目录
[2.1 什么是分库分表](#2.1 什么是分库分表)
[2.2 微服务中为什么要分库分表](#2.2 微服务中为什么要分库分表)
[2.3 微服务中常用的分库分表解决方案](#2.3 微服务中常用的分库分表解决方案)
[2.3.1 客户端分片方案](#2.3.1 客户端分片方案)
[2.3.2 中间件代理方案](#2.3.2 中间件代理方案)
[2.4 分布式数据库方案](#2.4 分布式数据库方案)
[2.5 ShardingSphere-Proxy 介绍](#2.5 ShardingSphere-Proxy 介绍)
[2.5.1 ShardingSphere-Proxy 是什么](#2.5.1 ShardingSphere-Proxy 是什么)
[2.5.2 ShardingSphere-Proxy 特点](#2.5.2 ShardingSphere-Proxy 特点)
[2.5.3 ShardingSphere-Proxy 适用场景](#2.5.3 ShardingSphere-Proxy 适用场景)
[三、ShardingSphere-Proxy 服务搭建](#三、ShardingSphere-Proxy 服务搭建)
[3.1 docker部署两个mysql示例](#3.1 docker部署两个mysql示例)
[3.1.1 部署第一个mysql示例](#3.1.1 部署第一个mysql示例)
[3.1.2 部署第二个mysql示例](#3.1.2 部署第二个mysql示例)
[3.1.3 验证下2个mysql示例是否可以正常连接](#3.1.3 验证下2个mysql示例是否可以正常连接)
[3.2 ShardingSphere-Proxy服务部署](#3.2 ShardingSphere-Proxy服务部署)
[3.2.1 创建必要的数据目录](#3.2.1 创建必要的数据目录)
[3.2.2 获取ShardingSphere-Proxy安装包](#3.2.2 获取ShardingSphere-Proxy安装包)
[3.2.3 解压安装包](#3.2.3 解压安装包)
[3.2.4 ShardingSphere-Proxy配置](#3.2.4 ShardingSphere-Proxy配置)
[3.2.5 启动与停止服务](#3.2.5 启动与停止服务)
[3.2.6 效果验证](#3.2.6 效果验证)
[3.3 ShardingSphere-Proxy 常用分片策略介绍](#3.3 ShardingSphere-Proxy 常用分片策略介绍)
[3.3.1 常用的分片规则](#3.3.1 常用的分片规则)
[3.4 常用的分片配置规则实战操作配置](#3.4 常用的分片配置规则实战操作配置)
[3.4.1 取模分片](#3.4.1 取模分片)
[3.4.2 HASH分片](#3.4.2 HASH分片)
[3.4.3 时间范围分片](#3.4.3 时间范围分片)
[3.4.4 行表达式分片](#3.4.4 行表达式分片)
[3.4.5 复合分片策略(多字段组合)](#3.4.5 复合分片策略(多字段组合))
[3.4.6 Hint强制路由分片](#3.4.6 Hint强制路由分片)
[3.4.7 范围分片策略](#3.4.7 范围分片策略)
一、前言
在微服务开发中,随着业务数据表数据量的不断增大,分库分表是应对数据量增长和高并发访问的重要架构手段,使用分库分表一方面可以应对数据量过大的问题,另一方面可以缓解数据库的高并发压力。在实际的架构设计与选型中,分库分表在具体的实践上也有很多种策略,比如基于程序端的ShardingJdbc,基于数据库端的ShardingSphere-Proxy,如果是那种比较简单的分库分表,还可以手写分库分表策略,本文以ShardingSphere-Proxy为例,介绍一下ShardingSphere-Proxy在分库分表中的具体使用。
二、微服务中分库分表介绍
2.1 什么是分库分表
分库分表就是把一个大数据库拆分成多个小数据库,把一个大表拆分成多个小表的技术手段。
1)为什么分库
-
分散压力:不同业务用不同数据库,不互相影响
-
故障隔离:一个数据库挂了,不影响其他业务
-
独立扩展:热门业务可以单独升级硬件
下面这张图清晰的描述了分库的过程
