在上一期博客中,我们介绍了如何进行lora训练,
LLM语言模型Lora微调
本期我们介绍如何合并训练后的模型
训练后的模型
使用perft训练后,lora模型和基础模型是两个safetenser文件,
这是lora的文件:

这是基础模型文件:
合并lora文件
使用perft可以直接合并lora和基础模型,形成一个safetenser文件
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
output_path = "./lora_adapter_merge"
# 加载原下载路径的tokenizer和model
tokenizer = AutoTokenizer.from_pretrained("./Qwen/Qwen3-1___7B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./Qwen/Qwen3-1___7B", device_map="auto", torch_dtype=torch.bfloat16)
# 加载lora模型
model = PeftModel.from_pretrained(model, model_id="./lora_adapter/")
print("Applying the LoRA")
model = model.merge_and_unload()
print(f"Saving the target model to {output_path}")
model.save_pretrained(output_path)
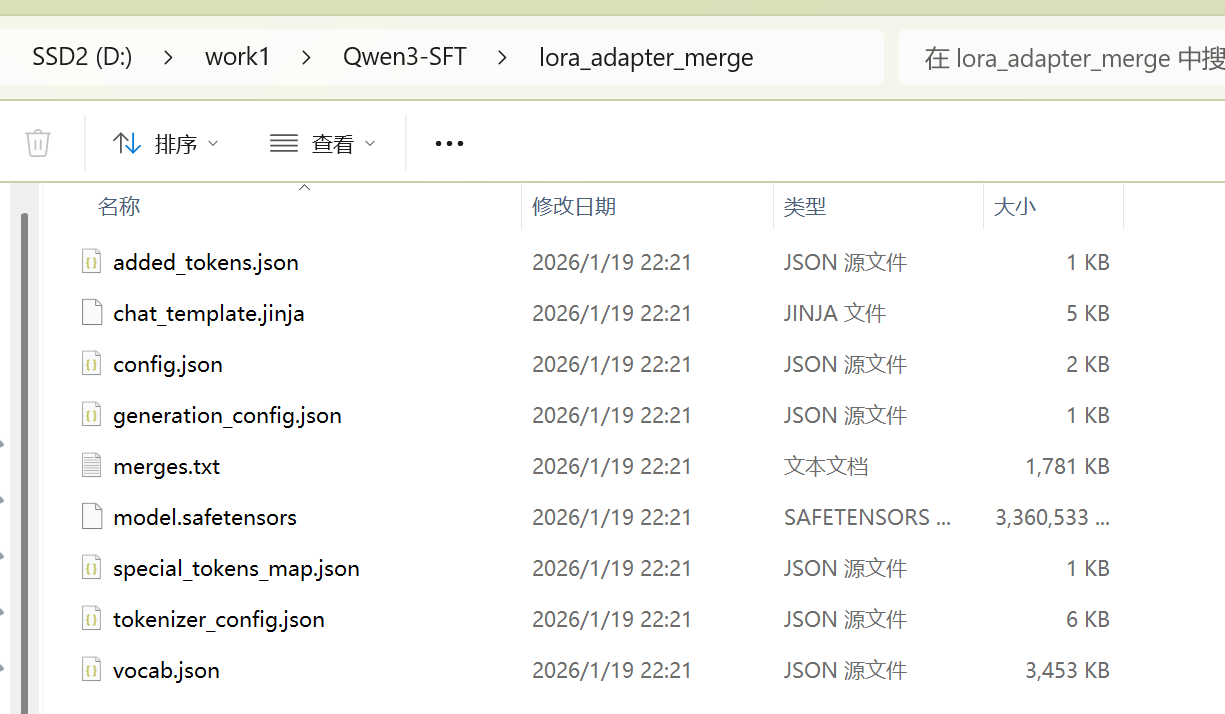
tokenizer.save_pretrained(output_path)下面就是合并后的输出,
合并结果
接下来是形成gguf文件
安装llamacpp
要合并成GGUF需要用到lammacpp这个库.
下载官方库
llama官方库位置:
官方库
我们直接下载zip文件到本地,
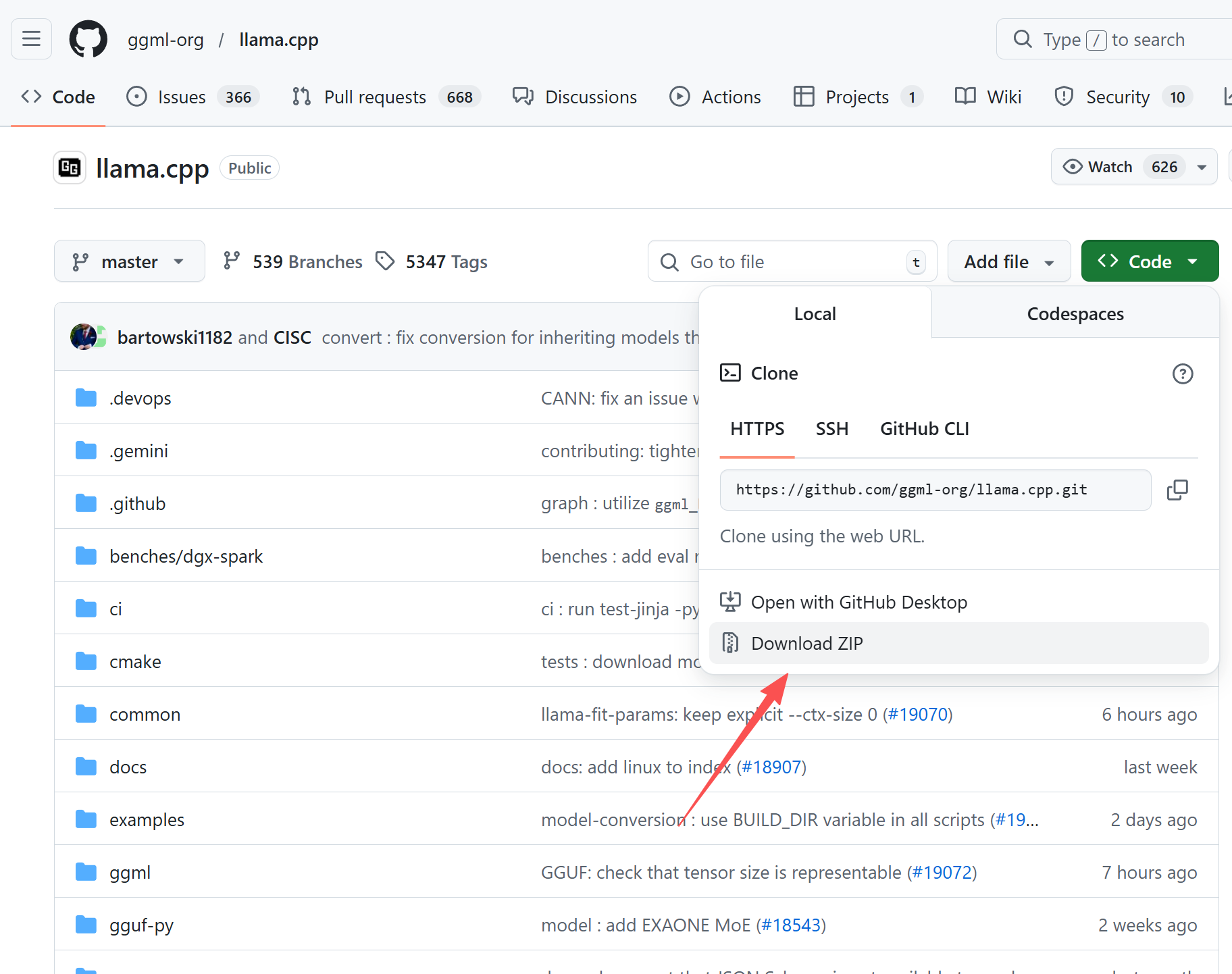
下载到本地之后进行解压成一个目录
准备python虚拟环境
从最佳实践来看最好在一个虚拟python环境中安装依赖,避免污染全局环境.
如何安装python虚拟环境请参考这篇文章里面的相关步骤
虚拟环境连接,需要忽略安装VLLM的这个步骤
安装依赖.
llamacpp自带的依赖文件里面会强制指定torch的版本,这个torch版本回合电脑本地的环境产生冲突,我们可以打开requirements这个文件夹,然后打开requirements-convert_hf_to_gguf,注释掉里面的torch依赖,自己手动在虚拟环境中安装pytorch依赖
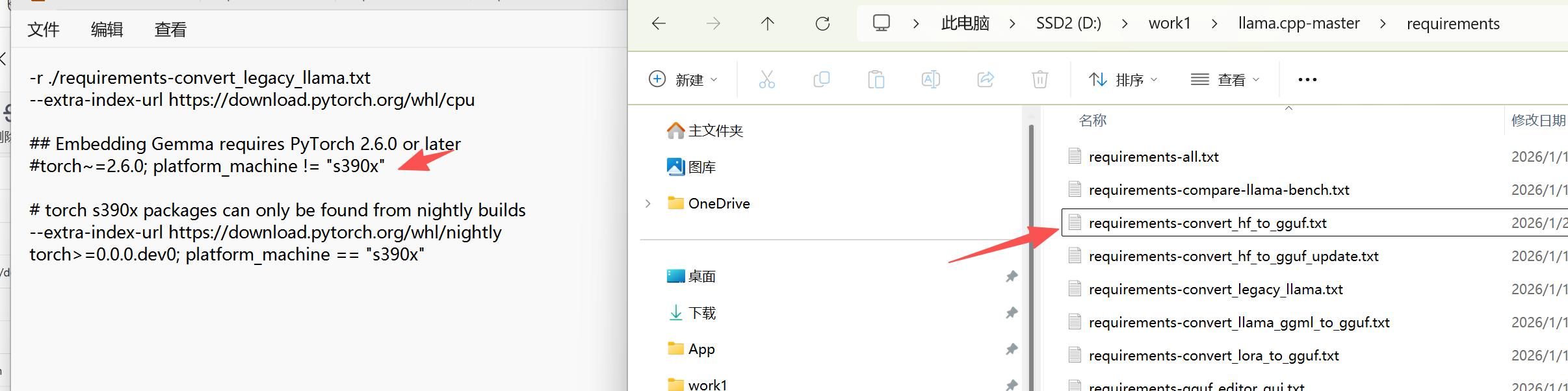
安装pytorch需要匹配自己的机器的显卡硬件,显卡驱动,英伟达还要匹配cuda版本,准备pytorch环境也是一个复杂的工作.
最后
在llamacpp的根目录执行下方的命令安装依赖
bash
pip install -r requirements.txt转换
bash
python llama.cpp/convert_hf_to_gguf.py 合并后模型的文件夹 --outtype f16 --verbose --outfile 想要输出的gguf文件文件中的outtype需要根据模型的情况做变更.