Python文件操作超详细教程:从编码到实战案例

文件操作是Python编程中处理数据持久化存储的核心技能。本文将系统讲解文件的编码、读取、写入、追加等操作,并通过账单备份实战案例帮助大家彻底掌握文件处理技巧。
一、文件编码:数据存储的基础
1.1 为什么需要文件编码?
核心问题:计算机只能识别0和1,那么丰富的文本文件如何被计算机识别并存储在硬盘中?
答案:使用编码技术(类似密码本)将内容翻译成0和1进行存储。
1.2 什么是文件编码?
编码技术即翻译的规则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容。
常见的编码格式:
-
UTF-8(最常用,全球通用)
-
GBK
-
Big5
-
等其他编码
不同的编码将内容翻译成二进制也是不同的,因此必须使用正确的编码才能正确读写文件。
1.3 编码的重要性
如果发送方使用编码A进行编码,接收方使用编码B进行解码,就会出现乱码问题。因此统一的编码标准至关重要。
1.4 查看和选择编码
查看文件编码:使用Windows记事本打开文件,右下角显示编码格式(如UTF-8)
编码选择建议:
-
UTF-8是目前全球通用的编码格式
-
除非有特殊需求,否则一律使用UTF-8格式进行文件编码
1.5 编码总结
-
什么是编码:编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑
-
为什么需要编码:计算机只认识0和1,需要编码进行翻译转换
-
推荐编码:UTF-8编码
二、文件读取操作详解
2.1 文件的基本概念
什么是文件:内存中的数据在关机后消失,要长久保存数据就需要使用文件。文件是操作系统管理磁盘数据的基本单位。
文件分类:文本文件、视频文件、音频文件、图像文件、可执行文件等。
2.2 文件操作三步走
对文件的基本操作可以分为三个步骤:
-
打开文件
-
读写文件
-
关闭文件
注意:可以只打开和关闭文件,不进行任何读写操作。
2.3 open()打开函数

基本语法:
open(name, mode, encoding)参数说明:
-
name:要打开的目标文件名(可以包含具体路径) -
mode:打开文件的模式(只读、写入、追加等) -
encoding:编码格式(推荐UTF-8)
示例代码:
这里的 ""r"" 代表原始字符串,不然还得使用转义字符
python
f = open(r"F:\26_01\python\test\文件.txt",'r',encoding="utf-8")
print(f.read())重要提示:encoding参数需要用关键字参数指定,不能依赖位置参数。
2.4 常用的三种访问模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
2.5 读取文件的方法
read()方法:读取指定长度内容
文件对象.read(num)-
num表示要读取的数据长度(单位是字节) -
不传入
num则读取文件中所有数据
readlines()方法:按行读取全部内容
python
f = open('python.txt')
content = f.readlines()
# ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc']
print(content)
f.close()- 返回一个列表,每行数据为一个元素
readline()方法:一次读取一行
python
f = open('python.txt')
content = f.readline()
print(f'第一行: {content}')
content = f.readline()
print(f'第二行: {content}')
f.close()for循环逐行读取
这种方式循环结束会自动关闭文件
python
for line in open("python.txt", "r"):
print(line)
# 每一个line临时变量记录了文件的一行数据2.6 关闭文件的重要性
python
f = open("python.txt", "r")
f.close()
# 不调用close(),文件将一直被Python程序占用with open语法

python
with open("python.txt", "r") as f:
content = f.readlines()
# 操作完成后自动关闭文件,避免遗忘close()2.7 读取操作汇总
| 操作 | 功能 |
|---|---|
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节,不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
2.8 读取操作总结
-
操作文件需要通过open函数打开文件得到文件对象
-
文件对象有4种读取方法:read()、readline()、readlines()、for循环
-
文件读取完成后要使用close()方法关闭文件对象
-
推荐使用with open语法,自动管理文件关闭
2.9 练习:单词计数
需求:读取word.txt文件,统计"itheima"单词出现的次数
文件内容:
python
itheima itcast python
itheima python itcast
beijing shanghai itheima
shenzhen guangzhou itheima
wuhan hangzhou itheima
zhengzhou bigdata itheima参考实现:
python
f = open(r"F:\26_01\python\test\文件.txt", 'r', encoding="utf-8")
count = 0
my_list = f.readlines()
for x in my_list:
x = x.strip() # 新增:去除换行符和空格
if x == "": # 检查是否为空行
continue
danci_list = x.split(" ")
for y in danci_list:
if y == "itheima":
count += 1
print(count)
print("最终统计:", count)
f.close()注意:处理换行符
方法1:在分割前去除换行符(推荐)
修改代码,在分割单词前使用 strip()去除每行的首尾空白符(包括换行符):
python
f = open(r"F:\26_01\python\test\文件.txt", 'r', encoding="utf-8")
count = 0
my_list = f.readlines()
for x in my_list:
x = x.strip() # 新增:去除换行符和空格
if x == "": # 检查是否为空行
continue
danci_list = x.split(" ")
for y in danci_list:
if y == "itheima":
count += 1
print(count)
print("最终统计:", count)
f.close()方法2:使用 split()替代 split(" ")
split()默认按任意空白符(包括空格、换行符等)分割,并自动去除空元素:
python
for x in my_list:
if x.strip() == "":
continue
danci_list = x.split() # 无参数,自动处理空白符
for y in danci_list:
if y == "itheima":
count += 1方法3:在比较前清理单词
直接处理每个单词的换行符
python
for y in danci_list:
y = y.strip() # 清理单词的换行符
if y == "itheima":
count += 1三、文件写入操作详解


