个人学习的笔记,希望帮助能到和我一样阅读Cortex-M3权威指南Cn遇到困难的人。
强烈建议先阅读Cortex-M3权威指南Cn第四、五章在来观看笔记
在cortex m3 中,c语言与汇编代码区别
首先我们需要树立一个观念:汇编是"机器的思考方式",C是"人的思考方式"
只有理解了这句话你才能正真理解这两者的区别!!!
抽象层级的不同:
C语言(高级语言):
c
int result = a + b * 2;编译器自动处理:
- 选择哪个寄存器放 a
- 选择哪个寄存器放 b
- 如何实现乘法(用乘法指令还是移位+加法)
- 结果的存储位置
汇编语言(低级语言):
assembly
; 假设 a 在 R0,b 在 R1
LDR R0, [SP, #4] ; 加载 a 到 R0
LDR R1, [SP, #8] ; 加载 b 到 R1
LSL R2, R1, #1 ; b * 2 (左移1位 = 乘以2)
ADD R0, R0, R2 ; a + (b*2)
STR R0, [SP, #12] ; 存储结果必须手动思考每一步!
硬件直接暴露:
汇编语言让你直接面对硬件的所有细节:
| 硬件细节 | 汇编必须处理 | C语言自动处理 |
|---|---|---|
| 寄存器分配 | 手动选择使用哪个寄存器 | 编译器自动分配 |
| 内存访问 | 明确指定加载/存储地址 | 变量自动映射到内存 |
| 指令选择 | 必须选择具体指令(ADD/SUB/MUL) | 运算符自动转换为指令 |
| 条件执行 | 必须设置条件标志并分支 | if/else 自动处理 |
| 调用约定 | 手动保存/恢复寄存器 | 函数调用自动处理 |
**CPU只有有限的 "智能" **
CPU本质上是一个状态机,它只知道:
- 执行当前指令
- 根据结果设置标志位
- 根据标志位决定下一条指令
assembly
CMP R0, R1 ; 比较 R0 和 R1
BEQ equal ; 如果相等(Z=1),跳转到 equal
BGT greater ; 如果大于(Z=0且N=V),跳转到 greater
BLT less ; 如果小于(N!=V),跳转到 less
B somewhere ; 否则跳转到 somewhere
equal:
; 相等的情况
greater:
; 大于的情况
less:
; 小于的情况而在C语言中:
c
if (a == b) {
// 相等
} else if (a > b) {
// 大于
} else {
// 小于
}详细对比:条件判断的实现
C语言版本(简洁):
c
// 计算绝对值
int abs(int x) {
if (x < 0) {
return -x;
} else {
return x;
}
}ARM汇编版本(详细):
assembly
abs:
CMP R0, #0 ; 比较 R0 和 0
BGE positive ; 如果 >= 0,跳转到 positive
; 负数情况
RSB R0, R0, #0 ; 计算 0 - R0,即取负
BX LR ; 返回
positive:
; 正数情况,R0 已经是结果
BX LR ; 返回c语言与汇编与编译器:
1. 汇编语言是"第一代"编程语言
- 最初程序员直接在纸带上打孔表示二进制指令
- 汇编语言是助记符,已经是巨大的进步
- 每个指令直接对应一个机器码
2. C语言是"第三代"编程语言 - 设计目标:让程序员专注算法,而非机器细节
- 引入关键抽象:
- 变量(而不是寄存器/内存地址)
- 表达式(而不是单个指令序列)
- 控制结构(而不是跳转标签)
- 函数(而不是子程序调用约定)
3. 编译器是"桥梁"
c
// C代码
int factorial(int n) {
if (n <= 1) return 1;
return n * factorial(n-1);
}
// 编译器生成的汇编(简化)
factorial:
CMP R0, #1 ; 比较 n 和 1
BGT recursive ; 如果大于1,递归
; 基本情况
MOV R0, #1 ; 返回 1
BX LR
recursive:
PUSH {LR, R0} ; 保存返回地址和 n
SUB R0, R0, #1 ; n-1
BL factorial ; 递归调用
POP {LR, R1} ; 恢复 LR 和原始 n
MUL R0, R1, R0 ; n * factorial(n-1)
BX LR汇编在嵌入式中的特点:
精确控制:
有时候你需要极致的控制:
assembly
; 精确的延时循环
delay:
MOV R0, #1000000 ; 1百万次
loop:
SUBS R0, R0, #1 ; 减1,同时设置标志
BNE loop ; 不为0则继续循环
BX LR特殊硬件操作:
assembly
; 启动DMA传输
MOV R0, #SOURCE_ADDR
MOV R1, #DEST_ADDR
MOV R2, #SIZE
STR R0, [DMA_SRC_REG] ; 设置源地址
STR R1, [DMA_DST_REG] ; 设置目标地址
STR R2, [DMA_CTRL_REG] ; 启动传输优化关键代码:
c
// C代码:简单的内存复制
void copy_memory(void* dst, void* src, int size) {
for (int i = 0; i < size; i++) {
((char*)dst)[i] = ((char*)src)[i];
}
}
assembly
; 优化的汇编版本:使用LDM/STM批量传输
copy_memory:
PUSH {R4-R11} ; 保存寄存器
; 使用8个寄存器一次复制32字节
copy_loop:
LDMIA R1!, {R4-R11} ; 从源加载8个寄存器
STMIA R0!, {R4-R11} ; 存储到目标
SUBS R2, R2, #32 ; 减少计数
BGT copy_loop ; 如果>0,继续
POP {R4-R11} ; 恢复寄存器
BX LR何时用C语言?
- 应用程序开发
- 算法实现
- 跨平台项目
- 快速原型开发
何时用汇编语言?
- 操作系统内核(上下文切换、中断处理)
- 设备驱动程序
- 实时系统(精确时序控制)
- 性能关键例程(加密、视频编解码)
- 引导代码(Bootloader)
混合编程的典型模式
c
// C代码调用汇编函数
extern void fast_memcpy(void* dst, void* src, int size);
int main() {
char src[100], dst[100];
fast_memcpy(dst, src, 100); // 调用优化的汇编函数
return 0;
}
assembly
; 汇编实现
.global fast_memcpy
fast_memcpy:
; 高度优化的内存复制
; ...
BX LR在cortex m3 中,常用Thumb-2 指令集
Cortex-M3 使用 Thumb-2 指令集,这是 16 位和 32 位指令的混合体。
一、数据传输指令
寄存器间数据传输
assembly
MOV R0, R1 ; R0 = R1(寄存器间移动)
MOV R0, #0x1234 ; R0 = 0x1234(立即数加载)
MVN R0, R1 ; R0 = ~R1(按位取反后移动)内存加载(Load)指令
assembly
LDR R0, [R1] ; R0 = *R1(从R1指向的地址加载32位)
LDRB R0, [R1] ; R0 = *(uint8_t*)R1(加载8位)
LDRH R0, [R1] ; R0 = *(uint16_t*)R1(加载16位)
LDR R0, [R1, #4] ; R0 = *(R1 + 4)(带偏移)
LDR R0, [R1, R2] ; R0 = *(R1 + R2)(寄存器索引)
LDR R0, [R1, R2, LSL #2] ; R0 = *(R1 + (R2 << 2))
LDR R0, =label ; R0 = label的地址(伪指令,实际是PC相对加载)内存存储(Store)指令
assembly
STR R0, [R1] ; *R1 = R0(存储32位)
STRB R0, [R1] ; *(uint8_t*)R1 = R0(存储8位)
STRH R0, [R1] ; *(uint16_t*)R1 = R0(存储16位)
STR R0, [R1, #-4]! ; 先R1=R1-4,然后*R1=R0(先减后存)
STR R0, [R1], #4 ; 先*R1=R0,然后R1=R1+4(先存后加)多寄存器加载/存储
assembly
LDMIA R0!, {R1-R4} ; 从R0地址加载R1-R4,然后R0+=16
; IA = Increment After(加载后地址增加)
STMDB R0!, {R1-R4} ; 先R0-=16,然后存储R1-R4到R0地址
; DB = Decrement Before(存储前地址减少)
; 常见用途:
PUSH {R0-R3, LR} ; 等价于 STMDB SP!, {R0-R3, LR}
POP {R0-R3, PC} ; 等价于 LDMIA SP!, {R0-R3, PC}二、算术运算指令
基本算术
assembly
ADD R0, R1, R2 ; R0 = R1 + R2
ADD R0, R1, #10 ; R0 = R1 + 10
ADD R0, #1 ; R0 = R0 + 1(某些汇编器支持)
SUB R0, R1, R2 ; R0 = R1 - R2
SUB R0, R1, #5 ; R0 = R1 - 5
RSB R0, R1, #0 ; R0 = 0 - R1(反向减法,常用于取负)乘除运算
assembly
MUL R0, R1, R2 ; R0 = R1 × R2
MLA R0, R1, R2, R3 ; R0 = (R1 × R2) + R3(乘加)
; Cortex-M3 没有硬件除法指令!
