训练大语言模型(LLM)主要分为三个核心阶段:
- 预训练:从海量数据集中学习,形成基础模型。
- 监督微调(SFT):通过精心挑选的示例优化模型,使其更实用。
- 强化学习(Reinforcement Learning,RL):与监督微调(SFT)不同,SFT依赖人类专家提供的标签数据,而RL则允许模型从自身的学习中进步。让模型在那些导致更好结果的token序列上进行训练,允许模型从自身的经验中学习。模型不再仅仅依赖显式标签,而是通过探索不同的token序列,并根据哪些输出最有用来获得反馈(奖励信号)。随着时间的推移,模型学会了更好地与人类意图对齐。
LoRA微调
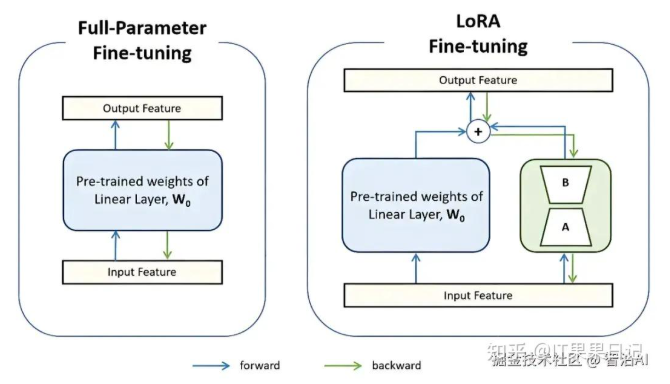
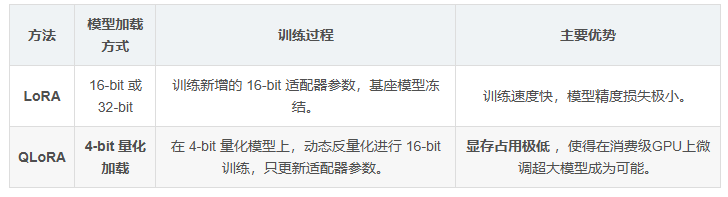
LORA(Low-Rank Adaptation) 是一种高效的参数高效微调方法,其核心思想是通过在预训练模型的权重矩阵中引入低秩适配矩阵(低秩分解矩阵 A 和 B),仅对这部分新增参数进行训练,从而大幅减少计算和显存开销。与传统全参数微调相比,LORA 通过冻结原始模型参数,仅更新适配层参数,实现了轻量化训练。
LORA 微调 的具体实现是通过 peft(Parameter-Efficient Fine-Tuning)库,结合 transformers 框架完成。例如,在 DeepSeek-7B 模型中,LORA 可针对注意力机制的关键层(如 q_proj、v_proj)进行适配,保留模型通用能力的同时,快速适应特定任务需求。
低秩分解: 精简更新
LORA 的聪明之处在于,它认为你不需要更新整个大矩阵,而是可以用一个"精简版"来代替。这个精简版叫"低秩矩阵",它捕捉了大矩阵里最核心的变化信息,但参数量小得多。具体操作是这样的:
在原始的权重矩阵(记为(W))旁边,加两个小矩阵(A)和(B); (A)和(B)的"秩"(rank)很低(比如8或16),参数量远小于(W); 微调时,原始矩阵(W)不动,只更新(A)和(B)。
最后,模型的输出变成 w+AxB,这里的 AxB就像一个小助手,帮原始模型适应新任务。第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。
实施LoRA微调的步骤
LoRA 的使用过程很简单,步骤如下:
- 选个基础模型: 比如一个预训练好的大模型(LLaMA、GPT等)
- 加 LoRA 模块: 在模型的某些层(比如自注意力层)旁边加两个小矩阵(A)和(B)。
冻结原始参数: 训练时,原始模型的参数不动,只更新(A)和(B)。
微调: 用新任务的数据训练(A)和(B),让它们学会A.新技能。
推理: 用的时候,把 LoRA 模块加到原始模型上,模型就能干新活了。
简单说,LoRA 用很少的参数(比如1.6万个)代替了更新全部参数(100 万个),但效果依然很好。
LORA 微调的优势与特点
资源占用低
通过仅训练低秩矩阵(如秩 r=8),显存需求可降低 5-10 倍。例如,DeepSeek-7B 在 4bits 量化后,显存占用仅需约 6GB,支持消费级显卡(如 RTX 3090)训练。
训练速度快
参数更新量减少 90% 以上,训练速度显著提升。实验显示,1200 条数据的微调可在 5 分钟内完成。
灵活适配场景
支持动态调整适配层(如注意力头、全连接层),并可与其他优化技术结合(如混合精度训练、梯度检查点)。
效果稳定
通过控制低秩矩阵的秩(r)和缩放因子(alpha),平衡模型容量与过拟合风险。实验表明,LORA 微调后模型在特定任务上的准确率接近全参数微调。
LORA 微调的应用场景
领域专业化
在医疗、法律等专业领域,通过微调使模型理解行业术语与逻辑(如医学问答、法律条文解析)。
