哨兵 Redis Sentinel
通过自动化的手段来解决主节点的挂了的问题
通过独立的进程进行的,不负责储存数据,只是对其他的redis-server进程起到监控的效果
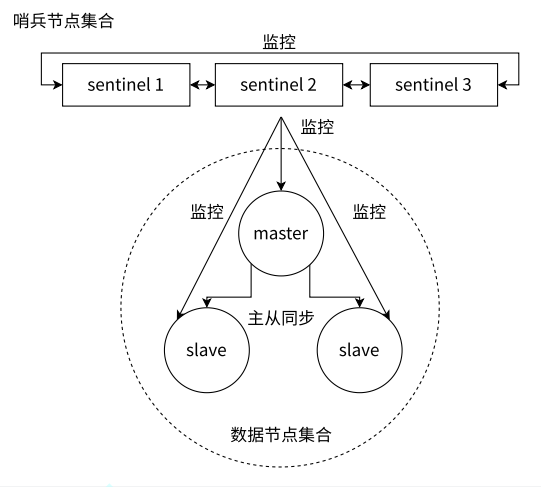
监控:这些进程会建立tcp长连接,定期发送心跳包
核心功能:监控,自动的故障转移,通知
哨兵重新选取主节点的流程
1.主观下线
哨兵节点通过心跳包判断redis服务器是否正常工作,此时不能排除网络波动的影响,
因此只能单方面认为这个redis挂了
2.客观下线
多个哨兵都投票认为挂了
3.选出leader
哨兵节点通过Raft算法选出了一个leader,领导者负责后续故障转移工作
Raft算法的核心就是先下手为强,谁先率先发出拉票请求,谁就大概率成为leader
4.eader在从节点中选一个中作为新主节点执行slaveof no one,让其他从节点同步新主节点
5.通知应用层转移到新的主节点
注意事项
- 哨兵节点不能只有一个,最好是奇数个方便投票
- 哨兵节点不负责存储数据,可以使用一些配备不高的机器来部署
- 哨兵+主从复制解决的问题是"提高可用性",不能解决数据极端情况下写丢失的问题
集群Cluster
redis提供的集群模式主要解决的时存储内存不足的问题
把数据分成多份:数据分片算法
1.哈希求余
优点:简答高效,数据分配均匀
缺点:⼀旦需要进⾏扩容,N改变了,原有的映射规则被破坏,就需要让节点之间的数据相互传输,重新排列,以满⾜新的映射规则.此时需要搬运的数据量是⽐较多的,开销较⼤
2.一致性哈希算法
数据由交替的变成连续的
优点:大大降低了扩容时数据搬运的规模,提高了扩容操作的效率
缺点:数据分配不均匀
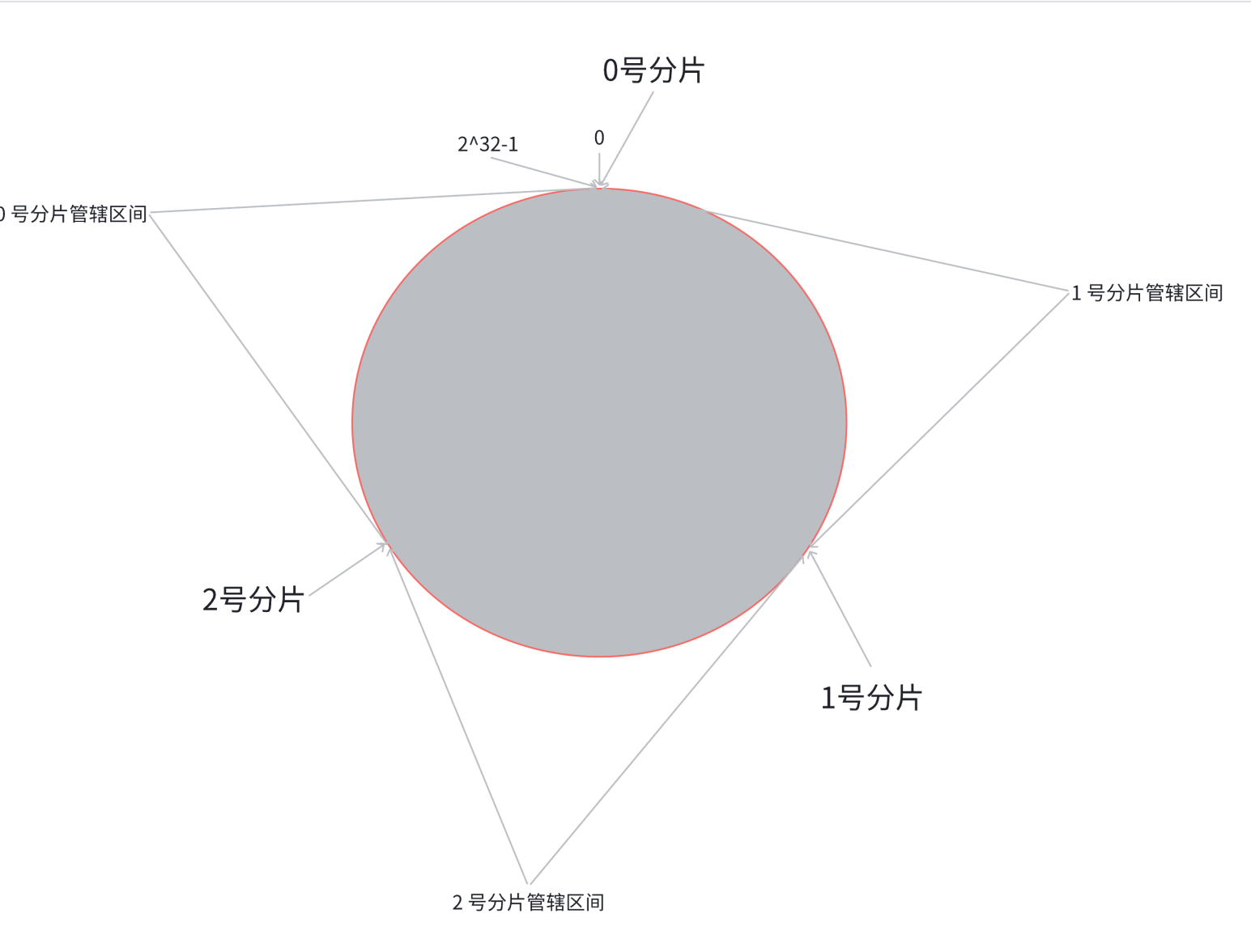
3.哈希槽分区算法

经过扩容,新增分片,我们可以把每个分片的槽位各拿出来伊甸

Redis的作者建议集群分⽚数不应该超过1000
集群故障处理:
