黄新宇,程新景,耿奇川,曹彬彬,周鼎夫,王鹏,林远清,杨瑞刚
百度研究院,中国北京
深度学习技术与应用国家工程实验室,中国
{huangxinyu01, chengxinjing, gengqichuan, caobinbin}@baidu.com
{zhoudingfu, wangpeng54, linyuanqing, yangruigang}@baidu.com
摘要
场景解析旨在为图像中的每个像素分配一个类别(语义)标签。它是对图像的全面分析。随着自动驾驶技术的兴起,像素级精确的环境感知有望成为关键的技术支撑。然而,提供一个大规模数据集用于设计和评估场景解析算法,特别是针对户外场景,一直很困难。每个像素的标注过程成本极高,限制了现有数据集的规模。在本文中,我们提出了一个大规模开放数据集ApolloScape,该数据集包含RGB视频和对应的密集3D点云。与其他现有数据集相比,我们的数据集具有以下独特特性。首先是规模,我们的初始版本包含超过14万张图像------每张图像都有其像素级语义掩码,计划最终达到100万张。其次是复杂性。在各种交通条件下捕获,每张图像中移动物体的数量平均从几十个到超过一百个(图1)。第三是3D属性,每张图像都标记有厘米级精度的高精度姿态信息,静态背景点云具有毫米级相对精度。我们能够通过一个交互式高效标注流程来标注如此多的图像,该流程利用了高质量的3D点云。此外,我们的数据集还包含基于车道颜色和样式区分的不同车道标记。我们期望我们的新数据集能够深度促进各种与自动驾驶相关的应用,包括但不限于2D/3D场景理解、定位、迁移学习和驾驶模拟。
1. 引言
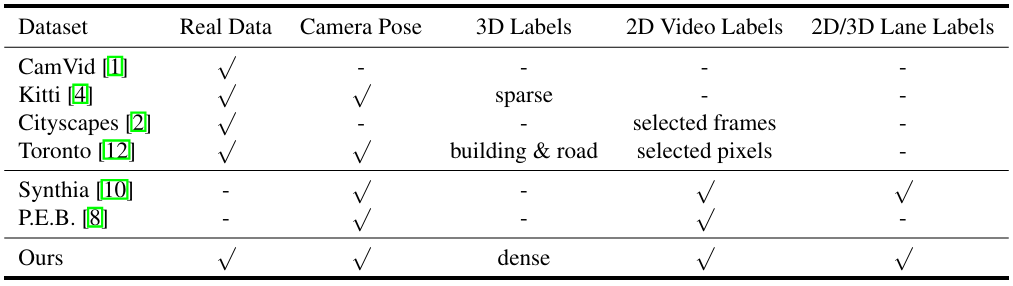
城市街景的语义分割,或场景解析,是自动驾驶领域的主要研究课题之一。近年来在不同城市收集了大量数据集,旨在增加城市街景的多样性和复杂性。剑桥驾驶标记视频数据库(CamVid)1可能是第一个具有语义标注视频的数据集。该数据集规模相对较小,包含701张手动标注的图像,带有32个语义类别,从驾驶车辆中捕获。KITTI视觉基准套件4收集并标注了用于不同计算机视觉任务(如立体视觉、光流、2D/3D目标检测和跟踪)的数据集。例如,7,481张训练图像和7,518张测试图像通过2D和3D边界框进行标注,用于目标检测和目标方向估计任务。该数据集每张图像最多包含15辆汽车和30个行人。然而,像素级标注仅由第三方部分完成,质量无法保证。因此,没有直接提供语义分割基准。Cityscapes数据集2专注于街景的2D语义分割,包含30个类别,5,000张带有精细标注的图像,和20,000张带有粗糙标注的图像。虽然视频帧可用,但只有每段视频片段中的一个图像(第20帧)被标注。TorontoCity基准12从无人机和移动车辆收集了激光雷达数据和图像,包括立体图像和全景图像。目前,这可能是最大的数据集,覆盖了大多伦多地区。然而,正如作者所提到的,手动标注这种规模的数据集是不可能的。因此,只提供了两个语义类别,即建筑足迹和道路,作为分割的基准任务。

