默认前进,ai控制转头,左转和右转
有看到门的面积奖励+1/+2/+3 和时间惩罚-1和终点奖励+500
体感是有学到东西的,但是因为门口有一些卡死点,所以效果可能一般
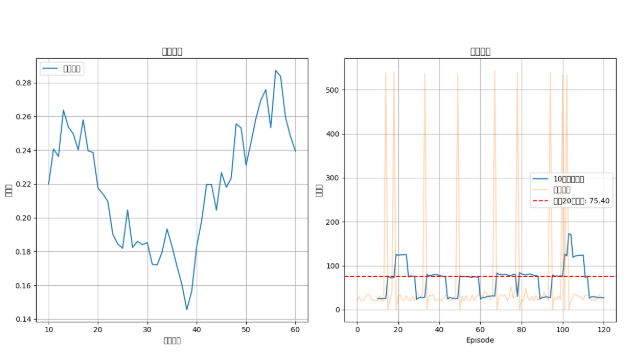
整体训练状态分析
-
训练稳定性 :训练过程存在较大波动,奖励不稳定
-
学习效果 :智能体已经能够在某些回合成功完成任务(获得高奖励)
-
平均表现 :最近20轮的平均奖励为75.46,说明智能体有一定的表现能力
-
探索与利用 :策略熵值的波动表明智能体在不断调整探索与利用的平衡
import os
import sys
import time
import logging
import queue
import threading
from collections import deque
import numpy as np
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
from ultralytics import YOLO
import pyautogui
from pathlib import Path
import json
import hashlib
import sys
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('Agg') # 使用非交互式后端,避免GUI问题设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
from control_api_tool import ImprovedMovementController # 导入移动控制器可视化功能已禁用
配置日志
def setup_logging():
"""设置日志配置"""
logger = logging.getLogger('ppo_agent_logger')log_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "logs") if not os.path.exists(log_dir): os.makedirs(log_dir) log_filename = os.path.join(log_dir, f"gate_find_ppo_{time.strftime('%Y%m%d_%H%M%S')}.log") logger.setLevel(logging.INFO) # 清除已有的处理器,避免重复 logger.handlers.clear() # 创建文件处理器 file_handler = logging.FileHandler(log_filename, encoding='utf-8') file_handler.setLevel(logging.INFO) # 创建控制台处理器 console_handler = logging.StreamHandler() console_handler.setLevel(logging.INFO) # 创建格式器 formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s') file_handler.setFormatter(formatter) console_handler.setFormatter(formatter) # 添加处理器到logger logger.addHandler(file_handler) logger.addHandler(console_handler) return logger配置参数
CONFIG = {
'IMAGE_WIDTH': 640,
'IMAGE_HEIGHT': 480,'ENV_MAX_STEPS': 20, 'LEARNING_RATE': 0.001, # 提高学习率 'GAMMA': 0.99, 'K_EPOCHS': 10, # 增加更新轮数 'EPS_CLIP': 0.2, 'TARGET_DESCRIPTION': 'gate', 'DETECTION_CONFIDENCE': 0.75, # 修改:提高检测置信度到0.9 'MIN_GATE_AREA': 10000, 'CENTER_THRESHOLD': 0.1, 'BASE_COMPLETION_REWARD': 250, 'QUICK_COMPLETION_BONUS_FACTOR': 8, 'CLIMB_CONFIDENCE_THRESHOLD': 0.85, 'USE_SLAM_MAP': False,}
class Memory:
"""
智能体的记忆存储类
"""
def init(self):
self.states = []
self.turn_actions = []
self.logprobs = []
self.rewards = []
self.is_terminals = []
self.action_params = []def clear_memory(self): del self.states[:] del self.turn_actions[:] del self.logprobs[:] del self.rewards[:] del self.is_terminals[:] del self.action_params[:] def append(self, state, turn_action, logprob, reward, is_terminal, action_param=None): self.states.append(state) self.turn_actions.append(turn_action) self.logprobs.append(logprob) self.rewards.append(reward) self.is_terminals.append(is_terminal) if action_param is not None: self.action_params.append(action_param)class TargetSearchEnvironment:
"""
目标搜索环境 - 仅使用YOLO检测
"""
def init(self, target_description="gate"):
self.target_description = target_description
self.step_count = 0
self.max_steps = CONFIG['ENV_MAX_STEPS']
self.last_detection_result = None
self.last_area = 0
self.logger = setup_logging()# 移动控制器 - 实际游戏控制 self.movement_controller = ImprovedMovementController() # 添加存储最近检测图像的队列 self.recent_detection_images = deque(maxlen=5) # 添加用于检查图像变化的变量 self.previous_image_hash = None self.image_change_counter = 0 self.total_image_checks = 0 # 面积历史(用于计算距离变化趋势) self.area_history = deque(maxlen=3) # 记录最近3步的目标面积 self.yolo_model = self._load_yolo_model() self._warm_up_detection_model() # 成功条件阈值 self.MIN_GATE_AREA = CONFIG['MIN_GATE_AREA'] self.CENTER_THRESHOLD = CONFIG['CENTER_THRESHOLD'] # 动作历史记录 self.action_history = deque(maxlen=10) # 可视化相关 self.visualizer = None self.visualizer_thread = None def _load_yolo_model(self): """ 加载YOLO模型 """ current_dir = Path(__file__).parent model_path = current_dir.parent / "models" / "find_gate.pt" if not model_path.exists(): self.logger.error(f"YOLO模型文件不存在: {model_path}") return None try: model = YOLO(str(model_path)) self.logger.info(f"成功加载YOLO模型: {model_path}") return model except Exception as e: self.logger.error(f"加载YOLO模型失败: {e}") return None def _warm_up_detection_model(self): """ 预热检测模型 """ self.logger.info("正在预热检测模型,确保模型已加载...") try: dummy_image = self.capture_screen() if dummy_image is not None and