个性化对话生成
构建特定角色风格的对话模型(如模拟"甄嬛体"回复),需构造指令集定义角色背景与语言风格。
低资源环境部署
在边缘设备或算力有限场景下(如笔记本、嵌入式系统),通过 4bits 量化实现轻量级微调。
多任务适配
通过不同 LORA 适配层组合,支持同一模型快速切换不同任务(如翻译、摘要生成)。
LoRA 在以下几个场景中表现出色:
1 模型微调
在深度学习中,模型微调(Fine-tuning)是将预训练模型应用于新任务的关键步骤。传统的微调方法需要更新大量的模型参数,资源消耗较大。LoRA 提供了一种更为高效的微调方法,只需要更新少量的低秩矩阵,从而实现快速适应。
2 迁移学习
在迁移学习(Transfer Learning)中,通常需要将一个领域的知识迁移到另一个领域。LoRA 可以通过添加低秩矩阵来实现这种知识迁移,而不需要重新训练整个模型。
3 参数共享
在多任务学习中,LoRA 可以用于不同任务之间的参数共享。通过对共享的权重矩阵应用低秩更新,不同任务可以在不相互干扰的情况下进行学习,从而提高模型的通用性和性能。
LoRA微调性能评估与调优技巧
性能评估指标
评估LoRA微调后的模型性能,通常需要结合任务类型选择合适的指标,并与基线模型(未微调或传统微调)进行对比。
- 任务相关指标:根据微调任务的性质选择,例如:
- 分类任务:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值。
- 生成任务:BLEU、ROUGE、METEOR等自动评估指标,以及人工评估的流畅性、相关性。
- 问答任务:EM(Exact Match,精确匹配)、F1值。
- 效率指标:LoRA的核心优势在于高效,因此需评估其效率表现。
- 参数效率:计算并验证可训练参数占总参数的比例是否显著降低(例如,降至0.1%以下)
- 内存与速度:对比微调过程中的显存占用、训练/推理时间,验证其在资源受限设备上的可行性
- 收敛性评估:监控训练过程中的损失(Loss)和评估指标变化,确保训练稳定且收敛,避免过拟合或欠拟合。
调优技巧
LoRA微调的性能高度依赖于超参数配置和策略选择,以下是一些核心调优技巧。
-
核心超参数调优:
- 秩(r):这是LoRA中最关键的参数,决定了适配器矩阵的维度和模型容量。r值过小可能导致表达能力不足,过大则失去参数高效的优势。通常从较小值(如8、16)开始尝试,根据任务复杂度和性能表现进行调整。
- 缩放系数(alpha):通常与r成比例设置,常见做法是将alpha设为r的2倍(如r=16, alpha=32)。alpha控制着LoRA适配器对原始权重的更新幅度
- 目标模块(target_modules):并非所有层都需要添加LoRA。优先在注意力机制的q_proj和v_proj层添加,这对模型"关注什么"影响最大。对于更复杂任务,可扩展至MLP层的up_proj、down_proj等。
-
进阶LoRA变体:
- QLoRA:当显存有限时,采用QLoRA将基础模型量化为4-bit精度,同时保持LoRA适配器为全精度,可在消费级显卡上高效微调大模型。
- LoRA+:发现LoRA中的A矩阵和B矩阵重要性不同,为A矩阵设置比B矩阵高10-100倍的学习率,可使训练更稳定、收敛更快。
- AdaLoRA:动态地为模型的不同层分配不同的秩(r),智能地分配"注意力预算",在相同总参数量下可获得更优性能。
-
训练策略优化:
- 学习率:LoRA微调通常使用比全参数微调更高的学习率。结合LoRA+等技巧进行差异化学习率设置是重要方向。
- 正则化:适当使用lora_dropout(如0.05)可以防止过拟合
- 数据质量:确保训练数据与目标任务高度相关且质量高,这是性能提升的基础。
LoRA微调的局限与未来展望
LORA 虽然好用,但也不是万能的:
- 效果有限: 某些复杂任务上,LORA 可能不如全参数微调。
- 超参数麻烦: 比如秩®的选择,太小效果不好,太大参数又多,需要试错。
- 位置选择: LORA 加在哪些层效果最好,靠经验或实验。LoRA 主要适用于线性层的优化,对于更复杂的非线性层或其他特定类型的层,其效果可能需要进一步探索。
- 适用性限制:LoRA 主要适用于预训练模型的微调,对于从头训练的新模型,LoRA 的优势可能不明显。
为了改进这些问题,出现了 LORA+、DORA 等升级版性能更强,适应性更好。
LoRA 作为一种新兴的模型优化技术,展示了其在大规模预训练模型上的巨大潜力。随着深度学习模型的不断增长和复杂化,LoRA 提供了一种高效且可扩展的解决方案,特别是在资源有限的环境下。未来,LoRA 有望在更多的应用领域中得到广泛采用,并进一步推动深度学习技术的发展。
QLoRA 参数微调
QLoRA(Quantized Low-Rank Adaptation)是一种高效的参数微调方法,它结合了4-bit量化和LoRA技术,能够在消费级GPU上微调大型语言模型,同时显著降低显存需求。其核心思想是在量化后的模型权重上应用低秩适配器,仅训练少量新增参数即可达到接近全参数微调的效果。
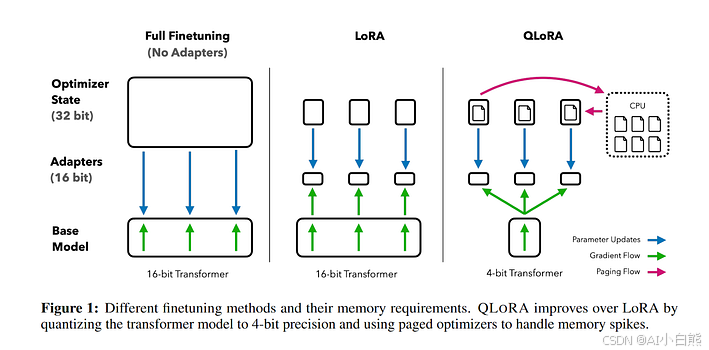
LoRA 和 QLoRA 都是参数高效微调(PEFT)技术,它们的核心思想都是冻结大部分预训练模型参数,只训练一小部分新增的"适配器"(adapter)参数。这样做的好处是显著减少了训练所需的计算量和显存占用。
尽管它们都基于相同的核心思想,但在具体微调方法上存在一个关键区别:QLoRA 在 LoRA 的基础上引入了量化技术。
LoRA 的微调方法
LoRA 的核心思想是低秩分解(Low-Rank Decomposition)。
- 冻结预训练模型:在微调开始时,原始的LLM(比如 LLaMA、GPT 等)所有参数都被冻结,不再进行更新。
- 插入适配器:在模型的 Transformer 模块中,LoRA 会在权重矩阵 W0 旁边添加两个小的、可训练的矩阵,通常称为 A 和 B。这两个矩阵的乘积 AB 构成了对原始权重矩阵的"增量更新" ΔW。
- 参数训练:在微调过程中,LoRA 只会训练这两个小矩阵 A 和 B 的参数,而原始的 W0 矩阵保持不变。
- 模型合并与推理:训练完成后,LoRA 适配器可以与原始模型分离,也可以将其参数合并到原始模型中。在推理时,通常会将 W0+BA 合并为一个新的权重矩阵,从而实现与全量微调相同的推理速度,并且不增加额外的延迟。
这种方法大大减少了需要训练的参数量,将原本可能需要数十亿参数的训练任务,压缩到只需训练几百万参数。
QLoRA 的微调方法
QLoRA(Quantized LoRA)可以被理解为 LoRA 的一种优化实现,它在 LoRA 的基础上增加了量化这一关键步骤。
- 4-bit 量化:QLoRA 首先将整个预训练模型从常规的 16-bit 浮点数(FP16 或 BF16)量化为 4-bit NormalFloat(NF4)数据类型。这个量化过程显著减小了模型的存储和显存占用。
- 冻结量化后的模型:与 LoRA 类似,量化后的预训练模型参数也被冻结,不参与训练。
- 插入适配器:同样地,QLoRA 也会在模型中插入 LoRA 适配器(矩阵 A 和 B)。
- 混合精度训练:这是 QLoRA 的核心创新点之一。尽管冻结的模型是 4-bit 的,但在前向和反向传播计算时,QLoRA 会将 4-bit 参数动态反量化(dequantize)回 16-bit 浮点数进行计算,以保持精度。但需要注意的是,只有 LoRA 适配器(A 和 B)是在 16-bit 精度下进行训练和梯度更新。