1.故障判定
当A判定B为PFAIL后,和其他节点进行沟通,当数目超过总集群个数的一半,那么B就被彻底判定为故障节点了
2.故障迁移
如果B是从节点,那么不需要进行故障迁移
如果B是主机,那么就对B的从节点触发故障迁移
集群扩容操作是一件风险极高,成本较大的操作
缓存的更新策略
1.定期生成
会把访问的数据,会以日志的形式记录下来的
写一套离线的流程,用shell,python脚本代码通过定时任务来触发
2.实时生成策略
如果redis中查到了,就直接返回;相反就从数据库查,把查询到的结果同时也写入redis
如果缓存已经满了就会触发淘汰策略,持续一段时间redis内部的数据就自然是热门数据
淘汰策略:
FIFO先进先出 LRU淘汰最久未使用的 LFU淘汰访问次数最少的 Random 随机淘汰
缓存预热:
实时生成才涉及,redis服务器首次介入之后,服务器里是没有数据的,此时所有的请求都打给mysql,
缓存预热就是用来解决上述问题。
先通过离线的方式,通过一些统计的途径,先把热点数据找到一批,导入到redis中
缓存穿透:
查询的某个key,在redis中没有,mysql也没有,这个key也不会被更新到redis中
这样的数据查多少次都没有,如果还存在很多还反复查询,一样也会给mysql带来很大压力
缓存雪崩:
由于短时间内,redis上大规模的key失效,导致缓存命中率陡然下降,mysql压力迅速上升
可能原因:
1.redis直接挂了 解决方案:加强监控报警,加强redis集群可用性的保证
2.redis正常,但是之前短时间设置了很多key的过期时间是相同的
解决方案:不给key设置过期时间或者设置时添加随机的因子(避免同一时刻过期)
缓存击穿:
相当于是缓存雪崩的特殊情况,针对的是"热点key"
解决方案:
1.基于统计的方式发现热点key并设置永不过期
2.服务降级,类似于省电模式,在特定情况下适当的关闭一些不重要的功能,只保留核心功能
访问数据库的时候使用分布式锁,限制同时请求数据库的并发量