; 除法需要通过软件库或移位实现比较与测试
assembly
CMP R0, R1 ; 比较 R0 和 R1,设置标志位但不保存结果
; 等价于 SUBS R0, R1,但不保存到寄存器
CMN R0, R1 ; 比较 R0 和 -R1(取负比较)
TST R0, R1 ; 测试位:R0 & R1,设置标志位
TEQ R0, R1 ; 测试相等:R0 ^ R1,设置标志位三、逻辑与移位指令
逻辑运算
assembly
AND R0, R1, R2 ; R0 = R1 & R2(按位与)
ORR R0, R1, R2 ; R0 = R1 | R2(按位或)
EOR R0, R1, R2 ; R0 = R1 ^ R2(按位异或)
BIC R0, R1, R2 ; R0 = R1 & ~R2(位清除)
ORN R0, R1, R2 ; R0 = R1 | ~R2(或非)移位操作
assembly
LSL R0, R1, #3 ; R0 = R1 << 3(逻辑左移)
LSR R0, R1, #2 ; R0 = R1 >> 2(逻辑右移)
ASR R0, R1, #4 ; R0 = R1 >> 4(算术右移,保持符号)
ROR R0, R1, #8 ; R0 = R1 循环右移8位
RRX R0, R1 ; R0 = (R1 >> 1) | (C << 31)(带进位右移1位)
; 可变移位(由寄存器指定移位量)
LSL R0, R1, R2 ; R0 = R1 << R2*四、分支与控制流指令
无条件分支
assembly
B label ; 跳转到 label(相对跳转,±32MB范围)
BX R0 ; 跳转到 R0 指定的地址(可切换指令集状态)
BL label ; 跳转到 label,同时将返回地址存入 LR
BLX R0 ; 跳转到 R0,同时将返回地址存入 LR条件分支(基于 APSR 标志位)
assembly
BEQ label ; Z=1(相等)时跳转
BNE label ; Z=0(不相等)时跳转
BHS/BCS label ; C=1(无符号大于等于)时跳转
BLO/BCC label ; C=0(无符号小于)时跳转
BMI label ; N=1(负数)时跳转
BPL label ; N=0(正数)时跳转
BVS label ; V=1(溢出)时跳转
BVC label ; V=0(无溢出)时跳转
BHI label ; C=1且Z=0(无符号大于)时跳转
BLS label ; C=0或Z=1(无符号小于等于)时跳转
BGE label ; N=V(有符号大于等于)时跳转
BLT label ; N!=V(有符号小于)时跳转
BGT label ; Z=0且N=V(有符号大于)时跳转
BLE label ; Z=1或N!=V(有符号小于等于)时跳转条件执行(IT 指令块)
assembly
CMP R0, #10 ; 比较 R0 和 10
ITTEE GT ; If-Then-Then-Else-Else
; 条件为 GT 时执行前两条,否则执行后两条
MOVGT R1, #1 ; 条件指令1
MOVGT R2, #2 ; 条件指令2
MOVLE R1, #0 ; 条件指令3
MOVLE R2, #0 ; 条件指令4五、特殊寄存器访问指令
读写特殊寄存器
assembly
MRS R0, APSR ; 读取 APSR 到 R0
MRS R0, IPSR ; 读取 IPSR 到 R0
MRS R0, EPSR ; 读取 EPSR 到 R0
MRS R0, CONTROL ; 读取 CONTROL 寄存器
MRS R0, MSP ; 读取主堆栈指针
MRS R0, PSP ; 读取进程堆栈指针
MRS R0, PRIMASK ; 读取 PRIMASK
MRS R0, FAULTMASK ; 读取 FAULTMASK
MRS R0, BASEPRI ; 读取 BASEPRI
MSR APSR, R0 ; 将 R0 写入 APSR
MSR CONTROL, R0 ; 将 R0 写入 CONTROL
; ... 其他类似- 快速中断控制
assembly
CPSID I ; 禁用中断(设置 PRIMASK=1)
CPSIE I ; 启用中断(清除 PRIMASK=0)
CPSID F ; 禁用 Fault(设置 FAULTMASK=1)
CPSIE F ; 启用 Fault(清除 FAULTMASK=0)六、堆栈操作指令
压栈/出栈
assembly
PUSH {R0-R3, LR} ; 将 R0-R3 和 LR 压入堆栈
POP {R0-R3, PC} ; 从堆栈弹出到 R0-R3 和 PC(函数返回)
; 等价于:
; STMDB SP!, {R0-R3, LR}
; LDMIA SP!, {R0-R3, PC}堆栈指针操作
assembly
ADD SP, SP, #16 ; 释放16字节栈空间
SUB SP, SP, #32 ; 分配32字节栈空间七、系统与特权指令
系统调用
assembly
SVC #0x01 ; 触发 SVC 异常,编号为1
; 用于系统调用(如 RTOS 服务)等待与休眠
assembly
WFI ; 等待中断(进入低功耗模式)
WFE ; 等待事件
SEV ; 发送事件(唤醒等待的 CPU)断点
assembly
BKPT #0xAB ; 软件断点(用于调试器)八、屏障指令
数据屏障
assembly
DMB ; 数据内存屏障
; 确保屏障前的所有内存访问在后续访问前完成数据同步屏障
assembly
DSB ; 数据同步屏障
; 确保屏障前的所有内存访问完成后才执行后续指令指令同步屏障
assembly
ISB ; 指令同步屏障
; 清空流水线,确保所有之前指令的效果可见
; 典型用法:修改系统寄存器后
MSR CONTROL, R0
ISB ; 确保 CONTROL 修改生效后再执行后续指令九、伪指令与特殊指令
伪指令(汇编器扩展)
assembly
NOP ; 空操作(实际是 MOV R8, R8)
LDR R0, =0x12345678 ; 加载任意32位立即数(汇编器自动处理)
ADR R0, label ; 加载 label 的相对地址饱和运算
assembly
SSAT R0, #16, R1 ; 有符号饱和到16位
USAT R0, #8, R1 ; 无符号饱和到8位字节序操作
assembly
REV R0, R1 ; 反转字节序(32位)
REV16 R0, R1 ; 反转每两个字节的顺序
REVSH R0, R1 ; 反转半字并符号扩展十、指令后缀与条件码
条件码后缀
几乎任何指令都可以条件执行:
assembly
ADDEQ R0, R1, R2 ; 当 Z=1(相等)时执行加法
MOVNE R0, #1 ; 当 Z=0(不相等)时执行移动S 后缀(更新标志位)
assembly
ADDS R0, R1, R2 ; 执行加法,并更新 APSR 标志位
SUBS R0, R1, #1 ; 执行减法,并更新标志位
MOVS R0, #0 ; 移动并更新标志位(常用于清零并设置 Z=1)- 宽度后缀
assembly
ADD.W R0, R1, R2 ; 强制使用32位编码
ADD.N R0, R1, R2 ; 强制使用16位编码(如果可能)实际代码示例
示例1:简单函数
assembly
; 函数:int add(int a, int b)
add:
ADD R0, R0, R1 ; R0 = a + b(参数在 R0, R1,结果在 R0)
BX LR ; 返回
; 调用:
MOV R0, #10 ; a = 10
MOV R1, #20 ; b = 20
BL add ; 调用函数
; 结果在 R0 = 30示例2:循环与条件
assembly
; 计算 strlen(字符串长度)
strlen:
MOV R1, R0 ; R1 = 字符串指针
MOV R0, #0 ; R0 = 长度计数器
loop:
LDRB R2, [R1], #1 ; 加载字节,指针+1
CMP R2, #0 ; 比较是否为'\0'
BEQ done ; 如果是,结束
ADD R0, R0, #1 ; 长度+1
B loop
done:
BX LR ; 返回长度示例3:中断处理框架
assembly
HardFault_Handler:
PUSH {R0-R3, R12, LR} ; 保存上下文
MRS R0, MSP ; 获取堆栈指针
BL hard_fault_handler_c ; 调用 C 处理函数
POP {R0-R3, R12, LR} ; 恢复上下文
BX LR ; 返回(实际上是异常返回)示例4:临界区保护
assembly
enter_critical:
MRS R0, PRIMASK ; 保存当前中断状态
CPSID I ; 禁用中断
BX LR ; 返回,R0 包含旧 PRIMASK
exit_critical:
MSR PRIMASK, R0 ; 恢复中断状态
BX LR注意:
寄存器约定:
- R0-R3:参数传递和临时寄存器
- R4-R11:需要保存的寄存器(被调用者保存)
- R12 (IP):临时寄存器
- R13 (SP):堆栈指针
- R14 (LR):链接寄存器
- R15 (PC):程序计数器
指令宽度: - 16位指令:代码密度高
- 32位指令:功能更强大
- 汇编器通常自动选择
对齐要求: - ARM指令必须对齐到2字节边界
- 32位Thumb指令必须对齐到4字节边界
条件执行: - 大多数算术和逻辑指令可以条件执行
- 通过IT指令块实现复杂的条件执行
在cortex m3 中,为什么位带区有1MB但是内核中却分配了512MB
在分析这个问题前首先需要了解:
- 位带不是一个独立的新存储区 ,而是一个地址重映射机制 。它的实现需要硬件电路来实时转换地址。
- 512MB的区是整个Cortex-M3为所有芯片制造商预留的"虚拟"地址范围,而1MB的位带区是这个范围内的一个具有特殊硬件功能的"固定"区域。
- 根本原则:地址空间 ≠ 物理存储器
即:1MB位带区 属于内核架构层面的一个固定功能特性 。ARM在设计Cortex-M3时,就决定在其中加入位带操作这个高效的硬件特性。512MB的SRAM区 则是内核架构为芯片厂商预留的"虚拟"地址范围 。ARM在规划这张4GB的"内存地图"时,决定把其中一块512MB的大区域划出来,专门用于连接"内部SRAM"。你可以把它看作一大片"预留用地"。
简单点来说:512MB只是一个预留的地址空间,并没有实际的储存空间介质。而且但并不是所有的存储器都需要位带操作。通常,只有需要原子位操作的特殊标志位或控制寄存器才需要。(1MB位带区是为了覆盖关键的控制和状态寄存器 ,而剩下的空间则是嵌入式系统设计的可扩展性的体现)
如果还是无法理解,这里我们使用一个比喻来理解:
首先要理解的关键概念:
txt
地址空间是"地图",物理存储器是"实际的土地"
地图上画了很大区域,但实际建造的城市可能只占一小部分类比:城市规划的蓝图
想象一个新开发区的规划图:
txt
整个规划区:100平方公里(地址空间)
├── 已开发区域:5平方公里(实际芯片的物理存储器)
│ ├── 商业区:控制寄存器(位带区覆盖的关键部分)
│ ├── 住宅区:SRAM
│ └── 工业区:外设
└── **预留用地:95平方公里(剩下的地址空间)**
├── 未来扩建(芯片升级)
├── 不同配置(产品线分化)
└── 特殊用途(定制化需求)关键点 :所有使用cortex m3作为内核的单片机都使用相同的地址范围起始部分 ,但实际物理存储器大小不同。
位带区有1MB与剩余空间511MB的比喻:城市道路规划
txt
位带区就像城市中心的"特种车辆专用道"
─── 很小但关键,确保紧急车辆(关键位操作)快速通行
剩余空间就像城市规划中的"预留发展用地"
─── 现在可能空着,但为未来医院、学校、商业区(新外设、新存储器)预留位置
整个地址空间就像城市的"行政区划图"
─── 定义了每个区域的功能,但具体建设多少建筑由开发商(芯片厂商)决定位带区物理现实:
txt
物理现实:每个位 → 别名区一个32位字
1MB位带区 × 8位/字节 = 8,388,608个位
每个位映射到4字节 → 需要 33,554,432字节 = 32MB别名区位带区实际应用:
txt
SRAM区:0x20000000-0x3FFFFFFF(512MB)
↓
实际上是:**允许多个不同芯片**在这个地址范围内
布置它们的SRAM,每个芯片只占用一部分典型嵌入式应用:
在典型的嵌入式应用中,需要原子位操作的资源包括:
- GPIO引脚:通常每个引脚对应一个位,用于输入或输出。
- 状态标志:例如,任务就绪标志、事件标志等。
- 控制寄存器:例如,使能位、中断使能位等。
这些资源的总量通常很小。例如,一个微控制器可能有几十个GPIO引脚,几十个状态标志,以及几十个控制位。总共可能只需要几百个位,即几十个字节。1MB的位带区(对应8M位)远远超过了这个需求。
举例说明:STM32F103C8T6
芯片基本规格
STM32F103C8T6(中等容量增强型):
- Flash:64KB(0x0800 0000 - 0x0800 FFFF)
- SRAM:20KB(0x2000 0000 - 0x2000 4FFF)
- 系统存储器:2KB Bootloader(0x1FFF F000 - 0x1FFF F7FF)
- 选项字节:16字节(0x1FFF F800 - 0x1FFF F80F)
SRAM区域详细分析
1. 物理SRAM布局(20KB)
txt
0x2000 0000 - 0x2000 4FFF (20KB)
├── 0x2000 0000 - 0x2000 00FF (256B):启动时的栈区域
├── 0x2000 0100 - 0x2000 04FF (1KB):.data段(已初始化的全局变量)
├── 0x2000 0500 - 0x2000 08FF (1KB):.bss段(未初始化的全局变量)
├── 0x2000 0900 - 0x2000 3FFF (约14KB):堆(heap)区域
└── 0x2000 4000 - 0x2000 4FFF (4KB):栈(stack)增长区域实际内容:
- 全局变量:程序中的全局和静态变量
- 堆内存:动态分配的变量(malloc分配)
- 栈内存:局部变量、函数调用现场
- 特殊用途 :
- 中断向量表(如果重定位到SRAM)
- DMA缓冲区
- USB端点缓冲区
2. SRAM位带区(理论1MB,实际只使用前20KB)
位带区 :0x2000 0000 - 0x200F FFFF(理论1MB)
实际可用的位带操作:
- 只有前20KB(0x2000 0000 - 0x2000 4FFF)有物理SRAM支持位带
- 超出部分的位带操作会引发总线错误(HardFault)
常用的位带操作对象(在SRAM中):
- 任务状态标志:RTOS中任务就绪/等待标志
- 事件标志组:任务间通信的事件标志
- 软件信号量:通过位操作实现的简单信号量
- 状态机状态位:控制状态机的各个状态
- 错误标志位 :记录各类错误状态
例子:
txt
地址 0x2000 0100 的位0:任务1就绪标志
地址 0x2000 0100 的位1:任务2就绪标志
地址 0x2000 0100 的位2:UART接收完成标志
地址 0x2000 0100 的位3:定时器溢出标志位带别名区:0x2200 0000 - 0x23FF FFFF(32MB)
- 对应位带区每个位的别名地址
- 只有对应物理SRAM存在的部分才有效
3. SRAM剩余空间(0x2000 5000 - 0x3FFF FFFF)
这部分完全没有物理存储器 ,访问会触发HardFault。
为什么存在?
