目录
-
- [什么是上下文工程(Context Engineering)?](#什么是上下文工程(Context Engineering)?)
- 为什么上下文工程很重要?
-
- [什么是上下文窗口(Context Window)?](#什么是上下文窗口(Context Window)?)
- 错误的上下文窗口会导致什么问题?
- 上下文工程策略
什么是上下文工程(Context Engineering)?
背景
上下文工程(Context Engineering)在 2025年中期(6月至7月)兴起的一个新术语,使 LLM (大语言模型)讨论的焦点从 Prompt Engineering 转向这个更广泛、更强大的概念:Context Engineering.
Context Engineering 这一术语提出者和定义者为 OpenAI 创始成员 Andrej Karpathy 提出,他用计算机体系结构做了一个类比:
- LLM 是 CPU(处理器)。
- Context Window(上下文窗口)是 RAM(内存)。
- Prompt Engineering 类似于给 CPU 下达指令。
- Context Engineering 则是决定在每一步操作中,加载什么数据到 RAM(内存)中。
定义
关于上下文工程(Context Engineering)的定义和理念,我觉得 Andrey Karpathy 的帖子对此做了很好的总结:
原文:People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
上下文工程是一门精妙的艺术和科学,它旨在为下一步操作在上下文窗口中填充恰到好处的信息。
之所以称之为科学,是因为要把这件事做好,涉及到任务描述与解释、少样本示例(few-shot)、RAG(检索增强生成)、相关数据(可能是多模态的)、工具、状态与历史信息、上下文压缩等诸多因素。信息太少或形式不当,模型就无法获得实现最佳性能所需的上下文;信息太多或无关紧要,则可能导致模型成本上升、性能反而下降。要把这些平衡好,本身就是一件极具挑战性的事情。
而之所以称之为艺术,则在于其中蕴含着一种对大语言模型"心理"和行为方式的直觉性把握。
为什么上下文工程很重要?
随着大语言模型的广泛使用,模型的上下文窗口(Context Window)也在不断扩大,从 128k 扩展到 1M+ tokens。即使现在上下文窗口已经很大的,但是不是无限的,而且过大的冗余上下文还会导致模型能力降低。
而且当 LLM 出现问题时,通常情况下原因一般有两个:
- 底层模型出了问题,它不够好。
- 底层模型没有被赋予合适的上下文信息,因此无法产生良好的输出。
第一原因,一般人是解决不了的。第二个原因,也就是上下文问题了。
比如下面两个场景:
-
在 web 界面的会提示你升级成 Pro、MAX 支持更大上下文窗口的版本。而你升级后会发现即使是最最最尊贵的 MAX 用户,也会出现一样的问题,这时候你发现只能新建一个 Chat。
-
在 AI IDE 中,它们有的会自行给你将前面的会话压缩,然后再新起一个会话,继续完成你的需求,这种情况下,好像用 AI IDE 开发也没关系,反正 IDE 帮我继续了会话。但是不知道你们有没有发现,其实随着上下文窗口的增大,LLM 的性能逐渐下降,并且最重要的你会消耗更多的 Token,不知不觉中,你的Token没了,然后需要花费更多的钱买更多的Token。
不知道大家有没有遇到过这两个场景,反正我都遇到了。也就是基于我自身遇到的问题(没有问题的话,你怎么会知道你需要什么?),才有了对 Context 的研究,进而了解到了 Context Engineering。所以想真正的懂得 Context Engineering,得先从模型的 Context Window 开始。
在这两年用 AI 和研究 AI,我一年花了近一千刀(没赚到一分钱,纯喜欢研究)。最烧钱的时候,是开了个一次 Claude MAX,然后发现其实没啥大用,因为上下文窗口就在那里。该换会话还换。AI订阅最多的时候是开了 Claude,GPT + AWS Kiro,然后现在就剩下一个白嫖一年的 Gemini + 每个月 20 刀的 Kiro。
说点题外话,开发来说,我认为 Claude 最牛,没有之一,至少对于我来说。借助 Claude,我从一个SRE 突然就成了一个全栈了,反正啥都干,前端后端,架构设计都是我来搞(工资是一点没多)。
至于这个文章为什么26年1月才发,因为25年倒大霉,经历了很多乱七八糟的,心境乱了,很多文档都是写了一个开头。
什么是上下文窗口(Context Window)?
