1. 引言:词向量---让机器理解语言的基础
在自然语言处理领域,如何让计算机"理解"词语的含义一直是一个核心挑战。传统的文本处理方法,如词袋模型,将每个词视为孤立的符号,无法捕捉词语之间的语义关系。例如,"国王"和"王后"这两个词在语义上密切相关,但在词袋模型中却被当作完全独立的特征。
词向量技术的出现彻底改变了这一局面。通过将每个词表示为高维空间中的一个连续向量,词向量能够捕捉丰富的语义信息。其中最著名的例子是:国王 - 男人 + 女人 ≈ 王后。这种向量运算能力让机器能够进行类比推理,为自然语言理解打开了新的大门。
本文将带您深入探索三种主流的词向量技术:Word2Vec、FastText和GloVe,并通过完整的代码实践展示如何训练、可视化和应用这些词向量模型。
2. 环境配置与基础概念
2.1. 核心库介绍
构建词向量系统需要多个Python库的支持:
python
import matplotlib
matplotlib.use('TkAgg') # 设置matplotlib后端
import os
import gensim
from gensim.models import Word2Vec, FastText, KeyedVectors
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False-
Gensim:专业的自然语言处理库,提供Word2Vec、FastText等实现
-
Matplotlib:数据可视化工具,用于词向量可视化
-
scikit-learn:提供PCA和t-SNE降维算法
-
NumPy:高效的数值计算库
2.2. 词向量的核心思想
- 分布式假设
词向量的理论基础是"分布式假设":具有相似上下文的词语具有相似的含义。例如,"苹果"和"香蕉"在句子中出现的上下文相似(如"吃苹果"、"吃香蕉"),因此它们的词向量应该接近。
- 词向量特性
-
语义相似性:相似词在向量空间中的距离较近
-
语义关系:可以通过向量运算捕捉词语关系
-
多维度表示:每个维度捕捉词语的不同特征
3. 训练自己的词向量模型
3.1. 准备训练语料
训练词向量需要大量的文本数据。这里我们使用一个简单的英文示例语料:
python
# 准备示例语料库
sentences = [
["natural", "language", "processing", "is", "fascinating"],
["word", "embeddings", "capture", "semantic", "meaning"],
["king", "queen", "man", "woman", "royalty"],
["similar", "words", "have", "close", "vectors"],
["machine", "learning", "models", "learn", "patterns"]
]语料预处理要点:
-
分词处理:将文本分割为词语序列
-
大小写统一:通常转换为小写
-
去除停用词:可选的预处理步骤
-
数据量要求:训练高质量词向量需要大量数据
3.2. Word2Vec模型训练
Word2Vec是Google于2013年提出的词向量模型,包含两种架构:
python
# 训练Word2Vec模型
word2vec_model = Word2Vec(
sentences, # 输入的句子列表
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=1, # 最小词频阈值
workers=4, # 并行线程数
epochs=50 # 训练轮次
)- Word2Vec的两种架构
-
CBOW(连续词袋模型):根据上下文预测目标词,训练速度快
-
Skip-Gram:根据目标词预测上下文,适合处理稀有词
- 关键参数解析
-
vector_size:词向量的维度,通常100-300维
-
window:上下文窗口大小,决定考虑多远距离的上下文
-
min_count:忽略词频低于此值的词语
-
workers:并行训练线程数,提高训练速度
3.3. FastText模型训练
FastText是Facebook于2016年提出的改进模型,通过子词信息处理未登录词:
python
# 训练FastText模型
fasttext_model = FastText(
sentences, # 输入的句子列表
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=1, # 最小词频阈值
workers=4, # 并行线程数
epochs=50, # 训练轮次
min_n=3, # 最小子词长度
max_n=6 # 最大子词长度
)FastText的核心优势:
-
子词表示:将词语拆分为字符n-gram,处理未登录词
-
形态学敏感:能捕捉词语的形态学变化
-
稀有词处理:即使词频很低也能获得较好表示
3.4. 模型保存与加载
python
# 保存模型
word2vec_model.save("word2vec_model.bin")
fasttext_model.save("fasttext_model.bin")
# 打印模型信息
print(f"\nWord2Vec模型信息:")
print(f"- 词汇量:{len(word2vec_model.wv)}")
print(f"- 词向量维度:{word2vec_model.vector_size}")
print(f"- 训练轮次:{word2vec_model.epochs}")