- 架构兼容性:保持Cortex-M3标准存储器映射
- 未来扩展:STM32F103系列更高型号(如F103RC有48KB SRAM)会使用更多地址
- 调试陷阱 :帮助捕获非法指针访问(访问这些地址立即出错)
实际访问后果:
txt
尝试访问 0x2000 5000(超出20KB)
↓
总线错误
↓
触发 HardFault_Handler()
↓
程序崩溃或进入错误处理外设区域详细分析
1. 物理外设布局
STM32F103C8T6的外设分布在0x4000 0000 - 0x4002 3400 范围内(约140KB),主要外设组:
AHB总线外设(0x4001 8000 - 0x4002 3400)
txt
0x4001 8000 - 0x4001 83FF: SDIO(但C8T6没有,保留)
0x4002 0000 - 0x4002 03FF: GPIOA
0x4002 0400 - 0x4002 07FF: GPIOB
0x4002 0800 - 0x4002 0BFF: GPIOC(C8T6只有PC13-15)
0x4002 0C00 - 0x4002 0FFF: GPIOD(C8T6没有)
0x4002 1000 - 0x4002 13FF: GPIOE(C8T6没有)
0x4002 1400 - 0x4002 17FF: GPIOF(C8T6没有)
0x4002 1800 - 0x4002 1BFF: GPIOG(C8T6没有)
0x4002 1C00 - 0x4002 1FFF: AFIO(复用功能I/O)
0x4002 1000 - 0x4002 13FF: 保留
0x4002 1400 - 0x4002 17FF: 保留
0x4002 2000 - 0x4002 23FF: EXTI(外部中断)
0x4002 1000 - 0x4002 13FF: 保留APB2总线外设(0x4001 0000 - 0x4001 7FFF)
txt
0x4001 0000 - 0x4001 03FF: SPI1
0x4001 0400 - 0x4001 07FF: 保留
0x4001 0800 - 0x4001 0BFF: USART1
0x4001 0C00 - 0x4001 0FFF: USART2(C8T6没有)
0x4001 1000 - 0x4001 13FF: USART3(C8T6没有)
0x4001 1400 - 0x4001 17FF: 保留
0x4001 1800 - 0x4001 1BFF: I2C1
0x4001 1C00 - 0x4001 1FFF: I2C2(C8T6没有)
0x4001 2000 - 0x4001 23FF: 保留
0x4001 2400 - 0x4001 27FF: 保留
0x4001 2800 - 0x4001 2BFF: 保留
0x4001 2C00 - 0x4001 2FFF: 保留
0x4001 3000 - 0x4001 33FF: 保留
0x4001 3400 - 0x4001 37FF: 保留
0x4001 3800 - 0x4001 3BFF: 保留
0x4001 3C00 - 0x4001 3FFF: 保留
0x4001 4000 - 0x4001 43FF: 保留
0x4001 4400 - 0x4001 47FF: 保留
0x4001 4800 - 0x4001 4BFF: 保留
0x4001 4C00 - 0x4001 4FFF: 保留
0x4001 5000 - 0x4001 53FF: 保留
0x4001 5400 - 0x4001 57FF: 保留
0x4001 5800 - 0x4001 5BFF: 保留
0x4001 5C00 - 0x4001 5FFF: BKP(备份寄存器)
0x4001 6000 - 0x4001 63FF: PWR(电源控制)
0x4001 6800 - 0x4001 6BFF: DAC(C8T6没有)
0x4001 7000 - 0x4001 73FF: 保留(CEC,C8T6没有)APB1总线外设(0x4000 0000 - 0x4000 7FFF)
txt
0x4000 0000 - 0x4000 03FF: TIM2(通用定时器)
0x4000 0400 - 0x4000 07FF: TIM3(通用定时器)
0x4000 0800 - 0x4000 0BFF: TIM4(通用定时器)
0x4000 0C00 - 0x4000 0FFF: 保留
0x4000 1000 - 0x4000 13FF: 保留
0x4000 1400 - 0x4000 17FF: 保留
0x4000 1C00 - 0x4000 1FFF: 保留
0x4000 2000 - 0x4000 23FF: RTC(实时时钟,通过BKP访问)
0x4000 2400 - 0x4000 27FF: WWDG(窗口看门狗)
0x4000 2800 - 0x4000 2BFF: IWDG(独立看门狗)
0x4000 2C00 - 0x4000 2FFF: 保留(SPI2,但C8T6的SPI2在APB2?实际没有)
0x4000 3000 - 0x4000 33FF: USART2(实际APB1)
0x4000 3400 - 0x4000 37FF: USART3(C8T6没有)
0x4000 3800 - 0x4000 3BFF: 保留
0x4000 3C00 - 0x4000 3FFF: I2C1(实际在APB2,这里是保留)
0x4000 4000 - 0x4000 43FF: I2C2(C8T6没有)
0x4000 4400 - 0x4000 47FF: 保留
0x4000 4800 - 0x4000 4BFF: 保留
0x4000 4C00 - 0x4000 4FFF: 保留
0x4000 5000 - 0x4000 53FF: 保留
0x4000 5400 - 0x4000 57FF: 保留
0x4000 5800 - 0x4000 5BFF: 保留
0x4000 5C00 - 0x4000 5FFF: 保留
0x4000 6000 - 0x4000 63FF: CAN(C8T6没有)
0x4000 6400 - 0x4000 67FF: 保留
0x4000 6800 - 0x4000 6BFF: 保留
0x4000 6C00 - 0x4000 6FFF: 保留
0x4000 7000 - 0x4000 73FF: 保留
0x4000 7400 - 0x4000 77FF: 保留2. 外设位带区(0x4000 0000 - 0x400F FFFF)
实际可进行位带操作的外设 (只有实际存在的外设寄存器):
常用位带操作的外设位:
- GPIO引脚控制(最常用的位带应用):
txt
GPIOA_ODR 寄存器(0x4001 080C)的各个位:
- 位0:PA0输出状态
- 位1:PA1输出状态
- ...
- 位7:PA7输出状态
通过位带可以原子地设置/清除单个引脚,不干扰其他引脚。中断标志位清除:
txt
EXTI_PR 寄存器(0x4001 0414):
- 位0:清除EXTI0中断挂起标志
- 位1:清除EXTI1中断挂起标志
- ...
