C语言知识点整理
- 一、变量和指针
- 二、sizeof和关键字
- 三、struct
- 四、变量赋值
- 五、通过指针赋值
- 六、上午答疑
- 七、结构体指针_函数指针
- 八、下午答疑_关于指针
- 九、什么是链表
- 十、链表的插入操作
- 十一、链表的删除操作
- 十二、ARM架构与汇编的初步体验
- 十三、全局变量的初始化与栈的引入
-
- [1 有初始值的全局变量,如何进行初始化?:](#1 有初始值的全局变量,如何进行初始化?:)
- [2 无初始值或者初始值为0的全局变量,如何进行初始化?](#2 无初始值或者初始值为0的全局变量,如何进行初始化?)
- [3 引入栈的概念](#3 引入栈的概念)
- 十四、局部变量的初始化
韦东山C语言知识点学习。 B站链接。
简单记。
一、变量和指针
主函数中定义变量,但未使用。编译,会提示"有变量 定义但未使用",查看map文件,会找不到对应的标识符identity。
即表明此变量被编译器优化掉。
加上关键字volatile,易变的,则不会被优化掉。
main也是一个函数,在其中定义的变量是局部变量,存在栈stack中。
map文件中体现的是"全局变量"。
map文件中会体现栈stack的起始位置,和长度,但是不会体现其中的变量。栈中的变量是随用随销的。
CPU相当于内核,RAM存变量,Flash存程序代码。
指针变量,也是变量,也存在内存中。
指针操作的是地址,指针占用的空间,应该能包含全部的地址范围。即CPU寻址的最大范围。
一般32位的CPU,寻址范围值2^32 - 1,即0x0000 0000 -- 0xFFFF FFFF。所以指针变量的长度为4个字节。
在物理层面,32位的CPU,地址线为32根,即0-31。
32位的CPU,不管什么类型的指针变量,占用空间的长度都是4个字节。
指针变量操作的是地址,所以指针变量的长度应该能把所有的地址包含进来。
而变量占用的长度,与变量类型有关。

只读的量为常量,不是变量。
一些只读的"常量",例如define的宏定义,switch中的case值,常量都放在"FLASH "中。有时编译器为了加快读的速度,也将常量放在RAM内存中,DATA段。
后半句话是对的。
加const关键字,用const定义变量,其变量的值在运行过程中不能被修改。应该会放在FALSH中(应该验证一下)。
二、sizeof和关键字

类比
c
char a;
int b;要获取a b占用的字节,直接将变量名输入到sizeof
c
sizeof(a);
sizeof(b);那么要获取指针的长度,也是将指针变量名输入进入。
c
char * p; //认为char*为指向char的指针类型 后面是该指针类型的变量名p
int * p1;
//即,查找指针变量的长度,应该用
sizeof(p);
sizeof(p1);
//如果是
sizeof(*p);
sizeof(*p1);
//含义为查找类型对应的长度 即char 1字节 int 4字节

视频中,工程为STM32的工程,点击编译后,没有下载,直接点击debug,使用view的uart1,就可以查看串口printf输出的内容。
工程中没有对STM32的配置,就是简单的C,前面头文件,后面main函数。
只加一个
这个函数。
在keil中使用C语言,可以查一下。也可以看下老师的工程,看看这个函数是什么作用。
不清除是什么原理。
应该是电脑连着仿真器,直接点击debug就可以运行了,这个函数可能是将所有的函数集中封装起来了。
不下载程序,直接点击debug,应该也不行吧,还没有理解老师视频中的操作。


volatile:
从程序运行的角度i = 1;没有必要,所以编译器会将此语句给优化掉。
但是代码作者想i = 1;有特殊用处,所以加volatile,不让编译器优化i这个变量。

另一个角度:
变量char i = 0;肯定在内存RAM中,CPU在使用变量的时候,会执行读-修改-写,先将变量读到CPU内部寄存器,再修改这个值,然后再写回到RAM内存。
如果变量i用作for循环
c
for(i = 0;i < 100;i ++)
{
}不加volatile,则CPU读取这个值之后,后续执行i++(修改变量),只会修改CPU寄存器中缓存(这也是CPU几级缓存的概念 为什么叫缓存)的i值,并不会去实际修改内存RAM中的值。CPU只来利用缓存中的数据,执行速度非常快。
如果加volatile,则CPU执行代码时,会将执行完i++;之后(修改变量),会将修改后的值,写回到RAM中。这样执行速度相对降低。
CPU缓存一般是SRAM,静态内存。
而RAM内存,一般指DRAM,动态内存。
静态内存SRAM执行速度比动态内存DRAM要快。
实际上,DRAM的执行速度也挺快的,
寄存器也相当于一个"变量",实际含义应该是内存中一个具体的地址,例如0x0000 0002,芯片规定为GPIOA高低电平的寄存器。
当GPIOA0电平为1时,该寄存器的D0为1;当GPIOA0电平为0时,该寄存器的D0为0;
即硬件上,将GPIO某个引脚的电平状态,连接到此地址某一个位置上。
如果定义一个变量在0x0000 0002这个地址,那么变量的D0-D7,分别代表GPIOA0-A7的电平状态。
此部分地址一般在单片机的片内RAM中,例如32为单片机,地址范围是0x0000 0000 --- 0xFFFF FFFF
比如规定一块地址范围0x0000 0000 --- 0x2000 0000作为特殊功能寄存器地址使用
会将"变量"指定地址的方式定义在这块范围,编程时操作某一个寄存器,读或写,就是操作这一块内存。
其它地址空间供用户自定义变量使用。
参考链接
8位和32位单片机的区别
当读GPIO的寄存器"变量"时,如果不使用volitile,则可能会实际读取CPU缓存的数据,而不会实际读取内存RAM中的数据。
会导致读寄存器,而不能反应实际GPIO的状态。
所以寄存器一般加volatile关键字,每次读取GPIO寄存器,从实际的RAM内存中读取,而不是从CPU缓存寄存器中读取。
const:
此关键字修饰的变量,不能被修改,可以放在flash中也可以放在ram中。
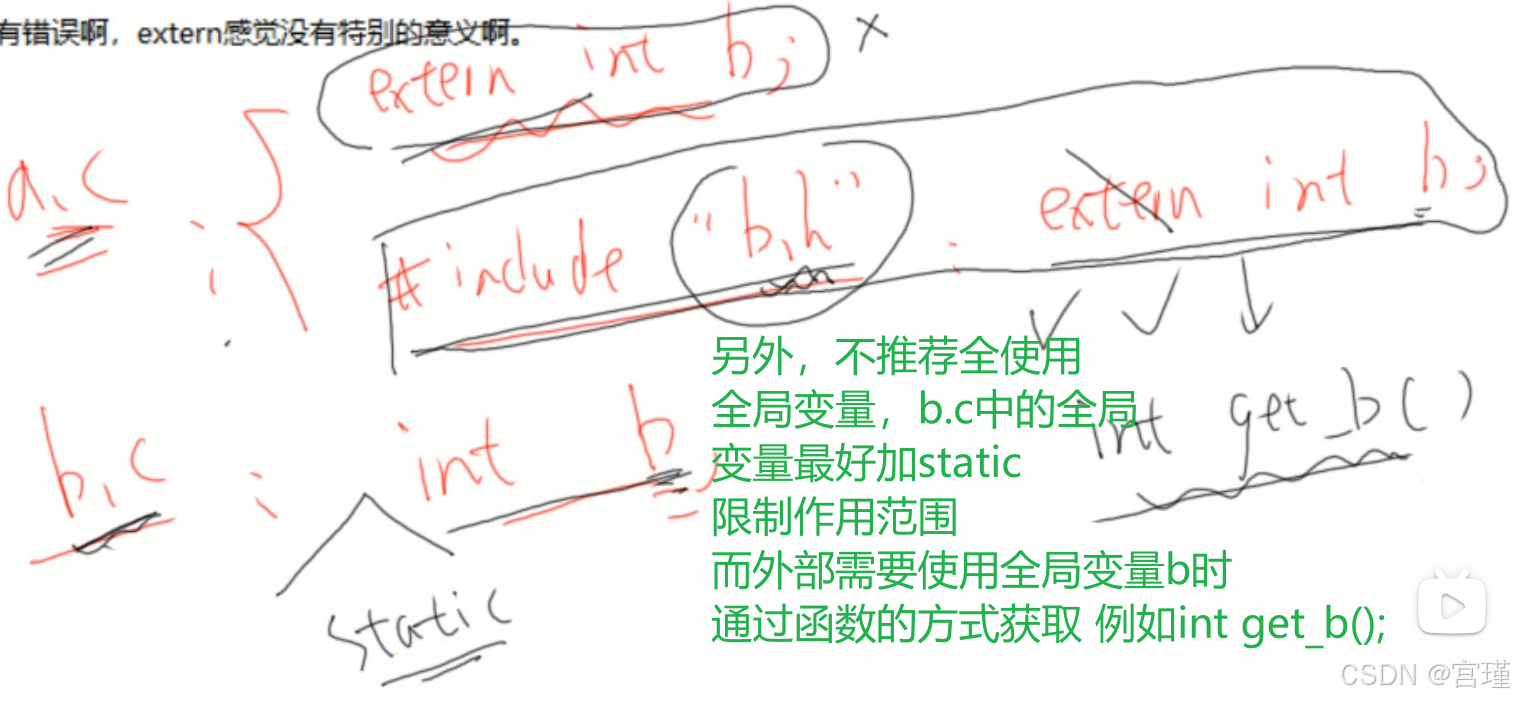
static:
此关键字修饰的变量/函数,作用范围只在c文件内。
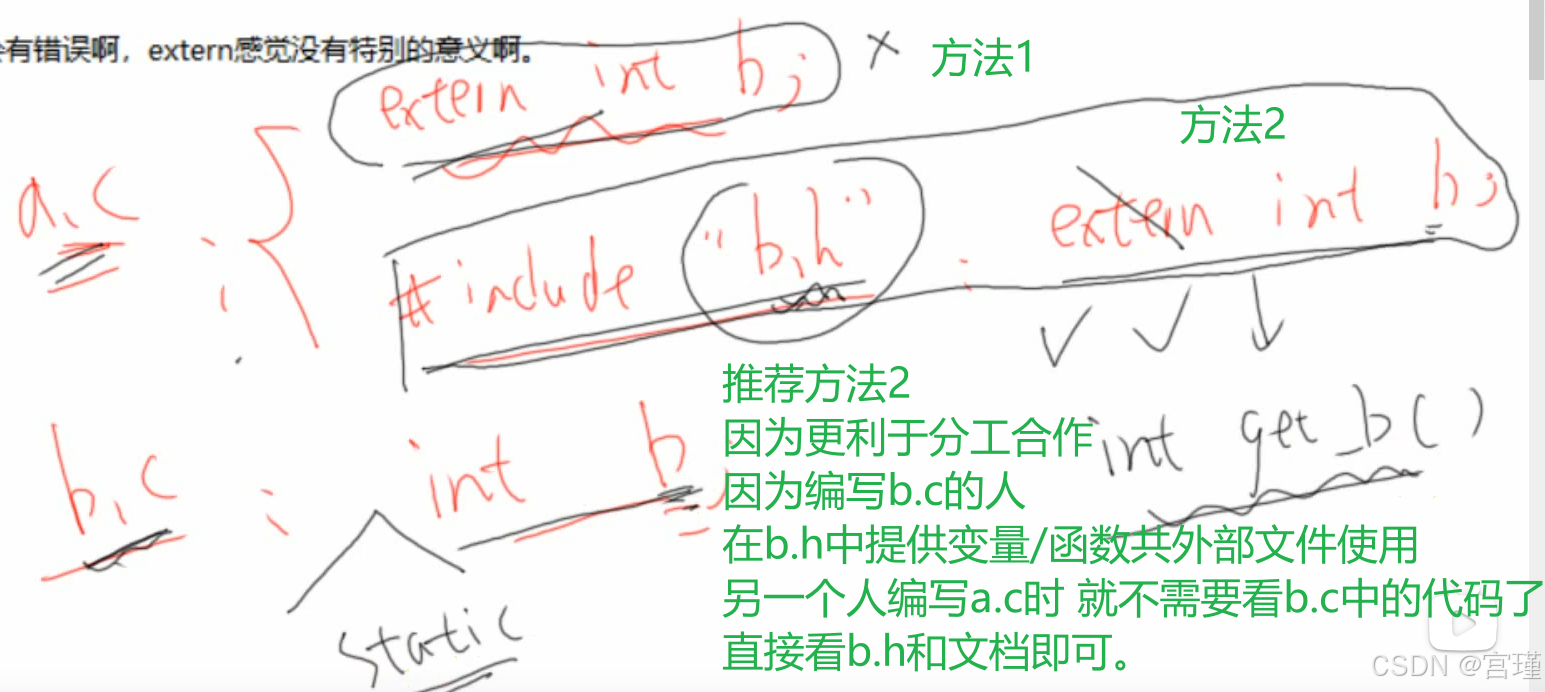
extern:
外部函数或变量。
从汇编的角度理解比较好。
下面图片中的方法,一个是告诉编译器,此变量在外部的c文件中被定义,本c文件可以直接使用,extern放在c中。(用的多)
另一个是告诉编译器,本c文件中的变量,将被外部的c文件使用,extern放在本c对应的h文件中,外部的c文件需要包含此h文件。
需要理解一点汇编和c的编译过程。


__weak:

三、struct

结构体是一种类型,不是变量,不会分配空间,只有变量才占空间。
c
sizeof(struct person); //查看结构体类型的大小(长度)不管指针指向的类型是什么,指针类型的长度永远为4字节(32位系统,与系统的位数有关)
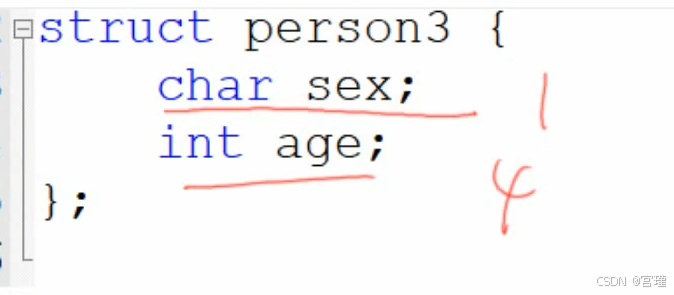
实际为8字节,发生了对齐。
char被扩充为4字节。(不同平台,是否对齐好像不一样,F28377D)

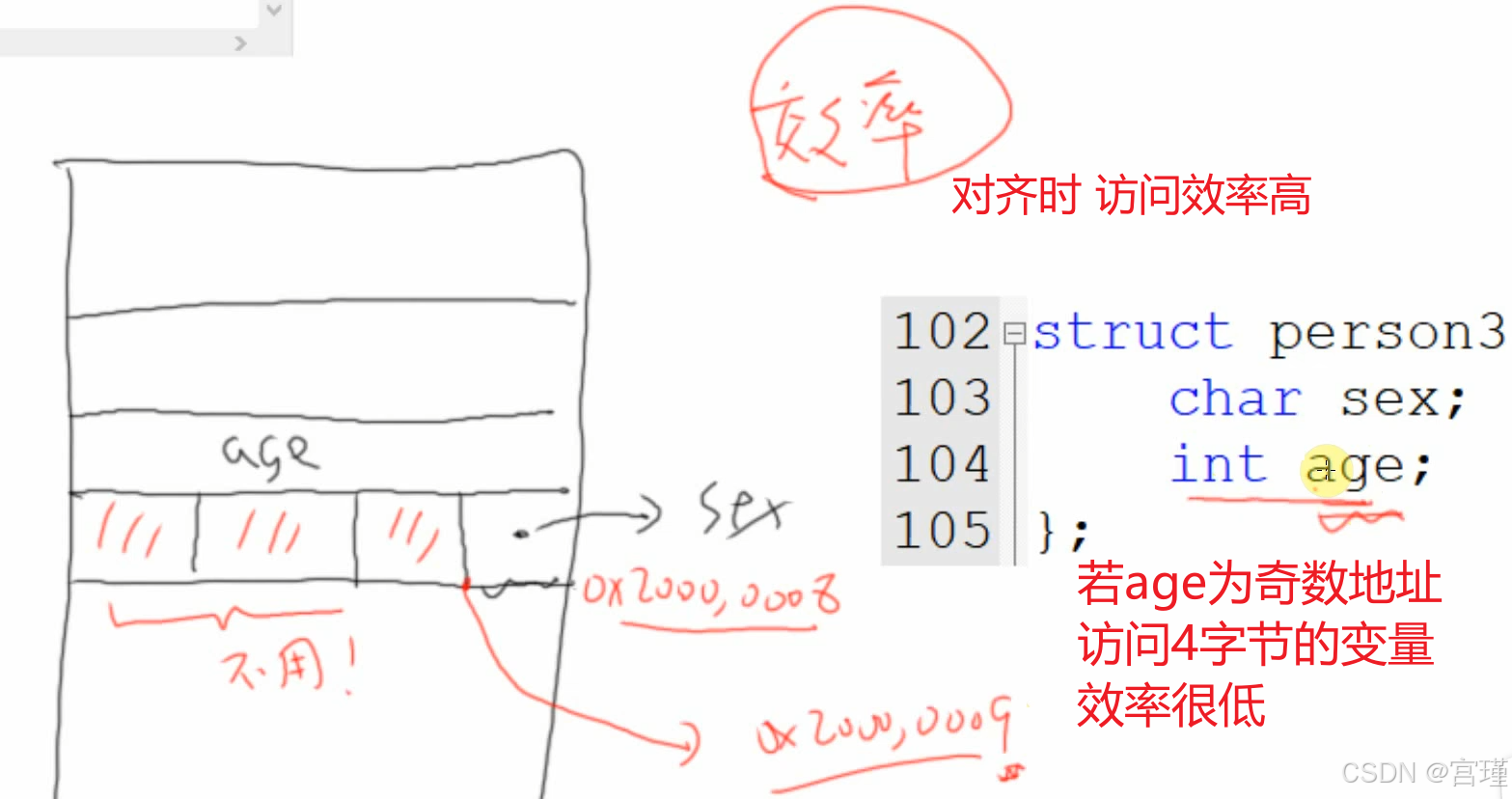

用奇地址访问一个字节,效率也很高
但是用奇数地址访问4字节,效率低,有些硬件平台不支持
具体可以查一下,暂时先这么理解

问题:如果不是结构体,定义char,也是分配4个字节吗?
是的,如果只定义一个char,占用4个字节,如果定义两个char,则两个char占用4个字节,浪费两个。
只不过单独定义char变量,编译器会将其它char变量放一块,看起来像是每个char只分配一个地址。
结构体成员一般在内存上是连续的,所以可以比较明显的看到char被分配了四个字节。
具体可以debug查看,可能不同平台不一样。
四、变量赋值
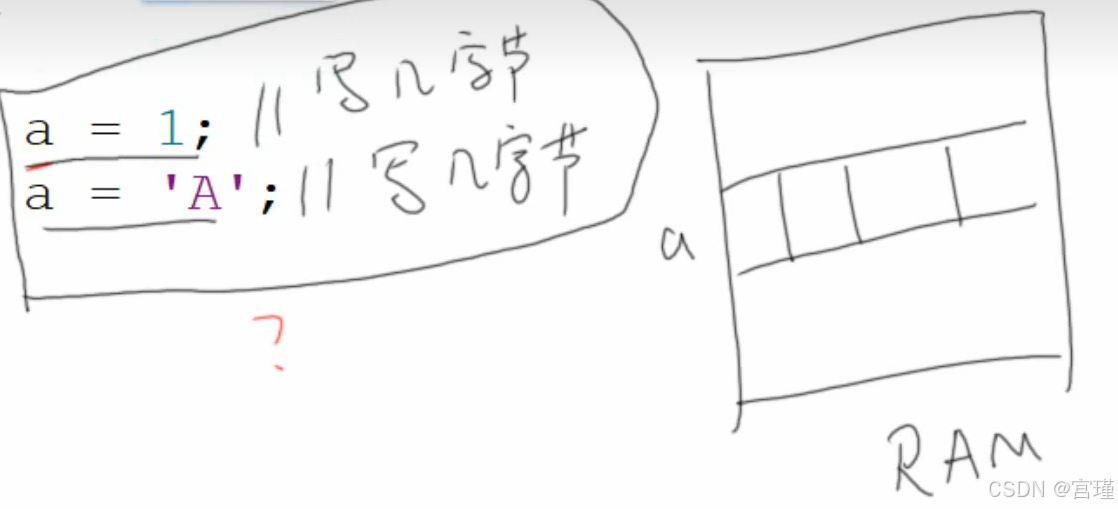
都是4。a是一个类型。
0x0001
0x0041
int a;
给a赋值1 和赋值 2^32 - 1。都是完整的给4个字节赋值。


上面c前面的三个地址,没有使用,所以这样写代码,在此种情况下不会产生什么问题。
如果定义两个char变量,即c前面的一个地址是另一个char变量,这样写代码便会出现问题。

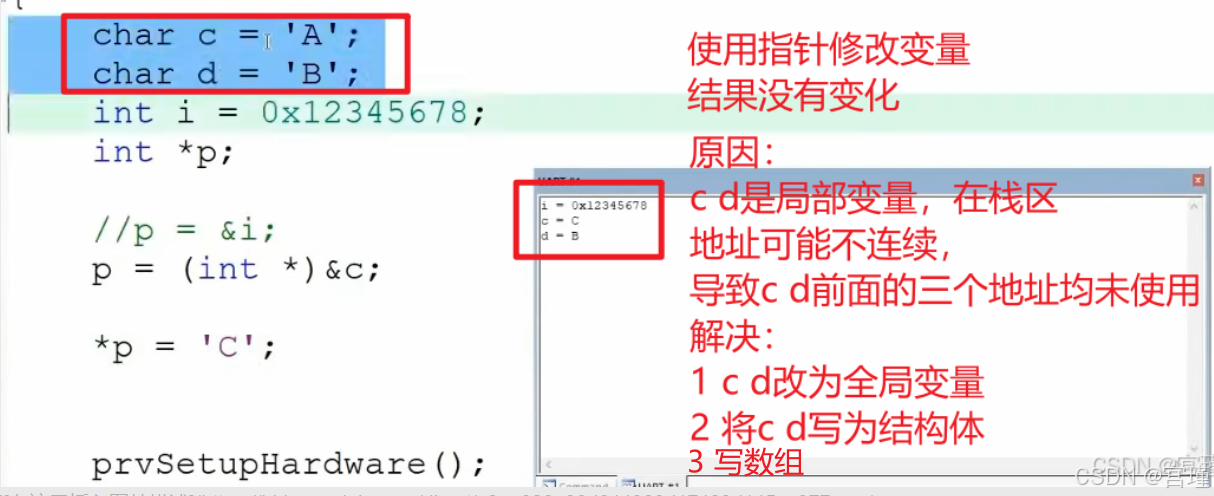



好问题:
如果用*p赋值d,会影响age吗?
如果是四字节操作,感觉会影响的。
实际开发时,发生了内存错误,很难找到原因。
五、通过指针赋值

变量赋值操作和指针操作是同一个含义。
都隐含对地址的操作

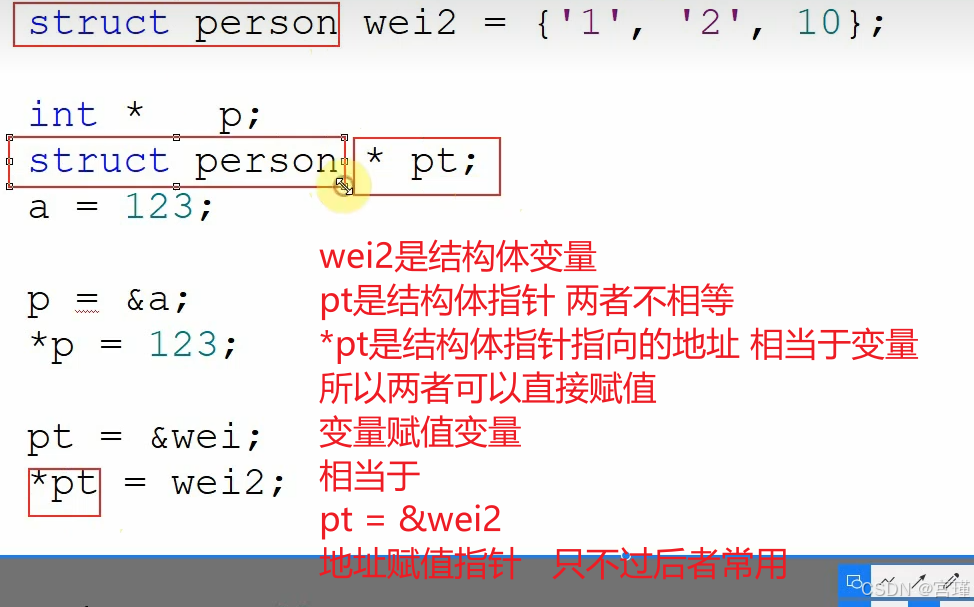
前面的a = 123;
隐含着将123给到a对应的地址。
注意理解指针与变量的"等级"关系。


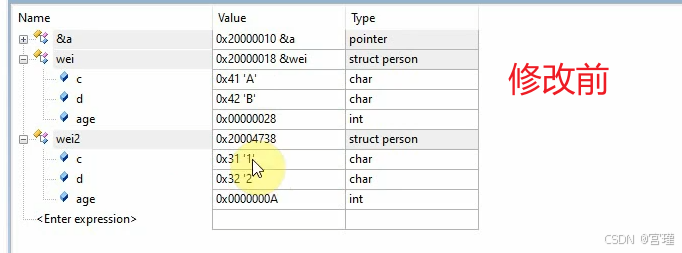
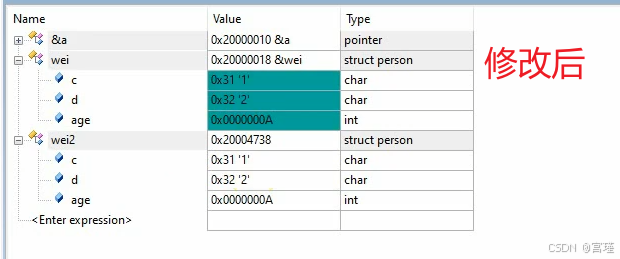
六、上午答疑
之前写代码的时候,用过
*p = 1;这种操作,与上面图片中的代码一样。只不过常用的是 通过指针给普通类型的变量赋值,而上面图片中为通过指针给结构体类型的变量赋值。
两者是类似的。
*p = 1; 星号运算符,为取值运算符,含义为取指针指向地址中的内容,将内容按指针类型解释。

头文件中定义一个变量,如果该头文件被include两次,将会报错:变量重复定义。
Include头文件,相当于将头文件中的内容原封不动的放在include处。
为了避免在最终的hex/bin文件中重复包含,所以一般加条件编译,既能满足c文件编写,又满足生成最后的hex/bin文件。


int类型占4个字节,变量a
假设有一个结构体类型占8个字节,变量b
一个int类型的指针,指向a的地址,因为是int类型,所以将后面4个字节(包含第一个地址)认为成此变量的占用范围。
一个8字节的结构体类型指针,指向b,因为是8个字节,所以将后面8个字节的范围,认为是该结构体变量的占用范围。
所以前面wei2结构体变量赋值的本质,就是将这n个字节,通过指针,全部赋值给了另一个结构体变量wei。
指针类型的作用,就是对首地址往后的n个字节,按指针的类型做出解释。
所以串口发送float时,可以将float做强制指针类型转换,转换为32位的无符号类型,然后再按位与,提取为4个字节,然后再通过串口逐个字节发送。
联合体的作用,与强制指针类型转换的作用相同,本质都是对首地址后面的n个字节做不同的类型解释。
不能通过指针,将一个数组完全赋值给另一个数组数组为同一类型变量的集合,而不是 整个数组为一个数组类型。
七、结构体指针_函数指针
结构体中如何使用指针

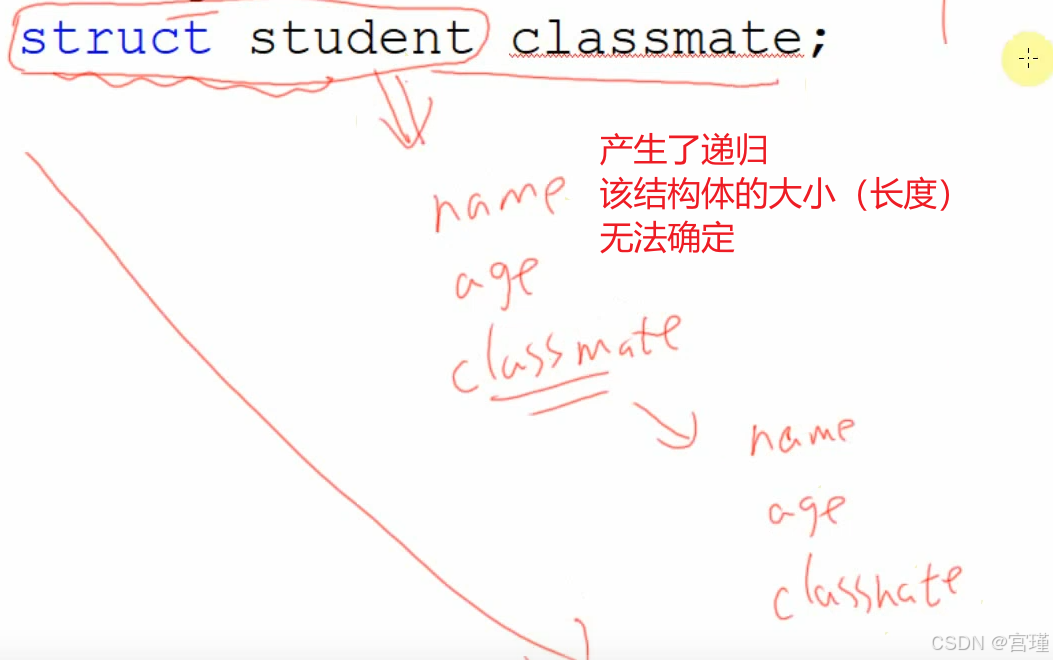
结构体变量中,包含结构体变量本身
不行!!!


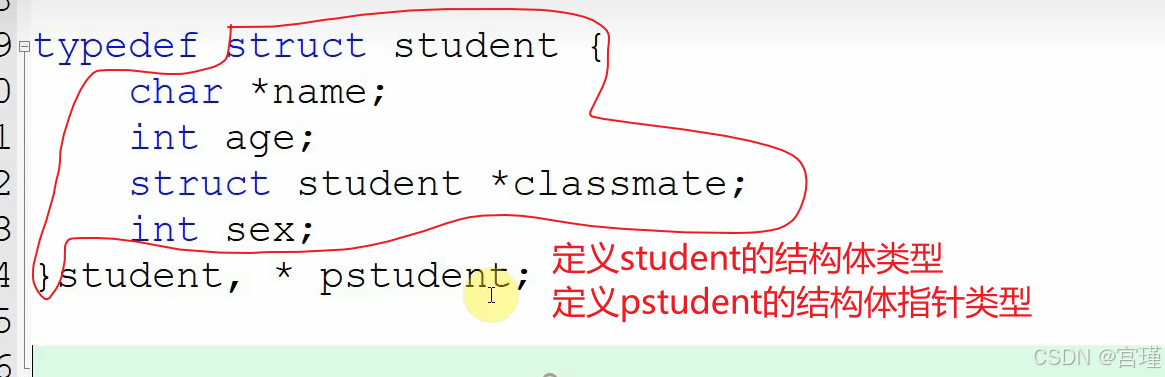

函数指针



所以,如果要定义函数指针,应该将函数名与*星号括号起来。

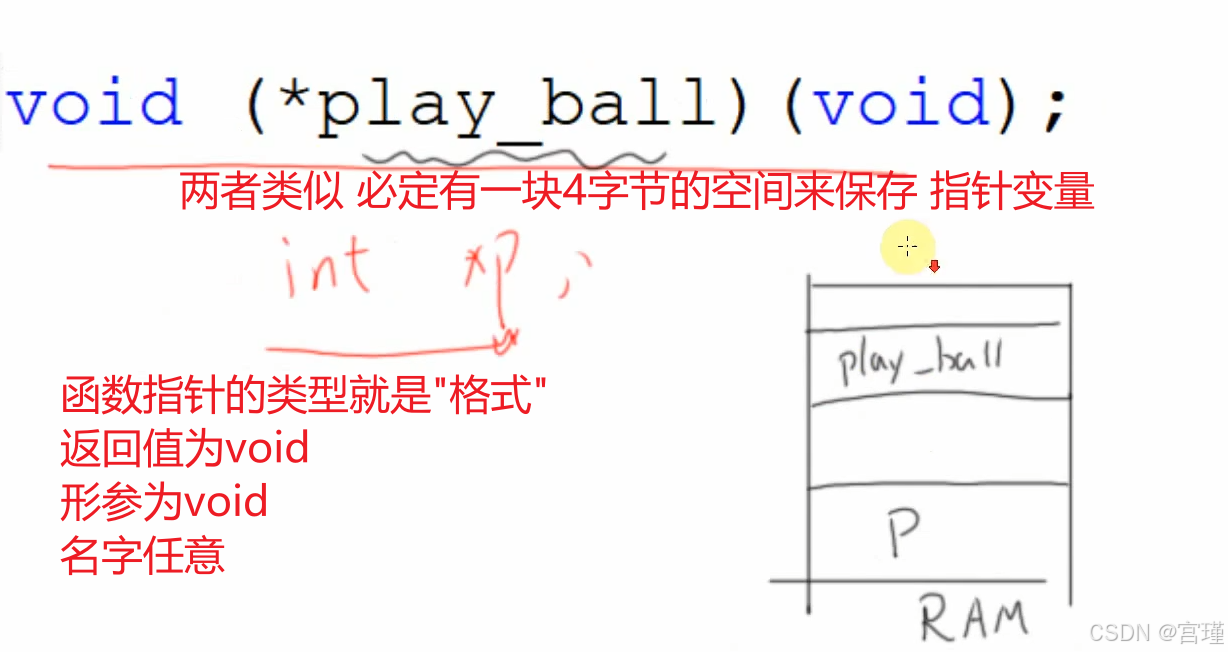
关键点是理解函数指针的定义形式。
推广:
typedef void (*play_ball)(void)实际为为函数指针起别名,可以用play_ball定义函数指针的变量。

给函数指针赋值时,直接将函数名赋值给函数指针即可。
函数名就是地址,所以不用取地址符。
用了也没错。
变量i为变量i的内容。&i为变量的地址。
而函数名,是否加&符,效果都是一样的,都是地址。、
函数指针初始化之后,使用时直接 函数指针名(形参);就当做一个函数用。
CPU会在STACK中为形参开辟空间,然后跳转到真正的函数地址执行。
函数指针通常用作某种模块库封装,方便用户实现功能。
当需要通过判断,决定执行哪一个函数时,改为结构体的形式。



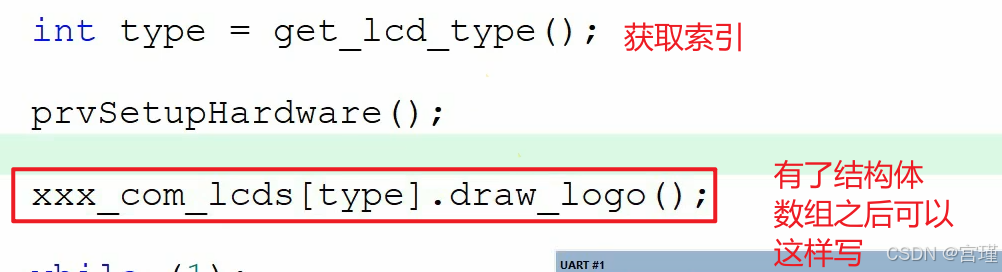
相当于将if逐个判断索引,改为了查表的形式。
常见的查表,是通过索引,返回一个数值,而这个是返回一个函数指针。
实现了通过索引,调用不同函数的功能。
在内存中,相当于:
索引0,函数0地址
索引1,函数1地址
索引2,函数2地址
...
本质就是一个表格,特殊的表格。
使用这种表格的形式,省去了if这样的判断语句,从而会节约硬件资源,代码占用会变小。
函数名就是一个地址,函数代码所在的入口地址。
在程序中调用一个函数,就相当于在汇编中添加call,跳转到函数的地址执行代码,执行完之后,再跳转原来的地方。
指针变量保存的就是一个地址。
函数指针,相当于通过指针预留了一个函数,此函数需要用户定义。
函数指针和函数的使用方法一样,本质上是一段函数代码,其首地址一个函数名,一个是函数指针。
函数指针,就是以指针的方式使用函数。深刻理解这段话。
函数指针的定义方式,与定义普通变量的方式有点差别。见的多了,习惯就好。
注意:函数指针,是一个指针变量,指向了一个函数。准确来说应该是一个函数指针变量。
指向函数的指针变量,简称函数指针。
普通的指针,比如指向char类型的指针变量,最常用,通常只称为指针。
再次封装:
下面这部分,不常用,再封装一次,有点理解不过来了。
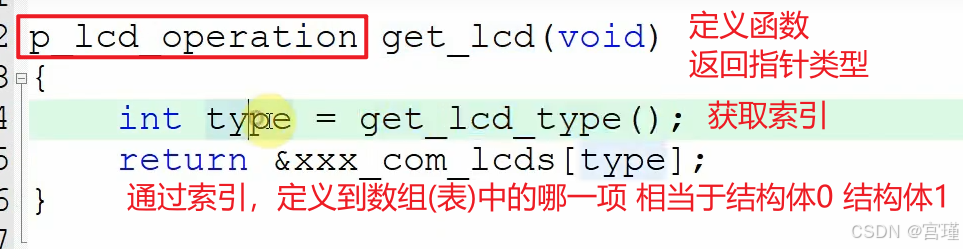
这个return有点高级,返回数组成员的地址,使用了取地址符。
因为函数的返回值类型为指针,所以可以返回地址。
数组元素为结构体类型。
不常见。
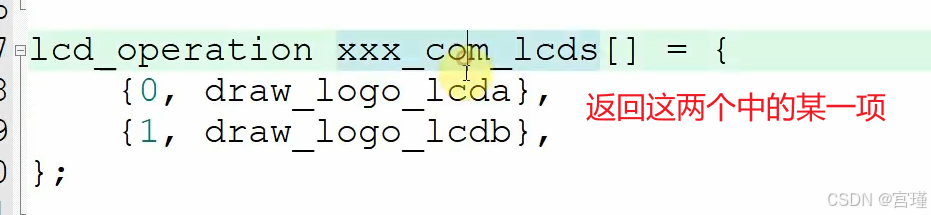

八、下午答疑_关于指针
问题1
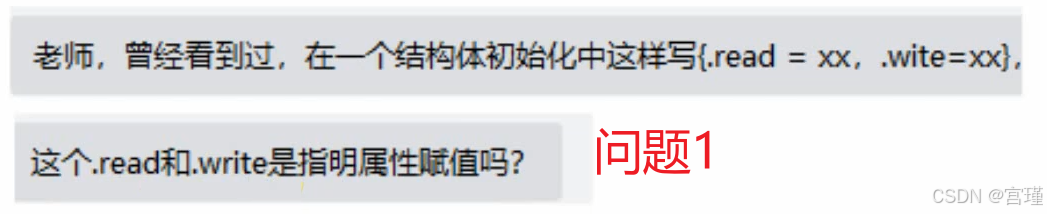


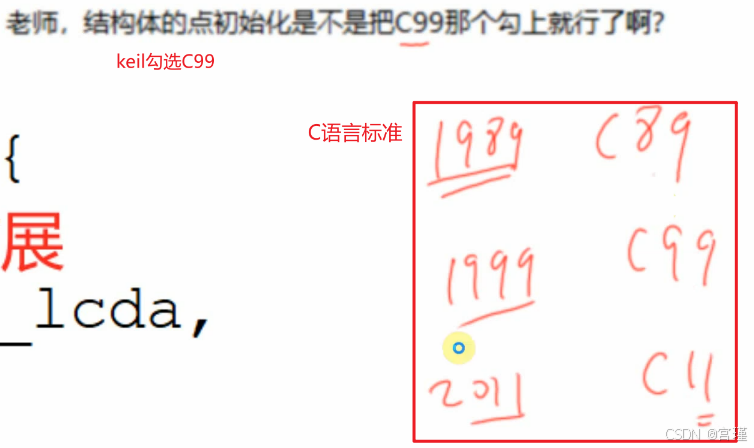
纠正:
该赋值方法不是GCC的扩展,而是C99的标准。
勾选C99之后,编译成功。
问题2

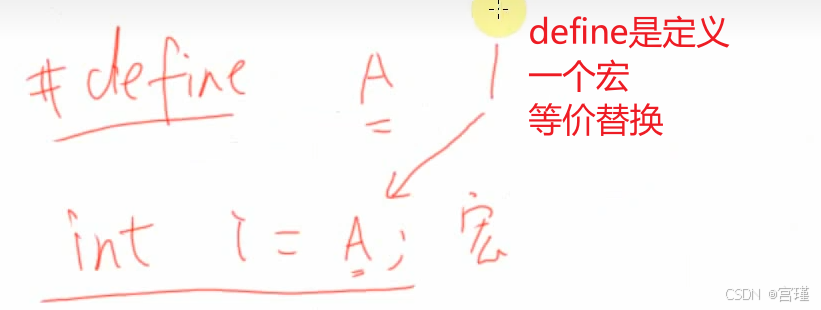
type def:类型定义,用来创建类型的,给类型起别名。



问题3
在"C语言:ESP32案例分析"文章中单独写过这个问题。


问题4
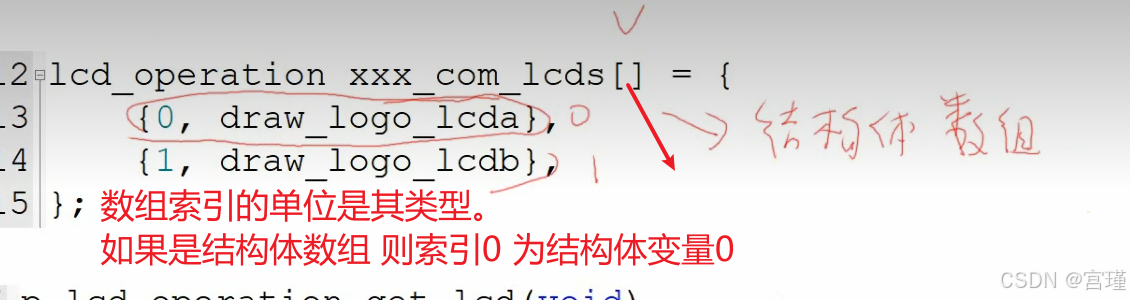
问题5

FLASH是只读的,通过指针写FLASH,CPU可以执行,但是写失败。
写FLASH之前,需要先执行擦除等操作,将FLASH恢复到默认状态,然后再写FLASH。
九、什么是链表
重要。
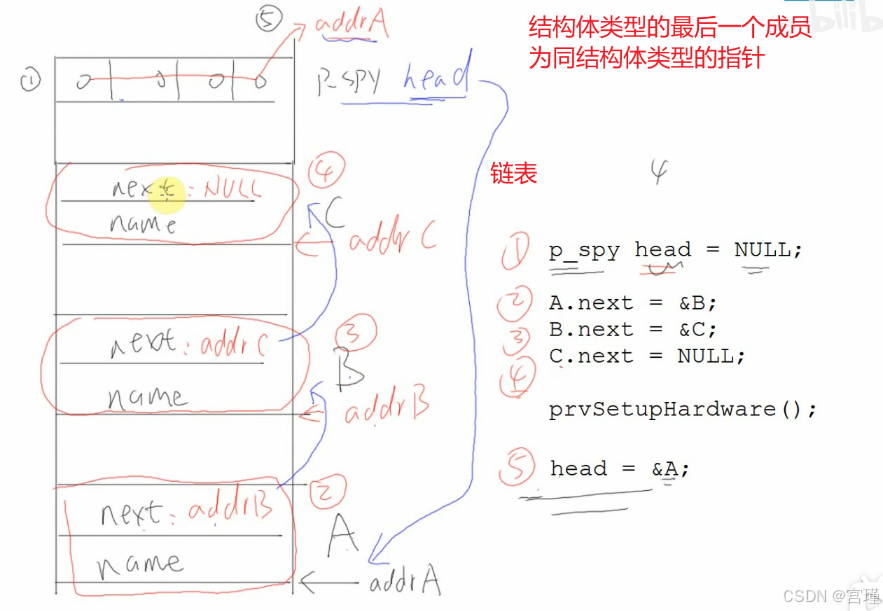
最后一个表的next指针为0;

可以新建一个指针,记录当前的链表。
十、链表的插入操作
链表结构体中,有一个指针指向下一个链表,称为单向链表。
若还有一个指针,指向上一个链表,称为双向链表。
链表的实质,就是指针。
视频中讲的,不是在已有的链表项A->B->C->D中添加新的链表,而是新建插入函数,通过插入函数创建A->B->C->D这个链表。
比较简单。
头部head设置为NULL,然后先插入A,形成链表,然后查询链表中的最后一个链表,逐次插入B C D。
十一、链表的删除操作
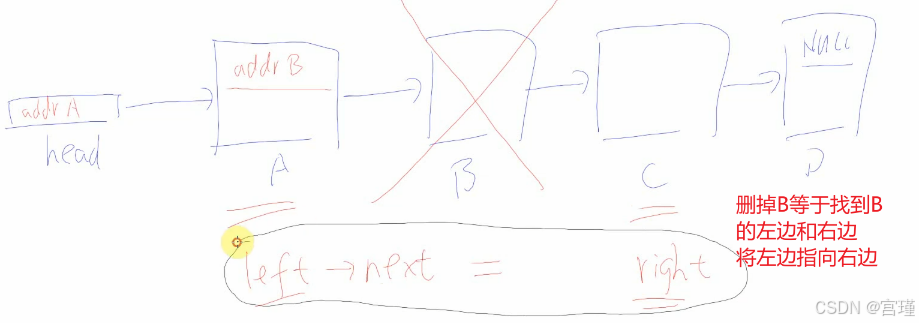
B的下线好找,在B的结构体中就记录了。
通过遍历,寻找B的上线,如果某一项的下线为B,那么这一项就是B的上线。
视频中以间谍为例,所以是上线,下线。
代码比较简单,写起来比较有意思。
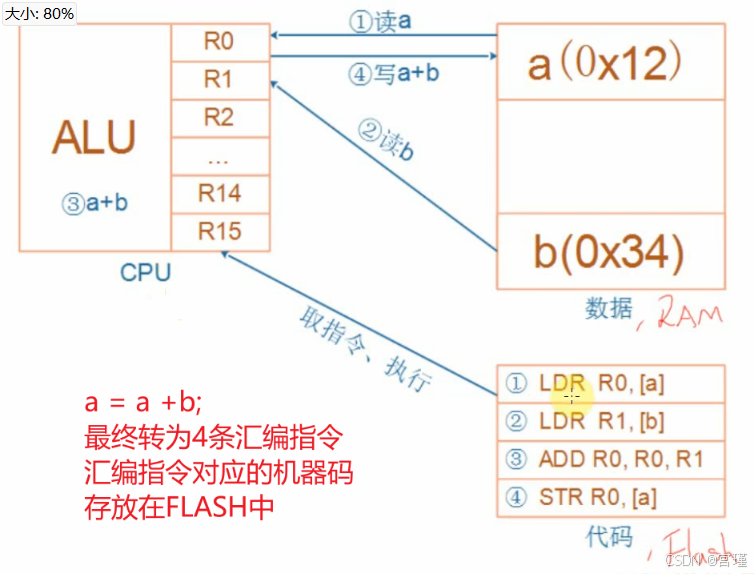
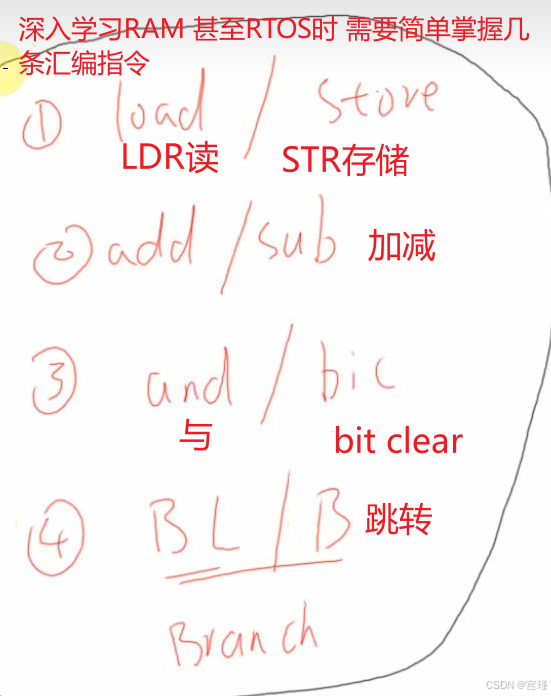
十二、ARM架构与汇编的初步体验
王爽老师的《汇编语言》不错。

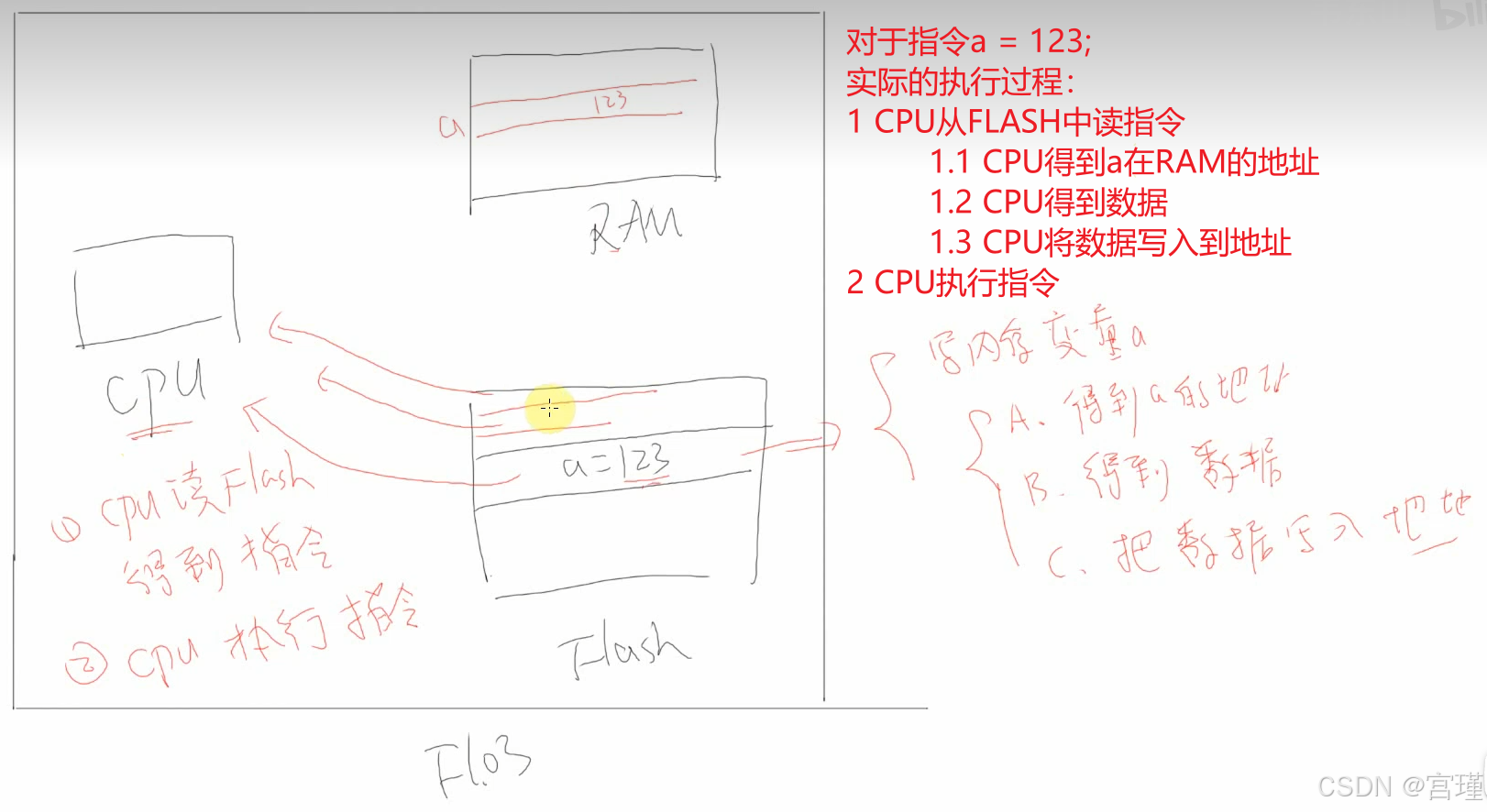
如何理解例子代码执行时,CPU的实际的操作步骤:(与汇编有关)
RAM架构使用精简指令集,所有的计算都在CPU中实现。
RAM可读可写,FLASH只能读。
C代码编译后,产生汇编指令,汇编指令操作码本质是一些十六进制(或者二进制)数据。
下载后,程序在FLASH中。
当程序执行时,CPU在FLASH中取指令,当取到int a = 1;时,CPU在RAM内存中开辟4字节空间,存放a的值。
当执行a = a + b时,CPU读出RAM内存中a的值,放在CPU内部的寄存器(或者称为缓存)中,然后读出b的值,计算a+b,把计算结果再放回到a的RAM地址处。
(大体是这个过程)
CPU内部的寄存器R0 -- R15,32位,用于缓存数据,所以寄存器,也可以称为缓存。
CPU内部还有有计算能力的寄存器,如ALU(算术逻辑单元 执行加减 与或非等操作)等。
缓存用于暂存数据,ALU用计算。
十三、全局变量的初始化与栈的引入
实际感受,一个嵌入式程序运行的本质是怎样的,全局变量是如何被设置的。
局部变量是在哪里?
需要看一下C的反汇编代码。

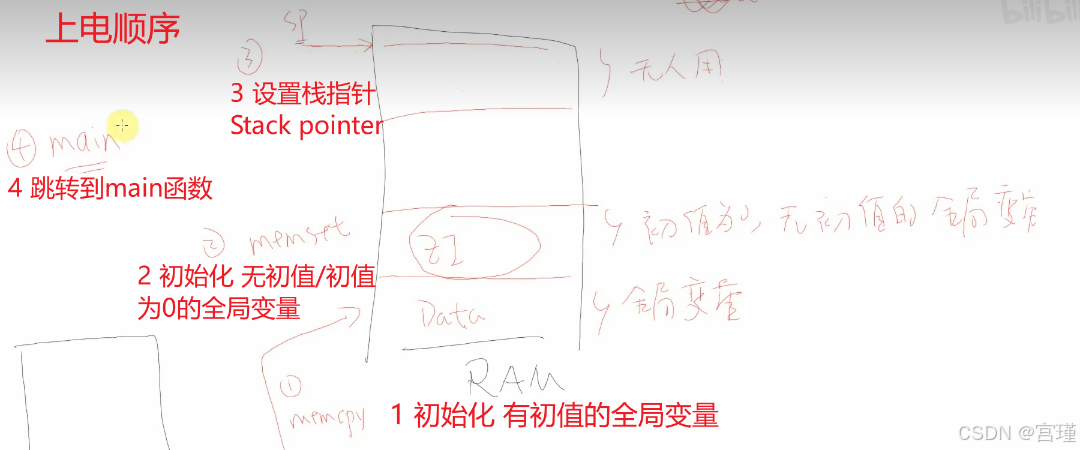
1 有初始值的全局变量,如何进行初始化?:
断电后,程序,数据都只在FLASH中。RAM CPU中都掉电消失了。
程序运行时,才会在RAM中产生变量。
1 全局变量的初值,来自FLASH。
FLASH中存放代码和数据,数据就是已初始化的全局变量的初始值。
一个定义int a = 0x12345678;对应两条汇编指令
a 从flash的某个地址,读取数据到CPU的某一个寄存器
b 将寄存器的值,赋值到RAM的某个地址。
此时便完成全局变量的定义,全局变量存在在RAM中。
此方法效率低,若有100个全局变量,每一条全局变量都对应两条汇编指令。
所以编译器实际的操作是:
将所有的全局变量初始值集中起来,作为数据段。
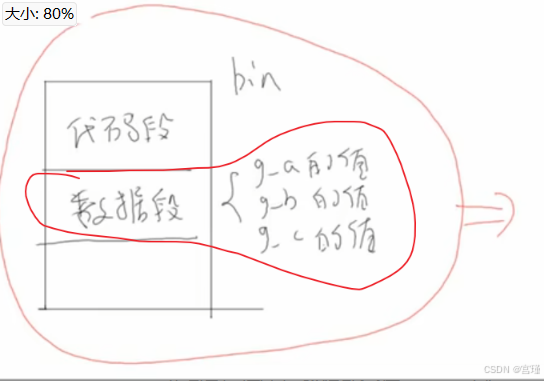
烧写程序时,bin或着hex等二进制文件,会被完整的复制到芯片内部的FLASH中。
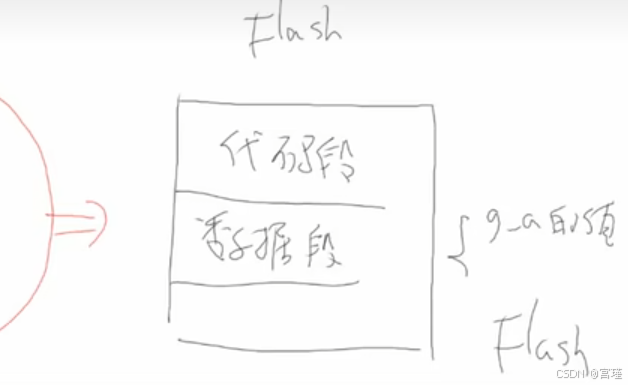
当程序运行时,FLASH中的数据段,会被完整的复制到RAM中。
所以省去了将全局变量逐个复制到RAM中。
数据作为一整段,整段复制到RAM中,效率更高。
如果数据分散在FLASH的不同页上,对变量寻址,还需要修改页寄存器。数据集中在一起,也省去了这个步骤。
对这些内容有个笼统的概念即可。
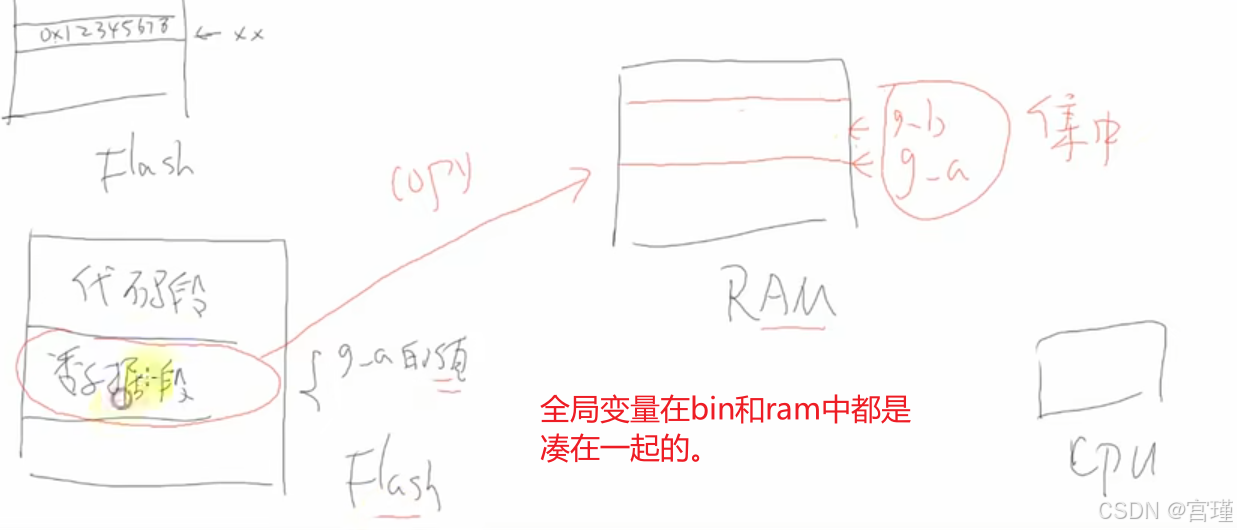
看一下汇编文件。

