Prompt 对大模型的应用效果很重要,作为和大模型之间最重要的沟通工具,其表达内容的优劣直接关乎模型性能、潜力的发挥
好的 prompt 可以激发 LLM 的最大潜能,从而在具体任务中取得好的效果
调试 Prompt 效果的工作不仅耗费大量人力、时间,且需要依赖大模型相关专业知识与足够的实践经验
大部分同学难以应对复杂多变的任务场景,还容易受个人偏见、偏好的影响,使得 Prompt 调优工作变得很"诡异"
开发能自动生成高效高质量提示词的技术迫在眉睫,学界早在 2022 年提出 Automatic Prompt Engineering 概念,近几年又有新发展
给定一个训练集,定义好评价指标,运行 Automatic Prompt Engineering 框架后,将自动得到能取得最佳效果的 Prompt
无论是想"提分"、还是想优化 LLM 标注器的效果、或是想根据用户反馈来优化 prompt 提升产品体验,这些方法都可借鉴
常见算法
算法框架 提出时间 提出机构 基座模型 特点
APE 2022 多伦多、滑铁卢大学 InstructGPT 简单,易于实现,容易得出局部最优解
APO 2023 Microsoft GPT 4
将 bad case 的原因分析引入 prompt 迭代,高估了LLM计算和利用梯度的能力,尤其是随着任务复杂性的增加,这种能力可能会受到限制
PromptAgent(灵枢方案)
2023 CMU、Microsoft 等 GPT 3.5/GPT 4/PaLM 2 引入了 agent 的 planning 和 reflection 方法
OPRO 2023 DeepMind、Google PaLM 普通 prompt 能优化,还能解决数学优化问题
EvoPrompt 2023 清华大学/Microsoft等 GPT-3.5Alpaca-7b 和遗传进化算法结合,开辟了新思路
BPO 2023 清华大学 GPT-4
期望训练一个 sequence-to-sequence 模型,输入 original prompt,直接输出优化后的 prompt
之后需要进行 prompt 优化时,直接使用这个模型即可,即插即用、无需训练
PE2 2023 Microsoft GPT 4 借鉴优化器batch_size/step等概念,优化meta prompts
LongPO 2025 Google PaLM 2-L 句子级别的优化,优化方法跟遗传算法类似
MIPROv2 DSPy
理论上可实现全局最优,但代码性能差,优化部分为单线程。生产环境使用有改造成本
APE 算法
https://arxiv.org/pdf/2211.01910
要求 LLM 生成一组候选指令,然后让他们评估哪些指令更有前景,然后进行重复迭代优化
By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans.
Inspired by classical program synthesis and the human approach to prompt engineering, we propose Automatic Prompt Engineer1(APE) for automatic instruction generation and selection. In our method, we treat the instruction as the "program," optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Extensive experiments show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 24/24 Instruction
通过对自然语言指令进行条件约束,大语言模型(LLMs)已展现出作为通用计算模型的卓越能力。然而,模型的任务表现在很大程度上取决于用于引导模型的提示词质量,而绝大多数高效的提示词均由人工精心设计。受经典程序综合技术与人类提示词工程方法的启发,我们提出了自动提示词引擎(Automatic Prompt Engineer,APE),用于实现指令的自动生成与筛选。
Induction tasks and 17/21 curated BIG-Bench tasks. We conduct extensive qualitative and quantitative analyses to explore the performance of APE. We show that APE-engineered prompts are able to improve few-shot learning performance (by simply prepending them to standard in-context learning prompts), find better zero-shot chain-ofthought prompts, as well as steer models toward truthfulness and/or informativeness. 2
在该方法中,将指令视作一种「程序」,通过在大语言模型生成的候选指令池中进行搜索来完成优化,以最大化选定的评分函数值。为评估筛选后指令的质量,测试了另一款大语言模型遵循该指令时的零样本任务表现。大量实验结果表明:在 24 项指令归纳任务中,自动生成的指令全面超越此前的大语言模型基线方案;在 21 项精选的 BIG-Bench 基准任务中,其表现也优于或与人类标注者生成的指令相当(占比 17/21)。