dummy_image.size > 0: dummy_result = self.detect_target(dummy_image) self.logger.info("检测模型已预热完成") else: self.logger.warning("无法获取初始截图进行模型预热") except Exception as e: self.logger.warning(f"模型预热过程中出现错误: {e}") def capture_screen(self): """ 截取当前屏幕画面 """ try: project_root = Path(__file__).parent.parent sys.path.insert(0, str(project_root)) from computer_cline.prtsc import capture_window_by_title result = capture_window_by_title("Sifu", "sifu_window_capture.png") if result: screenshot = Image.open("sifu_window_capture.png") screenshot = np.array(screenshot) screenshot = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR) # 检查图像是否与上一帧相同 current_hash = hashlib.md5(screenshot.tobytes()).hexdigest() if self.previous_image_hash is not None: self.total_image_checks += 1 if current_hash != self.previous_image_hash: self.image_change_counter += 1 self.previous_image_hash = current_hash return screenshot else: self.logger.warning("未找到包含 'sifu' 的窗口,使用全屏截图") screenshot = pyautogui.screenshot() screenshot = np.array(screenshot) screenshot = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR) # 检查图像是否与上一帧相同 current_hash = hashlib.md5(screenshot.tobytes()).hexdigest() if self.previous_image_hash is not None: self.total_image_checks += 1 if current_hash != self.previous_image_hash: self.image_change_counter += 1 self.previous_image_hash = current_hash return screenshot except ImportError: self.logger.warning("截图功能不可用,使用模拟图片") # 使用配置文件中的图像尺寸 sim_img = np.zeros((CONFIG['IMAGE_HEIGHT'], CONFIG['IMAGE_WIDTH'], 3), dtype=np.uint8) # 检查图像是否与上一帧相同 current_hash = hashlib.md5(sim_img.tobytes()).hexdigest() if self.previous_image_hash is not None: self.total_image_checks += 1 if current_hash != self.previous_image_hash: self.image_change_counter += 1 self.previous_image_hash = current_hash return sim_img except: # 如果没有Image模块,使用纯numpy数组 sim_img = np.zeros((CONFIG['IMAGE_HEIGHT'], CONFIG['IMAGE_WIDTH'], 3), dtype=np.uint8) current_hash = hashlib.md5(sim_img.tobytes()).hexdigest() if self.previous_image_hash is not None: self.total_image_checks += 1 if current_hash != self.previous_image_hash: self.image_change_counter += 1 self.previous_image_hash = current_hash return sim_img def detect_target(self, image): """ 使用YOLO检测目标 """ if self.yolo_model is None: self.logger.error("YOLO模型未加载,无法进行检测") return [] try: conf_threshold = CONFIG.get('DETECTION_CONFIDENCE', 0.9) # 修改:默认值改为0.9 self.logger.debug(f"YOLO检测开始,置信度阈值: {conf_threshold}") results = self.yolo_model.predict( source=image, conf=conf_threshold, save=False, verbose=False ) detections = [] result = results[0] if result.boxes is not None and len(result.boxes) > 0: boxes = result.boxes.xyxy.cpu().numpy() confs = result.boxes.conf.cpu().numpy() cls_ids = result.boxes.cls.cpu().numpy() names = result.names if hasattr(result, 'names') else {} for box, conf, cls_id in zip(boxes, confs, cls_ids): x1, y1, x2, y2 = box width = x2 - x1 height = y2 - y1 class_name = names.get(int(cls_id), f"class_{int(cls_id)}") detections.append({ 'bbox': [x1, y1, x2, y2], 'label': class_name, 'score': conf, 'width': width, 'height': height }) self.logger.debug(f"YOLO检测到 {len(detections)} 个目标") return detections except Exception as e: self.logger.error(f"YOLO检测过程中出错: {e}") return [] def _check_climb_conditions(self, detection_results): """ 检查climb检测结果是否满足条件 """ confidence_threshold = CONFIG.get('CLIMB_CONFIDENCE_THRESHOLD', 0.85) if not detection_results: return False # 筛选出所有climb检测结果 climb_detections = [ detection for detection in detection_results if ( detection['label'].lower() == 'climb' or 'climb' in detection['label'].lower() ) ] if not climb_detections: return False # 如果只有一个climb检测,要求其置信度超过阈值 if len(climb_detections) == 1: return climb_detections[0]['score'] >= confidence_threshold # 如果有多个climb检测,要求至少一个置信度超过阈值 return any(detection['score'] >= confidence_threshold for detection in climb_detections) def calculate_reward(self, detection_results, last_area, move_action, turn_action): """ 计算综合奖励 - 简化版 包含:时间惩罚、门检测奖励(看到门就给2分)、前进奖励和完成奖励 """ # 获取当前最大检测面积 current_area = self._get_max_detection_area(detection_results) if detection_results else 0 # 奖励参数 STEP_PENALTY = -1.0 # 时间惩罚:-1分/步 SUCCESS_REWARD = 500.0 # 完成奖励 GATE_REWARD = 2.0 # 看到门就给2分 FORWARD_REWARD = 2.0 # 前进动作奖励 STAY_PENALTY = -1.0 # 不动动作惩罚 # 1. 