Hive SerDe
一、SerDe 的核心作用
Hive 本身不直接解析数据文件(如 TextFile、JSON、Parquet),而是通过 SerDe 完成:
- 反序列化(Deserialize) :读取 HDFS 数据文件时,SerDe 把字节流 / 文本行拆分成表的字段(比如把
1,小明,lol-book拆成 id=1、name = 小明、hobby=lol-book); - 序列化(Serialize) :写入数据时,SerDe 把 Hive 表的字段数据转换成指定格式的字节流 / 文本行(比如把 id=2、name = 小红 转换成
2,小红,book-movie)。
二、Hive 常用 SerDe 类型(按场景分类)
不同数据格式对应不同的 SerDe,以下是最常用的 4 类,覆盖 90% 的场景:
| SerDe 类型 | 全类名 | 适用数据格式 |
| LazySimpleSerDe | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | Hive 默认 SerDe,分隔符文本(逗号 / 制表符 / 自定义分隔符) |
| JSONSerDe | org.apache.hive.hcatalog.data.JsonSerDe(Hive 内置) | JSON 格式(单行 JSON / 多行 JSON) |
| RegexSerDe | org.apache.hadoop.hive.serde2.RegexSerDe | 用正则表达式解析无固定分隔符的文本(如日志、固定格式字符串) |
| ParquetSerDe | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe | 适配 Parquet 文件,高效压缩,支持复杂类型,大数据场景首选 |
|---|
三、SerDe 的配置方式(创建表时指定)
SerDe 需在 CREATE TABLE 中通过 ROW FORMAT SERDE 指定,配合 SERDEPROPERTIES 配置解析规则(如分隔符、正则、JSON 映射)。
场景 1:默认 SerDe(LazySimpleSerDe)------ 分隔符文本
LazySimpleSerDe 是 Hive 默认 SerDe,无需显式指定,仅需配置分隔符:
sql
CREATE TABLE person (
id INT,
name STRING,
hobby STRING
)
ROW FORMAT DELIMITED -- 简写,底层用 LazySimpleSerDe
FIELDS TERMINATED BY ',' -- 字段分隔符:逗号
COLLECTION ITEMS TERMINATED BY '-' -- 集合元素分隔符:短横线
LINES TERMINATED BY '\n'; -- 行分隔符:换行
-- 等价于显式指定:
-- ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
-- WITH SERDEPROPERTIES (
-- 'field.delim' = ',',
-- 'collection.delim' = '-'
-- );场景 2:RegexSerDe ------ 正则解析日志
适配无固定分隔符的文本(如 Web 日志),用正则分组映射表字段:
sql
-- 解析 Web 日志的表
CREATE TABLE access_log (
ip STRING,
ident STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
-- 正则表达式:分组顺序对应表字段顺序
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*)(-|[0-9]*)",
-- 可选:输出分隔符(写入时用)
"output.format.string" = "%1$s %2$s %3$s [%4$s] \"%5$s\" %6$s %7$s"
)
STORED AS TEXTFILE;场景 3:JSONSerDe ------ 解析 JSON 数据
适配 JSON 格式的半结构化数据:
sql
CREATE TABLE json_person (
id INT,
name STRING,
hobby ARRAY<STRING>,
addr MAP<STRING,STRING>
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
-- 可选:配置 JSON 解析规则(如忽略多余字段)
WITH SERDEPROPERTIES (
"ignore.malformed.json" = "true", -- 忽略格式错误的 JSON 行
"mapping.id" = "user_id" -- 映射 JSON 中的 user_id 到表的 id 字段
)
STORED AS TEXTFILE;四、关键注意事项