print(f"\nFastText模型信息:")
print(f"- 词汇量:{len(fasttext_model.wv)}")
print(f"- 词向量维度:{fasttext_model.vector_size}")
print(f"- 最小子词长度:{fasttext_model.wv.min_n}")
print(f"- 最大子词长度:{fasttext_model.wv.max_n}")4. 词向量可视化与探索
4.1. 降维技术原理
词向量通常有100-300个维度,无法直接可视化。我们需要降维技术将其投影到2D或3D空间:
4.1.1. PCA(主成分分析)
-
原理:找到数据方差最大的方向
-
优点:计算快速,保持全局结构
-
缺点:可能扭曲局部结构
4.1.2. T-SNE(T分布随机邻域嵌入)
-
原理:保持高维空间中的局部邻域关系
-
优点:能揭示数据的聚类结构
-
缺点:计算较慢,超参数敏感
4.2. 可视化实现
python
# 词向量可视化函数
def visualize_vectors(model, words, method='pca'):
# 检查模型是否有wv属性
vector_model = model.wv if hasattr(model, 'wv') else model
vectors = [vector_model[word] for word in words]
vectors = np.array(vectors)
# 降维可视化
if method == "pca":
reducer = PCA(n_components=2)
title = "Word Vector Visualization (PCA)"
else:
reducer = TSNE(
n_components=2,
perplexity=min(5, len(words)-1),
learning_rate=200,
random_state=42
)
title = "Word Vector Visualization (t-SNE)"
result = reducer.fit_transform(vectors)
return result, title
# 创建单独的可视化函数
def plot_vectors(result, words, title):
plt.figure(figsize=(10, 6))
plt.scatter(result[:, 0], result[:, 1])
# 添加词语标签
for i, word in enumerate(words):
plt.annotate(word, xy=(result[i, 0], result[i, 1]))
plt.title(title)
plt.show()4.3. 对比可视化
同时比较PCA和T-SNE的降维效果:
python
# 可视化示例词
test_words = ["king", "queen", "man", "woman", "royalty"]
# 合并可视化(PCA + t-SNE)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
fig.suptitle('词向量可视化对比:PCA vs t-SNE', fontsize=16)
# PCA降维
result_pca, _ = visualize_vectors(word2vec_model, test_words, method="pca")
ax1.scatter(result_pca[:, 0], result_pca[:, 1])
for i, word in enumerate(test_words):
ax1.annotate(word, xy=(result_pca[i, 0], result_pca[i, 1]))
ax1.set_title("PCA降维(保持全局结构)")
# T-SNE降维
result_tsne, _ = visualize_vectors(word2vec_model, test_words, method="tsne")
ax2.scatter(result_tsne[:, 0], result_tsne[:, 1])
for i, word in enumerate(test_words):
ax2.annotate(word, xy=(result_tsne[i, 0], result_tsne[i, 1]))
ax2.set_title("t-SNE降维(保持局部结构)")
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()可视化结果解读:
-
PCA:更关注全局结构,可能将语义不相关的词放在一起
-
T-SNE:更关注局部结构,能清晰展示词语的聚类关系
5. 使用预训练词向量模型
5.1. GloVe模型介绍
GloVe 是斯坦福大学于2014年提出的词向量模型。与Word2Vec基于局部上下文不同,GloVe基于全局词共现矩阵,同时考虑了词语的共现频率。
GloVe的优势:
-
全局统计信息:利用整个语料库的统计信息
-
训练速度快:相比Word2Vec通常训练更快
-
性能优秀:在多项任务上表现优异
5.2. 加载预训练GloVe模型
python
# 加载预训练GloVe模型
def load_glove_model(glove_file='glove.6b.100d.txt', convert=True):
"""加载GloVe模型,可选是否先转换为Word2Vec格式"""