图1. 彩色图像(上)、2D语义标签(中)和静态背景的深度图(下)示例。
在本文中,我们提出了一个正在进行的项目,旨在提供一个开放的大规模综合性城市街景数据集。最终的数据集将包括带有百万级高分辨率图像和像素标注的RGB视频、具有语义分割的测量级密集3D点云、包含罕见事件的立体视频、以及夜视传感器数据。我们正在进行的数据收集将进一步覆盖广泛的环境、天气和交通条件。与其他现有数据集相比,我们的数据集具有以下特点:
-
第一个子集,143,906个带有像素标注的图像帧,已经发布。我们将数据集分为简单、中等和困难子集。难度级别基于每张图像中车辆和行人的数量来衡量,这通常表示场景复杂性。我们的目标是捕获并标注约一百万个视频帧和对应的3D点云。
-
我们的数据集具有静态物体的测量级密集3D点云。每个图像都关联有一个渲染的深度图,创建了第一个用于户外场景的像素标注RGB-D视频。
-
除了典型的物体标注外,我们的数据集还包含车道标记的细粒度标注(28个类别)。
-
为这个数据集设计了一个交互式高效的2D/3D联合标注流程。平均节省了70%的标注时间。基于我们的标注流程,所有3D点云都将分配上述标注。因此,我们的数据集是第一个包含3D标注的开放街景数据集。
-
视频帧的实例级标注可用,这对于设计用于可移动物体的预测、跟踪和行为分析的时空模型特别有用。
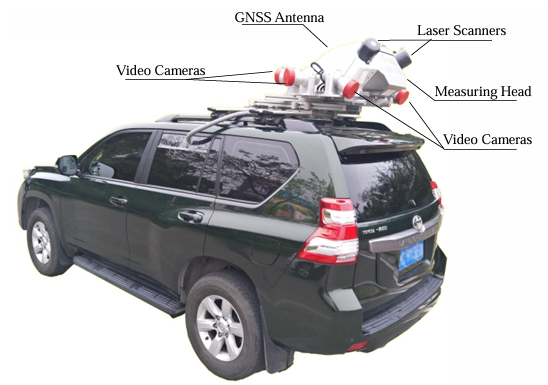
图2. 采集系统由两个激光扫描仪、最多六个摄像机和一个组合的IMU/GNSS系统组成。
我们已经在http://apolloscape.auto发布了我们数据集的第一批。更多数据将定期添加。
2. 数据采集
我们使用Riegl VMX-1HA9作为采集系统,主要由两个VUX-1HA激光扫描仪(360°视场角,范围从1.2m到420m,目标反射率大于80%)、VMX-CS6相机系统(使用两个前置相机,分辨率3384×2710)和带有IMU/GNSS的测量头(位置精度20~50mm,横滚和俯仰精度0.005°,航向精度0.015°)组成。
激光扫描仪利用两个激光束垂直扫描周围环境,类似于推扫式相机。与常用的Velodyne HDL-64E11相比,这些扫描仪能够获取更高密度的点云,并获得更高的测量精度/精确度(5mm/3mm)。整个系统已内部校准和同步。它安装在一辆中型SUV的顶部(图2),以每小时30公里的速度行驶,相机每1米触发一次。然而,移动物体的获取点云可能会严重变形甚至完全丢失。
3. 数据集
目前,我们已经发布了数据集的第一部分,包含143,906个视频帧和对应的像素级标注,用于语义分割任务。在发布的数据集中,进一步提供了89,430个可移动物体的实例级标注,这对于实例级视频目标分割和预测特别有用。表2显示了我们的数据集与其他街景数据集之间几个关键属性的比较。
表1. Kitti、Cityscapes和我们数据集(实例级)中实例的总数和平均数。字母e、m和h分别表示简单、中等和困难子集。
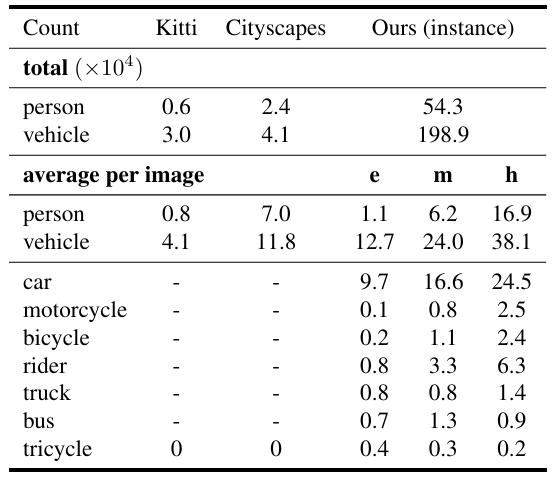
该数据集从呈现简单、中等和重度场景复杂性的不同轨迹中收集。与Cityscapes类似,我们基于可移动物体(如人和车辆)的数量来衡量场景复杂性。表1比较了我们的数据集与其他开放数据集2,4之间的场景复杂性。在表中,我们还展示了可移动物体各个类别的统计数据。我们发现,物体实例的总数和平均数都远高于其他数据集。更重要的是,我们的数据集包含更具挑战性的环境,如图3所示。例如,同一图像中出现了两种极端照明条件(如黑暗和明亮),这可能是由天桥的阴影造成的。公交车表面附近多辆车的反射可能会使许多实例级分割算法失效。我们将在不久的将来继续发布更多数据,具有更大样性的位置、交通条件和天气。
3.1. 规格说明
我们标注了五个组涵盖的25个不同标签。表3给出了这些标签的详细信息。表中显示的ID是用于训练的ID。值255表示忽略的标签,在测试阶段目前不进行评估。这些类别的规格与cityscape数据集类似,但有几个区别。例如,我们添加了一个新的"三轮车"类别,这在东亚国家是一种相当流行的交通工具。此类别涵盖所有类型的三轮车辆,可以是机动的也可以是人力驱动的。而cityscape中的骑行者类别定义为在交通工具上的人,我们认为人和交通工具是一个单一的移动物体,并将它们合并为一个单一类别。
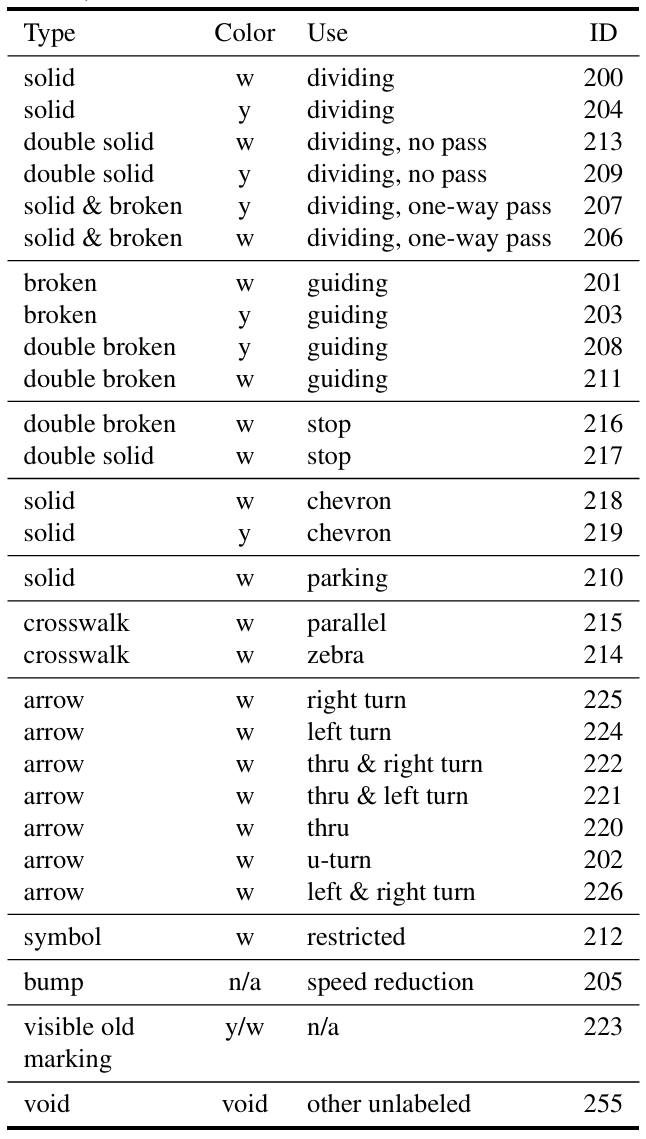
我们还标注了28种不同的车道标记,这在现有的开放数据集中目前不可用。这些标注基于车道边界属性定义,包括颜色(如白色和黄色)和类型(如实线和虚线)。表4给出了这些车道标记的详细信息。我们将"可见的旧标记"与其他类别分开,这代表了"幽灵标记",即可见的旧车道标记残留。这种标记在许多国家是一个持续存在的问题,甚至可能使人类驾驶员感到困惑。
4. 标注过程
为了使我们的视频帧标注准确高效,我们开发了一个如图4所示的标注流程。该流程主要包含两个阶段,3D标注和2D标注,分别处理静态背景/物体和移动物体。我们流程的基本思想与14中描述的类似,而我们流程中使用的一些关键技术是不同的。例如,处理移动物体的算法是不同的。
如第2节所述,移动物体的点云可能会严重变形。因此,我们采取三个步骤来消除这部分点云:1)多次扫描相同道路段;2)对齐这些点云;3)基于时间一致性移除点。注意,在步骤2)中可以添加额外的控制点以进一步提高对齐性能。

图3. 一些具有挑战性环境的图像(为可视化目的进行了中心裁剪)。最后一行包含由黄色矩形包围的放大区域。
表2. 我们的数据集与其他街景数据集之间的比较。"真实数据"表示数据是否从我们的物理世界收集。"3D标签"表示是否包含具有语义标签的场景3D地图。"2D视频标签"表示是否具有像素级语义标签。"2D/3D车道标签"表示是否具有车道标记的3D语义标签和视频像素级标签。
为了加速3D标注过程,我们首先基于空间距离和法线方向将点云过度分割为点簇。然后,我们手动标注这些点簇。基于部分标注数据,我们还重新训练了PointNet++模型7来预分割点云,这可以实现更好的分割性能。由于这些初步结果仍然不能直接用作真实标签,我们通过手动修正错误标注来优化结果。错误标注通常发生在物体边界周围。3D标注工具被开发出来以将上述模块集成在一起。如图5所示的工具用户界面设计进一步加速了标注过程,包括3D旋转、多边形(反向)选择、点云与相机视图之间的匹配等功能。
一旦生成了3D标注,所有2D图像帧的静态背景/物体标注通过3D-2D投影自动生成。计算机图形学中的溅射技术进一步应用于处理未标注的像素,这些像素通常由缺失点或强反射引起。
为了加速2D标注过程,我们首先训练了一个用于可移动物体的CNN网络13,并对2D图像进行预分割。另一个用于2D图像的标注工具被开发出来,用于修正或优化分割结果。同样,错误标注通常发生在物体边界周围,这可能是由多个物体的合并/分割和恶劣照明条件引起的。我们的2D标注工具被设计成可以轻松选择和调整边界的控制点。
图6展示了一个2D标注图像的示例。注意,一些背景类别如围栏、交通灯和植被能够被详细标注。在其他数据集中,这些类别可能由于遮挡而模糊,或者为了节省标注工作量而作为整个区域进行标注。
5. 基准套件
给定3D标注、2D像素和实例级标注、背景深度图、相机姿态信息,可以定义许多任务。在当前版本中,我们主要关注2D图像解析任务。我们希望在不久的将来添加更多任务。
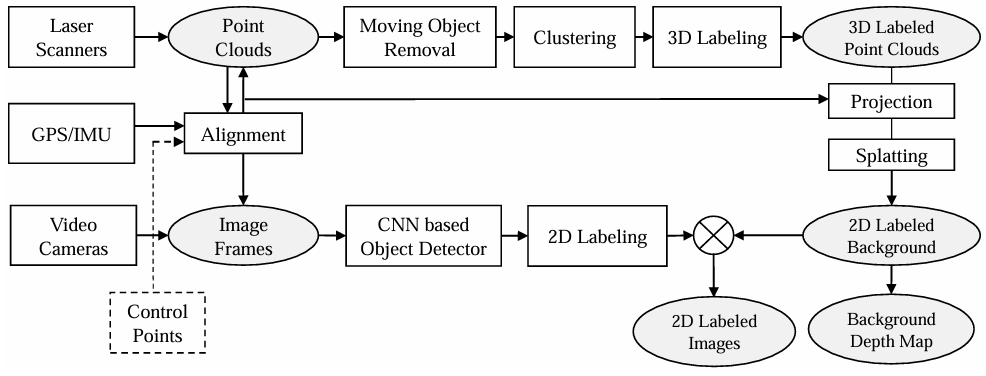
图4. 我们的2D/3D标注流程,分别处理静态背景/物体和移动物体。
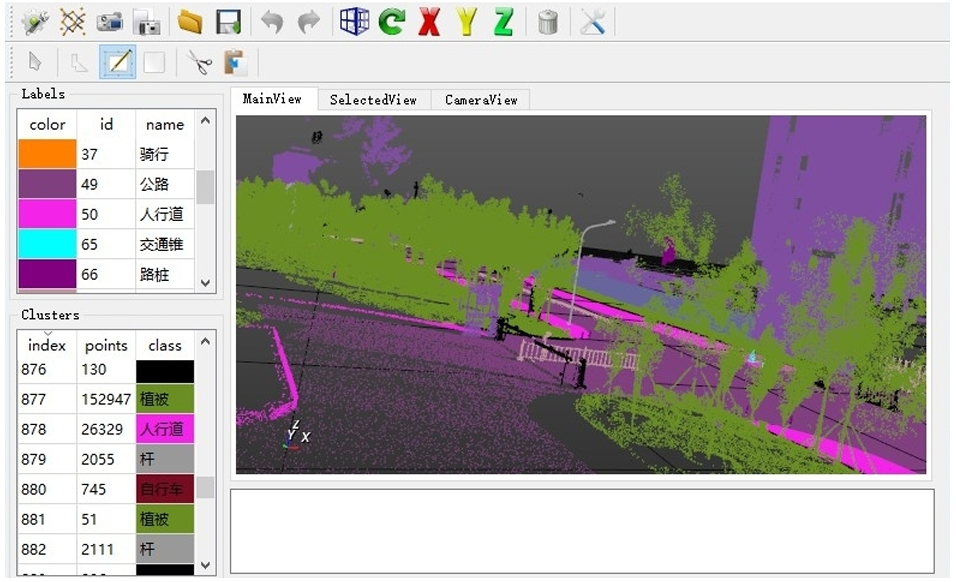