清除中断标志需要写1,位带操作确保原子性。状态寄存器位:
txt
USART_SR 寄存器(0x4001 3800)的各个状态位
TIMx_SR 寄存器(0x4000 0010)的各个标志位控制寄存器使能位:
txt
TIMx_CR1 寄存器(0x4000 0000)的CEN位(计数器使能)
USART_CR1 寄存器(0x4001 380C)的UE位(USART使能)位带操作的实际限制:
- 只能对实际存在的物理寄存器进行位带操作
- 访问不存在的物理地址的位带别名会引发HardFault
- 某些寄存器可能不支持位带(如Flash接口寄存器)
3. 外设剩余空间(0x4002 3400 - 0x5FFF FFFF)
这部分地址空间在STM32F103C8T6上完全空置 :
分区域分析:
- 0x4002 3400 - 0x400F FFFF (约12.7MB):
- 为STM32F103更高型号的外设预留
- 例如:F103ZE的FSMC、SDIO、DAC等
- C8T6访问这些地址会触发总线错误
- 0x4010 0000 - 0x5FFF FFFF (约511MB):
- 为整个Cortex-M3产品线预留
- 可能用于:
- 其他STM32系列(F4/F7/H7)的额外外设
- 未来新外设
- 多核系统中的其他处理器外设
- 对C8T6来说,这些地址完全没有物理设备
实际意义 :
这些"空洞"地址空间起到重要作用:
- 地址解码简化:硬件只需检测地址是否在有效范围内
- 错误检测:非法访问立即被捕获
- 可扩展性:新产品可以添加外设而不改变架构
- 兼容性:软件可以检测设备是否存在(尝试访问并检查错误)
STM32F103C8T6的完整地址空间使用情况:
txt
4GB地址空间(0x0000 0000 - 0xFFFF FFFF)
├── 实际使用的物理存储器(<1MB)
│ ├── 代码区:64KB Flash @ 0x0800 0000
│ ├── SRAM区:20KB @ 0x2000 0000
│ ├── 外设区:约140KB @ 0x4000 0000
│ ├── 系统存储:2KB Bootloader @ 0x1FFF F000
│ └── 内核外设:约4KB @ 0xE000 E000
│
└── 空洞/保留空间(>3.9GB)
├── 未实现的SRAM和外设地址
├── 为更高型号预留的空间
└── 架构保留的未来扩展空间位带区的实用部分 :
SRAM位带有效区域:
- 物理:0x2000 0000 - 0x2000 4FFF(20KB)
- 对应别名区:0x2200 0000 - 0x2200 9FFF(40KB,因为每字节8位×4字节)
外设位带有效区域: - 物理:0x4000 0000 - 0x4002 3400中的实际寄存器
- 对应别名区:分散在0x4200 0000 - 0x4204 6800范围内
结论:
- 位带区1MB是理论最大值,实际可用部分取决于物理存储器大小
- STM32F103C8T6只能使用前20KB SRAM和约140KB外设的位带操作
- 超出物理存储器的位带操作会立即导致HardFault
- 剩余空间是设计使然 ,不是错误,它为系统提供了:
- 错误检测能力(捕获非法指针)
- 产品线扩展性
- 架构兼容性
什么是位带区
位带区(Bit Banding)
这是Cortex-M3内核的特性:
- 作用:实现单个位的原子操作
- 两个位带区 :
- SRAM位带区 :0x2000_0000 - 0x200F_FFFF
- 位带别名区:0x2200_0000 - 0x23FF_FFFF
- 外设位带区 :0x4000_0000 - 0x400F_FFFF
- 位带别名区:0x4200_0000 - 0x43FF_FFFF
- SRAM位带区 :0x2000_0000 - 0x200F_FFFF
- 映射关系:每个位(bit)对应别名区的一个字(32位)
地址转换公式:
- 位带别名地址 = 位带别名基址 + (字节偏移×32) + (位编号×4)
STM32F103系列单片机是基于ARM Cortex-M3内核。Cortex-M3有一个称为位带(bit-band)的特性,它允许对单个比特进行原子操作。
位带区有两个区域:一个是SRAM位带区,另一个是外设位带区。
下面详细解释:
位带的概念
位带操作允许通过一个别名地址(alias address)来访问原始位带区(bit-band region)中的单个比特。这样,对别名地址的读写操作就相当于对原始位带区中特定比特的读写。这种操作是原子的,不会被打断。
位带映射
Cortex-M3内核中,位带区包括两个部分:
- SRAM位带区:原始位带区地址范围是0x20000000到0x200FFFFF(共1MB),对应的别名区地址范围是0x22000000到0x23FFFFFF(共32MB)。
- 外设位带区 :原始位带区地址范围是0x40000000到0x400FFFFF(共1MB),对应的别名区地址范围是0x42000000到0x43FFFFFF(共32MB)。
注意:STM32F103的SRAM只有20KB(0x20000000~0x20004FFF),外设寄存器地址范围也不同,但位带操作只针对这两个1MB的原始位带区有效,超出实际物理地址的范围不能使用。
地址转换公式
每个原始位带区中的每个比特都映射到别名区的一个32位字(4字节)。因此,别名区的一个字对应原始位带区的一个比特。
转换公式如下:
txt
别名地址 = 别名区基地址 + (原始字节地址 - 原始区基地址) * 32 + 比特序号 * 4其中:
- 原始字节地址:要操作的比特所在的字节地址。
- 比特序号:该比特在字节中的位置(0~7)。
- 别名区基地址:SRAM别名区基地址为0x22000000,外设别名区基地址为0x42000000。
- 原始区基地址:SRAM原始区基地址为0x20000000,外设原始区基地址为0x40000000。
因为每个比特对应别名区的一个字(4字节),所以乘以4。而每个字节有8个比特,所以原始地址每增加一个字节,对应的别名地址增加8个字(32字节),因此乘以32。
位带操作示例
假设我们要操作SRAM地址0x20000000的第2比特(比特序号2)。
首先,计算别名地址:
txt
别名地址 = 0x22000000 + (0x20000000 - 0x20000000) * 32 + 2 * 4
= 0x22000000 + 0 + 8
= 0x22000008然后,我们可以通过读写0x22000008这个地址来操作0x20000000地址的第2比特。
- 读0x22000008:返回0x00000001(表示该比特为1)或0x00000000(表示该比特为0)。
- 写0x22000008:写入0x00000001则设置该比特为1;写入0x00000000则清除该比特为0。
注意:写入其他值(非0或1)可能产生不可预知的结果,但通常写入0x00000000和0x00000001是安全的。
在STM32F103中的应用
在STM32F103中,我们通常用位带来操作外设寄存器,特别是GPIO的输入输出寄存器。例如,我们可以用位带来单独操作GPIO的某个引脚,而不影响其他引脚。
例如,GPIOA的输出数据寄存器ODR的地址是0x4001080C。假设我们要操作PA5,即第5比特。
计算别名地址:
txt
别名地址 = 0x42000000 + (0x4001080C - 0x40000000) * 32 + 5 * 4
= 0x42000000 + (0x1080C) * 32 + 20
= 0x42000000 + 0x210180 + 0x14
= 0x42210194然后,我们可以通过读写0x42210194来单独操作PA5。
注意
- 位带操作只适用于Cortex-M3、M4、M7等内核。
- 别名区地址必须按照32位字进行访问(即使用uint32_t指针)。
- 确保操作的原始地址在位带区内,并且有实际的物理存储器或外设寄存器。
宏定义简化操作
为了方便使用,通常会定义一些宏来简化位带操作。例如:
c
#define BITBAND_SRAM(address, bit) (*(volatile uint32_t*)(0x22000000 + (((uint32_t)address - 0x20000000) * 32) + (bit * 4)))
#define BITBAND_PERI(address, bit) (*(volatile uint32_t*)(0x42000000 + (((uint32_t)address - 0x40000000) * 32) + (bit * 4)))然后可以这样使用:
c
// 设置PA5为1
BITBAND_PERI(&GPIOA->ODR, 5) = 1;
// 清除PA5为0
BITBAND_PERI(&GPIOA->ODR, 5) = 0;
// 读取PA5的状态
uint32_t bit = BITBAND_PERI(&GPIOA->IDR, 5);注意:GPIOA->ODR和GPIOA->IDR都是寄存器,我们需要取它们的地址,然后转换为uint32_t类型进行计算。
STM32中Cortex-M3的位带区和位带别名区
理论
在STM32的Cortex-M3内核中,位带区(Bit-band Region) 和 位带别名区(Bit-band Alias Region) 是一种特殊的内存访问机制,允许对单个位进行原子操作。
可以简单理解为:位带区1个位(1Bit) ⇔ 位带别名区1个字(32位)
位带区
这是原始的内存区域,包含要操作的位。Cortex-M3有两个位带区:
- SRAM位带区 :地址范围
0x2000 0000 - 0x200F FFFF(1MB) - 外设位带区 :地址范围
0x4000 0000 - 0x400F FFFF(1MB)
这些区域中的每个位都可以通过别名地址单独访问。
位带别名区
这是映射到位带区每个位的特殊地址空间:
- SRAM位带别名区 :地址范围
0x2200 0000 - 0x23FF FFFF(32MB) - 外设位带别名区 :地址范围
0x4200 0000 - 0x43FF FFFF(32MB)
映射关系
位带区1个位(1Bit) ⇔ 位带别名区1个字(32位)
计算公式:
txt
别名地址 = 别名基地址 + (字节偏移 × 32) + (位号 × 4)其中:
- 字节偏移 = 目标字节地址 - 位带区基地址
- 位号 = 0-7(位在字节中的位置)
示例
这里我们以GPIOx_CRH寄存器中的GPIOB为例
txt
GPIOB基地址: 0x4001 0C00
GPIOB_CRH偏移: 0x04
GPIOB_CRH地址: 0x4001 0C04寄存器结构(每个引脚4位配置):
txt
位31:30 引脚15模式配置 (MODE15)
位29:28 引脚15配置 (CNF15)
位27:26 引脚14模式配置 (MODE14)
位25:24 引脚14配置 (CNF14)
... 以此类推
位3:2 引脚9模式配置 (MODE9)
位1:0 引脚9配置 (CNF9)修改引脚10的模式位:
假设我们要修改GPIOB_CRH中引脚10的模式位MODE10(位于寄存器的位19:18)。及将GPIOB_CRH寄存器的位19设置为1(MODE101)。
确定位带别名地址
txt
// 基地址
#define PERIPH_BASE 0x40000000
#define PERIPH_ALIAS 0x42000000
#define GPIOB_CRH_ADDR 0x40010C04
// 要操作的位:位19(从0开始计数)
// 位19在哪个字节?19÷8=2余3,所以在字节(基地址+2)的第3位
// 实际字节地址:0x40010C04 + 2 = 0x40010C06
// 计算字节偏移
uint32_t byte_offset = GPIOB_CRH_ADDR - PERIPH_BASE; // 0x40010C04 - 0x40000000 = 0x10C04
// 计算别名地址(针对位19)
// 位号计算:位19是字节0x40010C06的第3位(因为19%8=3)
uint32_t byte_addr_for_bit19 = GPIOB_CRH_ADDR + 2; // 0x40010C06
uint32_t bit_in_byte = 3; // 位19在字节中的位置详细计算过程
txt
// 方法1:直接使用公式计算位19的别名地址
uint32_t alias_addr = PERIPH_ALIAS +
((GPIOB_CRH_ADDR - PERIPH_BASE) << 5) +
(19 << 2);
// 展开计算:
// 字节偏移 = 0x40010C04 - 0x40000000 = 0x10C04
// 字节偏移 × 32 = 0x10C04 × 0x20 = 0x218080
