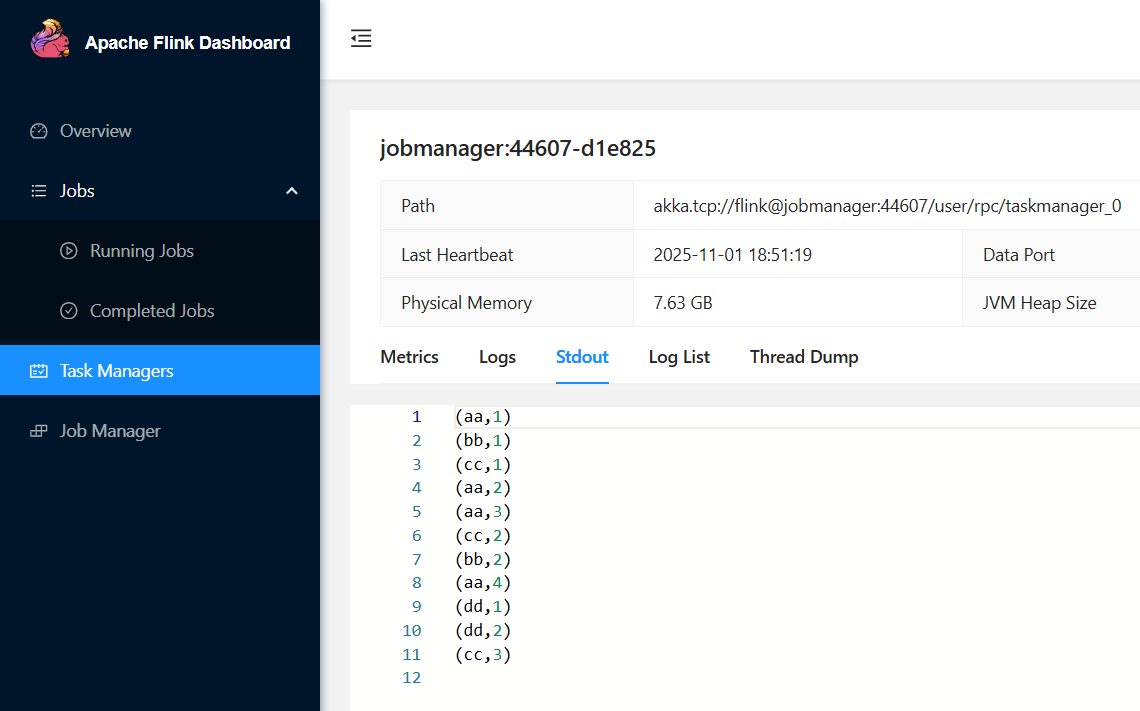
Starting taskexecutor daemon on host jobmanager.观察
在jobmamager:8081地址中观察输出数据
停止集群
(6)如果希望停掉集群,同样可以使用脚本,命令如下。
shell
[root@jobmanager flink]# bin/taskmanager.sh stop
Stopping taskexecutor daemon (pid: 3151) on host jobmanager.