3.1 写入操作快速入门
python
# 1. 打开文件
f = open('python.txt', 'w')
# 2. 文件写入
f.write('hello world')
# 3. 内容刷新
f.flush()重要机制:
-
直接调用write(),内容积攒在程序内存中(缓冲区)
-
调用flush()时,内容真正写入文件
-
这种机制避免频繁操作硬盘,提高效率
3.2 写入操作注意事项
-
文件不存在:使用"w"模式会创建新文件
-
文件存在:使用"w"模式会清空原有内容
3.3 写入操作总结
-
写入文件使用open函数的"w"模式
-
写入方法:write()写入内容,flush()刷新到硬盘
-
注意事项:w模式会创建新文件或清空已有文件
-
close()方法自带flush()功能
四、文件追加操作详解

4.1 追加写入快速入门
python
# 1. 打开文件,通过a模式打开
f = open('python.txt', 'a')
# 2. 文件写入
f.write('hello world')
# 3. 内容刷新
f.flush()追加模式特点:
-
文件不存在:创建新文件
-
文件存在:在文件末尾追加内容
-
可以使用"\n"写入换行符
4.2 追加操作总结
-
追加写入使用open函数的"a"模式
-
写入方法与w模式一致
-
注意事项:a模式在文件末尾追加内容
扩展:b模式
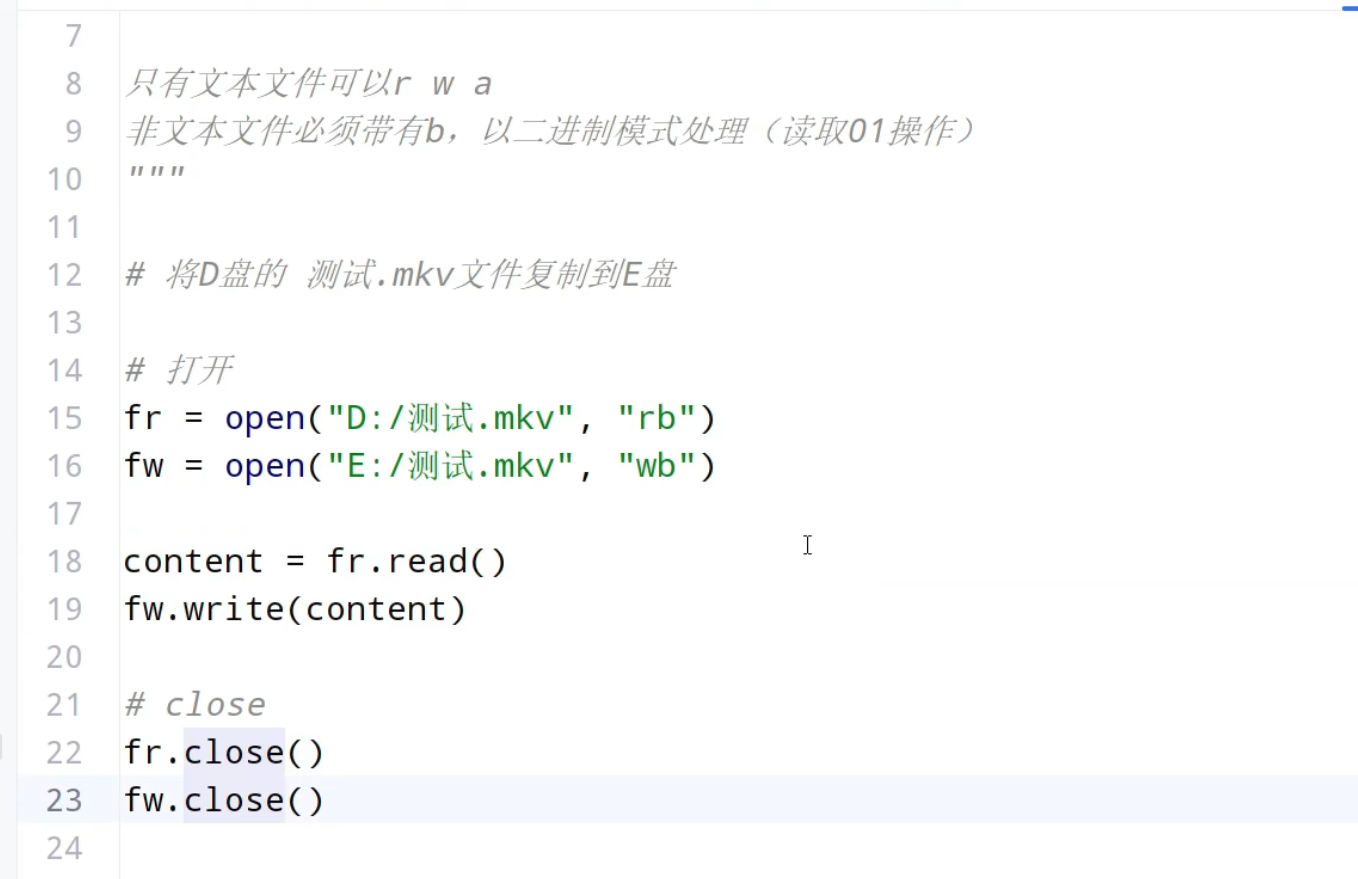
五、文件操作综合案例:账单备份
5.1 需求分析
原始账单文件(bill.txt)内容:
name,date,money,type,remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
(后续数据省略...)任务要求:
-
读取bill.txt文件
-
将文件写出到bill.txt.bak作为备份
-
丢弃标记为"测试"的数据行
5.2 实现思路
-
使用open和r模式打开源文件对象
-
使用open和w模式打开目标文件对象
-
for循环读取每行内容
-
判断remarks字段是否为"测试"
-
不是测试就write写出,是测试就跳过
-
关闭两个文件对象
5.3 完整代码实现
python
#读的文件
f = open(r"F:\26_01\python\test\bill.txt", 'r', encoding="utf-8")
#写的文件
t = open(r"F:\26_01\python\test\bill02.txt", 'w', encoding="utf-8")
#操作
for typr in f.readlines():
#去除前后的空格,以及换行符
typr = typr.strip()
#判断是否为空
if typr == " ":
continue
typr_list = typr.split(",")
#防止索引越界
if len(typr_list) <5:
t.write(typr + "\n")
continue
if "测试" == typr_list[4]:
continue
t.write(typr+"\n")
#关闭管道
f.close()
t.close()5.4 代码优化版本
python
def backup_bill_file(source_path, backup_path):
"""
备份账单文件并过滤测试数据
:param source_path: 源文件路径
:param backup_path: 备份文件路径
"""
try:
with open(source_path, 'r', encoding='UTF-8') as source_file:
with open(backup_path, 'w', encoding='UTF-8') as backup_file:
# 写入表头
header = source_file.readline()
backup_file.write(header)
# 处理数据行
for line in source_file:
line = line.strip()
if not line:
continue
parts = line.split(',')
if len(parts) >= 5 and parts[4] != '测试':
backup_file.write(line + '\n')
print(f"备份成功!文件已保存至: {backup_path}")
except FileNotFoundError:
print("错误:源文件不存在!")
except Exception as e:
print(f"处理文件时发生错误: {e}")
# 使用函数
backup_bill_file('bill.txt', 'bill.txt.bak')六、文件操作最佳实践
6.2 大文件读取优化
对于大文件,避免一次性读取全部内容:
python
# 不好的做法:一次性读取大文件
with open('large_file.txt', 'r') as f:
content = f.read() # 可能内存溢出
# 好的做法:逐行或分块读取
with open('large_file.txt', 'r') as f:
for line in f: # 逐行处理
process_line(line)
# 或者分块读取
def read_in_chunks(file_path, chunk_size=1024):
with open(file_path, 'r') as f:
while True:
chunk = f.read(chunk_size)
if not chunk:
break
yield chunk6.3 文件路径处理
python
import os
# 获取当前目录
current_dir = os.getcwd()
# 路径拼接
file_path = os.path.join('data', 'files', 'example.txt')
# 检查文件是否存在
if os.path.exists(file_path):
print("文件存在")七、总结
7.1 核心知识点回顾
-
文件编码:理解编码概念,统一使用UTF-8编码
-
文件读取:掌握多种读取方法及适用场景
-
文件写入:理解缓冲区机制,正确使用写入操作
-
文件追加:掌握追加模式的应用场景
-
实战应用:通过综合案例巩固文件操作技能
7.2 关键注意事项
-
始终指定正确的文件编码(推荐UTF-8)
-
使用with open语法自动管理文件关闭
-
大文件使用逐行或分块读取避免内存问题
-
写入操作后记得刷新缓冲区或关闭文件
-
做好异常处理,提高程序健壮性