// 位号 × 4 = 19 × 4 = 76 = 0x4C
// 别名地址 = 0x42000000 + 0x218080 + 0x4C = 0x422180CC这里需要解释一下位号的计算方法
方法A:字节内位号
c
// 步骤:
// 1. 找到位所在的字节地址
// 2. 计算字节内位置(0-7)
uint32_t addr = 0x40010C04; // GPIOB_CRH地址
uint32_t bit_num = 19; // 要操作的位号
// 计算字节地址:19÷8=2余3,所以是addr+2
uint32_t byte_addr = addr + (bit_num / 8); // 0x40010C06
uint8_t bit_in_byte = bit_num % 8; // 3
// 然后使用字节地址和字节内位号计算别名地址方法B:全局位号(直接使用19)
c
// 直接使用原始地址和全局位号
uint32_t addr = 0x40010C04;
uint32_t bit_num = 19;
// 公式:
alias_addr = 0x42000000 + ((addr - 0x40000000) × 32) + (bit_num × 4)使用数值验证
方法A:
c
addr = 0x40010C04
bit_num = 19
// 字节地址 = addr + 19/8 = 0x40010C04 + 2 = 0x40010C06
// 字节内位号 = 19 % 8 = 3
byte_offset_A = 0x40010C06 - 0x40000000 = 0x10C06
bit_in_byte = 3
alias_addr_A = 0x42000000 + (0x10C06 × 32) + (3 × 4)
= 0x42000000 + 0x2180C0 + 0xC
= 0x422180CC方法B:
c
addr = 0x40010C04
bit_num = 19
byte_offset_B = 0x40010C04 - 0x40000000 = 0x10C04
alias_addr_B = 0x42000000 + (0x10C04 × 32) + (19 × 4)
= 0x42000000 + 0x218080 + 0x4C
= 0x422180CC事实证明结果相同,都是 0x422180CC
数学推导证明
定义:
- A = 寄存器地址(如 0x40010C04)
- b = 全局位号(如 19)
- P_base = 外设基地址(0x40000000)
- Alias_base = 别名基地址(0x42000000)
方法A:
txt
字节地址 = A + floor(b/8)
字节内位号 = b % 8
字节偏移 = (A + floor(b/8)) - P_base
别名地址 = Alias_base + [字节偏移 × 32] + [字节内位号 × 4]
= Alias_base + [(A + floor(b/8) - P_base) × 32] + [(b % 8) × 4]方法B:
txt
字节偏移 = A - P_base
别名地址 = Alias_base + [字节偏移 × 32] + [b × 4]
= Alias_base + [(A - P_base) × 32] + [b × 4]证明等价:
txt
方法A = Alias_base + [(A - P_base) × 32] + [floor(b/8) × 32] + [(b % 8) × 4]
注意:b = 8 × floor(b/8) + (b % 8)
所以:b × 4 = [8 × floor(b/8) + (b % 8)] × 4
= 32 × floor(b/8) + 4 × (b % 8)
因此:
方法B = Alias_base + [(A - P_base) × 32] + [32 × floor(b/8) + 4 × (b % 8)]
= Alias_base + [(A - P_base) × 32] + [floor(b/8) × 32] + [(b % 8) × 4]
方法A = 方法B关键点
因为方法B的公式中的 (bit_num × 4) 实际上包含了两个部分:
- floor(bit_num/8) × 32:用于跨字节的偏移
- (bit_num % 8) × 4:用于字节内的偏移
txt
寄存器地址: 0x40010C04
这个地址对应8个位(位0-7)
当我们要访问位19时:
- 方法A:先跳到字节0x40010C06(跳过2个字节),然后取该字节的第3位
- 方法B:从寄存器地址开始,直接跳到位19的位置
两种方法在数学上是等价的:
(2个字节 × 32字节/字节) = 64字节偏移
(3位 × 4字节/位) = 12字节偏移
总共 = 76字节偏移
而 19 × 4 = 76 字节偏移
所以:方法B的 19×4 自动包含了跨字节的偏移!所以:bit_num × 4 等价于 (floor(bit_num/8) × 32) + ((bit_num % 8) × 4)
在cortex m3 中,什么是大小端
我们通常认为数据在内存中是"连续存放"的,但大小端定义了多字节数据的字节存放顺序。
什么是大端和小端?
想象一个数字 0x12345678(32位,4个字节:0x12, 0x34, 0x56, 0x78)。它要存放在从地址 0x0000 开始的4个字节内存中。
小端模式 (Little-Endian)
- 规则 :最低有效字节 存放在最低内存地址。
- 像写数字 :我们写数字"一百二十三"是
123,个位(最低位)在最后。但小端存储时,最低位的字节放在最前面。 - 内存布局 :
0x0000:0x78(最低有效字节)0x0001:0x560x0002:0x340x0003:0x12(最高有效字节)
- 特点 :地址增长方向与数字的"书写"方向相反 。x86, ARM Cortex-M 默认使用此模式。
大端模式 (Big-Endian) - 规则 :最高有效字节 存放在最低内存地址。
- 像读书:从左到右读,先读最高位的数字。存储时,最高位的字节也放在最前面。
- 内存布局 :
0x0000:0x12(最高有效字节)0x0001:0x340x0002:0x560x0003:0x78(最低有效字节)
- 特点 :地址增长方向与数字的"书写"方向相同。网络协议(如TCP/IP)、早期PowerPC、MIPS常用此模式。
为什么会有大小端?
这是一个历史遗留的"自行车停放架"问题,没有绝对的对错,只有不同的设计哲学和传承。
- 人类思维 vs 机器计算 :
- 大端 :更符合人类阅读习惯(从高位到低位),调试时直接查看内存 更容易看懂数值(
0x0000开始就是0x12 0x34...)。 - 小端 :更符合计算机计算习惯。当你进行加法或比较时,通常从最低位开始运算。在小端模式下,最低位字节在最低地址,电路设计上更容易实现连续读取和进位。
- 大端 :更符合人类阅读习惯(从高位到低位),调试时直接查看内存 更容易看懂数值(
- 数据类型转换的便利性 :
- 小端 的优势非常明显:一个
32位整数0x12345678在地址0x0000。如果你把它当作16位整数(通过0x0000地址)读取,你会得到0x5678,这正是它的低16位。地址不变,读取的宽度不同,就自然得到了数据的截断部分,这在编程中有时很方便。 - 在大端模式下,从同一地址读取不同宽度会得到数据的不同部分,不够直观。
由于这些差异,不同的处理器架构和协议选择了不同的道路,并形成了各自的生态。
- 小端 的优势非常明显:一个
CM3的"字节不变大端" vs ARM7的"字不变大端"
这是你问题的关键,也是ARMv7-M架构的一个微妙但重要的变化。它们的区别在于 "不变"的是什么 。
为了说明,我们先看一个小端系统作为参照,内存中存放 0x12345678:
- 地址
0x0:0x78 - 地址
0x1:0x56 - 地址
0x2:0x34 - 地址
0x3:0x12
ARM7的"字不变大端"
- 核心 :以32位字为单位看,字的内容是不变的。
- 解释 :当处理器配置为大端模式后,它重新定义 了从内存系统看到的"数据视图"。对于一个存放在地址
0x0~0x3的 字 ,CPU希望从内存总线上一口气看到的就是0x12345678。 - 实现 :这意味着内存控制器或总线需要在内部进行字节交换,以满足CPU的"视图"。
- 内存实际布局 (为了满足CPU的"字视图",内存实际存放可能是):
- 地址
0x0:0x12 - 地址
0x1:0x34 - 地址
0x2:0x56 - 地址
0x3:0x78
- 地址
- 关键影响 :在这种模式下,软件通过不同地址访问同一个字节可能会看到不同的值,因为内存系统可能根据访问宽度(字节、半字、字)动态重组数据。这增加了系统的复杂性,尤其是对外设寄存器的访问可能出问题。
Cortex-M3的"字节不变大端"
- 核心 :每个字节地址上的字节内容是不变的。
- 解释 :这是更简单、更清晰的定义。它规定:一个确定的字节数据,存储在确定的字节地址上,这个关系在任何端模式下都固定不变。 大小端模式只影响如何将这些独立的字节组合成半字或字。
- 内存实际布局 :
- 地址
0x0:0x12 - 地址
0x1:0x34 - 地址
0x2:0x56 - 地址
0x3:0x78
(注意,这个布局和上面ARM7的例子看起来一样,但哲学完全不同!这里0x12就是固定在地址0x0的字节内容)
- 地址
- 组合规则 :
- 从地址
0x0读取一个字节 :得到0x12。 - 从地址
0x0读取一个半字 (16位):大端模式下,高字节在前,所以是0x12和0x34组合成0x1234。 - 从地址
0x0读取一个字 (32位):大端模式下,是0x12,0x34,0x56,0x78组合成0x12345678。
- 从地址
- 关键优势 :
- 一致性 :无论以何种宽度访问,同一个地址上的字节值永远不变。这对内存映射的外设寄存器至关重要,因为外设的某个状态位或控制位总是映射到固定的字节地址。
- 简化硬件:内存系统不需要为CPU准备特殊的"字视图",硬件实现更简单。
- 利于DMA等:其他总线主设备(如DMA控制器)看到的内存视图与CPU一致,协同工作无障碍。
使用比喻理解CM3的"字节不变大端" vs ARM7的"字不变大端:展览馆与讲解员
再想象一个拥有4个连续展台(内存地址)的展览馆,展品是4个部件,拼起来是一辆完整的马车(一个32位字)。
ARM7 "字不变大端":重塑现实的讲解员
- 马车本来的部件顺序是:轮子(0x78)、车厢(0x56)、马鞍(0x34)、马头(0x12)。
- 当你要求以大端模式观看时,讲解员(内存控制器)强行将部件在展台上重新排列为:马头(0x12)、马鞍(0x34)、车厢(0x56)、轮子(0x78),然后告诉你:"看,这就是马车。"
- 问题 :如果你绕开展解员,直接去盯着一号展台看,你看到的可能是"马头",而不是原始的"轮子"。展品本身被移动了。
Cortex-M3 "字节不变大端":引导视角的讲解员 - 展品位置是固定不变的:一号展台就是轮子(0x78),二号是车厢(0x56),三号是马鞍(0x34),四号是马头(0x12)。
- 当你要求以大端模式观看时,讲解员不移动任何展品,他只是递给你一个望远镜(配置CPU的端模式),并说:"请从四号展台开始看,然后三号、二号、一号,这样拼起来就是马车。"
- 关键 :无论你用什么方式看,一号展台上永远都是轮子 。改变的只是你观察和组合它们的顺序。
| 特性 | ARM7 "字不变大端" | Cortex-M3 "字节不变大端" |
|---|---|---|
| 不变的是什么 | 32位字的整体数据视图 | 每个字节地址上的内容 |
| 改变的是什么 | 字节在存储子系统中的物理/逻辑顺序 | 字节被组合成半字/字的规则 |
| CPU与内存视图 | 可能不同(需要转换) | 完全一致 |
| 对编程的影响 | 访问同一地址的字节和字可能得到不匹配数据,不利于外设寄存器访问。 | 访问行为可预测,外设寄存器映射稳定可靠。 |
在cortex m3中,什么是对齐访问与非对齐访问
在Cortex-M3中,对齐访问与非对齐访问指的是CPU访问内存时,数据地址是否符合特定"边界"要求的规则。
这里我们使用比喻来理解:
比喻:停车场与停车位
想象内存是一个巨大的停车场 ,每个车位有一个编号(内存地址 ),并且严格规定:
- 摩托车(1字节数据):可以停在任何车位。
- 轿车(2字节数据,半字):必须停在编号为偶数的车位(如0, 2, 4号)。
- 大巴车(4字节数据,字) :必须停在编号是4的倍数的车位(如0, 4, 8号)。
对齐访问 就是遵守这个规则,把车停进规定的车位。
非对齐访问就是破坏规则,比如把一辆大巴车斜着停在4、5、6、7号车位上。
什么是对齐访问?