- SerDe 与存储格式匹配 :
- TextFile 通常搭配 LazySimpleSerDe/RegexSerDe/JSONSerDe;
- Parquet/ORC 有专属 SerDe(如 ParquetHiveSerDe),无需手动指定(Hive 自动匹配);
- 字段顺序 / 数量匹配 :
- RegexSerDe 的正则分组数量必须和表字段数量一致(比如 7 个分组对应 7 个字段);
- JSONSerDe 的字段名(或映射名)必须和 JSON 中的 Key 匹配;
- 性能优先级 :
- 列式存储(Parquet/ORC)的 SerDe 性能远高于文本类 SerDe;
- LazySimpleSerDe 性能 > RegexSerDe(正则解析耗时更高);
Hive参数
命名规则
hive当中的参数、变量,都是以命名空间开头
通过${}方式进行引用,其中system、env下的变量必须以前缀开头。
hive 参数设置方式
**第一种方式:**修改配置文件 ${HIVE_HOME}/conf/hive-site.xml
第二种方式:启动hive cli时,通过--hiveconf key=value的方式进行设置
例如:设置打印输出的时候打印标题行
bash
[root@node4 ~]# hive --hiveconf hive.cli.print.header=true
hive> select word,count from wc_count;
OK
word count
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2第三种方式:进入cli之后,通过使用set命令设置
sql
#set查询参数
hive> set hive.cli.print.header;
hive.cli.print.header=false
#查询所有的参数
hive> set;
#set设置参数
hive> set hive.cli.print.header=true;注意:2和3两种方式设置的参数只在当前会话有效。
hive的历史操作的命令:
sql
[root@node4 ~]# ll -a
-rw-r--r-- 1 root root 11590 11月 19 11:07 .hivehistory
# 在当前用户的家目录/root下有一个.hivehistory文件,该文件记录了执行的hive命令:
[root@node4 ~]# vim .hivehistoryhive参数的初始化配置:
在当前用户的家目录的.hivercwen文件,如果没有可以创建一个,添加想要初始化的参数配置:
sql
[root@node4 ~]# vim .hiverc
set hive.cli.print.header=true;Hive视图、公共表达式、索引
视图
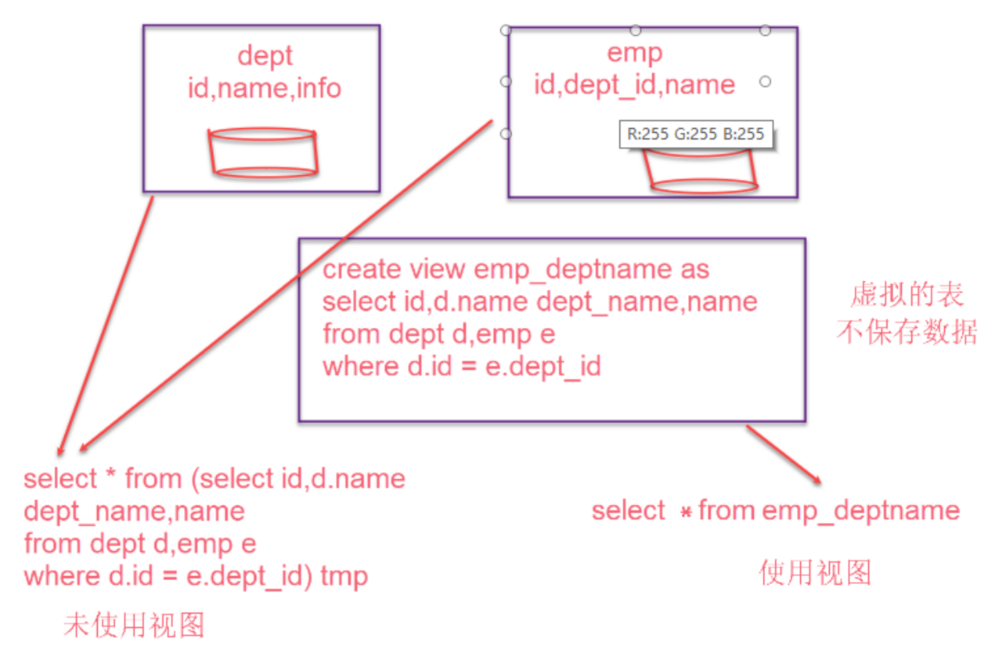
和关系型数据库中的普通视图一样,hive也支持视图
特点:
- 不支持物化视图
- 只能查询,不能做加载数据操作
- 视图的创建,只是保存一份元数据,查询视图时才执行对应的子查询
- view定义中若包含了ORDER BY/LIMIT语句,当查询视图时也进行ORDER BY/LIMIT语句操作,view当中定义的优先级更高
- view支持迭代视图
语法:
sql
-- 创建视图
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name
[(column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ... ;
--示例
create view v_psn as select * from person order by id desc;
-- 删除视图
DROP VIEW [IF EXISTS] [db_name.]view_name;
--示例
drop view v_psn;公共表达式(CTE,推荐写法)
CTE 是通过 WITH 子句定义的临时查询结果集,仅在当前 SQL 语句中有效,执行完后自动销毁,相当于 "一次性的临时表",但比临时表更轻量、更易维护。
基础语法
sql
WITH cte_name1 AS (
-- 第一个 CTE 的查询逻辑
SELECT 列1, 列2 FROM 表 WHERE 条件
),
cte_name2 AS (
-- 第二个 CTE(可引用前面的 CTE)
SELECT 列3, 列4 FROM cte_name1 WHERE 条件
)
-- 主查询:引用 CTE
SELECT * FROM cte_name2;递归 CTE
递归 CTE 是一种能自己调用自己的查询,专门用来处理有层级关系的数据,比如:
- 公司的部门树(总公司 → 分公司 → 部门 → 小组)
- 论坛的评论楼(主评论 → 一级回复 → 二级回复)
- 家谱关系(爷爷 → 爸爸 → 你 → 孩子)
它的核心结构分为两部分:
- 锚点成员(Anchor Member):查询的 "起点",用来获取层级的根节点。
- 递归成员(Recursive Member):查询的 "循环体",用当前结果去关联原表,获取下一层节点,直到没有新数据为止。
示例:用 "部门树" 例子一步步拆解
假设我们有一张部门表 dept:
| dept_id | dept_name | parent_id |
|---|---|---|
| 1 | 总公司 | 0 |
| 2 | 北京分公司 | 1 |
| 3 | 技术部 | 2 |
| 4 | 产品部 | 2 |
| 5 | 上海分公司 | 1 |
| 6 | 运营部 | 5 |
我们的目标是用递归 CTE 把这棵树的层级关系查出来。
第一步:锚点成员(找根节点)
sql
SELECT dept_id, dept_name, parent_id, 1 AS level
FROM dept
WHERE parent_id = 0- 这里
parent_id = 0表示根节点(总公司)。 - 我们给根节点的层级
level设为1。 - 结果:只有
总公司这一行。
第二步:递归成员(找子节点)
sql
SELECT d.dept_id, d.dept_name, d.parent_id, dt.level + 1 AS level
FROM dept d
JOIN dept_tree dt ON d.parent_id = dt.dept_id- 这是递归的核心:我们把上一步得到的临时结果
dept_tree(当前层级)和原表dept关联,找到所有parent_id等于当前dept_id的子节点。 - 子节点的层级是父节点层级 + 1(比如总公司是
1,它的子节点北京分公司就是2)。 - 第一次递归:用根节点
总公司(dept_id=1)找到子节点北京分公司和上海分公司(层级2)。 - 第二次递归:用
北京分公司(dept_id=2)找到子节点技术部、产品部(层级3);用上海分公司(dept_id=5)找到子节点运营部(层级3)。 - 第三次递归:子节点
技术部、产品部、运营部没有子节点了,递归结束。
第三步:组合起来
把锚点成员和递归成员用 UNION ALL 连接,就构成了完整的递归 CTE:
sql
WITH RECURSIVE dept_tree AS (
-- 锚点成员:根节点
SELECT dept_id, dept_name, parent_id, 1 AS level
FROM dept
WHERE parent_id = 0
UNION ALL
-- 递归成员:找子节点
SELECT d.dept_id, d.dept_name, d.parent_id, dt.level + 1 AS level
FROM dept d
JOIN dept_tree dt ON d.parent_id = dt.dept_id
)
SELECT * FROM dept_tree;递归 CTE 的执行流程
- 先执行锚点成员,得到根节点结果集,作为第一次递归的输入。
- 执行递归成员,用输入结果集关联原表,得到子节点结果集。
- 把递归成员的结果集作为新的输入,再次执行递归成员。
- 重复步骤 2-3,直到递归成员不再返回新的结果集,递归结束。
- 最后用
UNION ALL把所有结果集合并,得到最终的层级关系。
索引
索引在Hive 3.0+ 已弃用。Hive 官方推荐使用 分区(Partitioning) 、分桶(Bucketing) 或 列式存储(ORC/Parquet) 替代索引。
Hive运行方式
命令行方式cli (控制台模式,了解即可)
与hdfs交互:
sql
hive> dfs -ls /; Found 7 items
Found 5 items
drwxr-xr-x - root supergroup 0 2026-01-17 04:53 /fof
drwx------ - root supergroup 0 2026-01-18 11:29 /tmp
drwxr-xr-x - root supergroup 0 2026-01-18 14:52 /user
drwxr-xr-x - root supergroup 0 2026-01-16 17:22 /weather
drwxr-xr-x - root supergroup 0 2026-01-15 13:57 /wordcount
hive> dfs -cat /user/hive_remote/warehouse/psnbucket/000000_0;
8,scala,88
4,hive,44与 Linux 交互:!开头
sql
!pwd;
!ls /root;脚本运行方式(实际生成环境中更为常用)
sql
[root@node4 ~]# hive --service cli --help usage: hive
-d,--define <key=value> Variable substitution to apply to Hive 定义变量commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line 执行后面跟着的sql语句