时间惩罚 step_penalty = STEP_PENALTY # 2. 移动动作奖励 move_reward = FORWARD_REWARD if move_action == 0 else STAY_PENALTY # 3. 门检测奖励 - 看到门就给2分 gate_reward = 0.0 success_bonus = 0.0 # 检查YOLO检测是否成功 if detection_results: # 检查是否检测到门 gate_detected = any(detection['label'].lower() == 'gate' or 'gate' in detection['label'].lower() for detection in detection_results) # 看到门就给2分 if gate_detected: gate_reward = GATE_REWARD self.logger.info(f"检测到门,奖励: {gate_reward:.2f}") else: gate_reward = 0.0 # 4. 完成奖励 if self._check_climb_conditions(detection_results): success_bonus = SUCCESS_REWARD # 计算总奖励 total_reward = step_penalty + move_reward + gate_reward + success_bonus self.logger.info(f"奖励分解 - 时间: {step_penalty:.2f}, 门: {gate_reward:.2f}, 完成: {success_bonus:.2f}, 总计: {total_reward:.2f}") return total_reward, current_area def _calculate_center_reward(self, detection_results, reward_weight): """ 计算朝向中心的奖励 目标越靠近画面中心,奖励越高 避免了"距离近但没看向目标"的问题 """ if not detection_results: return -5.0 # 未检测到目标的小惩罚 img_width = CONFIG['IMAGE_WIDTH'] img_height = CONFIG['IMAGE_HEIGHT'] center_x = img_width / 2 center_y = img_height / 2 # 计算所有检测框的中心点 center_rewards = [] for det in detection_results: x1, y1, x2, y2 = det['bbox'] det_center_x = (x1 + x2) / 2 det_center_y = (y1 + y2) / 2 # 计算与画面中心的归一化距离(0~1) dist_x = abs(det_center_x - center_x) / (img_width / 2) dist_y = abs(det_center_y - center_y) / (img_height / 2) dist_avg = (dist_x + dist_y) / 2 # 距离中心越近,奖励越高(距离为0时奖励最大) center_reward = reward_weight * (1.0 - dist_avg) center_rewards.append(center_reward) # 取最大朝向中心奖励 return max(center_rewards) if center_rewards else -5.0 def _calculate_repetition_penalty(self, turn_action): """ 重复动作惩罚 - 只考虑转头动作 特别关注转头动作,避免"转到零"的视角混乱问题 """ if len(self.action_history) < 3: return 0.0 recent_actions = list(self.action_history)[-3:] same_action_count = sum(1 for act in recent_actions if act[1] == turn_action) # 只比较转头动作 # 检查是否是重复的转头动作 turn_only = True # 所有动作都只是转头 if turn_only: # 纯转头动作,检查是否在来回转头(左-右-左-右) if len(recent_actions) >= 3: recent_turns = [act[1] for act in recent_actions[-3:]] # 获取最近的转头动作 # 如果转头动作模式是 0-1-0 或 1-0-1(左右来回) if recent_turns == [0, 1, 0] or recent_turns == [1, 0, 1]: return -80.0 # 严重惩罚左右来回转头 # 连续相同转头动作的惩罚 if same_action_count >= 3: return -100.0 # 严重惩罚连续3次相同转头 elif same_action_count >= 2: return -50.0 # 中等惩罚连续2次相同转头 else: return -10.0 # 轻微惩罚纯转头(鼓励结合移动) else: # 移动动作的惩罚 if same_action_count >= 3: return -50.0 # 严重惩罚连续3次相同移动 elif same_action_count >= 2: return -20.0 # 中等惩罚连续2次相同移动 else: return 0.0 # 不惩罚 def _get_max_detection_area(self, detection_results): """ 获取检测结果中的最大面积 """ if not detection_results: return 0 return max([det['width'] * det['height'] for det in detection_results]) def step(self, move_action, turn_action, move_duration=0.5, turn_angle=30): """ 执行动作并返回新的状态、奖励和是否结束 执行移动动作和转头动作 """ move_action_names = ["前进", "不动"] turn_action_names = ["左转", "右转"] self.logger.debug(f"执行动作: 移动-{move_action_names[move_action]}, 转头-{turn_action_names[turn_action]}, 移动时间: {abs(move_duration)}, 转头角度: {turn_angle}") # 执行动作前先检查当前状态 pre_action_state = self.capture_screen() pre_action_detections = self.detect_target(pre_action_state) # 检查当前状态是否有符合条件的climb类别 pre_climb_detected = self._check_climb_conditions(pre_action_detections) if pre_climb_detected: self.logger.info(f"动作执行前已检测到符合条件的climb类别,立即终止") self.reset_to_origin() return pre_action_state, 0, True, pre_action_detections # 执行移动动作 if move_action == 0: # 前进 self.movement_controller.move_forward(duration=abs(move_duration)) # 移动动作1: 不动,不执行任何操作 # 执行转头动作 if turn_action == 0: # 左转 self.movement_controller.turn_left(angle=turn_angle) elif turn_action == 1: # 右转 self.movement_controller.turn_right(angle=turn_angle) # 获取新状态 new_state = self.capture_screen() detection_results = self.detect_target(new_state) # 检查是否检测到符合条件的climb climb_detected = self._check_climb_conditions(detection_results) # 计算奖励 reward, new_area = self.calculate_reward(detection_results, self.last_area, move_action, turn_action) # 