对齐访问是指数据对象的地址是其自身大小的整数倍。
- 字节访问 (8位) :地址可以是任意值(因为1的倍数总是它本身)。
- 正确 访问
0x20000000,0x20000001,0x20000002都是对齐的。
- 正确 访问
- 半字访问 (16位) :地址必须是2的倍数(即地址最低位为0)。
- 正确 访问
0x20000000,0x20000002,0x20000004是对齐的。 - 错误 访问
0x20000001,0x20000003是非对齐的。
- 正确 访问
- 字访问 (32位) :地址必须是4的倍数(即地址最低两位为00)。
- 正确 访问
0x20000000,0x20000004,0x20000008是对齐的。 - 错误 访问
0x20000001,0x20000002,0x20000003都是非对齐 的。
对齐访问是CPU的"舒适区",硬件可以通过单次高效操作完成存取。
- 正确 访问
什么是非对齐访问?
非对齐访问即违反上述规则。例如:
- 试图从地址
0x20000001读取一个 字 (32位)。 - 试图从地址
0x20000003写入一个 半字 (16位)。
Cortex-M3对非对齐访问的态度是:有限支持,但有代价。 - 与早期ARM处理器的关键区别 :像ARM7这样的老架构,根本不支持 非对齐访问,尝试非对齐访问会直接触发硬件异常。
- Cortex-M3的进步 :为了提高软件灵活性(例如处理来自网络或外部设备的不规则数据包),Cortex-M3支持大多数情况下的非对齐访问,但它是通过硬件"暗中帮忙"实现的。
Cortex-M3如何处理非对齐访问?
当CPU执行一条非对齐访问指令时,硬件会自动将其拆分成多次对齐访问 ,然后在内部重组数据。这个过程对程序员透明,但有性能代价。
示例 :从非对齐地址 0x20000001 读取一个字 (0x12345678)。
- 硬件拆分 :硬件识别到这是非对齐访问。它会发起两次对齐的半字读取 :
- 第一次从
0x20000000读取一个半字(得到0x5678)。 - 第二次从
0x20000002读取一个半字(得到0x1234)。
- 第一次从
- 内部重组 :硬件将
0x1234和0x5678在内部总线矩阵中正确拼接,最终将完整的0x12345678交给CPU寄存器。 - 性能开销 :这个"一拆一拼"的过程需要额外的时钟周期。一次非对齐的字访问,其耗时可能是一次对齐字访问的2到3倍。
重要限制
Cortex-M3并非在所有地方都允许非对齐访问,有几条严格的"红线":
- 对"原子"操作指令绝对禁止 :
- 用于多线程同步的
LDREX(加载独占) 和STREX(存储独占) 指令必须对齐 。非对齐访问会触发 UsageFault 异常。
- 用于多线程同步的
- 对位带区访问绝对禁止 :
- 访问位带区 (
0x20000000-0x200FFFFF和0x40000000-0x400FFFFF) 以及它们的别名区时必须对齐 。非对齐访问会触发 HardFault 异常。这是因为位带操作本身依赖于精确的地址计算。
- 访问位带区 (
- 对私有外设总线(PPB)区域强烈不建议 :
- 访问内核系统控制块(SCB)、NVIC等区域 (
0xE0000000以上) 应始终保持对齐。虽然某些访问可能不会立即出错,但行为是未定义的,可能导致不可预知的结果。
- 访问内核系统控制块(SCB)、NVIC等区域 (
总结
| 特性 | 对齐访问 | 非对齐访问 (在支持的情况下) |
|---|---|---|
| 硬件操作 | 单次总线事务完成。 | 被拆分为多次对齐总线事务,内部重组。 |
| 时钟周期 | 最少(通常1个周期,取决于等待状态)。 | 显著更多(通常是2-3倍或以上)。 |
| 总线利用率 | 高效。 | 低效,占用更多总线带宽。 |
| 对实时性的影响 | 可预测,延迟确定。 | 不可预测,引入额外延迟,不利于硬实时系统。 |
| 能耗 | 较低。 | 较高(因为触发了更多硬件活动)。 |
一下是Cortex-M3权威指南Cn原文:
非对齐访问是什么:任何一个不能被4整除的地址都是非对齐的。而对于半字,任何不能被2整除的地址(也就是奇数地址)都是非对齐的。在 CM3 中,非对齐的数据传送只发生在常规的数据传送指令中,如 LDR/LDRH/LDRSH。
不支持,包括:
- 多个数据的加载/存储(LDM/STM)
- 堆栈操作 PUSH/POP
- 互斥访问(LDREX/STREX)。如果非对齐会导致一个用法 fault
- 位带操作。因为只有 LSB 有效,非对齐的访问会导致不可预料的结果。
事实上,在内部是把非对齐的访问转换成若干个对齐的访问的,这种转换动作由处理器总线单元来完成。这个转换过程对程序员是透明的,因此写程序时不必操心。但是,因为它通过若干个对齐的访问来实现一个非对齐的访问,会需要更多的总线周期。事实上,节省内存有很多方法,但没有一个是通过压缩数据的地址,不惜破坏对齐性的这种歪门邪道。因此,应养成好习惯,总是保证地址对齐,这也是让程序可以移植到其它ARM芯片上的必要条件。
在cortex-M3中,什么是互斥锁(互斥体)
互斥体主要是通过其硬件独占访问 功能实现的。与高端处理器不同,Cortex-M3没有复杂的多级缓存一致性协议,它的互斥体实现更为轻量,核心是 LDREX (加载独占) 和 STREX (存储独占) 这对指令。
Cortex-M3内部有一个简单的独占访问监视器,它可以跟踪处理器对某个内存地址的"独占加载"操作。其工作原理如下:
- LDREX :执行"加载独占"。它从内存中读取一个值到寄存器,同时标记该地址被当前处理器"监视"或"预留"。
- STREX :执行"存储独占"。它尝试将寄存器的值写回同一个被监视的地址 。只有在执行
STREX之前,这个"独占标记"没有被任何其他操作(例如中断、其他线程的访问、或另一个LDREX)破坏时,写入才会成功。STREX指令会返回一个状态码(通常为0表示成功,1表示失败),告知软件写入是否完成。
汇编伪代码流程如下:
assembly
; 假设互斥体的状态存放在一个内存地址(例如 0x20000000)
; 锁值约定:0 = 空闲,1 = 被占用
AcquireLock:
MOV R1, #1 ; R1 准备写入的值:1(上锁)
SpinLoop:
LDREX R0, [LockAddr] ; 1. 独占加载:读取锁的当前状态到R0,并开始监视
CMP R0, #0 ; 2. 判断锁是否空闲(是否为0)?
BNE SpinLoop ; 3. 如果不空闲(!=0),回到循环开头继续尝试
; 4. 如果空闲(==0),尝试获取锁:
STREX R2, R1, [LockAddr] ; 5. 尝试独占存储:将1(R1)写入锁地址
CMP R2, #0 ; 6. 检查独占存储是否成功(R2是否为0)?