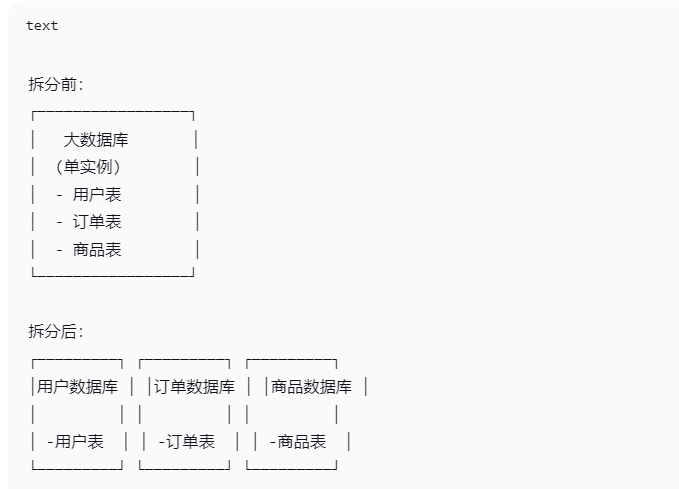
2)为什么分表
-
查询更快:100万数据的表比1亿数据的表查询快很多
-
维护容易:备份、修复小表更快
-
并行操作:可以同时操作多个表
分表就是把一个大表拆分成多个小表,下面这张图清晰展示了分表的过程

2.2 微服务中为什么要分库分表
在微服务开发中,使用分库分别主要解决下面几个核心问题
-
数据规模爆炸问题
-
单表数据量超过千万级时,查询性能急剧下降(如用户表10亿数据)
-
索引维护成本高,DDL操作锁表时间长
-
-
高并发瓶颈问题
-
单数据库连接数有限(MySQL默认151连接)
-
微服务多实例并发可能耗尽连接池,导致服务雪崩
-
-
服务耦合问题
-
多服务共享一个数据库,导致:
-
数据库变更影响所有服务
-
故障传播(一个服务拖垮整个数据库)
-
无法独立扩展数据库资源
-
-
2.3 微服务中常用的分库分表解决方案
下面介绍几种在微服务开发中常用的分库分表解决方案
2.3.1 客户端分片方案
客户端分片,在应用层直接实现分片逻辑,无代理层,比较有名也是使用较多的为ShardingSphere 生态(最主流),包括:ShardingSphere-JDBC,和ShardingSphere-Proxy
1)ShardingSphere-JDBC
-
轻量级 Java 框架
-
以 Jar 包形式提供服务
-
支持数据分片、读写分离、分布式事务
-
兼容 MyBatis、JPA、Hibernate
2)ShardingSphere-Proxy
-
透明化代理服务
-
支持任意兼容 MySQL/PostgreSQL 协议的客户端
-
适合异构语言架构
2.3.2 中间件代理方案
中间件代理的特点是:独立部署代理层,应用透明访问,下面介绍几种常用的方案
1)MyCat
-
老牌国产中间件
-
支持 MySQL 协议
-
功能全面(分片、读写分离、故障切换)
-
社区活跃,文档丰富
2)ProxySQL + Vitess
-
ProxySQL:高性能 MySQL 代理
-
Vitess:YouTube 开源的集群方案
-
适合云原生部署
-
支持水平扩展和自动化运维
3)阿里云 DRDS / PolarDB-X
-
云厂商托管方案
-
完全兼容 MySQL
-
自动分片,无需应用改造
-
企业级功能(全局索引、分布式事务)
2.4 分布式数据库方案
这种数据库原生支持分布式,应用无感知,对开发者来说,无需关注背后的实现原理,做到开箱即用
1)TiDB
-
兼容 MySQL 协议
-
自动水平扩展
-
强一致性分布式事务
-
HTAP 混合负载
2)CockroachDB
-
兼容 PostgreSQL 协议
-
全球分布式
-
强一致性
-
自动数据分片和平衡
3)OceanBase
-
原生分布式数据库
-
高可用,强一致
-
支付宝核心系统验证
2.5 ShardingSphere-Proxy 介绍
2.5.1 ShardingSphere-Proxy 是什么
ShardingSphere-Proxy 是 Apache ShardingSphere 生态中的一个透明化数据库代理。其核心定位是作为一个独立部署的中间层服务,位于应用程序与后端被分片的数据库集群之间,对外提供一个标准化的、逻辑单一的数据库入口。
简单来说,你可以将它理解为一个 "数据库翻译官" 或 "统一网关"。应用程序像连接一个普通数据库一样连接它,而它则负责将接收到的 SQL 请求,按照预设的分片、读写分离等规则,透明地转发到底层多个真实的物理数据库或数据节点中执行,并将结果汇总后返回给应用。
2.5.2 ShardingSphere-Proxy 特点
ShardingSphere-Proxy 具备如下特点:
-
中心化透明代理
-
独立进程部署:作为独立的中间件服务运行,与应用进程分离
-
统一接入入口:为应用程序提供单一的逻辑数据库入口点
-
架构解耦:将分片逻辑从应用中剥离,集中到代理层管理
-
-
多数据库协议兼容
-
MySQL 协议全面兼容:支持 MySQL 5.7/8.0 协议版本
-
PostgreSQL 协议支持:兼容 PostgreSQL 协议及生态工具
-
协议级透明:客户端无需感知后端分片细节