更新步数 self.step_count += 1 # 检查是否到达最大步数 done = self.step_count >= self.max_steps or climb_detected # 更新最后检测结果和面积 self.last_detection_result = detection_results self.last_area = new_area # 修改:现在在计算完奖励后才输出日志 self.logger.info(f"S {self.step_count}, A: {new_area:.2f}, R: {reward:.2f}") # 更新动作历史 self.action_history.append((0, turn_action)) # move_action设为0 # 修改:只有在达到最大步数时才重置,避免重复重置 if done and not climb_detected: # 如果不是因为climb而结束,也要重置 self.logger.info(f"达到最大步数 {self.max_steps}") # 在episode结束时重置游戏环境 self.reset_to_origin() return new_state, reward, done, detection_results def reset_to_origin(self): """ 重置到原点 """ # 按键操作序列 pyautogui.press('esc') time.sleep(0.2) pyautogui.press('q') time.sleep(0.2) pyautogui.press('enter') time.sleep(0.2) pyautogui.press('enter') time.sleep(0.2) # 检测门是否存在 gate_detected = False while not gate_detected: new_state = self.capture_screen() detection_results = self.detect_target(new_state) self.logger.info(f"检测到 {len(detection_results)} 个目标") for i, detection in enumerate(detection_results): self.logger.info(f" 目标 {i+1}: {detection['label']}, 置信度: {detection['score']:.2f}") for detection in detection_results: if detection['label'].lower() == 'gate' or 'gate' in detection['label'].lower(): gate_detected = True self.logger.info(f"成功检测到门!准备进入...") time.sleep(0.2) pyautogui.press('enter') time.sleep(0.3) pyautogui.press('enter') break if not gate_detected: self.logger.info(f"未检测到门,等待1秒后按回车重新检测...") time.sleep(1) pyautogui.press('enter') time.sleep(0.2) # 最后再按一次回车 pyautogui.press('enter') time.sleep(0.2) pyautogui.press('enter') time.sleep(0.2) # 重置环境内部状态 self.step_count = 0 self.last_area = 0 self.last_detection_result = None self.action_history.clear() self.logger.info("重置到原点操作完成") def reset(self): """ 重置环境 """ self.step_count = 0 self.last_area = 0 self.last_detection_result = None self.action_history.clear() # 获取初始状态 initial_state = self.capture_screen() self.last_detection_result = self.detect_target(initial_state) self.last_area = self._get_max_detection_area(self.last_detection_result) if self.last_detection_result else 0 return initial_state def get_recent_detection_images(self): """ 获取最近的检测图像 """ return list(self.recent_detection_images) def start_visualizer(self): """ 启动可视化(已禁用) """ print("Visualization is disabled.")class PolicyNetwork(nn.Module):
"""
策略网络 - 修改版,只输出转头动作
"""
def init(self, state_dim, turn_action_dim):
super(PolicyNetwork, self).init()# 更深的卷积特征提取器 self.conv_layers = nn.Sequential( nn.Conv2d(3, 32, kernel_size=8, stride=4, padding=1), nn.BatchNorm2d(32), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU(), nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(128), nn.ReLU(), nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(256), nn.ReLU(), ) # 使用全局平均池化自适应处理不同输入尺寸 self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # 全连接层 - 256个通道 self.fc_shared = nn.Sequential( nn.Linear(256, 512), nn.ReLU(), nn.Dropout(0.3), nn.Linear(512, 512), nn.ReLU(), nn.Dropout(0.2) ) # 转头动作策略头 self.turn_policy = nn.Sequential( nn.Linear(512, 256), nn.ReLU(), nn.Linear(256, turn_action_dim) ) # 价值函数头 self.value_head = nn.Sequential( nn.Linear(512, 256), nn.ReLU(), nn.Linear(256, 1) ) def forward(self, x): # 归一化输入 x = x / 255.0 # 调试:检查输入统计信息 if hasattr(self, 'input_mean'): self.input_mean = x.mean().item() self.input_std = x.std().item() conv_features = self.conv_layers(x) # 卷积特征提取 if hasattr(self, 'conv_mean'): self.conv_mean = conv_features.mean().item() self.conv_std = conv_features.std().item() conv_features = self.global_avg_pool(conv_features) # 全局平均池化 (B, 256, 1, 1) conv_features = conv_features.view(conv_features.size(0), -1) # 展平 (B, 256) shared_features = self.fc_shared(conv_features) # 共享全连接层处理 # 转头动作策略头 turn_logits = self.turn_policy(shared_features) # 转头动作logits state_values = self.value_head(shared_features) # 状态价值 turn_probs = torch.softmax(turn_logits, dim=-1) # 打印神经网络最后一层的值(保留两位小数) turn_probs_np = turn_probs.detach().cpu().numpy().tolist() state_values_np = state_values.detach().cpu().numpy().tolist() # 保留两位小数 turn_probs_rounded = [[round(val, 2) for val in sublist] for sublist in turn_probs_np] state_values_rounded = [[round(val, 2) for val in sublist] for sublist in state_values_np] print(f"[神经网络最后一层] 转头动作概率: {turn_probs_rounded}") print(f"[神经网络最后一层] 状态价值: {state_values_rounded}") return turn_probs, state_valuesclass PPOAgent:
"""
PPO智能体 - 增强版,只输出转头动作
"""
def init(self, state_dim, turn_action_dim, lr=0.001, gamma=0.99, K_epochs=10, eps_clip=0.2):
self.lr = lr # 提高学习率
self.gamma = gamma
self.eps_clip = eps_clip
self.K_epochs = K_epochs # 增加更新轮数
self.entropy_coef = 0.1 # 提高熵正则化系数,鼓励更多探索self.policy = PolicyNetwork(state_dim, turn_action_dim) self.optimizer = optim.Adam(self.policy.parameters(), lr=lr, weight_decay=1e-5) self.policy_old = PolicyNetwork(state_dim, turn_action_dim) self.policy_old.load_state_dict(self.policy.state_dict()) self.MseLoss = nn.MSELoss() # 添加日志记录器 self.logger = setup_logging() # 添加梯度和参数范数跟踪 self.gradient_norms = [] self.parameter_norms = [] self.loss_history = [] self.reward_history = [] # 记录每个episode的总奖励 def select_action(self, state, memory, return_debug_info=False): """ 选择动作 - 只选择转头动作,默认前进 """ # 确保输入状态的形状正确 if len(state.shape) == 3: # (H, W, C) state_tensor = torch.FloatTensor(state).unsqueeze(0).permute(0, 3, 1, 2) else: state_tensor = torch.FloatTensor(state).unsqueeze(0) # 调试:检查输入统计信息(只打印一次) if not hasattr(self, '_debug_printed'): self.logger.info(f"[调试] 输入图像形状: {state_tensor.shape}, " f"均值: {state_tensor.mean().item():.2f}, " f"标准差: {state_tensor.std().item():.2f}, " f"范围: [{state_tensor.min().item():.0f}, {state_tensor.max().item():.0f}]") self._debug_printed = True with torch.no_grad(): turn_probs, state_values = self.policy_old(state_tensor) # 转头动作概率 turn_probs_np = turn_probs.squeeze().cpu().numpy() value_np = state_values.squeeze().cpu().numpy() turn_max_idx = np.argmax(turn_probs_np) # 固定移动动作:默认前进 move_action = 0 # 固定为前进动作 # 转头动作:从策略分布中采样动作 turn_dist = torch.distributions.Categorical(turn_probs) turn_action = turn_dist.sample() turn_logprob = turn_dist.log_prob(turn_action) logprob = turn_logprob # 只计算转头动作的对数概率 # 只在前10步打印详细信息,后面简化输出 if len(memory.rewards) < 10: turn_entropy = turn_dist.entropy().mean() self.logger.info(f"[网络] 转头: [{turn_probs_np[0]:.3f} {turn_probs_np[1]:.3f}] 价值: {value_np:.3f} | " f"最佳: 转头-{turn_max_idx} | " f"输入均值: {getattr(self.policy_old, 'input_mean', 0):.3f}, " f"卷积均值: {getattr(self.policy_old, 'conv_mean', 0):.3f}") self.logger.info(f"[探索] 转头熵: {turn_entropy:.4f}") # 动作参数 # 默认前进,固定前进时间为0.5秒 move_duration = 0.5 # 固定前进时间 turn_angle = 30 # 存储到记忆中 memory.append( state_tensor.squeeze(0), turn_action.item(), logprob.item(), 0, False, [move_duration, turn_angle, move_action] ) if return_debug_info: return move_action, turn_action.item(), move_duration, turn_angle, { 'turn_probs': turn_probs.cpu().numpy(), 'value': state_values } return move_action, turn_action.item(), move_duration, turn_angle def update(self, memory): """ 更新策略 - 只更新转头动作 """ # 计算折扣奖励 rewards = [] discounted_reward = 0 for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)): if is_terminal: discounted_reward = 0 discounted_reward = reward + (self.gamma * discounted_reward) rewards.insert(0, discounted_reward) # 归一化奖励 rewards = torch.FloatTensor(rewards) rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5) # 转换为张量 - 确保维度正确 old_states = torch.stack(memory.states).detach() old_actions_turn = torch.LongTensor(memory.turn_actions).detach() old_logprobs = torch.FloatTensor(memory.logprobs).detach() total_loss = 0 # PPO更新 for _ in range(self.K_epochs): # 前向传播 turn_probs, state_values = self.policy(old_states) # 创建分布 turn_dist = torch.distributions.Categorical(turn_probs) # 计算新旧策略比率 logprobs = turn_dist.log_prob(old_actions_turn) ratio = torch.exp(logprobs - old_logprobs) # 计算优势(使用GAE-like标准化) advantages = rewards - state_values.squeeze(1).detach() advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-5) # PPO损失 surr1 = ratio * advantages surr2 = torch.clamp(ratio, 1 - self.eps_clip, 1 + self.eps_clip) * advantages actor_loss = -torch.min(surr1, surr2).mean() # 价值函数损失 critic_loss = self.MseLoss(state_values.squeeze(), rewards) # 熵正则化 - 鼓励探索,防止策略过早收敛 