BNE SpinLoop ; 7. 如果失败(R2 !=0,如被中断打断),重试整个流程
DMB ; 8. 成功后,插入数据内存屏障,确保锁操作在后续内存访问前完成
BX LR ; 获取锁成功,返回
ReleaseLock:
DMB ; 释放锁前,确保所有内存访问已完成
MOV R0, #0 ; 准备解锁值:0
STR R0, [LockAddr] ; 普通存储指令即可释放锁(无需STREX)
BX LR关键在于 :即使两个执行流(线程/中断)同时读取到锁空闲(LDREX 读到0),也只有一个 能成功执行 STREX 将锁置为1,另一个的 STREX 会失败并循环重试,从而实现了原子性的"读-改-写"。
在硬件上:Cortex-M3实现互斥体的操作核心是一个称为 "独占访问监视器" 的逻辑单元。它不是一块独立的大芯片,而是集成在处理器内部总线接口附近的一组状态机和标记逻辑。
关键在于,这个监视器非常简单和轻量 。你可以把它想象成一个单条目、带状态的小本子:
- 它只记录一件事 :当前处理器是否对某个内存地址发起了"独占加载"(
LDREX)? - 它只有几个状态 :通常可以抽象为
IDLE(空闲)、OPEN(已监视某个地址)、EXCLUSIVE(独占加载成功,等待存储)。
整个硬件完成过程,可以理解为处理器、独占监视器和内存系统之间一次严谨的"握手"协议,分为三个阶段:
第一阶段:声明意向(LDREX指令)
当CPU执行一条LDREX指令(例如 LDREX R0, [R1])时,硬件会执行一系列不同于普通加载的操作:
- 发起带标记的读请求 :CPU在系统总线上发起一次内存读取,但会附加一个"独占访问"标记。这个标记是一个物理信号,它告知内存系统:"这次读取是一个'独占序列'的开始"。
- 激活本地监视器 :芯片内部的"独占访问监视器"(一个简单的状态机)捕获到这个信号。它从"空闲"状态转变为"打开监视"状态。关键点在于,Cortex-M3的监视器设计非常简化,它通常不精确记录具体的内存地址,而是笼统地标记"有一个独占操作正在进行中"。这降低了硬件复杂度。
- 数据返回 :内存系统像处理普通读请求一样,将目标地址的数据值返回给CPU的寄存器。至此,CPU看起来只是完成了一次加载。
第二阶段:受保护的"窗口期"
在LDREX执行完毕之后,到其配对的STREX执行之前的这段时间,是一个由硬件监视的关键窗口期。
- 监视器的职责:在此期间,独占监视器持续检查系统内是否发生了任何可能破坏这次"独占序列"的事件。
- 破坏性事件 :这些事件被称为"对独占状态的污染",主要包括:
- 任何存储操作 :即使是一条完全无关的
STR指令向其他地址写入数据,也可能导致监视器复位。这是因为监视器的粒度很粗,无法区分不同地址。 - 异常或中断的发生与返回 :这是硬件保障确定性的重要设计。当处理器响应中断或进行任务切换时,硬件会自动清除独占监视器的状态。这防止了低优先级任务的独占操作被高优先级中断意外干扰而导致死锁,但也意味着简单的自旋锁不能安全地用于中断与任务之间。
- 软件显式清除 :执行
CLREX指令会直接复位监视器。
如果发生上述任何污染事件,独占监视器会立即从"打开监视"状态复位回"空闲"状态 ,宣告本次独占序列失效。
第三阶段:尝试完成与原子裁决(STREX指令)
当软件准备更新共享资源并释放锁时,会执行配对的STREX指令(例如STREX R2, R0, [R1])。此时,硬件进行最终裁决:
- 任何存储操作 :即使是一条完全无关的
- 查询监视器状态:CPU首先向独占监视器查询当前状态。这是一个快速的硬件查询。
- 成功路径(状态未污染) :
- 如果监视器仍处于"打开监视"状态,说明自
LDREX以来没有污染事件发生。 - CPU会在总线上发起一次带"独占"标记的写事务 。内存系统识别到这个标记,会确保这次写入作为一个不可分割的原子操作完成。
- 写入成功后,
STREX指令会将其目标寄存器(例中的R2)设置为 0,向软件报告"成功"。
- 如果监视器仍处于"打开监视"状态,说明自
- 失败路径(状态已污染) :
- 如果监视器已因污染事件复位为"空闲"状态,查询结果即为失败。
- CPU不会发起带独占标记的写入。它可能完全放弃这次存储,或者发起一次普通的(非原子的)写入(该写入可能被系统忽略)。
STREX指令会将其目标寄存器设置为 1 ,向软件报告"失败"。
无论成功与否,在STREX指令执行完毕后,独占监视器都会自动复位为"空闲"状态 ,等待下一次LDREX。
可以看到,硬件本身并没有一个叫"互斥锁"的完整模块。它只完成了两件事:
- 提供原子性裁决 :通过独占监视器这个状态机,硬件保证了在无污染条件下,
LDREX和STREX之间对内存的"读-改-写"操作是原子的 。即使多个执行流同时执行到STREX,也只有一个能成功(获锁),其余都会失败(继续循环尝试)。 - 划定能力边界 :通过粗粒度监视和在异常时自动复位等行为,硬件清晰地告诉软件:"我的能力仅限于此。复杂场景(如跨越中断)下的数据保护,需要你结合开关中断等软件策略来共同管理。"
因此,一个完整的互斥锁是由软件 利用这对硬件原语构建出来的。典型的自旋锁软件算法就是循环执行"LDREX读取锁标志 -> 判断是否空闲 -> 尝试STREX上锁 -> 检查是否成功"这一过程,直到成功为止。
以下是Cortex-M3权威指南Cn原文:
互斥体在多任务环境中使用,也在中断服务例程和主程序之间使用,用于给任务申请共享资源(如一块共享内存)。在某个(排他型)共享资源被一个任务拥有后,直到这个任务释放它之前,其它任务是不得再访问它的。为建立一个互斥体,需要定义一个标志变量,用指示其对应的共享资源是否已经被某任务拥有。当另一个任务欲取得此共享资源时,它要先检查这个互斥体,以获知共享资源是否无人使用。在传统的ARM处理器中,这种检查操作是通过SWP指令来实现的。SWP保证互斥体检查是原子操作的,从而避免了一个共享资源同时被两个任务占有(这是紊乱危象的一种常见表现形式)。
在新版的ARM处理器中,读/写访问往往使用不同的总线,导致SWP无法再保证操作的原子性,因为只有在同一条总线上的读/写能实现一个互锁的传送。因此,互锁传送必须用另外的机制实现,这就引入了"互斥访问"。互斥访问的理念同SWP非常相似,不同点在于:在互斥访问操作下,允许互斥体所在的地址被其它总线master访问,也允许被其它运行在本机上的任务访问,但是CM3能够"驳回"有可能导致竞态条件的互斥写操作。
互斥访问分为加载和存储,相应的指令对子为LDREX/STREX,LDREXH/STREXH,LDREXB/STREXB,分别对应于字/半字/字节。在使用互斥访问时,LDREX/STREX 必须成对使用。
堆、栈、ROM、RAM
栈(Stack)是什么
栈 = 函数调用时自动分配/自动释放的内存区域(通常由编译器/CPU调用约定管理)。
- 怎么来的:进入函数,函数的局部变量、返回地址、保存的寄存器等,会在栈上"压入";函数返回时自动"弹出"。
- 典型内容
- 局部变量:
int a; char buf[64]; - 函数参数、返回地址
- 中断现场保护(很多 MCU 中断进来会把现场压栈)
- 局部变量:
- 特点
- 速度快:只是改一下栈指针(SP)。
- 生命周期短:离开作用域/函数返回就没了。
- 大小通常固定:启动时就配置好(链接脚本/启动文件里)。
- 常见坑
- 栈溢出:局部数组太大、递归太深、中断嵌套太多 → 覆盖别的内存,表现为"莫名其妙跑飞/HardFault"。
- 返回局部变量地址:函数返回后栈帧释放,指针悬空。
堆(Heap)是什么
堆 = 运行时动态分配/释放的内存区域 (通常由 malloc/free 或 new/delete 管理)。
- 怎么来的:程序运行过程中想要多少内存就申请多少,用完再释放。
- 典型内容
- 动态数组、动态对象:
p = malloc(n);/new T(...) - 可变长度缓冲区、消息队列节点等(如果用动态分配)
- 动态数组、动态对象:
- 特点
- 更灵活:大小可变、生命周期可跨函数。
- 速度相对慢:要找空闲块、维护管理结构。
- 容易出问题(嵌入式更明显)
- 常见坑
- 内存碎片:频繁申请/释放不同大小块,时间久了可用空间被切碎,导致申请失败。
- 泄漏 :忘了
free/delete,RAM 越用越少。 - 不确定性 :实时系统里
malloc可能耗时不稳定,影响实时性。
| 项目 | 栈 | 堆 |
|---|---|---|
| 分配/释放 | 自动 | 手动(malloc/free 或 new/delete) |
| 生命周期 | 函数/作用域内 | 直到释放(或程序结束) |
| 速度 | 很快 | 较慢、不确定 |
| 容易出的问题 | 栈溢出、悬空指针(返回局部地址) | 碎片、泄漏、申请失败、实时性抖动 |
| 嵌入式常见建议 | 局部变量别太大,避免深递归 | 能不用就不用,或用内存池替代 |
堆和栈都在 RAM 里,不在 ROM 里。
因为堆/栈存的是"运行时会变化的数据"(局部变量、动态分配内存、函数调用现场),必须放在可读写的存储器里。
ROM 是什么
ROM(Read-Only Memory,只读存储器) :广义上指"掉电不丢、主要用来放程序"的存储器。嵌入式里常见就是 Flash(本质上也是一种 ROM 类存储)。
- 特点
- 掉电不丢(非易失)
- 读很方便,写/擦比较慢,而且有擦写次数寿命
- 程序通常从这里取指执行(很多 MCU 支持 XIP:直接在 Flash 上执行)
- 通常放什么
- 程序代码(
.text) - 只读常量(
.rodata,例如const字符串/查表数据) - 启动信息、固件版本等
注意:严格意义的"ROM"是出厂固化不可写;但在 MCU 里大家常把 Flash 也口头叫 ROM,因为它"像 ROM 一样存程序"。
- 程序代码(
RAM 是什么
RAM(Random Access Memory,随机存取存储器):运行时用的"工作内存"。
- 特点
- 掉电丢失(易失)
- 可读可写、速度快
- 通常放什么
- 栈(stack)
- 堆(heap)
- 全局/静态变量(
.data/.bss) - 中间计算用的临时数据、缓冲区等
特性:
- 栈(stack)在 RAM:每次函数调用都会在栈上压入/弹出数据。
- 堆(heap)在 RAM :
malloc/new申请出来的内存来自堆。
嵌入式的内存布局经常可以这么理解(逻辑示意): - Flash/ROM
.text代码.rodata常量
- RAM
.data(有初值的全局/静态变量,启动时从 Flash 拷贝到 RAM).bss(无初值的全局/静态变量,启动时清零)- heap(向上增长,常见)
- stack(向下增长,常见)
STM32F103 里的 "ROM" 具体是什么?
在 STM32F103 上通常指两类"掉电不丢"的片上存储:
- 主 Flash(程序存储器)
- 放固件:代码
.text、只读常量.rodata等 - 基地址:0x0800 0000(主 Flash 的原始地址空间)
- 放固件:代码
- System memory(系统存储器/Bootloader ROM)
- ST 出厂烧录的串口下载 Bootloader 所在区域
- 典型"原始地址空间"在 0x1FFF F000 或 0x1FFF B000(不同系列/型号有差异,F103 多数在 0x1FFF F000)
STM32F103 里的 "RAM" 具体是什么?
RAM 就是片上 SRAM(工作内存):放栈、堆、全局变量、运行时数据。
- SRAM 基地址:0x2000 0000
- 常见的(以中密度 F103x8/xB 为例):
- Flash:64/128 KB
- SRAM:20 KB
在stm32中有一种叫做"Boot memory alias(启动别名映射)"的机制,可以把他简单理解为:把地址 0x0000_0000 这块"启动窗口"(Boot space)临时指向某一块真实存储器(Flash / System memory / SRAM),让 CPU 复位后能从 0x0000_0000 取到向量表并开始执行。(CPU 复位后总是从 0x0000 0000 取复位向量(向量表))
核心:CPU 固定从 0x0000_0000 取"启动向量表",但真实的 ROM/RAM 物理地址并不都在 0x0000_0000,所以需要 alias 这个"映射"。
别名映射的比喻 :
想象你有三套房子(Flash、System Memory、SRAM),每套都有自己地址。
但快递员(CPU)只认"幸福路1号"(0x0000_0000)这个地址。
于是你装了个"智能门牌"(别名映射):
- 当开关拨到位置A:幸福路1号 → 主Flash房
- 位置B:幸福路1号 → 系统Bootloader房
- 位置C:幸福路1号 → SRAM房
这样快递员每次都能送到,但实际上东西在不同房子里。
STM32F103C8T6内存视图:
txt
┌─────────────────────┐ 0x2000 5000 (RAM结束)
│ │
│ 未使用RAM │
│ │
├─────────────────────┤ ← 栈顶(_estack)
│ 栈(STACK) │ ↓ 向下增长
│ 局部变量/函数调用 │
├─────────────────────┤
│ 堆(HEAP) │ ↑ 向上增长
│ malloc/free区 │
├─────────────────────┤ 0x2000 0800
│ .bss段 │
│ (未初始化全局变量) │
├─────────────────────┤ 0x2000 0000
│ .data段 │ ← RAM起始
│ (初始化全局变量) │
└─────────────────────┘STM32F103C8T6 里 ROM / RAM 是哪些
- 主 Flash(程序所在,常口头叫 ROM) :容量通常 64KB(C8 代表 64KB),用于存程序与常量。
- 物理地址:0x0800_0000
- System memory(出厂 Bootloader 所在,真正 ROM 区) :用于串口下载等系统引导程序。
- 物理地址(F103 非 connectivity line):0x1FFF_F000
- SRAM(真正 RAM) :20KB,用于栈/堆/全局变量/运行时数据。
- 物理地址:0x2000_0000
为什么必须要 "alias 到 0x0000_0000"
Cortex-M3 复位后会做两件"写死的事":
- 从 0x0000_0000 读初始 MSP(主栈指针)
- 从 0x0000_0004 读 Reset_Handler 并跳转执行
所以无论想从哪里启动(Flash / 系统 Bootloader / SRAM),都要保证在复位那一刻:
- 地址 0x0000_0000 处"看起来像"有一张正确的向量表
这就是 Boot memory alias 的作用:让 0x0000_0000 这块地址临时映射到选择的启动存储器上。
这里可以简单理解为:"CPU复位硬件规定" + "STM32用别名映射把0地址'指向'某块存储器" 两部分来看。
Cortex-M3 复位时硬件写死的取数流程是什么?