上下文窗口是指大语言模型在生成新文本时可以回顾和参考的全部文本量,加上它生成的新文本。并不是模型训练用的大型数据语料库,而是模型的"工作记忆"。
较大的上下文窗口允许模型理解和响应更复杂和冗长的提示,而较小的上下文窗口可能会限制模型处理较长提示或在扩展对话中保持连贯性的能力。
模型思考的内容,也是属于上下文窗口的,也是消耗 Token 的,所以别什么问题都用 Thinking。简单问题问Thinking,可能废 Token 不说,还会更加不准确,因为你让它在胡思乱想。
下面的图表说明了API请求的标准上下文窗口行为:
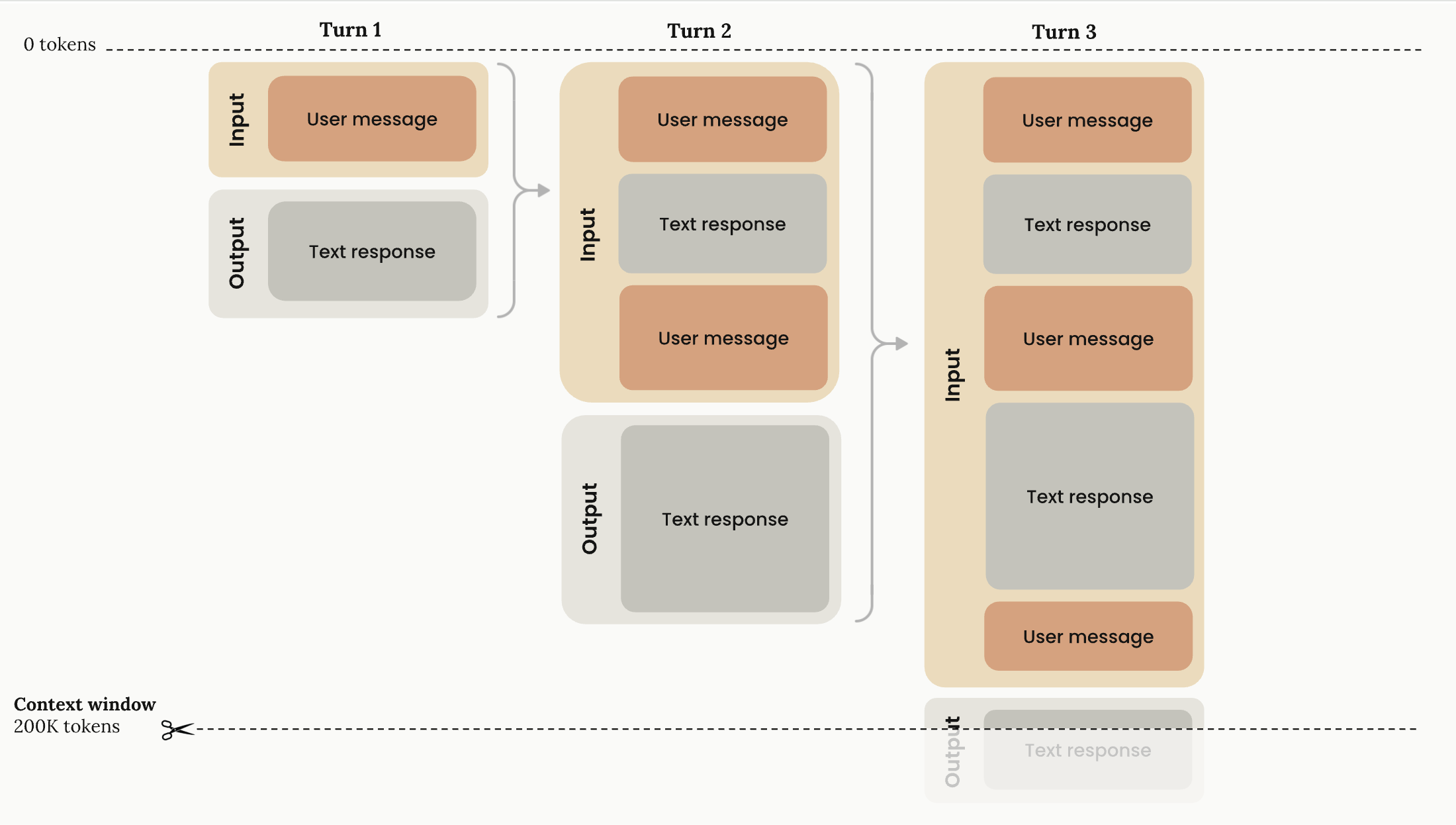
可以看到当你超过模型的最大上下文窗口时,模型输出就会被截断了。这个是模型的上下文窗口最大限制,已经不是升级订阅可以解决的了。
在这里就说明 API 请求的标准上下文窗口行为,关于思考和工具调用的上下文窗口可以看这篇 Claude 文档:context-windows,很详细也很简单,就不单独整理了。免得因一字之差,而误人子弟。
- 渐进式令牌累积: 随着对话在轮次中推进,每条用户消息和助手响应都在上下文窗口内累积。之前的轮次完全保留。
- 线性增长模式: 上下文使用随着每一轮线性增长,之前的轮次完全保留。
- 200K令牌容量: 总可用上下文窗口(200,000个令牌)代表存储对话历史和从Claude生成新输出的最大容量。
- 输入-输出流 :每一轮包括:
- 输入阶段: 包含所有之前的对话历史加上当前用户消息
- 输出阶段: 生成成为未来输入一部分的文本响应
错误的上下文窗口会导致什么问题?