# 获取当前脚本的绝对路径
script_dir = os.path.dirname(os.path.abspath(__file__))
glove_path = os.path.join(script_dir, glove_file)
# 检查文件是否存在
if not os.path.exists(glove_path):
print(f"未找到GloVe模型文件: {glove_path}")
print("下载指南: wget https://nlp.stanford.edu/data/glove.6B.zip && unzip glove.6B.zip")
print("解压后将 glove.6b.100d.txt 放入与本脚本相同目录")
return None
# 转换为Word2Vec格式
w2v_path = f"{glove_path}.w2v.txt"
if convert and not os.path.exists(w2v_path):
print(f"正在将GloVe转换为Word2Vec格式: {w2v_path}")
from gensim.scripts.glove2word2vec import glove2word2vec
glove2word2vec(glove_path, w2v_path)
try:
path_to_use = w2v_path if convert else glove_path
print(f"正在加载Glove模型: {path_to_use}")
model = KeyedVectors.load_word2vec_format(path_to_use, binary=False)
return model
except Exception as e:
print(f"加载Glove模型失败: {e}")
return None预训练模型资源:
-
GloVe:提供多种维度的预训练模型(50d, 100d, 200d, 300d)
-
Word2Vec:Google News预训练模型(300维,300万词汇)
-
FastText:多语言预训练模型,支持157种语言
5.3. 可视化GloVe词向量
python
# 尝试加载GloVe模型
glove_model = load_glove_model()
if glove_model:
# 可视化GloVe词向量
glove_words = [w for w in test_words if w in glove_model]
if len(glove_words) >= 3:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
fig.suptitle('GloVe词向量可视化对比:PCA vs t-SNE', fontsize=16)
# PCA降维
result_pca, _ = visualize_vectors(glove_model, glove_words, method="pca")
ax1.scatter(result_pca[:, 0], result_pca[:, 1])
for i, word in enumerate(glove_words):
ax1.annotate(word, xy=(result_pca[i, 0], result_pca[i, 1]))
ax1.set_title("GloVe - PCA降维")
# t-SNE降维
result_tsne, _ = visualize_vectors(glove_model, glove_words, method="tsne")
ax2.scatter(result_tsne[:, 0], result_tsne[:, 1])
for i, word in enumerate(glove_words):
ax2.annotate(word, xy=(result_tsne[i, 0], result_tsne[i, 1]))
ax2.set_title("GloVe - t-SNE降维")
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()6. 词向量应用:词类比测试
6.1. 词类比原理
词类比测试是评估词向量质量的重要方法。最经典的例子是:国王 - 男人 + 女人 ≈ 王后
python
# 词类比测试
def word_analogy_test(model, a, b, c):
"""测试词类比: a:b :: c:?"""
try:
vector_model = model.wv if hasattr(model, 'wv') else model
result = vector_model.most_similar(positive=[b, c], negative=[a], topn=3)
print(f"\n词类比测试:{a}:{b} :: {c}:?\n结果: {result}")
except Exception as e:
print(f"词类比测试失败,可能是词汇表中缺少词语: {e}")
# 测试词类比
word_analogy_test(word2vec_model, 'man', 'woman', 'king')6.2. 词类比应用场景
-
语义关系发现:首都-国家关系(巴黎-法国,东京-?)
-
形态学变化:形容词-副词关系(quick-quickly,slow-?)
-
时态变化:动词时态关系(go-went,eat-?)
-
词性变化:名词-形容词关系(child-childish,fool-?)