之前学的锁本质上都是只能在一个进程中生效,而在分布式中是多个进程的,因此要引入分布式锁。
分布式锁
操作的时候先加锁(往redis上设置一个特殊的key-value,完成操作再删除掉),
其他服务器也想操作时也去尝试设置,如果发现存在key-value就认为加锁失败,放弃或阻塞
引用setnx 加锁,针对解锁就用del命令
但会出现极端情况:某个加锁成功,执行后续逻辑时崩溃了(没有解锁)
因此引入过期时间,通过set ex nx这样的命令完成设置
所谓的锁即就是redis的普通键值对,但是还是可能服务器1加锁,服务器2解锁
因此引入校验机制:
- 给服务器编号,每个服务器有身份标识
- 进行加锁的时候,key对应要对哪个资源加锁,value就可以储存服务器号
解锁的时候就可以判定是否为同一服务器
但解锁的时候先查询判定,再进行del,这两步操作不是原子的
有可能在一个服务器内两个线程都在执行上述解锁操作,重复删除
因此可以通过lua脚本解决
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;
逻辑是一样的,只不过是原子的
Watch Dog(看门狗)
过期时间的设置多少合适,更好的方式是动态续约
初始情况下,设置一个过期时间(比如1s),就提前(在比如还剩300ms)时候,
如果任务没进行完,就再续上1s,重复之
分布式锁场景中,涉及到的数据量不大,使用redis作为分布式锁,而redis本身就很有很大可能挂了
进行加锁就是把key设置到主节点上,如果主节点挂了就有哨兵自动升级成主节点,进一步保证刚才的锁能用。
但主从节点之间数据同步是存在延时的,主节点收到set请求还没同步就挂了,那么即使从节点升级成主节点,但刚才加锁的数据也不存在。
解决方案:redlock算法
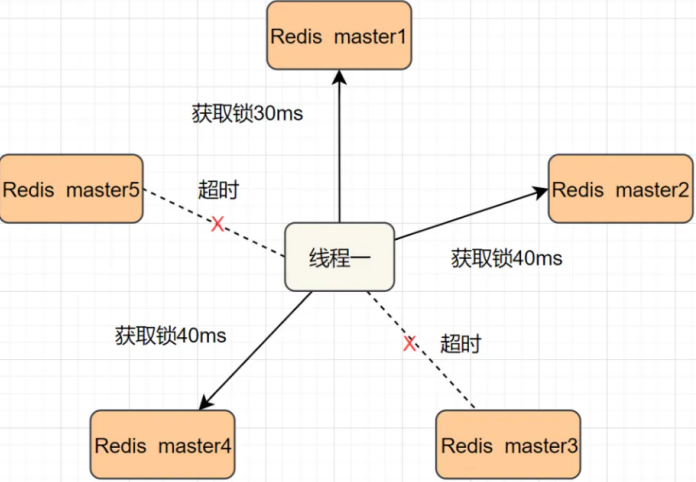
如果每个节点加锁失败就立即尝试下一个节点
如果加锁成功的数超过总节点数的一半才是视为加锁成功