-
-
零应用侵入性
-
配置透明:应用仅需修改数据库连接地址,无需调整业务代码
-
SQL 兼容:支持绝大多数标准 SQL 语法和特性
-
驱动无感:使用各语言原生的数据库驱动即可连接
-
-
完整的分片能力继承
-
灵活分片策略:支持行表达式、时间范围、哈希取模等多种分片算法
-
分布式主键:内置 Snowflake 等分布式ID生成器
-
强制分片路由:支持通过 Hint 方式手动指定路由目标
-
-
数据治理能力强
-
可观测性:内置 Metrics 指标、链路追踪和 SQL 审计日志
-
弹性管控:支持动态配置更新、实例熔断和禁用
-
安全特性:提供 SQL 防火墙、黑白名单等安全控制
-
-
分布式事务支持
-
XA 事务:支持标准的 XA 分布式事务协议
-
柔性事务:集成 Seata 等柔性事务解决方案
-
本地事务:保证单分片内的 ACID 特性
-
2.5.3 ShardingSphere-Proxy 适用场景
在微服务架构中,ShardingSphere-Proxy 通常作为一个独立的、共享的基础设施服务来部署。所有需要访问分片数据库的微服务,都将数据库连接指向它。
选型建议:
-
选择 ShardingSphere-Proxy,当:你的技术栈是多语言异构的;你希望对分片细节对业务开发完全透明;你的团队希望由 DBA 或基础设施团队统一管控数据访问层;你在对一个遗留的单体数据库系统进行平滑的分布式改造。
-
选择 ShardingSphere-JDBC,当:你的技术栈以 Java 为主;你追求极致的性能和最低的网络延迟;你希望架构简单、轻量,避免引入额外的代理服务。
三、ShardingSphere-Proxy 服务搭建
为了后续的案例实践和配置,首先来搭建ShardingSphere-Proxy的使用环境。
3.1 docker部署两个mysql示例
3.1.1 部署第一个mysql示例
部署第一个MySQL实例(主节点,端口3306),执行下面的命令
bash
docker run -d \
--name=mysql-master \
-e MYSQL_ROOT_PASSWORD=root123 \
-e MYSQL_DATABASE=sharding_db \
-p 3306:3306 \
mysql:8.0.29执行之后,使用docker ps命令检查下是否执行成功

3.1.2 部署第二个mysql示例
部署第二个MySQL实例(从节点,端口3307),执行下面的命令
bash
docker run -d \
--name=mysql-slave \
-e MYSQL_ROOT_PASSWORD=root123 \
-e MYSQL_DATABASE=sharding_db \
-p 3307:3306 \
mysql:8.0.29执行之后,使用docker ps命令检查下是否执行成功

3.1.3 验证下2个mysql示例是否可以正常连接
进入docker容器后,执行下面的命令,如果能看到下面的效果,说明mysql示例正常运行,两个docker示例均做如此操作
bash
mysql -h 127.0.0.1 -P 3306 -u root -proot123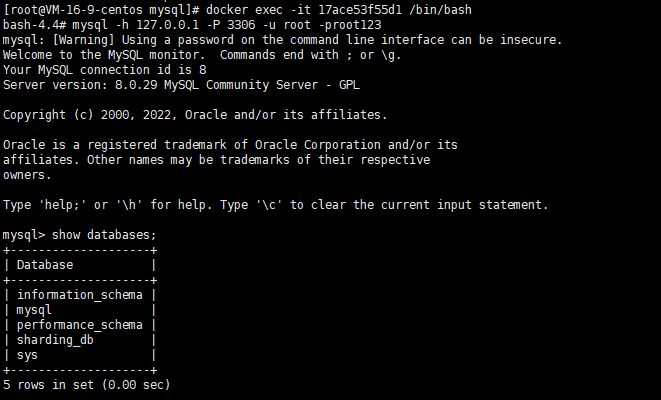
3.2 ShardingSphere-Proxy服务部署
接下来详细介绍ShardingSphere-Proxy的服务部署过程
3.2.1 创建必要的数据目录
创建数据配置目录
bash
mkdir -p /opt/shardingsphere
cd /opt/shardingsphere3.2.2 获取ShardingSphere-Proxy安装包
依次执行下面的命令获取ShardingSphere-Proxy的安装包
bash
# 下载最新版(请检查官网获取最新版本号)
SHARDING_VERSION="5.3.2"
wget "https://archive.apache.org/dist/shardingsphere/${SHARDING_VERSION}/apache-shardingsphere-${SHARDING_VERSION}-shardingsphere-proxy-bin.tar.gz"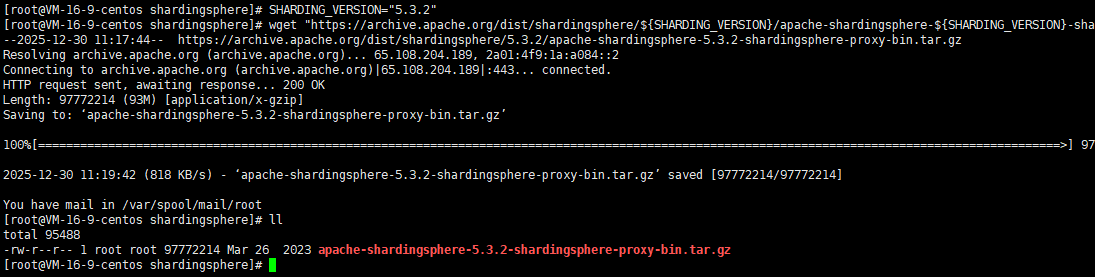
