

💗博主介绍:计算机专业的一枚大学生 来自重庆 @燃于AC之乐✌专注于C++技术栈,算法,竞赛领域,技术学习和项目实战✌💗
💗根据博主的学习进度更新(可能不及时)
💗后续更新主要内容:C语言,数据结构,C++、linux(系统编程和网络编程)、MySQL、Redis、QT、Python、Git、爬虫、数据可视化、小程序、AI大模型接入,C++实战项目与学习分享。
👇🏻 精彩专栏 推荐订阅👇🏻
点击进入🌌作者专栏🌌:
Linux系统编程✅
算法画解✅
C++✅🌟算法相关题目点击即可进入实操🌟
感兴趣的可以先收藏起来,请多多支持,还有大家有相关问题都可以给我留言咨询,希望希望共同交流心得,一起进步,你我陪伴,学习路上不孤单!
文章目录
- 前言
- 1.进程优先级
-
- [1.1 概念](#1.1 概念)
- [1.2 查看系统进程](#1.2 查看系统进程)
- [1.3 PRI和NI,查看与更改优先级](#1.3 PRI和NI,查看与更改优先级)
- [1.4 竞争,独立,并行,并发](#1.4 竞争,独立,并行,并发)
- 2.进程切换
-
- [2.1 死循环情况与CPU处理](#2.1 死循环情况与CPU处理)
- [2.2 具体切换方式](#2.2 具体切换方式)
- 3.linux真实调度算法O(1)调度队列
-
- [3.1 指针数组优先级](#3.1 指针数组优先级)
- [3.2 活动队列相关数据](#3.2 活动队列相关数据)
- [3.3 过期队列,active和expired指针](#3.3 过期队列,active和expired指针)
前言
在上一篇《【Linux系统编程】进程管理探秘:从硬件架构到僵尸/孤儿进程》中,我们揭开了Linux进程的生命周期与基础管理机制。当操作系统成功创建进程后,一个更深层的问题便自然浮现:
系统中有成百上千个进程在"同时"运行,CPU如何决定下一刻该执行哪一个?
这就是进程调度的核心问题------一场关于CPU时间分配的精密艺术。想象一下,后台下载软件、前台IDE编辑器、系统守护进程、用户交互命令......所有这些进程都在向CPU发出自己的执行请求。如果没有合理的调度机制,系统要么陷入混乱,要么效率低下。
本篇将带你深入Linux调度的核心层:
优先级战场:为什么有些进程能"插队"?PRI和NI值如何影响进程的"地位"?
切换的代价:当CPU从一个进程切换到另一个时,到底发生了什么"幕后工作"?
O(1)调度算法:Linux历史上经典的调度器如何用巧妙的数据结构实现高效调度?
理解调度机制不仅是系统编程的进阶必备,更能帮助你:
优化程序性能,合理设置进程优先级
诊断系统卡顿、响应延迟的根本原因
深入理解操作系统设计的精妙之处
让我们继续这次Linux内核之旅,从表面的进程管理,深入到决定它们执行顺序的调度核心。你会发现,看似"自动"的进程执行背后,隐藏着一套精密而优雅的协调机制。
1.进程优先级
1.1 概念
CPU资源分配的先后顺序,进程优先级(priority)。
优先级高的进程先得到CPU分配的资源,有优先执行的权利。
为什么会这样设计?因为目标资源稀缺。
好处:对多任务环境linux有益,可以把进程(如:不重要的进程)安排到指定的CPU上,可以改善系统性能。
区分:优先级 vs 权限, 优先级:能得到(做),但是有先后 问题;, 而权限:是能不能得到(做)的问题。
1.2 查看系统进程
在Linux/unix, 用ps-l命令输出内容如下:

重要信息:
1.UID:执行者(用户)身份。
2.PID:进程的代号。
3.PPID:这个进程是由那个进程发展衍生而来的,父进程。
4.PRI:这个进程可被执行的优先级,越小优先级越高。
5.NI:进程的nice值(修改值)。
1.3 PRI和NI,查看与更改优先级
PRI:进程的优先级,程序被CPU执行的先后顺序,值越小,优先级越高,越早被执行。(可变化,但是变化幅度不大)
NI: nice值,优先级的修正值。
PRI(新) = PRI(默认, 80)+ nice,注意:规定每次修改都是从默认值80改。
nice值为-, 优先级变大,+,优先级变小。
在linux下,调整优先级,就是调整nice值,nice: -20~19,一共40个级别,就是 60~79。
⽤top命令更改已存在进程的nice:
top
进⼊top后按"r"‒>输⼊进程PID‒>输⼊nice值
其他调整优先级的命令:nice,renice
1.4 竞争,独立,并行,并发
1.竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级。
2.独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰。
3.并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行。
4.并发: 多个进程在⼀个CPU下采用进程切换的方式,在⼀段时间之内,让多个进程都得以推进,称之为并发。
思考:我们的电脑,1个CPU,只能跑一个进程,为什么我们感觉可以同时使用多个进程(打开QQ,微信,听歌,上课,敲代码),实际上这就是并发。因为进程切换的非常之快,ms, 所以在1s内,给我们的感觉就是多个进程都在运行,可以将一个CPU,看成n个逻辑上的CPU,效率为1/n。
并行与并发。
2.进程切换
2.1 死循环情况与CPU处理
时间片:当代计算机都是分时操作系统,没有进程都有它合适的时间片(其实就是⼀个计数器)。时间片到达,进程就被操作系统从CPU中剥离下来。
1.死循环:一旦一个进程占CPU,不一定会跑完代码,会受到分配的时间片的限制,不会一直占用CPU。
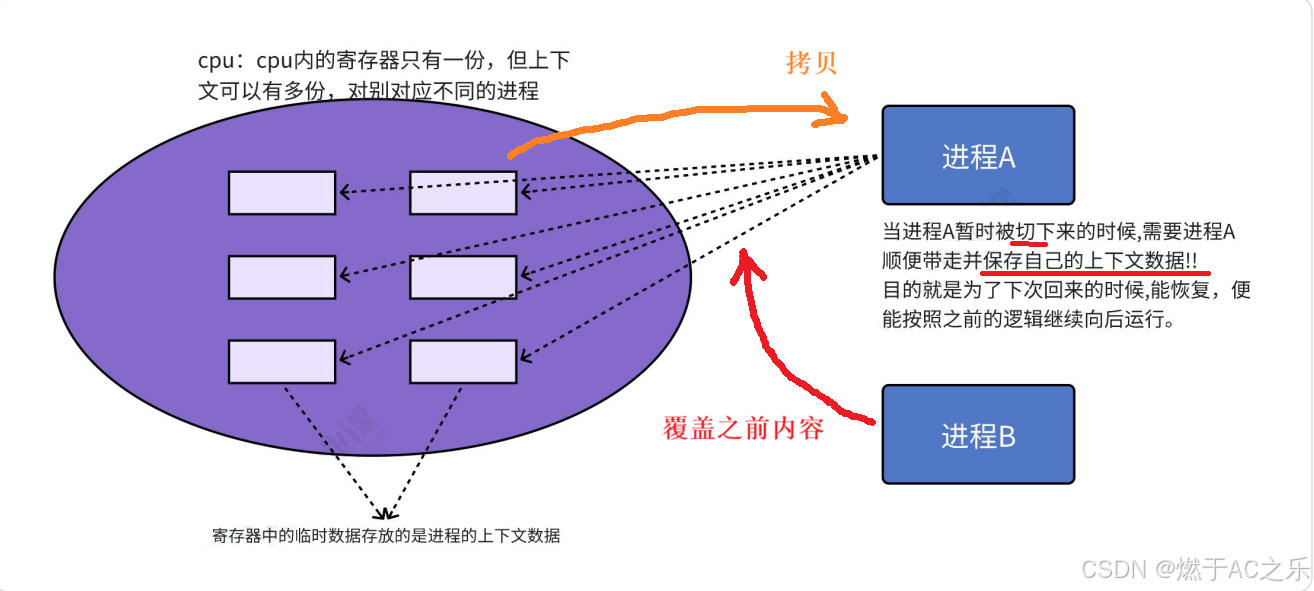
2.CPU读取进程中的代码和数据是一条一条的读的,读取后存到寄存器中,临时保存,寄存器:PC/EIP(下条指令地址),ebp/esp/ea/b/c/dx,cs/ds/es/fg/gs,eflags/cr0~cr4......
结论:寄存器是CPU内部临时空间,寄存器!=寄存器里面的数据。
2.2 具体切换方式
CPU上下文切换:任务切换, 或CPU寄存器切换。当多任务内核决定运⾏另外的任务时, 它保存正在运行任务的当前状态, 也就是CPU寄存器中的全部内容。这些内容被保存在任务自己的堆栈中, 入栈⼯作完成后就把下⼀个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器,
并开始下⼀个任务的运行。
进程切换:最核心就是保存和恢复当前进程的硬件上下文数据,CPU寄存器的内容。
拷贝到进程A的task_struct: tss(任务状态段)。
区分:全新的进程,还是已调度过的,(bool标记isrunning)
补充:全局指针:struct task_struct* current标记当前的task_struct。

3.linux真实调度算法O(1)调度队列
3.1 指针数组优先级
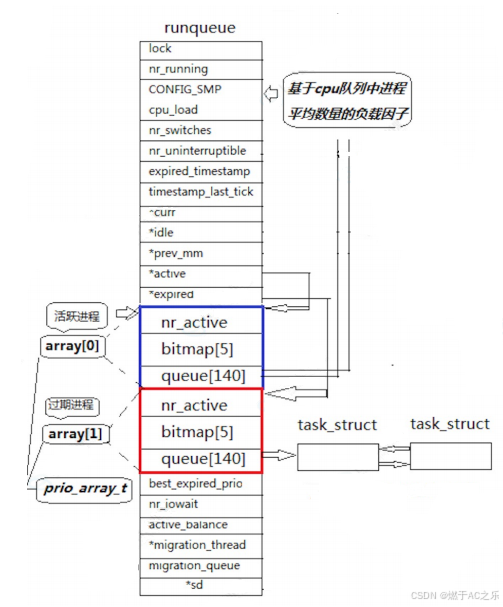
⼀个CPU拥有⼀个runqueue
如果有多个CPU就要考虑进程个数的负载均衡问题:CPU上的进程数是否相对均衡。
指针数组(struct task_struct* queue140)
实时操作系统:实时优先级:0〜99(我们这里不考虑)
应用于许多工业领域,汽车刹车,要立即执行。
分时操作系统:普通优先级:100〜139(nice值的取值范围,可与之对应!) 后端服务器应用广泛。
3.2 活动队列相关数据
时间片还没有结束的所有进程都按照优先级放在该队列
nr_active: 总共有多少个运行状态的进程
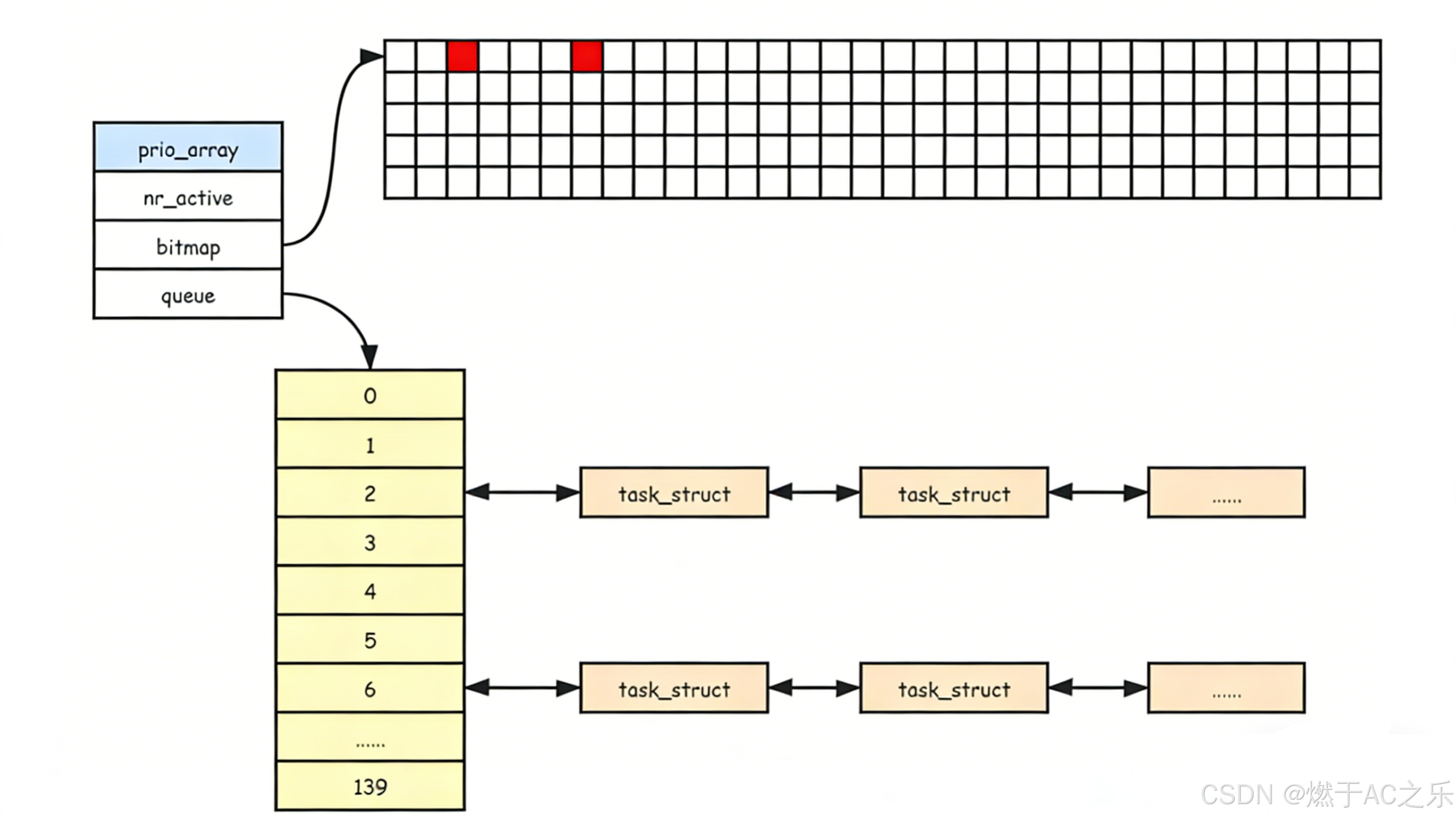
queue140: ⼀个元素就是⼀个进程队列,相同优先级的进程按照FIFO规则进行排队调度,所以,数组下标就是优先级。
从该结构中,选择⼀个最合适的进程,过程是怎么的呢?
- 从0下表开始遍历queue140
- 找到第⼀个非空队列,该队列必定为优先级最高的队列
- 拿到选中队列的第⼀个进程,开始运行,调度完成!
- 遍历queue140时间复杂度是常数!但还是太低效了!
• bitmap5:⼀共140个优先级,⼀共140个进程队列,为了提⾼查找⾮空队列的效率,就可以⽤
5*32个⽐特位表⽰队列是否为空,这样,便可以⼤ 提⾼查找效率!
3.3 过期队列,active和expired指针
过期队列和活动队列结构⼀样。过期队列上放置的进程,都是时间片耗尽的进程。
当活动队列上的进程都被处理完毕之后,对过期队列的进程进行时间片重新计算 。
抢占插队,进入的是活动队列。
active指针永远指向活动队列。(struct rqueue_elemactive= &prio_array0)
expired指针永远指向过期队列。(struct rqueue_elem active= &prio_array1)
可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时⼀直都存在的。
在合适的时候,只要能够交换active指针和expired指针的内容,就相当于有具有了⼀批新的活动进程。
在系统当中查找⼀个最合适调度的进程的时间复杂度是⼀个常数,不随着进程增多而导致时间成本增加,我们称之为进程调度O(1)算法。
cpp
struct rq {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
unsigned long raw_weighted_load;
#ifdef CONFIG_SMP
unsigned long cpu_load[3];
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
struct task_struct *curr, *idle;
struct mm_struct *prev_mm;
struct prio_array *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* For active balancing */
int active_balance;
int push_cpu;
struct task_struct *migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_local;
#endif
struct lock_class_key rq_lock_key;
};
/*
* These are the runqueue data structures:
*/
struct prio_array {
unsigned int nr_active;
DECLARE_BITMAP(bitmap, MAX_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_PRIO];
};

加油!志同道合的人会看到同一片风景。
看到这里请点个赞 ,关注 ,如果觉得有用就收藏一下吧。后续还会持续更新的。 创作不易,还请多多支持!