-f <filename> SQL from files 执行指定文件中的sql语句
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable substitution to apply to Hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file 执行初始化的sql文件
-S,--silent Silent mode in interactive shell 静默模式(不显示Ok和Time taken信息)
-v,--verbose Verbose mode (echo executed SQL to the console)示例:
sql
[root@node4 ~]# hive -e "select * from person"
person.id person.name person.likes person.address
1 小明1 ["lol","book","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
2 小明2 ["lol","book","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
3 小明3 ["lol","book","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
4 小明4 ["lol","book","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
5 小明5 ["lol","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
6 小明6 ["lol","book","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
7 小明7 ["lol","book"] {"beijing":"xisanqi","shanghai":"pudong"}
8 小明8 ["lol","book"] {"beijing":"xisanqi","shanghai":"pudong"}
9 小明9 ["lol","book","movie"] {"beijing":"xisanqi","shanghai":"pudong"}
#将查询结果写入到指定的文件中
[root@node4 ~]# hive -e "select * from person" >he.log
#查看写入后的文件
[root@node4 ~]# cat he.loghive脚本: ./脚本名称
sql
[root@node4 ~]# vim hive.sh
hive -e "select * from person"
[root@node4 ~]# chmod +x hive.sh [root@node4 ~]# ./hive.shhive -f file:执行后还在linux命令行
sql
[root@node4 ~]# vim hivef.sql select * from person
[root@node4 ~]# hive -f hivef.sqlhive -i init.sql:执行后进入hive客户端
sql
[root@node4 ~]# hive -i init.sql在hive cli中运行一个sql脚本:
sql
hive> source hivef.sql;Hive优化
Fetch 抓取
Fetch抓取是指Hive在对某些查询操作可以不必使用MapReduce计算,只需要读取指定表对应存储目下的文件,然后输出查询结果到控制台即可。
在hive-default.xml.template文件中hive.fetch.task.conversion,默认值是more。
set hive.fetch.task.conversion=none/minimal/more(默认值);
默认做了优化,以下两种情况都不经过mr,改为 none后,将走mr。
以下SQL不会转为Mapreduce来执行
-
select仅查询本表字段
-
where仅对本表字段做条件过滤
-
使用limit
本地运行模式
开发和测试阶段使用本地模式,优点快,缺点是http://node3:8088/cluster看不到。对于小数据集hive通过本地模式在单机上处理任务,执行时间可以明显被缩短。
sql
# 开启本地模式,默认为false
hive> set hive.exec.mode.local.auto=true;设置local mr 的最大输入数据量,当输入数据量小于这个值是采用local mr的方式,默认134217728也就是128M。若大于该配置仍会以集群方式来运行!