[root@jobmanager flink]# bin/standalone-job.sh stop
No standalonejob daemon (pid: 2796) is running anymore on jobmanager.YARN运行模式
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
相关准备和配置
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
jobManager节点
shell
[kangking@jobmanager ~]$ start-dfs.sh
Starting namenodes on [jobmanager]
Starting datanodes
Starting secondary namenodes [tasktwo]
[kangking@jobmanager ~]$ jps
4832 Jps
4425 DataNode
4809 NodeManager
4300 NameNodetaskone节点
shell
[kangking@taskone ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[kangking@taskone ~]$ jps
3090 NodeManager
3220 Jps
2955 ResourceManager
2557 DataNode
[kangking@taskone ~]$tasktwo节点
shell
[root@tasktwo ~]# jps
2657 SecondaryNameNode
2817 NodeManager
2565 DataNode
2990 Jps
[root@tasktwo ~]#会话模式部署
执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群。
- 启动Hadoop集群(HDFS、YARN)
- 执行申请资源命令
shell
[kangking@jobmanager flink]$ bin/yarn-session.sh -nm test这里对参数进行解释
-
-d: 分离模式,将不想让Flink YARN在前端运行,YARN会话可以在后台运行(这个-d需要放在其他参数前面,否则不会生效)
-
-jm:配置JobManager所需要的内存,单位是MB
-
-nm:在YARN UI上显示任务
-
-qu:指定yarn队列名
-
-tm:配置每个TaskManager所需要的内存
注意Flink1.11不再舍弃了参数-n和-s分别指定TaskManager和Slot的数量,这里交给Yarn动态分配
在成功分配以后会给出UI界面的地址和任务的ApplicationID,当然我们也可以直接在YARN里面访问UI
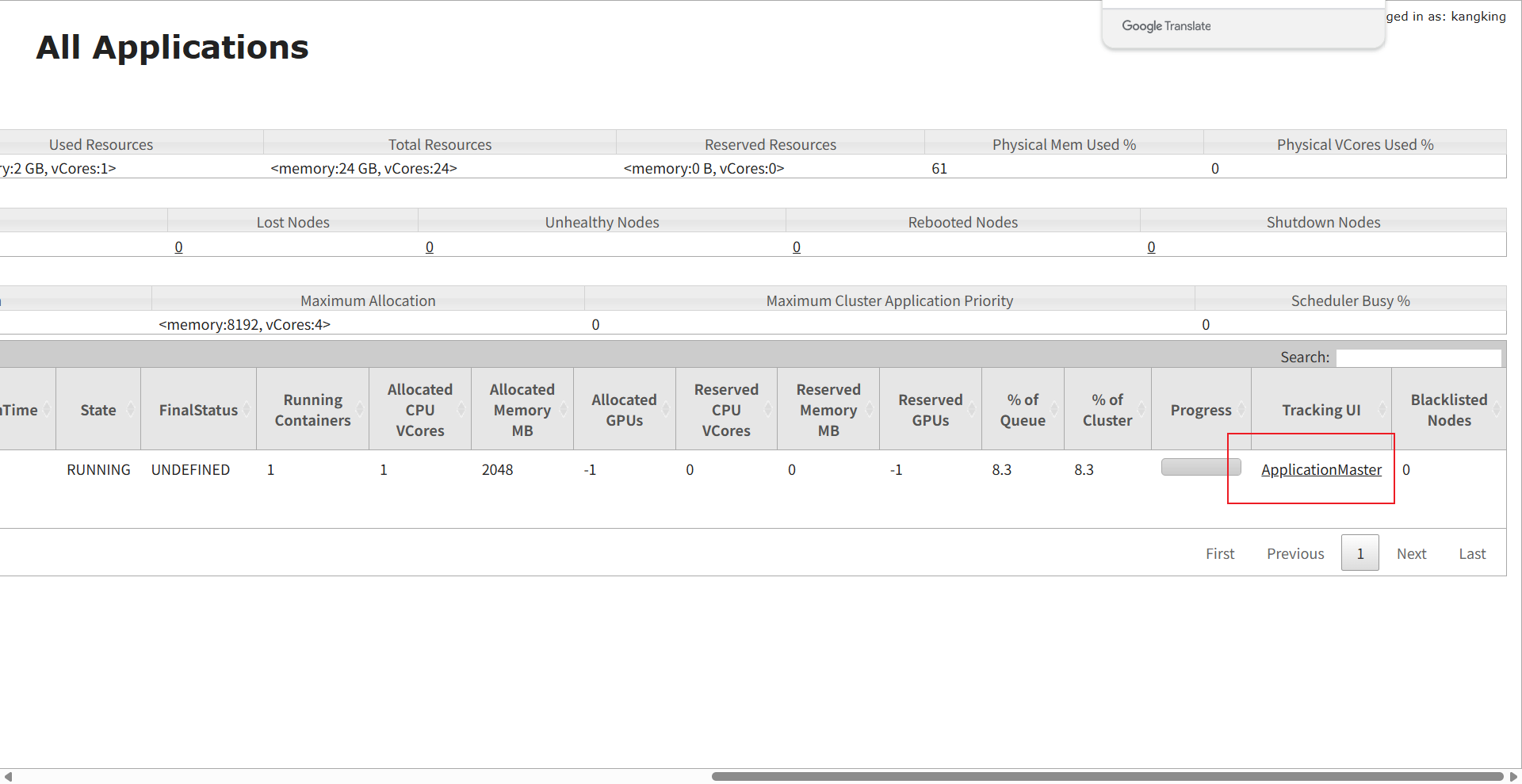
作业提交
web提交:与前面的独立部署模式相同,这里不过多赘述
指令提交:
将打包好的jar包上传集群
执行命令提交到YARN集群
shell
[root@jobmanager flink]# bin/flink run -t yarn-session \
-Dyarn.application.id=<Appliaction ID> \
-c com.KangKing.start01.Flink_UnBound_Stream \
Flink-begin-1.0-SNAPSHOT.jar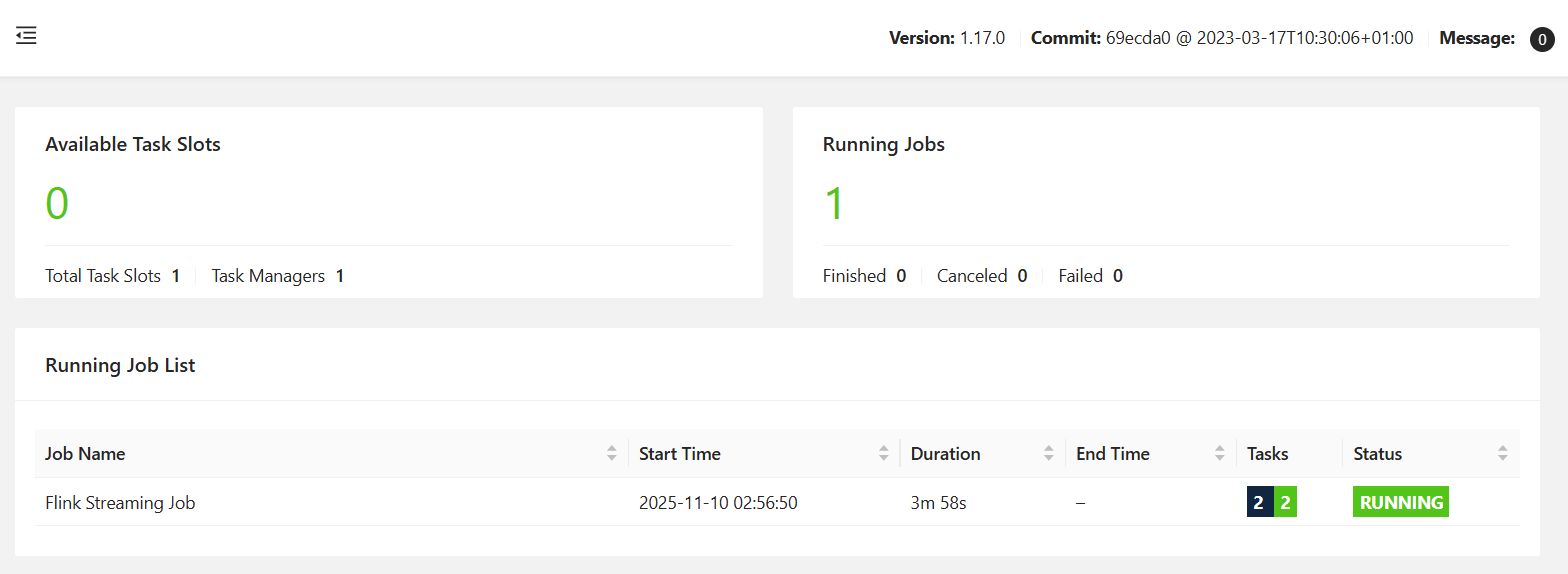
成功提交
作业的查看与取消:
shell
#查看作业
[kangking@jobmanager flink]$ bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
#取消作业
[kangking@jobmanager flink]$ bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>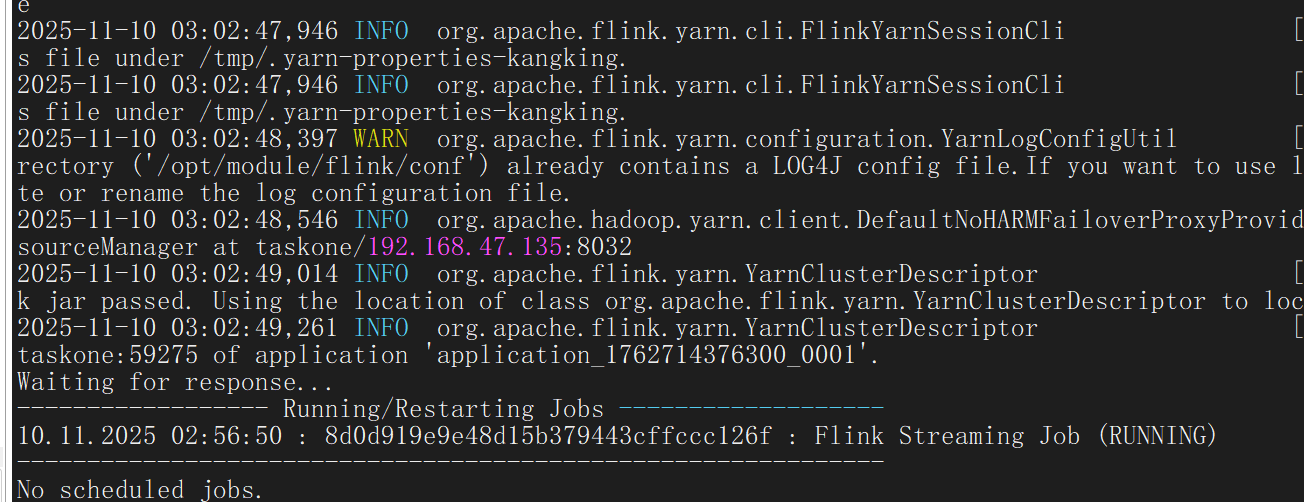
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
(1)上传flink的lib和plugins到HDFS上
shell
hadoop fs -mkdir /flink-dist
hadoop fs -put lib/ /flink-dist
hadoop fs -put plugins/ /flink-dist(2)上传自己的jar包到HDFS
shell
hadoop fs -mkdir /flink-jars
hadoop fs -put FlinkTutorial-1.0-SNAPSHOT.jar /flink-jars(3)提交作业
shell
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://jobManager:8020/flink-dist" -c com.KangKing.start01.Flink_UnBound_Stream hdfs://jobManager:8020/flink-jars/Flink-begin-1.0-SNAPSHOT.jar这种方式下,flink本身的依赖和用户jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。
History Server
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:任务运行时的相关配置。
创建存储目录
hadoop fs -mkdir -p /logs/flink-job配置flink.conf
shell
jobmanager.archive.fs.dir: hdfs://jobManager:8020/logs/flink-job
historyserver.web.address: jobManager
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://jobManager:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000启动历史服务器
shell
bin/historyserver.sh start停止历史服务器
shell
bin/historyserver.sh stop浏览器访问jobManager:8082可以看到Job的记录