复位后,Cortex-M3 不会像传统 MCU 那样从 0 地址取第一条指令执行,而是先把 向量表(vector table) 当作"启动参数表"来读:
- 读
[0x0000_0000]→ 装载 MSP(主栈指针) - 读
[0x0000_0004]→ 装载 PC(复位向量 Reset_Handler 地址)并跳转
这两条在 ST 的 Cortex-M3 编程手册里写得很明确: - "On reset, the processor loads the MSP with the value from address 0x00000000."
- "On reset, the processor loads the PC with the value of the reset vector, which is at address 0x00000004."
所以复位那一瞬间,CPU 必须能在 0x0000_0000 读到一个"像样的向量表"。
向量表的前两项长这样: - 第 0 项:初始 MSP(一般是 RAM 末尾地址)
- 第 1 项:Reset_Handler 地址(注意最低位为 1,表示 Thumb 状态,这是 Cortex-M 的规则)
与其他MCU对比:
- 传统8051:直接从0x0000执行,没有别名映射
- ARM7/9:有专门的异常向量表,但位置固定
- STM32:灵活的别名映射,支持三种启动源
- 某些现代MCU:可以从多个Flash bank启动
为什么"必须 alias 到 0x0000_0000"?
因为在 STM32F103(Cortex-M3)里,代码区的固定起点就是 0x0000_0000,而 SRAM 从 0x2000_0000 开始;CPU 复位取向量时是走 ICode/DCode 总线去取"代码区"的内容。RM0008 明确说明了这一点:
- CPU 会从 0x0000_0000 取栈顶值、从 0x0000_0004 开始执行启动代码;
- 代码区从 0x0000_0000 开始,SRAM 从 0x2000_0000 开始;
因为复位向量在 ICode 总线上取,所以 boot space 必须出现在 code area(通常是 Flash),STM32 用"特殊机制"才能从 SRAM 启动。
但现实是: - 你的用户程序通常在 主 Flash 的物理地址 0x0800_0000
- 系统 Bootloader 在 System memory 的物理地址 0x1FFF_F000(F103 非 connectivity line)
- RAM 在 0x2000_0000
它们都不等于 0x0000_0000。
可 CPU 复位偏偏"只认 0x0000_0000/0x0000_0004"。
所以STM32必须做一件事: - 把 0x0000_0000 这块"启动窗口(boot memory space)" 临时映射(alias)到你选择的那块存储器上,让 CPU 能在 0 地址读到向量表。
总结
- Cortex-M3 复位硬规定:只从 0 地址取 MSP/PC。
- STM32F103 的主 Flash/System ROM/SRAM 的物理地址分别在 0x0800..., 0x1FFF..., 0x2000...,不在 0。
- 所以 STM32 必须用 Boot memory alias ,让 0x0000_0000 这块启动窗口"看起来像"你选择的那块存储器,从而让 CPU 能启动。
STM32F103C8T6 的三种启动 alias 关系(BOOT0/BOOT1)
常规:从主 Flash 启动(BOOT0=0)
- 0x0000_0000 → alias 到 主 Flash 的内容
- 同时主 Flash 仍然能用它的原始地址访问:0x0800_0000
因此:同一份 Flash 内容,既能从0x0000_0000读到,也能从0x0800_0000读到。
从系统 Bootloader 启动(BOOT0=1, BOOT1=0)
- 0x0000_0000 → alias 到 System memory(Bootloader)
- System memory 原始地址仍可访问:0x1FFF_F000 (F103 这类非 connectivity line)
这就是为什么拉 BOOT0 进 ISP/串口下载时,CPU 为什么能"像从 0 地址启动一样"跑到 Bootloader。
从 SRAM 启动(BOOT0=1, BOOT1=1)
- SRAM 仍然只在 0x2000_0000 可访问
- 当从 SRAM 启动时,必须把向量表重定位到 SRAM(用 NVIC 的向量表偏移寄存器,也就是 SCB->VTOR)
直觉理解: - 复位那一下 CPU 还是要从 0x0000_0000 抓向量;芯片用"特殊机制"让它完成启动
- 但进入 SRAM 程序后,中断向量不能一直指望在 0x0000_0000,所以需要把 VTOR 指到 SRAM 里的向量表,否则一来中断就会跳错地方(HardFault 很常见)。
这和堆/栈、程序存放有什么直接关系
- 程序代码/常量:通常在主 Flash(0x0800_0000),启动时 alias 让它出现在 0x0000_0000
- 堆/栈/全局变量/运行数据:都在 SRAM(0x2000_0000)
- 系统 Bootloader(ROM):在 System memory(0x1FFF_F000),当选择该启动模式时被 alias 到 0x0000_0000
在cortex m3中,什么是流水线
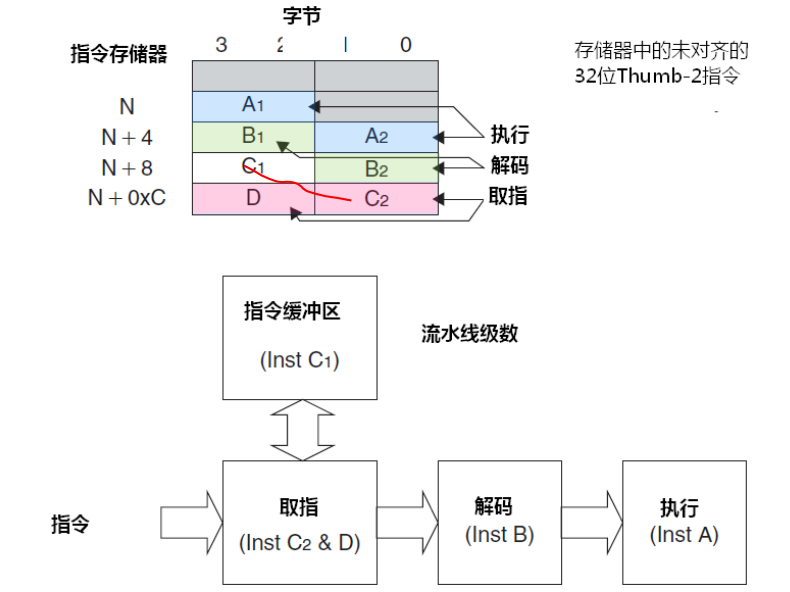
在Cortex-M3中,流水线是处理器内核用来同时处理多条指令、大幅提升执行效率的核心硬件技术。
流水线是将一条指令的执行过程拆解成多个更小、更简单的步骤 (称为"级"),并为每一步配备专用的硬件电路。这样,多条指令就可以像在装配线上一样同时被处理,每条指令处于不同的完成阶段。
Cortex-M3采用经典的3级流水线 :取指 -> 解码 -> 执行。
-
取指级
- 任务 :从程序存储器(通常是Flash)中,根据程序计数器的值,读取下一条要执行的指令。
- 硬件 :程序计数器 、I-Code总线 、预取指缓冲器(如果有)。
- 关键点 :取指可能需要多个时钟周期(由于Flash较慢)。为了缓解这个问题,Cortex-M3有一个指令预取单元,它会提前尝试读取后续指令,尽可能让流水线第一级"吃饱"。
-
解码级
- 任务 :对取来的指令进行"翻译",识别出这是一条什么指令(是ADD还是STR?),并生成控制CPU内部各个部件(如ALU、寄存器组)所需的所有控制信号。
- 硬件 :指令解码器。
- 关键点:对于Thumb-2指令集,解码器需要处理16位和32位混合的指令,这是其设计复杂之处。解码完成后,指令所需的操作数(寄存器值)也会被准备好。
-
执行级
- 任务:真正完成指令所规定的计算或操作。这是最复杂的一级。
- 硬件 :算术逻辑单元 、移位器 、寄存器组 、地址计算单元 、数据接口。
- 具体工作 :
- 对于算术指令:ALU进行加、减、逻辑运算。
- 对于加载/存储指令:计算内存地址,并通过数据总线进行读写。
- 对于分支指令:计算目标地址并更新PC。
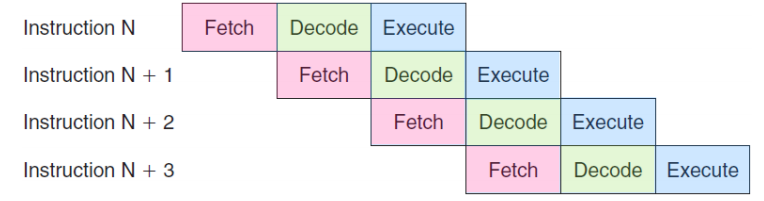
如何工作:
假设有3条顺序指令:ADD(加法), SUB(减法), LDR(加载)。在3级流水线下,时间流逝如下图所示:
txt
时钟周期 | 流水线状态
---------|-----------------------------
周期 1 | 取指 ADD | 空闲 | 空闲
周期 2 | 取指 SUB | 解码 ADD | 空闲
周期 3 | 取指 LDR | 解码 SUB | 执行 ADD
周期 4 | 取指 ... | 解码 LDR | 执行 SUB
周期 5 | ... | ... | 执行 LDR- 第3周期 是理想状态的体现:三条指令同时在流水线中,分别处于执行、解码、取指阶段。
- 平均来看,每个时钟周期都有一条指令完成执行 。对比无流水线(可能3个周期才完成一条指令),吞吐率提升了近3倍。
以下是Cortex-M3权威指南Cn原文: