之前已经详细介绍了YOLOv8的模型结构(YOLOv8结构详解-CSDN博客)。得益于Ultralytics优秀的代码封装,可以方便快捷地直接下载其仓库代码训练或测试自己的代码。在此处,将介绍如何针对自己的数据集进行优化代码,添加自定义的模块,并训练模型。
一、CoTNet简介
论文:2107.12292
CoTNet是京东AI研究院提出的一种即插即用的自注意力模块,可以直接将ResNet中的卷积换成CoT Block,凭借着其出色的自注意力机制在各种视觉任务上取得性能提升。因此,可以将其代替YOLOv8中的C2f中的bottleneck,为纯卷积组成的YOLOv8提高长距离上下文信息提取能力,从而达到提高检测精度的目的。
大多数的基于Transformer的设计通常直接在二维特征图上计算自注意力矩阵,但是这种基于空间位置中孤立查询键值对的交互,忽略了相邻键之间的上下文关联。
Contexttual Transformer (CoT)通过3✖3卷积对输入键进行上下文编码,然后将其与查询拼接,并通过两个连续的1✖1卷积学习动态多头注意力矩阵,然后将矩阵与输入值相乘,获得动态上下文表征。这种设计充分挖掘了输入键值之间的上下文信息,用以指导动态注意力矩阵的学习,从而增强视觉表征能力。
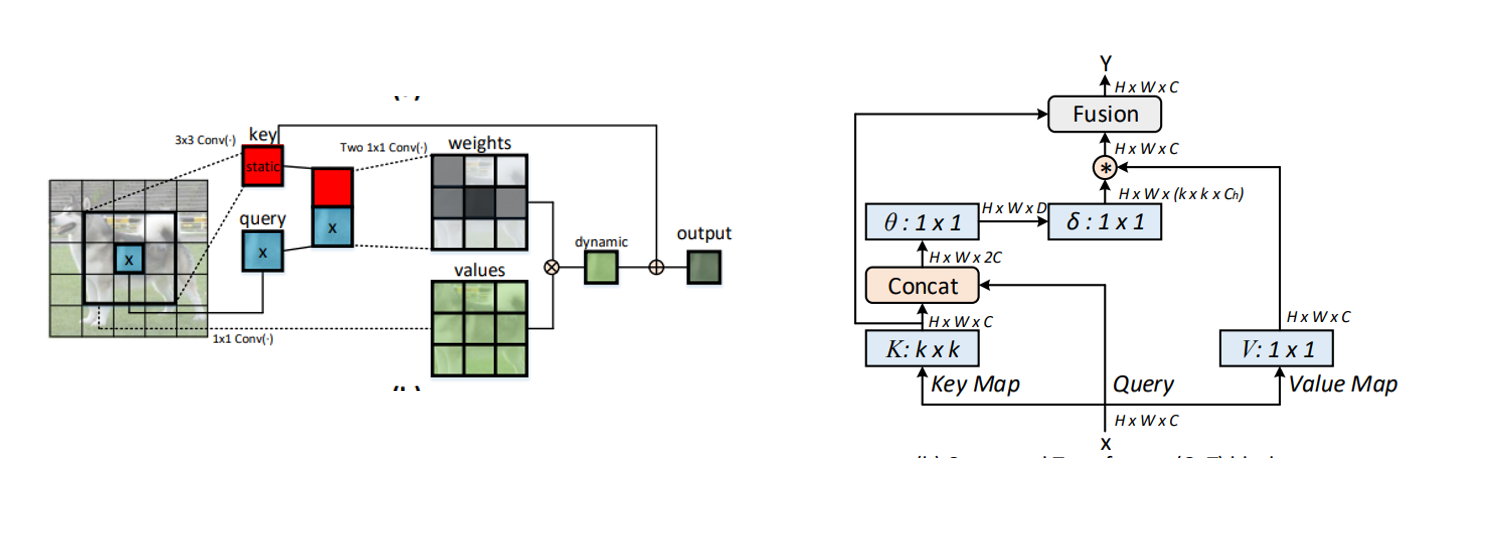
上图是关于CoT Block的设计细节,据此,可以写出CoT的代码来。或者直接参考官方给出的代码,但是官方的稍微有点复杂。(代码地址:GitHub - JDAI-CV/CoTNet: This is an official implementation for "Contextual Transformer Networks for Visual Recognition".)
二、YOLO中添加CoT
在添加代码之前,首先要注意的是下载Ultralytics YOLO时,直接从github上下载,不要使用pip install ultralytics下载仓库,最好保证环境中不要有该库,否则可以代码直接待用该库,没有跑我们修改的项目,将其设置为可编辑的代码有些麻烦。
1、在ultralytics/nn/modules/block.py中加入我们的自定义模块:C2f_CoT。
python
#ultralytics/nn/modules/block.py
class CoTNetLayer(nn.Module):
def __init__(self, dim, kernel_size):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.key_embed = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=kernel_size, padding=kernel_size // 2, stride=1, bias=False),
nn.BatchNorm2d(dim),
nn.ReLU(inplace=True)
)
self.value_embed = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(dim)
)
factor = 4
self.attention_embed = nn.Sequential(
nn.Conv2d(2 * dim, 2 * dim // factor, kernel_size=1, bias=False),
nn.BatchNorm2d(2 * dim // factor),
nn.ReLU(inplace=True),
nn.Conv2d(2 * dim // factor, kernel_size * kernel_size * dim, kernel_size=1, stride=1)
)
def forward(self, x):
bs, c, h, w = x.shape
k1 = self.key_embed(x) # shape:bs,c,h,w
v = self.value_embed(x).flatten(2) # shape: bs, c, h*w
y = torch.cat([k1, x], dim=1)
att = self.attention_embed(y) # shape:bs, c*k*k, h, w
att = att.view(bs, c, self.kernel_size * self.kernel_size, h, w)
att = att.mean(2, keepdim=False) # shape:bs, c, h, w
att = att.flatten(2) # shape: bs, c, h*w
k2 = F.softmax(att, dim=-1) * v
k2 = k2.view(bs, c, h, w)
return k1 + k2
class C2f_CoT(nn.Module):
"""C2f module with CoTNetLayer()."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(CoTNetLayer(self.c, 3) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f_CoT layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))添加完毕后,同步更新文件最上方的__all__,加入C2f_CoT。
python
__all__ = ('DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3', 'C2f', 'C3x', 'C3TR', 'C3Ghost',
'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'RepC3', 'C2f_CoT')由于YOLOv8是通过yaml文件调用不同的模块,组成完整的模型架构的。因此,在修改yaml文件之前,还需要在初始化文件init.py和task.py中加入C2f_CoT模块,否则是找不到我们的自定义模块的。
2、在__init__.py里,在from .block里加入导入C2f_CoT,并且__all__里添加模块的公开接口声明。
python
#ultralytics/nn/modules/__init__.py
from .block import (C1, C2, C3, C3TR, DFL, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, GhostBottleneck,
HGBlock, HGStem, Proto, RepC3, C2f_CoT)
from .conv import (CBAM, ChannelAttention, Concat, Conv, Conv2, ConvTranspose, DWConv, DWConvTranspose2d, Focus,
GhostConv, LightConv, RepConv, SpatialAttention)
from .head import Classify, Detect, Pose, RTDETRDecoder, Segment
from .transformer import (AIFI, MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer, LayerNorm2d,
MLPBlock, MSDeformAttn, TransformerBlock, TransformerEncoderLayer, TransformerLayer)
__all__ = ('Conv', 'Conv2', 'LightConv', 'RepConv', 'DWConv', 'DWConvTranspose2d', 'ConvTranspose', 'Focus',
'GhostConv', 'ChannelAttention', 'SpatialAttention', 'CBAM', 'Concat', 'TransformerLayer',
'TransformerBlock', 'MLPBlock', 'LayerNorm2d', 'DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3',
'C2f', 'C3x', 'C3TR', 'C3Ghost', 'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'Detect',
'Segment', 'Pose', 'Classify', 'TransformerEncoderLayer', 'RepC3', 'RTDETRDecoder', 'AIFI',
'DeformableTransformerDecoder', 'DeformableTransformerDecoderLayer', 'MSDeformAttn', 'MLP', 'C2f_CoT')3、找到task.py文件,添加导入C2f_CoT。然后找到parse_model函数,仿照C2f的写法,加入C2f_CoT,如下方所示。其中c1、c2分别是卷积的输入输出通道数,输入通道数直接在yaml文件去-1层,也就是上一层的,而c2取的是args0,也就是yaml文件中的args列表中的第一个元素,后面会在yaml设计上会再次解释这个。
python
#ultralytics/nn/tasks.py
from ultralytics.nn.modules import (AIFI, C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x,
Classify, Concat, Conv, Conv2, ConvTranspose, Detect, DWConv, DWConvTranspose2d,
Focus, GhostBottleneck, GhostConv, HGBlock, HGStem, Pose, RepC3, RepConv,
RTDETRDecoder, Segment, C2f_CoT)
#....
#def parse_model(d, ch, verbose=True)
#...
if m in (C2f_CoT, Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (C2f_CoT, BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 14、最后就是yaml文件的修改了,可以重新创建一个yaml文件,取名为yolov8_c2f_cot.yaml。注意前面的yolo8_不要变,否则训练时也会不能构件完整的新模型结构,不能通过添加n、s、m、l等来区分模型大小。因为yolov8是通过yaml文件名加上正则匹配来判断选择模型大小的。
由于CoT Block里面的卷积使用了分组卷积,所以最终的参数量不大,这里可以将所有的C2f换成我们的C2f_CoT。
这里简单介绍下每一层写法的意义。如- -1, 1, Conv, \[64, 3, 2] 第一个-1表示该层与上一层相连,1代表该模块重复一次,Con是模块的名字,后面列表里面的参数是定义Conv类时的初始化参数,第一个c1,也就是输入通道数不算,后面的输出通道数64,卷积核大小为3,步长为2。需要注意的是,这里只是替换了原有的C2f模块,没有增加新的模块,例如如果加入新的注意力模块时,意味着backbone的层数增加了(从0开始),后面head的部分的Concat和检测头的from层数可能发生变化。
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_CoT, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_CoT, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_CoT, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_CoT, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_CoT, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_CoT, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_CoT, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_CoT, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)三、训练新模型
最后可以创建一个train.py文件用于训练,可以选择是否加载预训练权重,会自动匹配预训练权重和我们的模型结构模块形状是否相同,跳过其不同的权重加载。
python
from ultralytics import YOLO
model = YOLO("yolov8n_c2f_cot.yaml")
model.load("yolov8n.pt")
model.train(data="coco128.yaml", epochs=3)