hive.exec.mode.local.auto.inputbytes.max=134217728
设置local mr 的最大输入文件个数,当输入文件个数小于这个值是采用local mr方式
hive.exec.mode.local.auto.input.files.max=4 #默认4
并行模式
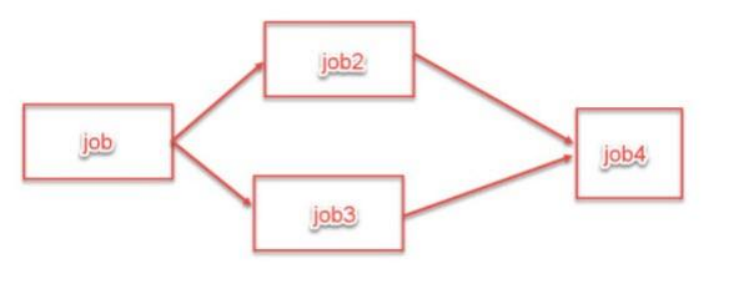
sql
# 修改为并行执行,默认为false
hive>set hive.exec.parallel=true;
hive> set hive.exec.parallel.thread.number;
hive.exec.parallel.thread.number=8
#并行进程默认是8个进程同时进行。严格与非严格模式
| 模式 | 适用场景 |
| 严格模式 | 生产环境(强制规范查询写法,避免误操作导致集群资源耗尽、查询超时) |
| 非严格模式(默认) | 测试 / 开发环境(灵活调试查询,无需严格遵守过滤规则,提升开发效率) |
|---|
严格模式的核心限制
- 限制分区表的全表扫描
- 规则 :查询分区表时,
WHERE子句必须包含分区列的过滤条件,否则直接报错。
- 限制 ORDER BY 不加 LIMIT
- 规则 :
ORDER BY必须配合LIMIT使用,否则报错。
- 限制笛卡尔积查询
- 规则 :两个表关联时,必须指定
JOIN条件,禁止隐式笛卡尔积。
sql
hive> set hive.mapred.mode=strict;#严格模式
hive> set hive.mapred.mode=nostrict;#非严格模式行列过滤
行列过滤也被称为分区剪裁和列裁剪。
尽可能早的过滤掉尽可能多的数据,避免大量数据流入外层sql
行过滤
- a. 分区在hive上本质是目录,分区剪裁可以高效的过滤掉大部分数据。
- b. 尽量使用分区剪裁。
- c. where条件过滤
列过滤(列裁剪)
- a.只获取需要的列的数据,减少数据输出。
- b.少用select *
JVM 重用
为什么需要 JVM 重用?
Hive 执行 MapReduce 任务时,默认会为每个 Map/Reduce 任务启动一个独立的 JVM 进程:
- 问题:创建和销毁 JVM 进程会消耗大量系统资源(CPU / 内存),尤其是当任务包含大量小 Map/Reduce 任务时(比如查询小文件多的表),JVM 启停开销会成为性能瓶颈。
- 解决思路 :JVM 重用允许一个 JVM 进程重复执行多个 Map/Reduce 任务,避免频繁启停,降低资源开销。
核心逻辑
启用 JVM 重用后,一个 JVM 进程会被分配一个 "任务池",执行完一个任务后不销毁,而是继续执行池中的下一个任务,直到达到最大重用次数或任务池为空,才销毁 JVM。
适用场景
- 小文件多的场景:查询包含大量小文件的表时,会生成大量小 Map 任务,JVM 重用能大幅减少启停开销;
- 短任务密集的场景:如简单的过滤、聚合查询,任务执行时间短,JVM 启停占比高;
- 集群资源充足的场景:JVM 重用会占用更多内存(JVM 进程不销毁),需确保集群有足够内存。
配置方式
sql
-- 开启 JVM 重用(默认 false)
set mapred.job.reuse.jvm.num.tasks = 10; -- 一个 JVM 最多重用 10 次
-- 可选:设置 JVM 等待下一个任务的超时时间(默认 10000 毫秒)
set mapred.job.reuse.jvm.waitmillis = 20000;全局级配置(修改 mapred-site.xml,重启集群生效)
sql
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>10</value>
<description>每个 JVM 最多重用的任务数</description>
</property>
<property>
<name>mapred.job.reuse.jvm.waitmillis</name>
<value>20000</value>
<description>JVM 等待下一个任务的超时时间</description>
</property>推测执行
为什么需要推测执行?
Hive 执行一个查询会拆分成多个 Map/Reduce 任务,这些任务理论上并行执行且耗时相近。但在实际集群中,可能因为以下原因出现慢任务:
- 某台节点的 CPU / 内存 / 磁盘 IO 资源被抢占;
- 节点网络波动,数据传输慢;
- 任务分配到的数据分片不均匀(比如个别分片数据量极大)。
这些慢任务会成为整个 Job 的 "瓶颈"------ 即使其他 99% 的任务都完成了,Job 也必须等待最后 1% 的慢任务结束。
推测执行的工作流程
- 任务监控:集群会监控所有并行任务的执行进度和耗时;
- 慢任务判定:当大部分任务(比如 90%)已经完成,剩下的少数任务耗时远超平均耗时(比如超过 1.5 倍平均耗时),则判定这些任务为 "慢任务";
- 启动备份任务 :为慢任务启动一个备份任务,与原任务并行执行;
- 结果抢占:哪个任务先执行完成,就将其结果作为最终结果,并立即终止另一个未完成的任务;
- 结果合并:采用成功任务的结果,继续推进整个 Job。
配置
sql
set hive.mapred.reduce.tasks.speculative.execution=true;#开启推测执行表优化
小表与大表join
Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。所以有Map side join针对小表与大表join进行优化。两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多 份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
实现方式:
1、SQL方式,在SQL语句中添加MapJoin标记(mapjoin hint)
sql
SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value
FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key;2、开启自动的MapJoin
hive.ignore.mapjoin.hint;默认为true,如果自动和手动冲突了,手动的配置失效,以自动配置为准。
sql
hive> set hive.ignore.mapjoin.hint;
hive.ignore.mapjoin.hint=true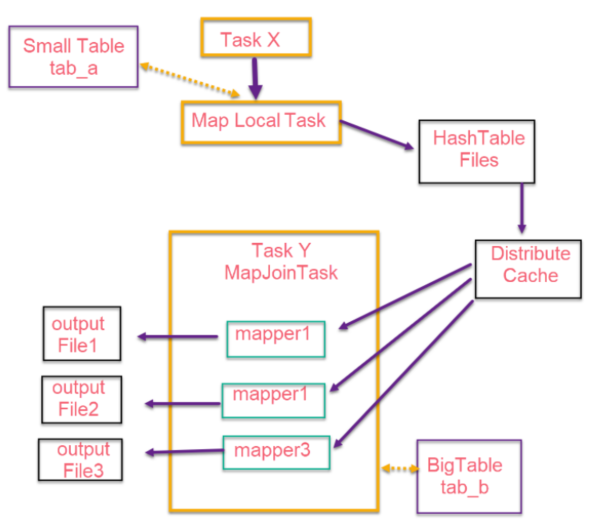
相关配置参数:
- hive.mapjoin.smalltable.filesize; #默认25M
(大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行)
- hive.ignore.mapjoin.hint;
(默认值:true;是否忽略mapjoin hint 即mapjoin标记)
- hive.auto.convert.join.noconditionaltask;