turn_entropy = turn_dist.entropy().mean() entropy_loss = -turn_entropy # 总损失 loss = actor_loss + 0.5 * critic_loss + self.entropy_coef * entropy_loss total_loss = loss.item() # 反向传播 self.optimizer.zero_grad() loss.backward() # 梯度裁剪 torch.nn.utils.clip_grad_norm_(self.policy.parameters(), max_norm=0.5) # 记录梯度范数 total_norm = 0 for p in self.policy.parameters(): if p.grad is not None: param_norm = p.grad.data.norm(2) total_norm += param_norm.item() ** 2 total_norm = total_norm ** (1. / 2) self.gradient_norms.append(total_norm) # 记录参数范数 param_norm = sum(p.norm(2).item() ** 2 for p in self.policy.parameters()) ** (1. / 2) self.parameter_norms.append(param_norm) self.optimizer.step() self.loss_history.append(total_loss) # 更新旧策略 self.policy_old.load_state_dict(self.policy.state_dict()) # 输出训练信息 if len(self.loss_history) > 0: self.logger.info(f"损失: {self.loss_history[-1]:.4f}, " f"梯度范数: {self.gradient_norms[-1]:.4f}, " f"参数范数: {self.parameter_norms[-1]:.4f}") def save_checkpoint(self, checkpoint_path): """ 保存检查点 """ torch.save({ 'policy_state_dict': self.policy.state_dict(), 'policy_old_state_dict': self.policy_old.state_dict(), 'optimizer_state_dict': self.optimizer.state_dict(), }, checkpoint_path) self.logger.info(f"模型检查点已保存: {checkpoint_path}") def load_checkpoint(self, checkpoint_path): """ 加载检查点 """ checkpoint = torch.load(checkpoint_path, map_location=torch.device('cpu')) self.policy.load_state_dict(checkpoint['policy_state_dict']) self.policy_old.load_state_dict(checkpoint['policy_old_state_dict']) self.optimizer.load_state_dict(checkpoint['optimizer_state_dict']) self.logger.info(f"模型检查点已加载: {checkpoint_path}")def run_episode(env, ppo_agent, episode_num, total_episodes, training_mode=True, print_debug=False, visualizer=None):
"""
运行一个episode - 添加可视化支持
"""
state = env.reset()
episode_memory = Memory()
total_reward = 0
step_count = 0
final_area = 0
success_flag = False
climb_detected = False# 检查初始状态是否有climb initial_detections = env.detect_target(state) climb_detected = env._check_climb_conditions(initial_detections) while step_count < env.max_steps and not climb_detected: # 训练模式:使用act方法 if training_mode: if print_debug: turn_action, move_forward_step, turn_angle, debug_info = ppo_agent.select_action( state, episode_memory, return_debug_info=True) # 打印调试信息 if 'turn_probs' in debug_info: print(f"turn_probs shape: {np.array(debug_info['turn_probs']).shape}") print(f"turn_action: {turn_action}") else: turn_action, move_forward_step, turn_angle = ppo_agent.select_action( state, episode_memory) else: # 评估模式:使用确定性动作 turn_action, move_forward_step, turn_angle = ppo_agent.select_action( state, episode_memory) # 执行环境步骤(只传入转头动作) next_state, reward, done, detection_results = env.step( turn_action, turn_angle) # 检查是否检测到climb climb_detected = env._check_climb_conditions(detection_results) # 更新episode_memory中的奖励和终端状态 if len(episode_memory.rewards) > 0: episode_memory.rewards[-1] = reward episode_memory.is_terminals[-1] = done or climb_detected total_reward += reward state = next_state step_count += 1 # 训练模式下的更新 if training_mode and len(episode_memory.rewards) > 0: # 更新智能体 ppo_agent.update(episode_memory) # 输出梯度和参数范数信息 if ppo_agent.gradient_norms: avg_grad_norm = sum(ppo_agent.gradient_norms[-10:]) / len(ppo_agent.gradient_norms[-10:]) avg_param_norm = sum(ppo_agent.parameter_norms[-10:]) / len(ppo_agent.parameter_norms[-10:]) ppo_agent.logger.info(f"梯度范数: {avg_grad_norm:.4f}, 参数范数: {avg_param_norm:.4f}") # 获取最近的检测图像 recent_detection_images = getattr(env, 'get_recent_detection_images', lambda: [])() return { 'step_count': step_count, 'total_reward': total_reward, 'final_area': final_area, 'climb_detected': climb_detected, 'success_flag': climb_detected, 'recent_detection_images': recent_detection_images }def evaluate_trained_ppo_agent(model_path, evaluation_episodes=10, show_visualization=False):
"""
评估训练好的PPO模型 - 添加可视化支持
"""