7. 三种模型的对比分析
7.1. 技术特点对比
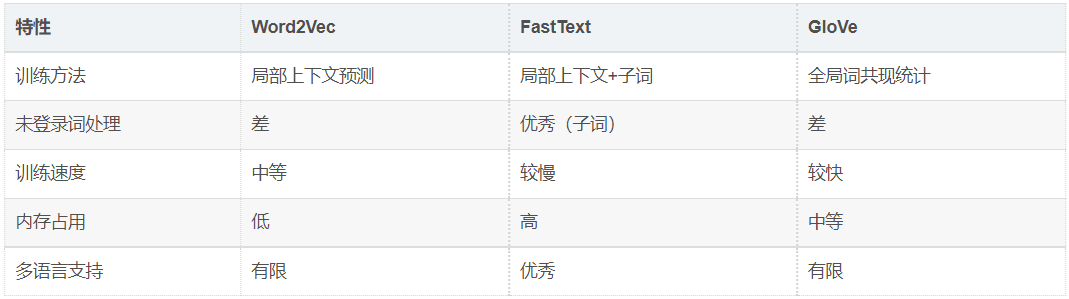
7.2. 应用场景选择
7.2.1. 选择Word2Vec的情况
-
有大量领域特定文本
-
不需要处理未登录词
-
计算资源有限
7.2.2. 选择FastText的情况
-
处理形态丰富的语言(如土耳其语、芬兰语)
-
需要处理未登录词
-
有足够的计算资源
7.2.3. 选择GloVe的情况
-
需要快速获得高质量词向量
-
有预训练模型可用
-
关注全局语义关系
8. 实际应用建议
8.1. 中文词向量训练
对于中文文本,需要特别注意:
-
分词质量:使用高质量分词工具(如jieba、THULAC)
-
字符级处理:中文可考虑字符级词向量
-
领域适应:针对特定领域训练专用词向量
8.2. 性能优化技巧
-
批量处理:使用批量相似度计算
-
模型压缩:使用量化技术减少模型大小
-
缓存机制:缓存常用词的相似度结果
8.3. 评估指标
-
内在评估:词类比、相似度任务
-
外在评估:在下游任务上的表现(如文本分类、命名实体识别)
-
可视化评估:通过降维可视化直观检查
9. 完整代码示例
以下是完整的词向量训练、可视化和应用代码:
python
import matplotlib
matplotlib.use('TkAgg')
import os
import gensim
from gensim.models import Word2Vec, FastText, KeyedVectors
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 准备示例语料库
sentences = [
["natural", "language", "processing", "is", "fascinating"],
["word", "embeddings", "capture", "semantic", "meaning"],
["king", "queen", "man", "woman", "royalty"],
["similar", "words", "have", "close", "vectors"],
["machine", "learning", "models", "learn", "patterns"]
]
# 训练Word2Vec模型
word2vec_model = Word2Vec(
sentences,
vector_size=100,
window=5,
min_count=1,
workers=4,
epochs=50
)
# 训练FastText模型
fasttext_model = FastText(
sentences,
vector_size=100,
window=5,
min_count=1,
workers=4,
epochs=50,
min_n=3,
max_n=6
)
# 保存模型
word2vec_model.save("word2vec_model.bin")
fasttext_model.save("fasttext_model.bin")
# 打印模型信息
print(f"\nWord2Vec模型信息:")
print(f"- 词汇量:{len(word2vec_model.wv)}")
print(f"- 词向量维度:{word2vec_model.vector_size}")
print(f"- 训练轮次:{word2vec_model.epochs}")
print(f"\nFastText模型信息:")
print(f"- 词汇量:{len(fasttext_model.wv)}")
print(f"- 词向量维度:{fasttext_model.vector_size}")
print(f"- 最小子词长度:{fasttext_model.wv.min_n}")
print(f"- 最大子词长度:{fasttext_model.wv.max_n}")
# 词向量可视化函数
def visualize_vectors(model, words, method='pca'):
vector_model = model.wv if hasattr(model, 'wv') else model
vectors = [vector_model[word] for word in words]
vectors = np.array(vectors)
if method == "pca":
reducer = PCA(n_components=2)
title = "Word Vector Visualization (PCA)"
else:
reducer = TSNE(
n_components=2,
perplexity=min(5, len(words)-1),
learning_rate=200,
random_state=42
)
title = "Word Vector Visualization (TSNE)"
result = reducer.fit_transform(vectors)
return result, title
def plot_vectors(result, words, title):
plt.figure(figsize=(10, 6))
plt.scatter(result[:, 0], result[:, 1])
for i, word in enumerate(words):
plt.annotate(word, xy=(result[i, 0], result[i, 1]))
plt.title(title)
plt.show()
# 可视化示例词
test_words = ["king", "queen", "man", "woman", "royalty"]
# 合并可视化(PCA + TSNE)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
fig.suptitle('词向量可视化对比:PCA vs TSNE', fontsize=16)
# PCA降维
result_pca, _ = visualize_vectors(word2vec_model, test_words, method="pca")
ax1.scatter(result_pca[:, 0], result_pca[:, 1])
for i, word in enumerate(test_words):