3.2.3 解压安装包
执行下面的命令进行安装包解压
bash
# 解压
tar -zxvf apache-shardingsphere-5.3.2-shardingsphere-proxy-bin.tar.gz
cd apache-shardingsphere-5.3.2-shardingsphere-proxy-bin/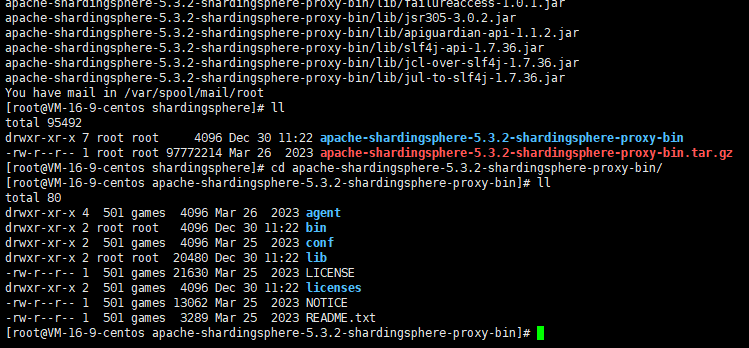
目录结构说明
bash
.
├── bin/ # 启动脚本
│ ├── start.sh # 启动脚本
│ └── stop.sh # 停止脚本
├── conf/ # 配置文件目录
│ ├── server.yaml # 服务器配置
│ └── config-xxx.yaml # 数据源和规则配置
├── lib/ # 依赖库
├── logs/ # 日志目录
└── ext-lib/ # 扩展库目录3.2.4 ShardingSphere-Proxy配置
首先,进入到conf目录下,对原始的配置文件进行备份
bash
cp conf/server.yaml conf/server.yaml.bak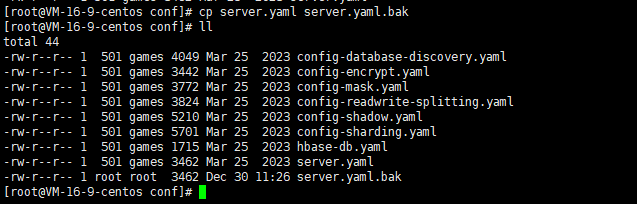
编辑server.yaml,通过下面的命令,将配置信息写入到server.yaml中
bash
cat > conf/server.yaml << 'EOF'
mode:
type: Standalone
repository:
type: JDBC
rules:
- !AUTHORITY
users:
- root@%:root
- admin@%:admin123
provider:
type: ALL_PRIVILEGES_PERMITTED
props:
max-connections-size-per-query: 50
kernel-executor-size: 16
sql-show: true
sql-simple: true
EOF某些情况下,上面的这种配置写法可能会在服务启动的时候报错,提示yaml格式异常,这种情况下,可以调整为下面的写法
bash
mode:
type: Standalone
repository:
type: JDBC
authority:
users:
- user: root
password: admin123
- user: sharding
password: sharding
privilege:
type: ALL_PERMITTED
props:
max-connections-size-per-query: 50
kernel-executor-size: 16
sql-show: true
sql-simple: true某些情况下,上面的这种配置写法可能会在服务启动的时候报错,提示yaml格式异常,这种情况下,可以调整为下面的写法
bash
mode:
type: Standalone
repository:
type: JDBC
authority:
users:
- user: root
password: admin123
- user: sharding
password: sharding
privilege:
type: ALL_PERMITTED
props:
max-connections-size-per-query: 50
kernel-executor-size: 16
sql-show: true
sql-simple: true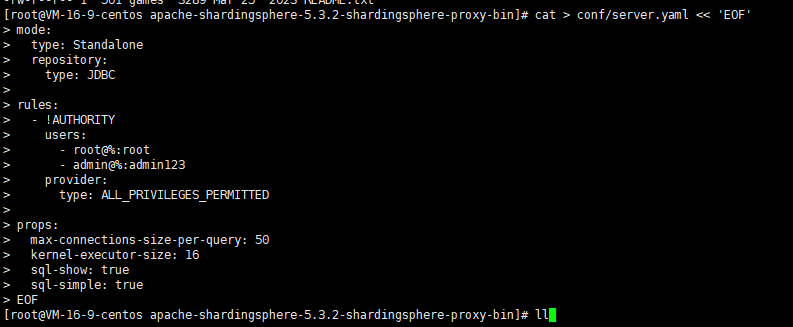
创建数据源配置,执行下面的命令,将原始的config-sharding.yaml文件内容进行替换
-
原始的配置提供了参考使用的demo,这里使用下面的配置信息进行替换;
-
注意数据库的连接信息使用你自己的即可;
bash
cat > conf/config-sharding.yaml << 'EOF'