图5. 我们3D标注工具的用户界面。
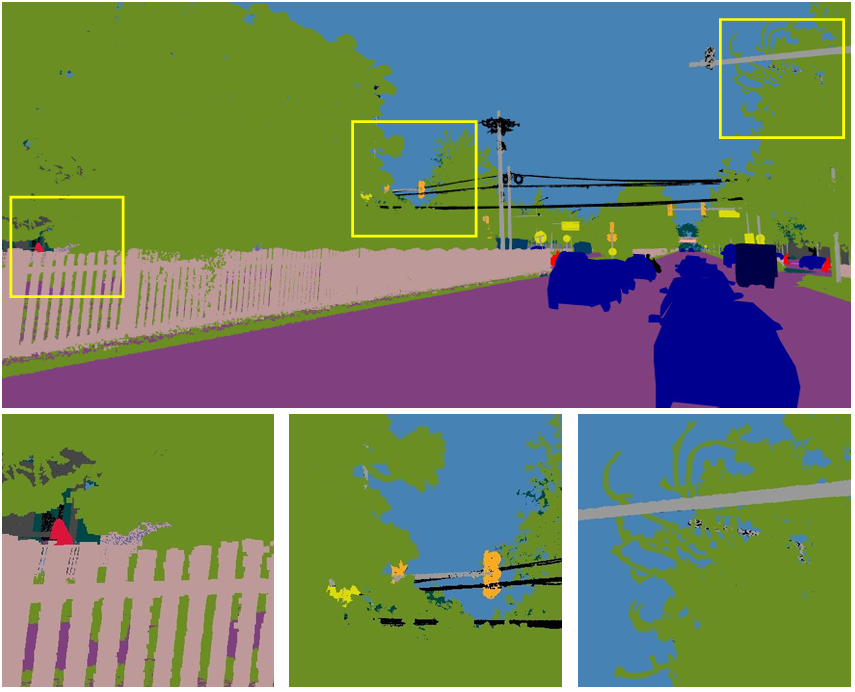
图6. 2D标注示例,包含详细边界。
5.1. 图像解析度量
给定真实标签集合S={Li}i=1NS = \{L_{i}\}{i=1}^{N}S={Li}i=1N和预测标签集合S∗={L^i}i=1NS^{*} = \{\hat{L}{i}\}{i=1}^{N}S∗={L^i}i=1N,类别c的交并比(IoU)度量3计算为:
IoU(S,S∗,c)=∑i=1Ntp(i,c)∑i=1N(tp(i,c)+fp(i,c)+tn(i,c))(tp(i,c)=∑p1(Li(p)=c⋅L^i(p)=c)fp(i,c)=∑p1(Li(k)eqc⋅L^i(p)=c)tn(i,c)=∑p1(Li(k)=c⋅L^i(p)eqc)\begin{aligned}IoU(\mathcal{S},\mathcal{S}^{*},c)&=\frac{\sum{i=1}^{N}tp(i,c)}{\sum_{i=1}^{N}(tp(i,c)+fp(i,c)+tn(i,c))}(\\tp(i,c)&=\sum_{p}\mathbf{1}(\mathbf{L}{i}(p)=c\cdot\hat{\mathbf{L}}{i}(p)=c)\\fp(i,c)&=\sum_{p}\mathbf{1}(\mathbf{L}{i}(k) eq c\cdot\hat{\mathbf{L}}{i}(p)=c)\\tn(i,c)&=\sum_{p}\mathbf{1}(\mathbf{L}{i}(k)=c\cdot\hat{\mathbf{L}}{i}(p) eq c)\end{aligned}IoU(S,S∗,c)tp(i,c)fp(i,c)tn(i,c)=∑i=1N(tp(i,c)+fp(i,c)+tn(i,c))∑i=1Ntp(i,c)(=p∑1(Li(p)=c⋅L^i(p)=c)=p∑1(Li(k)eqc⋅L^i(p)=c)=p∑1(Li(k)=c⋅L^i(p)eqc)
然后,总体平均IoU是所有C个类别的平均值:F(S,S∗)=1C∑cIoU(S,S∗,c)\mathcal{F}(\mathcal{S},\mathcal{S}^{*})=\frac{1}{C}\sum_{c}IoU(\mathcal{S},\mathcal{S}^{*},c)F(S,S∗)=C1∑cIoU(S,S∗,c)。
5.2. 基于帧的评估
在当前版本中,连续帧之间的跟踪信息不可用。因此,我们使用基于帧的评估。然而,我们不是将所有图像一起评估(这与单图像评估相同),而是考虑基于帧的评估。
5.2.1 视频语义分割度量
我们提出了基于帧的IoU度量,独立评估每个预测帧。
给定一组带有真实标签S={Li}i=1NS = \{L_{i}\}{i=1}^{N}S={Li}i=1N和预测标签S∗={L^i}i=1NS^{*} = \{\hat{L}{i}\}{i=1}^{N}S∗={L^i}i=1N的图像序列。两个对应图像之间的度量为m(L,L^)m(\mathbf{L}, \hat{\mathbf{L}})m(L,L^)。每个预测标签L将包含像素级预测。
F(S,S∗)=mean(∑im(Li,L^i)∑iNi)\mathcal{F}(\mathcal{S},\mathcal{S}^{*})=mean(\frac{\sum{i}\mathbf{m}(\mathbf{L}{i},\hat{\mathbf{L}}{i})}{\sum_{i}\mathbf{N}{i}})F(S,S∗)=mean(∑iNi∑im(Li,L^i))
m(Li,L^i)=⋯ ,IoU(Li=j,L\^i=j),⋯ T\mathbf{m}(\mathbf{L}{i},\hat{\mathbf{L}}{i})=\\cdots,IoU(\\mathbf{L}_{i}=j,\\hat{\\mathbf{L}}_{i}=j),\\cdots^{T}m(Li,L^i)=⋯,IoU(Li=j,L\^i=j),⋯T
Ni=⋯ ,1(j∈L(Li)orj∈L(L\^i),⋯ \mathbf{N}{i}=\\cdots,1(j\\in\\mathcal{L}(\\mathbf{L}_{i})or j\\in\\mathcal{L}(\\hat{\\mathbf{L}}_{i}),\\cdotsNi=⋯,1(j∈L(Li)orj∈L(L\^i),⋯
表3. 我们数据集中类别的详细信息。

其中IoU在两个二值掩码M1M_{1}M1和M2M_{2}M2之间计算。j∈L(Li)j \in \mathcal{L}(\mathbf{L}{i})j∈L(Li)表示标签j出现在真实标签LiL{i}Li中。
5.3. 视频目标实例分割度量
我们首先基于重叠区域的阈值在真实实例和预测实例之间进行匹配。对于每个预测实例,如果预测实例与忽略标签之间的重叠区域大于阈值,则该预测实例将从评估中移除。注意,组类别,如汽车组和自行车组,在评估中也被忽略。未匹配的预测实例被视为误报。
表4. 我们数据集中车道标记的详细信息(y: 黄色,w: 白色)。
我们使用插值平均精度(AP)5作为目标分割的度量。AP为每个视频片段的所有图像帧的每个类别计算。然后计算所有视频片段和所有类别的平均AP(mAP)。
6. 图像解析的实验结果
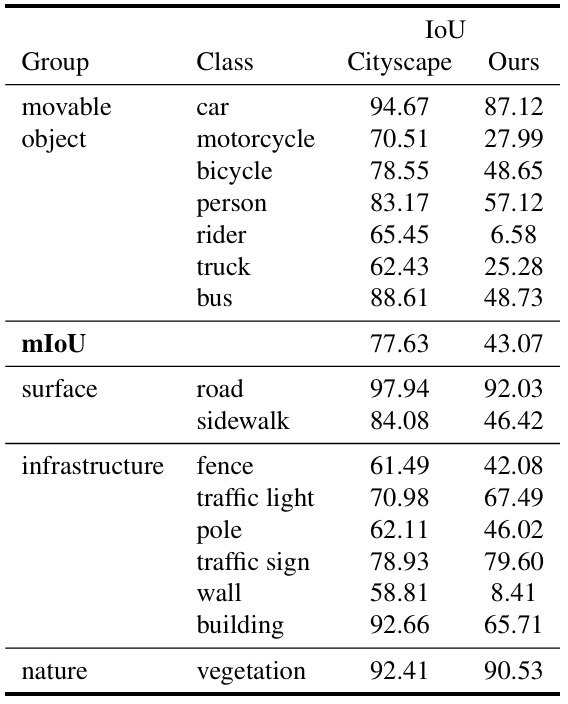
我们在Wide ResNet-38网络13上进行了实验,该网络与原始ResNet结构6相比,用宽度换取深度。发布的模型使用我们的数据集进行微调,初始学习率0.0001,裁剪大小512×512,均匀采样,10倍数据增强,100个轮次。预测使用单一尺度1.0计算,没有任何后处理步骤。为了与ResNet-38网络中的训练和测试进行比较,我们从我们的数据集中选择了一个小子集,包含5,378张训练图像和671张测试图像,这与Cityscapes数据集中的精细标注图像数量相同(即约5K训练图像和500张测试图像)。表5显示了这两个数据集共有类别的解析结果。注意,基于我们的数据集计算的IoU远低于Cityscapes的IoU。我们数据集中可移动物体的mIoU比Cityscapes低34.6%(两个数据集共有的类别)。
表5. 基于ResNet-38网络使用5K训练图像的图像解析结果。
7. 结论与未来工作
在这项工作中,我们提出了一个大规模综合性街景数据集。该数据集包含1)比现有数据集更高的场景复杂性;2)2D/3D标注和姿态信息;3)各种标注的车道标记;4)具有实例级标注的视频帧。
未来,我们首先将扩大我们的数据集,以达到一百万张标注的视频帧,包含更多样化的条件,包括雪、雨和雾天环境。其次,我们计划在不久的将来安装立体相机和全景相机系统,以生成深度图和全景图像。在当前版本中,移动物体的深度信息仍然缺失。我们希望为静态背景和移动物体生成完整的深度信息。
参考文献
1 G. J. Brostow, J. Fauqueur, and R. Cipolla. Semantic object classes in video: A high-definition ground truth database. Pattern Recognition Letters, 30(2):88--97, 2009.
2 M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
3 M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111(1):98--136, 2015.
4 A. Geiger, P. Lenz, C. Stiller, and R. Urtasun. Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR), 2013.
5 B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. In European Conference on Computer Vision, pages 297--312. Springer, 2014.
6 K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016.
7 C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems, pages 5105--5114, 2017.
8 S. R. Richter, Z. Hayder, and V. Koltun. Playing for benchmarks. In International Conference on Computer Vision (ICCV), 2017.
9 RIEGL. VMX-1HA. http://www.riegl.com/, 2018. Online; accessed 01-March-2018.
10 G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3234--3243, 2016.
11 Velodyne Lidar. HDL-64E. http://velodynelidar.com/, 2018. Online; accessed 01-March-2018.
12 S. Wang, M. Bai, G. Mattyus, H. Chu, W. Luo, B. Yang, J. Liang, J. Cheverie, S. Fidler, and R. Urtasun. Torontocity: Seeing the world with a million eyes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3009--3017, 2017.
13 Z. Wu, C. Shen, and A. v. d. Hengel. Wider or deeper: Revisiting the resnet model for visual recognition. arXiv preprint arXiv:1611.10080, 2016.
14 J. Xie, M. Kiefel, M.-T. Sun, and A. Geiger. Semantic instance annotation of street scenes by 3d to 2d label transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3688--3697, 2016.