ax1.annotate(word, xy=(result_pca[i, 0], result_pca[i, 1]))
ax1.set_title("PCA降维(保持全局结构)")
# TSNE降维
result_tsne, _ = visualize_vectors(word2vec_model, test_words, method='tsne')
ax2.scatter(result_tsne[:, 0], result_tsne[:, 1])
for i, word in enumerate(test_words):
ax2.annotate(word, xy=(result_tsne[i, 0], result_tsne[i, 1]))
ax2.set_title("TSNE降维(保持局部结构)")
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
# 加载预训练GloVe模型
def load_glove_model(glove_file='glove.6b.100d.txt', convert=True):
script_dir = os.path.dirname(os.path.abspath(__file__))
glove_path = os.path.join(script_dir, glove_file)
if not os.path.exists(glove_path):
print(f"未找到GloVe模型文件:{glove_path}")
print("下载指南:wget https://nlp.stanford.edu/data/glove.6B.zip && unzip glove.6B.zip")
print("解压后将 glove.6b.100d.txt 放入与本脚本相同目录")
return None
w2v_path = f"{glove_path}.w2v.txt"
if convert and not os.path.exists(w2v_path):
print(f"正在将GloVe转换为Word2Vec格式: {w2v_path}")
from gensim.scripts.glove2word2vec import glove2word2vec
glove2word2vec(glove_path, w2v_path)
try:
path_to_use = w2v_path if convert else glove_path
print(f"正在加载Glove模型:{path_to_use}")
model = KeyedVectors.load_word2vec_format(path_to_use, binary=False)
return model
except Exception as e:
print(f"加载Glove模型失败:{e}")
return None
# 词类比测试
def word_analogy_test(model, a, b, c):
try:
vector_model = model.wv if hasattr(model, 'wv') else model
result = vector_model.most_similar(positive=[b, c], negative=[a], topn=3)
print(f"\n词类比测试:{a}:{b} :: {c}:?\n结果:{result}")
except Exception as e:
print(f"词类比测试失败,可能是词汇表中缺少词语:{e}")
# 测试词类比
word_analogy_test(word2vec_model, 'man', 'woman', 'king')
# 尝试加载GloVe模型
glove_model = load_glove_model()
if glove_model:
glove_words = [w for w in test_words if w in glove_model]
if len(glove_words) >= 3:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
fig.suptitle('GloVe词向量可视化对比:PCA vs TSNE', fontsize=16)
# PCA降维
result_pca, _ = visualize_vectors(glove_model, glove_words, method="pca")
ax1.scatter(result_pca[:, 0], result_pca[:, 1])
for i, word in enumerate(glove_words):
ax1.annotate(word, xy=(result_pca[i, 0], result_pca[i, 1]))
ax1.set_title("GloVe - PCA降维")
# TSNE降维
result_tsne, _ = visualize_vectors(glove_model, glove_words, method="tsne")
ax2.scatter(result_tsne[:, 0], result_tsne[:, 1])
for i, word in enumerate(glove_words):
ax2.annotate(word, xy=(result_tsne[i, 0], result_tsne[i, 1]))
ax2.set_title("GloVe - TSNE降维")
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
try:
word_analogy_test(glove_model, 'man', 'woman', 'king')
except Exception as e:
print("GloVe模型不支持词类比测试,需要完整模型")10. 总结与展望
通过本文的完整实践,我们深入探索了三种主流的词向量技术。词向量作为自然语言处理的基础技术,已经深刻影响了NLP的发展方向。
未来发展趋势包括:
-
上下文相关词向量:如BERT、ELMo等动态词向量
-
多语言词向量:统一的多语言语义空间
-
知识增强词向量:融合外部知识图谱
-
高效压缩技术:减小模型大小,提高推理速度
无论您是NLP初学者还是经验丰富的研究者,掌握词向量技术都是深入理解现代自然语言处理的基础。希望本文能为您的学习和实践提供有价值的参考。