__main的代码 应该在代码的安装包了 视频中没有继续找。


将目的地址LDR到R0
将源地址LDR到R1
将长度LDR到R2
然后跳转到 memcpy 标号处
总结:有初始值的全局变量,初始值会保存在FLASH中,初始化时,实际的执行操作,类似memcpy,将falsh中的有初始值的全局变量段,整段复制到RAM中。
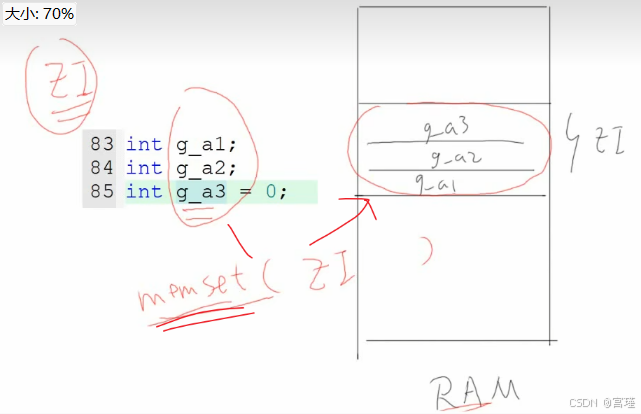
2 无初始值或者初始值为0的全局变量,如何进行初始化?

这种变量,在汇编中全部在ZI段。在ZI段定义。
RAM上电时,初始值不确定(但一般是0),在对ZI段初始化时,执行类似memset的操作,将RAM对应的ZI段,全部设置为0.
相当于完成对"没有初始值的全局变量的初始化"
因为没有初始值,或者初始值为0,那么只要在初始化时,将RAM的一段空间,置为0就可以了。
与有初始值的全局变量初始化对比理解:
有初始值的全局变量会在FLASH中保存初始值。
无初始值的全局变量,初始化时,将ram置为0就可以了,不需要再FLASH中存初始值。

在进入main函数之前,会先完成 "有初始值的全局变量初始化" 和 "无初始值的全局变量的初始化"。
完成后,再进入main函数。
3 引入栈的概念
局部变量在栈中,如何理解?


CPU R14寄存器是LR寄存器,用来保存返回地址。
但是如果函数嵌套时,有多个返回地址,所以一个LR就不够用了,所以需要将返回地址保存在栈空间中。也就是RAM的一段空间中。
返回地址一定保存在LR中,LR中的值,再保存在栈空间中。

十四、局部变量的初始化
深入理解栈,理解局部变量在栈空间,需要看汇编文件。

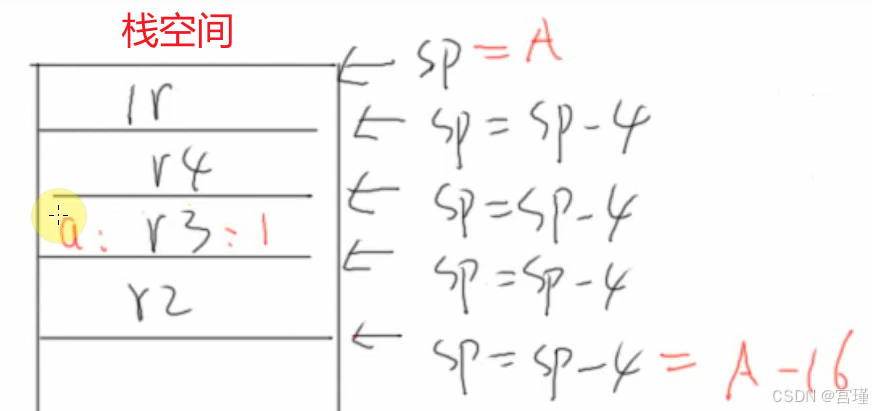
push {r2 - r4,lr} ;将r2 r3 r4 lr的值 push到栈空间中。
;因为是32位CPU,CPU内部的寄存器为32位,所以每push一个寄存器,SP栈指针减4。
;栈空间是FIFO先入先出。栈的位置由SP指针记录。
volatile int a = 1; //初始化局部变量,翻译为汇编,对应下面两条汇编指令
MOVS R0,#0x01 ;将0x01赋值给R0寄存器。加井号是将0x01认为是数值(一个立即数),而不是地址。(RAM汇编和x86汇编立即数的方表示方式不同,此处是RAM架构下的汇编。)(实际编程中,需要查看所用芯片的架构,架构不同,汇编语法也有所不同)
STR R0, SP , #0x04 ;将R0的值,STR存储到SP + 4的地址处。也就是下图中R3的位置。 SP , #0x04为SP + 0X04。加星号为立即数。
可以看到,有初值的全局变量在DATA段中,初始化时,将data段整段cpy到RAM内存中。
而有初值/无初值的全局变量,定义时,不会连续cpy到一段内存中,而是每一条局部变量定义,都对应像上面的两条汇编语句。
所以相对于全局变量初始化,局部变量初始化的效率会低很多。
push {r2 - r4,lr} ;将r2 r3 r4 lr的值 push到栈空间中。
后面又STR R0, SP , #0x04
导致R3的位置又被占用
意思是,前面push r3到栈中,后面又占用了R3保存在stack中的值
没问题,这涉及到
push {r2 - r4,lr} 是想在栈中占个位置。
有个大概的概念即可,暂时不深究了。


有初值的变量,其初值都会保存在代码中,也就是会占用一部分FALSH空间。

断断续续 看了很久 完结撒花