(默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin)
- hive.auto.convert.join.noconditionaltask.size;
(将多个mapjoin转化为一个mapjoin时,其表的最大值)
扩展 :hive.groupby.skewindata 避免数据倾斜。是 Hive 针对 GROUP BY 语句数据倾斜的专项优化开关。 当开启该参数时,Hive 会将原本的 "1 轮 MapReduce" 的 GROUP BY 拆成 2 轮MapReduce ,打散倾斜的 Key,避免单个 Reduce 任务处理过多数据;比如:按 gender分组,若 "男" 的记录有 1 亿条,"女" 只有 100 万条 → 处理 "男" 的 Reduce 卡死,其他 Reduce 很快完成。此时落开启则原本 1 个 Reduce 处理 1 亿条 "男" 的数据,变成 10 个 Reduce 各处理 1000 万条,再汇总,彻底解决倾斜。
大表join大表
- 空key过滤:
(1) 有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer
上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数
是异常数据,我们需要在SQL语句中进行过滤。最终目的是reduce负载均衡,防止数据倾斜。不过一般在ETL数据清洗时便会对空值进行处理(过滤掉或者赋值)。
- 空key转换:
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果
中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的
reducer上。
Map-Side 聚合
相当用combiner。
-
默认情况下,Map阶段相同key发送到一个reduce,当某个key的数据过大时就会发生数据倾斜。
-
并不是所有的聚合都需要再reduce端完成,可以先在map端进行聚合,最后再在reduce端聚合。 如同combiner。
-
通过设置以下参数开启在Map端的聚合
#开启map端的聚合
set hive.map.aggr=true;
#相关参数:
hive.groupby.mapaggr.checkinterval;
map端group by执行聚合时处理的多少行数据(默认:100000)
hive.map.aggr.hash.min.reduction;
进行聚合的最小比例(预先对100000条数据做聚合,这100000条数据的体积若聚合之后的数据量/聚合
前的值大于该配置0.5,则不会聚合)
hive.map.aggr.hash.percentmemory;
map端聚合使用的内存的最大值
hive.map.aggr.hash.force.flush.memory.threshold;
map端做聚合操作是hash表的最大可用内存,大于该值则会触发flush
hive.groupby.skewindata
是否对GroupBy产生的数据倾斜做优化,默认为false
去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换。
每个reduce任务处理的数据量,默认值256MB
set hive.exec.reducers.bytes.per.reducer=256000000
sql
select count(distinct imei) from jizhan;
#转换为
Select count(imei) from (select imei from jizhan group by imei) tmp虽然会多一个Job来完成,但在数据量大的情况下,这个绝对值得。
合理设置 Map 与 Reduce 数量
合理设置Map数
通常情况下,作业会通过计算split切片的数量决定产生对应个数map任务。 主要决定因素:input的文件总个数,input的文件大小,集群设置的文件块大小。block块,split_size, 文件个数 split切片数量决定map task数量。
思考一:是不是 map 数越多越好?
答:不是。如果一个任务有很多小文件,则每个小文件都会被当成一个split切片,用一个map任务来完成,执行真实业务逻辑运算的时间远远小于map任务的启动和初始化的时间,就会造成很大的资源浪费。另外,同时可执行的map数也是受限的。如何优化,答案是减少map的数量,比如通过合并小文件减少map数量。
思考二:是不是保证每个 map 处理接近 128M 的文件块,就高枕无忧了?
答:不一定,比如一个128MB(或者接近该值)的文件,默认情况会用一个map去完成,但是这个文件可能只有很少的小字段,却又几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定比较耗时。如何解决?答案是增加map的个数。
合理设置 Reduce 数
reduce个数并不是越多越好,过多的启动和初始化reduce也会消耗时间和资源;另外过多的
reduce会生成很多个结果文件,同样产生了小文件的问题。