这里借用 Manus 发布的一篇文章做个总结,原文:AI代理的上下文工程:构建Manus的经验教训
- **上下文腐烂 **(Context Rot) 是指随着上下文窗口被填满,大语言模型的性能会下降的现象,即使总token数远低于技术限制(例如100万tokens)。"有效上下文窗口"------即模型能保持高质量表现的窗口------往往远小于广告宣传的token限制,目前对大多数模型来说小于25.6万tokens。
- 上下文污染 (Context Pollution) 是指上下文中存在过多不相关、冗余或相互冲突的信息,这些信息会分散大语言模型的注意力并降低其推理准确性。
- 上下文混淆 (Context Confusion) 是指大语言模型无法区分指令、数据和结构标记,或遇到逻辑上不兼容的指令时出现的失效模式。这种情况经常发生在系统指令(全局规则)内部发生冲突、存在过多相似指令或与用户指令冲突时。
简单一点就是,错误的上下文窗口会导致模型性能下降,浪费更多的 Token,准确率更低。
上下文工程策略
上下文工程的核心在于如何高效地管理有限的上下文窗口资源,以下四个维度来构建上下文策略:
这四个维度的策略其实在最新 Anthropic 的 Agent Skills 都应用到了,从现在往后看,发现一切都是有迹可循的。
上下文卸载 (Context Offloading)
将信息移至外部系统,以减轻上下文窗口的负担。LLM 的上下文窗口是昂贵且有限的,不应作为长期存储。
- 暂存区 (Scratchpads): 让 Agent 将思考过程、中间结果或关键信息写入到暂存区(如文件或特定的状态字段),而不是全部堆积在对话历史中。
- 外部记忆 (Memories): 建立跨会话的长期记忆机制,Agent 可以将重要的反思、用户偏好或合成的知识存储起来,供未来调用。
- 文件系统作为上下文: 利用文件系统作为无限的持久化存储。Agent 可以按需读取和写入文件,处理大量数据(如网页、PDF),仅在上下文中保留文件引用(URL 或路径)。
上下文缩减 (Context Reduction)
通过压缩历史记录,在保留关键信息的同时减少 Token 消耗。
- 摘要 (Summarization): 当对话或工具输出过长时,使用 LLM 对其进行摘要。这可以是分层的(递归摘要)或基于触发器的(如达到 Token 阈值)。
- 修剪 (Trimming): 基于规则移除旧的或不重要的消息。例如,保留最近的 N 轮对话,或移除早期的冗余思考过程。
- 可恢复压缩: 采用非破坏性的压缩方式。例如,将网页内容替换为其 URL,虽然从上下文中移除了内容,但 Agent 仍可通过 URL 重新获取(Re-retrieval)。
上下文检索 (Context Retrieval)
动态地将相关信息添加到上下文中,实现"即时"(Just-in-Time)加载。
- RAG (检索增强生成): 对于知识库或代码库,通过向量检索或关键词搜索,仅提取与当前任务最相关的片段。
- 工具选择: 当工具数量庞大时,通过检索机制动态筛选出当前任务可能需要的工具子集,避免将所有工具描述都塞入上下文中,减少模型困惑。
- 注意力操控: 对于长周期任务,可以将关键目标或计划(如
todo.md)"朗读"或插入到上下文的末尾,强制模型关注最新的任务状态,防止"中间迷失"(Lost-in-the-middle)现象。
上下文隔离 (Context Isolation)
通过分离上下文来提高任务的专注度和效率,避免信息相互干扰。
- 多智能体系统 (Multi-agent Systems): 将复杂任务分解给多个子 Agent。每个子 Agent 拥有独立的上下文窗口和专用工具,专注于特定子任务,互不干扰。
- 沙盒环境: 在隔离的环境中执行工具或代码。只有最终结果被返回给 LLM,中间产生的大量过程数据被隔离在沙盒中,避免污染上下文。
- 状态对象分离: 设计结构化的状态对象,区分"公开"和"私有"上下文。在每轮对话中,仅向 LLM 暴露当前决策所需的字段,隐藏无关的内部状态。