# 创建环境和智能体
env = TargetSearchEnvironment(CONFIG['TARGET_DESCRIPTION'])# 启动可视化(如果需要) if show_visualization and QT_AVAILABLE: env.start_visualizer() turn_action_dim = 2 # turn_left, turn_right ppo_agent = PPOAgent( (3, CONFIG.get('IMAGE_HEIGHT', 480), CONFIG.get('IMAGE_WIDTH', 640)), turn_action_dim ) # 加载模型 if os.path.exists(model_path): ppo_agent.load_checkpoint(model_path) print(f"模型已加载: {model_path}") else: print(f"模型文件不存在: {model_path}") return None # 评估循环 scores = [] total_rewards = [] success_count = 0 all_recent_detection_images = [] # 收集所有episode的检测图像 print(f"开始评估,共 {evaluation_episodes} 个episode") for episode in range(evaluation_episodes): # 每隔几轮打印一次调试信息 print_debug = True # 每2轮打印一次调试信息 result = run_episode(env, ppo_agent, episode, evaluation_episodes, training_mode=False, print_debug=print_debug) scores.append(result['step_count']) total_rewards.append(result['total_reward']) if result['success_flag']: success_count += 1 # 收集最近检测图像 all_recent_detection_images.extend(result['recent_detection_images']) print(f"Eval Ep: {episode+1}/{evaluation_episodes}, Steps: {result['step_count']}, " f"Reward: {result['total_reward']:.3f}, Success: {result['success_flag']}") # 计算评估指标 avg_score = np.mean(scores) if scores else 0 avg_reward = np.mean(total_rewards) if total_rewards else 0 success_rate = success_count / evaluation_episodes if evaluation_episodes > 0 else 0 evaluation_result = { 'avg_score': avg_score, 'avg_reward': avg_reward, 'success_rate': success_rate, 'total_evaluated_episodes': evaluation_episodes, 'success_count': success_count, 'recent_detection_images': all_recent_detection_images[-5:] # 只保留最后5个检测图像 } print(f"\n=== 评估结果 ===") print(f"平均步数: {avg_score:.3f}") print(f"平均奖励: {avg_reward:.3f}") print(f"成功率: {success_rate:.3f}") print(f"成功次数: {success_count}/{evaluation_episodes}") return evaluation_resultdef continue_training_ppo_agent(model_path='ppo_model_checkpoint.pth', load_existing=True, show_visualization=False):
"""
继续训练PPO智能体 - 添加可视化支持
"""
# 创建环境和智能体
env = TargetSearchEnvironment(CONFIG['TARGET_DESCRIPTION'])# 启动可视化(如果需要) if show_visualization and QT_AVAILABLE: env.start_visualizer() turn_action_dim = 2 # turn_left, turn_right ppo_agent = PPOAgent( (3, CONFIG.get('IMAGE_HEIGHT', 480), CONFIG.get('IMAGE_WIDTH', 640)), turn_action_dim, lr=CONFIG['LEARNING_RATE'], gamma=CONFIG['GAMMA'], K_epochs=CONFIG['K_EPOCHS'], eps_clip=CONFIG['EPS_CLIP'] ) start_episode = 0 if load_existing and os.path.exists(model_path): # 首先查找检查点文件 latest_checkpoint = find_latest_checkpoint(model_path) if latest_checkpoint: # 如果找到检查点,优先加载检查点 checkpoint = torch.load(latest_checkpoint, map_location=torch.device('cpu')) ppo_agent.policy.load_state_dict(checkpoint['policy_state_dict']) ppo_agent.policy_old.load_state_dict(checkpoint['policy_old_state_dict']) ppo_agent.optimizer.load_state_dict(checkpoint['optimizer_state_dict']) start_episode = int(latest_checkpoint.split('_')[-1].replace('.pth', '')) print(f"从检查点加载模型: {latest_checkpoint}, 从第 {start_episode} 轮开始") elif os.path.exists(model_path): # 没有检查点但主模型存在,加载主模型 checkpoint = torch.load(model_path, map_location=torch.device('cpu')) ppo_agent.policy.load_state_dict(checkpoint['policy_state_dict']) ppo_agent.policy_old.load_state_dict(checkpoint['policy_old_state_dict']) ppo_agent.optimizer.load_state_dict(checkpoint['optimizer_state_dict']) print(f"从主模型加载: {model_path}, 从第 0 轮开始") # 创建目录用于保存训练效果图片 training_plots_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "training_plots") if not os.path.exists(training_plots_dir): os.makedirs(training_plots_dir) # 训练循环 - 使用正确的训练流程 episode_rewards = [] # 记录每个episode的总奖励 combined_memory = Memory() # 用于累积5个episode的经验 for episode in range(start_episode, 2001): print(f"\n=== Episode {episode} Started ===") ppo_agent.logger.info(f"=== Episode {episode} Started ===") state = env.reset() episode_memory = Memory() total_reward = 0 for t in range(env.max_steps): # 智能体选择动作(选择移动动作和转头动作) move_action, turn_action, move_duration, turn_angle = ppo_agent.select_action( state, episode_memory ) # 执行环境步骤(传入移动动作和转头动作) next_state, reward, done, detections = env.step( move_action, turn_action, move_duration, turn_angle ) # 更新记忆中的奖励和终端状态 if len(episode_memory.rewards) > 0: episode_memory.rewards[-1] = reward episode_memory.is_terminals[-1] = done total_reward += reward state = next_state if done: break # 记录奖励 episode_rewards.append(total_reward) ppo_agent.reward_history.append(total_reward) # 将当前episode的经验添加到累积记忆中 for i in range(len(episode_memory.states)): combined_memory.append( episode_memory.states[i], episode_memory.turn_actions[i], episode_memory.logprobs[i], episode_memory.rewards[i], episode_memory.is_terminals[i], episode_memory.action_params[i] if i < len(episode_memory.action_params) else None ) # 每2轮更新一次策略 if (episode + 1) % 2 == 0: if len(combined_memory.rewards) > 0: ppo_agent.update(combined_memory) print(f"Episode {episode}: 每2轮策略更新完成") ppo_agent.logger.info(f"Episode {episode}: 每2轮策略更新完成") combined_memory.clear_memory() # 清空记忆,准备下一轮 # 记录训练信息 print(f"Episode {episode}, Total Reward: {total_reward:.2f}, Steps: {t+1}") ppo_agent.logger.info(f"Episode {episode}, Total Reward: {total_reward:.2f}, Steps: {t+1}") # 每10轮保存一次检查点 if (episode + 1) % 10 == 0: checkpoint_path = f'ppo_model_checkpoint_ep_{episode}.pth' ppo_agent.save_checkpoint(checkpoint_path) # 每20轮生成并保存训练效果图片 if (episode + 1) % 20 == 0: # 计算最近20轮的平均奖励 recent_rewards = episode_rewards[-20:] if len(episode_rewards) >= 20 else episode_rewards avg_reward = np.mean(recent_rewards) print(f"\n=== 训练效果 (最近20轮) ===") print(f"平均奖励: {avg_reward:.2f}") print(f"最大奖励: {max(recent_rewards):.2f}") print(f"最小奖励: {min(recent_rewards):.2f}") # 生成训练效果图表 plt.figure(figsize=(12, 6)) # 图表1: 训练损失 plt.subplot(1, 2, 1) if len(ppo_agent.loss_history) > 0: # 平滑损失曲线(使用移动平均) if len(ppo_agent.loss_history) >= 10: smoothed_loss = np.convolve(ppo_agent.loss_history, np.ones(10)/10, mode='valid') plt.plot(range(10, len(ppo_agent.loss_history) + 1), smoothed_loss, label='平滑损失') else: plt.plot(ppo_agent.loss_history, label='损失') plt.title('训练损失') plt.xlabel('更新次数') plt.ylabel('损失值') plt.grid(True) plt.legend() else: plt.title('训练损失') plt.xlabel('更新次数') plt.ylabel('损失值') plt.grid(True) plt.text(0.5, 0.5, '暂无损失数据', ha='center', va='center', transform=plt.gca().transAxes) # 图表2: 平均奖励 plt.subplot(1, 2, 2) if len(episode_rewards) > 0: # 计算移动平均奖励 window_size = min(10, len(episode_rewards)) if len(episode_rewards) >= window_size: moving_avg_rewards = np.convolve(episode_rewards, np.ones(window_size)/window_size, mode='valid') plt.plot(range(window_size, len(episode_rewards) + 1), moving_avg_rewards, label=f'{window_size}轮移动平均') plt.plot(episode_rewards, alpha=0.3, label='原始奖励') plt.axhline(y=avg_reward, color='r', linestyle='--', label=f'最近20轮平均: {avg_reward:.2f}') plt.title('训练奖励') plt.xlabel('Episode') plt.ylabel('总奖励') plt.grid(True) plt.legend() else: plt.title('训练奖励') plt.xlabel('Episode') plt.ylabel('总奖励') plt.grid(True) plt.text(0.5, 0.5, '暂无奖励数据', ha='center', va='center', transform=plt.gca().transAxes) plt.tight_layout() # 保存图表 plot_path = os.path.join(training_plots_dir, f'training_progress_ep_{episode}.png') plt.savefig(plot_path) plt.close() print(f"训练效果图表已保存: {plot_path}") ppo_agent.logger.info(f"训练效果图表已保存: {plot_path}")def find_latest_checkpoint(model_path):
"""
查找最新的检查点文件
"""
import re
model_dir = os.path.dirname(model_path)
model_base_name = os.path.basename(model_path).replace('.pth', '')# 查找所有相关的检查点文件 checkpoint_pattern = re.compile(rf'{re.escape(model_base_name)}_ep_(\d+)\.pth$') found_checkpoints = [] if os.path.exists(model_dir): for file in os.listdir(model_dir): match = checkpoint_pattern.match(file) if match: full_path = os.path.join(model_dir, file) epoch_num = int(match.group(1)) found_checkpoints.append((full_path, epoch_num)) if found_checkpoints: # 返回具有最高epoch编号的检查点 latest_checkpoint = max(found_checkpoints, key=lambda x: x[1]) return latest_checkpoint[0] return Nonedef create_environment_and_agent():
"""
创建环境和智能体 - 添加可视化支持
"""
# 创建环境
env = TargetSearchEnvironment(CONFIG['TARGET_DESCRIPTION'])turn_action_dim = 2 # turn_left, turn_right ppo_agent = PPOAgent( (3, CONFIG.get('IMAGE_HEIGHT', 480), CONFIG.get('IMAGE_WIDTH', 640)), turn_action_dim ) return env, ppo_agentdef main():
"""
主函数,用于直接运行此脚本
"""
import sys
if len(sys.argv) < 2:
print("默认运行继续训练...")
continue_training_ppo_agent(show_visualization=False)returnif name == "main":
main()