databaseName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://localhost:3306/demo_ds_0?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
EOF3.2.5 启动与停止服务
使用下面的命令进行服务的启动和停止
bash
# 1. 启动服务
cd /opt/shardingsphere/apache-shardingsphere-5.3.2-shardingsphere-proxy-bin
./bin/start.sh
# 查看启动日志
tail -f logs/stdout.log
# 2. 停止服务
./bin/stop.sh
# 3. 查看进程状态
ps aux | grep java | grep shardingsphere启动服务


如果启动过程中出现下面的错误,请找一个mysql的8.X的jar包上传到lib目录下

最后,通过navicat连一下,可以看到,通过当前的shardingsphere服务已经可以成功代理目标数据库了
- 默认端口是3307
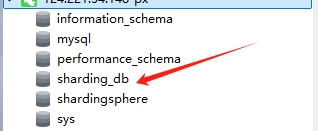
3.2.6 效果验证
接下来在shardingsphere的代理连接看到的sharding_db中创建一张数据表
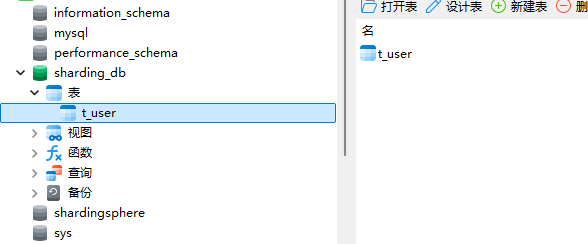
然后在真实的数据库节点下,就能看到这个表了
- 可以简单理解为,shardingsphere是在代理真实的数据库做一些操作
3.3 ShardingSphere-Proxy 常用分片策略介绍
3.3.1 常用的分片规则
ShardingSphere提供了丰富的分片规则,如下图:
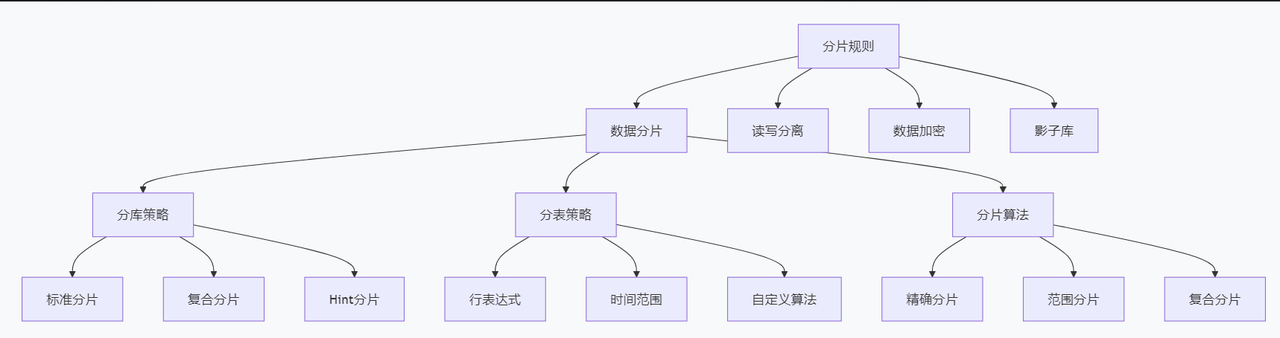
下面对其中的分片规则做一下说明
-
标准分片(Standard Sharding)
-
最基础的分片方式,适用于单个分片键的场景
-
精确分片:
=,IN查询 -
范围分片:
BETWEEN,<,>查询 -
实现接口:
StandardShardingAlgorithm
-
-
-
复合分片(Complex Sharding)
-
支持多个分片键组合分片
-
多个字段共同决定数据路由
-
实现接口:
ComplexKeysShardingAlgorithm
-
-
-
行表达式分片(Inline Sharding)
-
通过简单配置实现分片,无需编码
-
使用 Groovy 表达式
-
示例:
ds${order_id % 2}
-
-
-
Hint 分片(Hint Sharding)
-
通过编程 Hint 强制指定路由
-
不依赖 SQL 中的分片键
-
手动指定路由目标
-
-
-
时间范围分片(Date/Time Range Sharding)
-
按时间维度自动分片
-
支持年、月、日等粒度
-
自动管理时间分区
-
-
-
取模分片(Mod Sharding)
-
最常用的均匀分布算法
-
order_id % n方式路由 -
确保数据均匀分布
-
-
-
哈希分片(Hash Sharding)
-
使用哈希函数分片
-
如一致性哈希
-
减少扩容时数据迁移
-
-
-
范围分片(Range Sharding)
-
按数据范围划分
- 如 ID 范围:1-1000 到 ds0,1001-2000 到 ds1
-
对于不同的场景下,分片的使用规则各有不同,下面是一些参考建议:
-
均匀分布:取模分片
-
多条件查询:复合分片
-
时间序列数据:时间范围分片
-
简单配置:行表达式分片
-
特殊路由需求:Hint 分片
3.4 常用的分片配置规则实战操作配置
3.4.1 取模分片
取模分片(Mod Sharding)是最常用的分片算法之一,通过取余运算将数据均匀分布到多个数据节点上。基本公式:分片位置 = 分片键值 % 分片总数
- 特点:数据均匀分布,扩容需迁移数据
bash
rules:
- !SHARDING
shardingAlgorithms:
database_inline_mod:
type: MOD
props:
sharding-count: 2 # 分2个库
table_inline_mod:
type: MOD
props:
sharding-count: 4 # 每个库分4个表
tables:
t_order:
actualDataNodes: ds${0..1}.t_order_${0..3}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline_mod
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline_mod取模分片包括:
-
行表达式配置
-
标准取模
-
HASH取模
下面是一个完整的配置案例,按照订单系统分库分表(2库×4表)
bash
# config-sharding.yaml
dataSources:
ds0:
url: jdbc:mysql://localhost:3306/db_order_0?useSSL=false
username: root
password: 123456
ds1:
url: jdbc:mysql://localhost:3306/db_order_1?useSSL=false
username: root
password: 123456
rules:
- !SHARDING
shardingAlgorithms:
# 1. 分库算法:用户ID取模
db_mod:
type: INLINE
props:
algorithm-expression: ds${user_id % 2}
# 2. 分表算法:订单ID取模
table_mod:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 4}
# 3. 范围分表算法:用于范围查询优化
table_range_mod:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 4}
allow-range-query-with-inline-sharding: true # 允许范围查询
tables:
t_order:
# 实际物理表:ds0.t_order_0 到 ds1.t_order_3
actualDataNodes: ds${0..1}.t_order_${0..3}
# 分库策略:按用户ID取模
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: db_mod
# 分表策略:按订单ID取模
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_mod
# 主键生成策略
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# 绑定表:订单明细表
t_order_item:
actualDataNodes: ds${0..1}.t_order_item_${0..3}
databaseStrategy:
standard:
shardingColumn: order_id # 与主表使用相同分片键
shardingAlgorithmName: db_mod
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_mod
keyGenerators:
snowflake:
type: SNOWFLAKE
bindingTables:
- t_order,t_order_item取模分片具有如下优点:
-
数据分布均匀:确保各分片数据量基本平衡
-
配置简单:只需定义分片数量和取模字段
-
查询高效:精确查询能直接定位到具体分片
-
易于理解:算法直观,便于维护
3.4.2 HASH分片
HASH分片是通过哈希函数对分片键值进行计算,将结果映射到具体分片位置的分片算法。相比简单取模,HASH分片能提供更好的数据分布均匀性和扩容友好性。基本公式:分片位置 = HASH(分片键值) % 分片总数
下面是一个最基础的配置:
bash
shardingAlgorithms:
hash_mod_sharding:
type: HASH_MOD
props:
sharding-count: 8
hash-function: MD5 # 可选:MD5、SHA-1、SHA-256HASH分片常用形式:
-
标准HASH_MOD分片
-
一致性哈希分片(扩容友好)
-
自定义哈希分片
下面是一个标准的HASH_MOD分片完整配置
bash
# config-sharding-hash.yaml
dataSources:
ds0:
url: jdbc:mysql://localhost:3306/db0
username: root
password: 123456
ds1:
url: jdbc:mysql://localhost:3306/db1
username: root
password: 123456
rules:
- !SHARDING
shardingAlgorithms:
# 1. HASH_MOD分库算法
database_hash_mod:
type: HASH_MOD
props:
sharding-count: 2 # 2个数据库
hash-function: SHA-256 # 使用SHA-256哈希
# 2. HASH_MOD分表算法
table_hash_mod:
type: HASH_MOD
props:
sharding-count: 8 # 8个表
hash-function: MD5 # 使用MD5哈希
# 3. 一致性哈希算法(推荐生产环境)
table_consistent_hash:
type: CONSISTENT_HASH
props:
sharding-count: 16 # 16个分片
tables:
# 方案A:使用HASH_MOD分片
t_order_hash:
actualDataNodes: ds${0..1}.t_order_hash_${0..7}
databaseStrategy:
standard:
shardingColumn: order_no # 订单号作为分片键
shardingAlgorithmName: database_hash_mod
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: table_hash_mod
# 方案B:使用一致性哈希分片
t_order_consistent:
actualDataNodes: ds${0..1}.t_order_consistent_${0..15}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_hash_mod
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: table_consistent_hash3.4.3 时间范围分片
在某些情况下,如果能够预知数据的分布与时间范围有着对应关系,就可以考虑使用按照时间范围分片这种策略
- 适合日志,历史归档类的数据
bash
# conf/config-sharding-interval.yaml
databaseName: sharding_interval_db
rules:
- !SHARDING
shardingAlgorithms:
# 时间范围分片(按月)
table_interval_by_month:
type: INTERVAL
props:
datetime-pattern: "yyyy-MM-dd HH:mm:ss"
datetime-lower: "2024-01-01 00:00:00"
datetime-upper: "2024-12-31 23:59:59"
sharding-suffix-pattern: "yyyyMM" # 表后缀:202401, 202402...
datetime-interval-amount: 1
datetime-interval-unit: "MONTHS"
auto-tables-range: "2024-01,2024-12" # 自动创建分区
# 按周分片
table_interval_by_week:
type: INTERVAL
props:
datetime-pattern: "yyyy-MM-dd"
datetime-lower: "2024-01-01"
sharding-suffix-pattern: "yyyy_ww" # 表后缀:2024_01, 2024_02...
datetime-interval-amount: 7
datetime-interval-unit: "DAYS"
# 自动分片(推荐)
table_auto_interval:
type: AUTO_INTERVAL
props:
sharding-count: 12
datetime-lower: "2024-01-01 00:00:00"
datetime-upper: "2024-12-31 23:59:59"
sharding-seconds: 2592000 # 30天的秒数
tables:
# 操作日志表:按月分片
t_operation_log:
actualDataNodes: ds_0.t_operation_log_${202401..202412}
tableStrategy:
standard:
shardingColumn: create_time
shardingAlgorithmName: table_interval_by_month
# 订单历史表:按创建时间分片
t_order_history:
actualDataNodes: ds_${0..1}.t_order_history_${202401..202412}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_mod
tableStrategy:
standard:
shardingColumn: create_time
shardingAlgorithmName: table_auto_interval3.4.4 行表达式分片
bash
shardingAlgorithms:
# 简单分库
ds_inline:
type: INLINE
props:
algorithm-expression: ds${user_id % 2}
# 分库分表组合
table_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 4}
# 日期分表
date_inline:
type: INLINE
props:
algorithm-expression: t_log_${create_time.format('yyyyMMdd')}在下面的配置中,是基于两个数据库相同数据表的情况下的分片策略配置,其中就使用了行表达式分片
bash
databaseName: sharding_db
dataSources:
ds_0:
url: jdbc:IP:3306/sharding_db_0?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:IP:3306/sharding_db_1?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
# 分表配置示例
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# 分片算法
shardingAlgorithms:
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
# 分布式序列
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 1233.4.5 复合分片策略(多字段组合)
复合分片(Complex Sharding)是指使用多个分片键组合来决定数据路由的策略。它不是简单的取模或哈希,而是通过自定义算法,根据业务逻辑将数据分配到合适的分片。基本公式:
bash
// 复合分片决策
分片位置 = f(分片键1, 分片键2, 分片键3, ...)// 其中 f 是自定义的复合分片算法下面是一个详细的完整配置
bash
# conf/config-sharding-complex.yaml
databaseName: sharding_complex_db
rules:
- !SHARDING
shardingAlgorithms:
# 自定义复合分片算法
complex_sharding:
type: CLASS_BASED
props:
strategy: complex
algorithmClassName: com.example.ComplexOrderShardingAlgorithm
# 标准复合分片
standard_complex:
type: CLASS_BASED
props:
strategy: standard
algorithmClassName: com.example.StandardShardingAlgorithm
tables:
# 订单表:用户ID + 订单类型组合分片
t_order_complex:
actualDataNodes: ds_${0..1}.t_order_${0..7}
databaseStrategy:
complex:
shardingColumns: user_id,order_type
shardingAlgorithmName: complex_sharding
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_mod
# 商品库存表:仓库ID + 商品分类组合分片
t_inventory:
actualDataNodes: ds_${0..1}.t_inventory_${0..15}
databaseStrategy:
complex:
shardingColumns: warehouse_id,category_id
shardingAlgorithmName: complex_sharding3.4.6 Hint强制路由分片
Hint强制路由(Hint Sharding)是通过编程方式或SQL注释明确指定数据路由路径的分片策略。它绕过常规的分片算法,直接告诉ShardingSphere数据应该存放在哪个分片。其特点如下:
-
完全控制:开发人员决定数据存放位置
-
绕过算法:不依赖分片键值计算
-
灵活性强:适用于特殊业务场景
-
代码侵入:需要在代码或SQL中显式指定
bash
# conf/config-sharding-hint.yaml
databaseName: sharding_hint_db
rules:
- !SHARDING
shardingAlgorithms:
# Hint分片算法
hint_database_sharding:
type: HINT_INLINE
props:
algorithm-expression: ds_${value}
hint_table_sharding:
type: HINT_INLINE
props:
algorithm-expression: t_order_${value}
tables:
# 使用Hint分片的表
t_order_hint:
actualDataNodes: ds_${0..1}.t_order_hint_${0..3}
databaseStrategy:
hint:
shardingAlgorithmName: hint_database_sharding
tableStrategy:
hint:
shardingAlgorithmName: hint_table_sharding3.4.7 范围分片策略
范围分片是根据分片键值的范围区间将数据分配到不同分片的策略。每个分片负责处理特定范围内的数据。
-
订单、日志、监控数据等按时间顺序写入
-
按时间段(年、月、日)进行查询和分析
-
历史数据需要归档清理
bash
# conf/config-sharding-range.yaml
databaseName: sharding_range_db
rules:
- !SHARDING
shardingAlgorithms:
# 范围分片算法
table_range_by_id:
type: RANGE
props:
ranges: 0-999999=0,1000000-1999999=1,2000000-2999999=2,3000000-=3
# 按用户ID范围分片
user_range_sharding:
type: RANGE
props:
ranges: 0-9999=0,10000-49999=1,50000-99999=2,100000-199999=3,200000-=4
# 按地区分片
region_range_sharding:
type: RANGE
props:
ranges: 100000-199999=0,200000-299999=1,300000-399999=2,400000-499999=3
tables:
# 用户表:按用户ID范围分片
t_user_range:
actualDataNodes: ds_0.t_user_${0..4}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user_range_sharding
# 地区订单表:按地区编码分片
t_region_order:
actualDataNodes: ds_${0..1}.t_region_order_${0..3}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_mod
tableStrategy:
standard:
shardingColumn: region_code
shardingAlgorithmName: region_range_sharding四、写在文末
本文通过较大的篇幅详细介绍了在微服务开发场景中,ShardingSphere-Proxy这款分库分表中间件代理服务的详细使用,并通过实际案例演示了其多种分片配置规则的使用,希望对看到的同学有用,本篇到此结束,感谢观看。