- 双量化(Double Quantization):QLoRA 还引入了一种额外的优化,即对量化常数进行再次量化,进一步节省了显存。
核心参数详解
- r(秩):决定低秩矩阵的维度,是影响模型容量的最关键变量。r值越大,模型表达能力越强,但训练开销也越高。在QLoRA中,由于模型已被量化,适配器需要承担更多适应工作,因此通常需要比标准LoRA更高的r值。例如,标准LoRA中使用r=16的任务,在QLoRA中可能需要r=32才能达到相近效果。常见范围为8到64。
- lora_alpha(缩放因子):控制LoRA适配器对模型输出的影响强度。实践中,通常将alpha设置为r的两倍左右(例如r=32时,alpha=64),以通过公式output = W + (B×A)×(alpha/r)稳定适应强度。
- target_modules(目标模块):指定LoRA适配器应用到模型的哪些层。最常见的是应用于所有注意力层的查询(q)和键(k)投影矩阵。对于需要注入新知识或更复杂适配的任务,可扩展至价值投影(v)、输出投影(o)甚至前馈网络(ffn)层。
- dropout:作为正则化手段,防止在少量数据上过拟合。取值通常在0到0.5之间。QLoRA训练中,适度启用(如0.1--0.2)往往能提升泛化能力,但过高会阻碍学习。
调参建议
- 首要关注r值:它对效果影响最大,建议从较高值(如32)开始尝试。
- 学习率:QLoRA模块的学习率可设得比全参数微调更高,1e-4到3e-4是常见范围。若loss不下降,优先检查学习率是否过低。
- 使用预热:建议设置3%--5%的预热步数,帮助模型稳定收敛。
- 参考模板:可使用如LLaMA-Factory Online等集成化平台,其内置了经过验证的QLoRA参数模板,可直接套用,加速迭代。
面临的问题与解决方法
QLoRA(Quantized Low-Rank Adaptation)作为一种高效的低秩适配微调技术,通过4位量化和分页优化等手段显著降低了显存占用,但其在实际应用中仍面临一些关键挑战。以下是QLoRA面临的主要问题及对应的解决方法:
-
显存占用仍较高:尽管QLoRA通过量化基座模型和LoRA适配器大幅降低了显存需求,但在微调大型模型(如14B参数以上)时,优化器状态(如AdamW的动量和方差)仍可能占用大量显存,导致训练无法进行。
- 解决方法:采用分页优化器(Paged Optimizer),将优化器状态分页存储在CPU内存中,并按需加载到GPU,有效缓解了显存峰值压力。
-
量化带来的精度损失:将基座模型权重从16位浮点(如bf16)量化为4位,会引入信息损失,可能影响模型最终性能。
- 解决方法:引入4位NormalFloat(NF4)量化格式,该格式基于权重近似正态分布的特性设计,而非均匀量化,在权重密集区域(如0附近)提供更高精度,从而在4位下最大程度保留模型信息。
-
量化常数的存储开销:在块量化过程中,每个量化块都需要存储缩放因子(scale),这些缩放因子本身使用FP16/FP32存储,会抵消部分量化收益。
- 解决方法:采用双重量化(Double Quantization)技术,即对量化后的权重(code)进行第一层量化,再对缩放因子(scale)本身进行第二层8位量化,从而进一步压缩存储开销。
-
训练速度下降:量化和去量化操作增加了计算开销,导致训练时间比标准LoRA更长。
- 解决方法:通过仅训练LoRA适配器参数(冻结量化后的基座模型),并结合高效的量化库(如bitsandbytes),在保持性能的同时优化计算流程。
-
优化器内存瓶颈:即使使用LoRA,AdamW等优化器仍需为每个可训练参数存储额外的动量和方差,内存占用依然可观。
- 解决方法:可考虑使用SGD优化器,因其无需存储额外的移动平均值,在LoRA框架下能进一步降低显存占用(尽管收敛速度可能较慢)。