APE 通过输出演示(类似 few shot 示例)自动生成特定任务的指令,生成几个候选 instruction
或通过直接推理或基于语义相似性的递归过程,在 target 模型中执行得到评估分数,最后基于评估分数来选择最合适的 instruction
核心思路:
从候选集中选出好的 prompt,再在好的 prompt 附近进行试探性搜索
生成候选 prompt 的算法:
- 正向模式:利用大模型给出预期输入输出,生成候选 prompt
- 逆向模式:将待生成的 prompt 放到 examples 前面,让 LLM 用填空的方式写 prompt
- 定制提示:通过定制化提示,以满足特定任务的需求



如上三张图,是大模型指令学习/评估的三种不同模板
核心是通过 "输入-输出对" 来生成/验证指令
常用于模型的指令泛化能力训练、指令逆向推理、事实性问答评估等场景
Forward Generation Template(正向生成模板)
核心逻辑:已知输入 - 输出对,让模型反向推导 "指令"
流程:
告诉模型 "我给朋友一个指令 + 5 个输入,朋友根据指令生成输出"
然后给出若干 Input:Q→Output:A 的示例对,最后让模型补全 处的 "原始指令"
用途:
测试大模型的指令归纳能力,能否从输入输出的规律中,总结出背后的任务指令
比如从 "Q 是数学题、A 是计算结果" 中归纳出 "指令是'计算数学题的答案'"
Reverse Generation Template(逆向生成模板)
核心逻辑:已知指令 + 输入 - 输出对,让模型扩展 / 验证任务
流程:
先告诉模型 "我给朋友的指令是",再给出若干 Input:Q→Output:A 的示例对
后续让模型:
- 补全更多符合该指令的 "输入 - 输出对"
- 验证现有输入输出是否符合指令要求
用途:
- 测试大模型的指令泛化能力,能否根据给定指令,生成/判断符合要求的输入输出
- 比如指令是 "将句子转为被动语态",模型需生成更多 "主动句→被动句" 的示例
Template for TruthfulQA(TruthfulQA 评估模板)
核心逻辑:针对 "事实性问答" 的评估模板,用于测试模型回答真实性
流程:
设定 "Smith 教授收到的指令是"
比如指令是 "回答以下问题,确保内容真实准确"),再给出Input:Q→Output:A的问答对
后续让模型:
判断教授的回答(A)是否符合 "真实、无编造" 的要求修正错误的回答
用途:
用于TruthfulQA 数据集(评估大模型 "是否会编造虚假信息" 的经典数据集),测试模型的事实准确性与诚实性
在训练集上打分,并保留高分 prompt
为了减少计算成本,APE 提出一种 Prompt 筛选方案:
首先,通过训练集的一个子集计算所有候选提示的得分,然后根据设定的阈值筛选出一部分高质量的提示
接着,从数据集中随机抽取一个新的、不重复的样本,以更新评分的移动平均值。反复执行该过程(迭代),直到剩下少数高质量候选提示
最后,根据这些提示在所有训练样本上的得分,得出最终的候选提示(Successive Rejects)
在高分 prompt 附近进行采样,模拟 MCTS 过程
在迭代过程中,作者发现得分较高的 prompt 往往在多轮迭代中保持不变(容易陷入局部最优,辅助一些随机生成策略)
作者实验发现,对于比较难的任务,进行 resample 能够进一步提升效果
所以在每一轮迭代中,过滤掉得分较低的 prompt,使用 LLM 仿照当前得分高的提示,生成一组与高得分 prompt 相似的新 prompt
PromptAgent,灵枢采用方案
《灵枢》的完整官方全称是《灵枢经》,也常与《素问》合称《黄帝内经灵枢经》
它是中医经典《黄帝内经》的两大组成部分之一(另一部分为《素问》),二者合璧才是完整的《黄帝内经》
现有方法倾向于生成与普通用户提示局部相似的变体,很难达到专家提示的深度和广度
PromptAgent 将生成专家级提示的过程比喻为人类专家设计提示时的反复试错和迭代。
每一轮迭代相当于PromptAgent 在提示空间中走一步,通过对模型错误进行反思来选择探索方向并对当前提示进行修正
这种人性化的试错过程使 PromptAgent 能够像人类专家一样在失败中不断学习和进化,最终抵达最优的提示形式
PromptAgent 通过迭代改进提示,基于错误反馈来模仿人类专家的试错过程
它将提示生成形式化为一个马尔可夫决策过程 (MDP),MDP 的决策目标不是 "最大化单次即时奖励",而是 "最大化长期的累积折扣奖励"
其中状态是任务提示,动作是用于改进提示的错误反馈
然后,MCTS 用于探索提示空间,平衡"探索"和"利用",以找到错误反馈的高奖励路径,从而产生可推广的专家级提示
MCTS 赋予了 PromptAgent 前瞻性和回溯性,它可以估计未来的回报,调整当前的探索策略,避免陷入局部最优
整个搜索过程在提示空间上形成了一棵树,PromptAgent 总是选择最有希望的分支向下探索
最终经过多轮迭代,它可以在广阔的专家提示空间中找到最优解
算法框架的关键组成部分:
- 状态 S: S 表示 prompt 的采样(生成)空间,每个状态 St 对应一个提示的版本 Pt,代表任务提示的每次迭代或版本
- 动作 A: 基于基础模型所犯的错误而生成的错误反馈 ,A 为动作空间,每个动作 at 是基于模型错误反馈生成的修改
- 转移函数 T: T(st,at) ,使用优化器 LLM 根据错误反馈(动作)更新提示(状态)
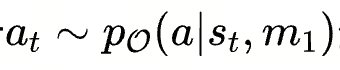
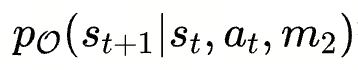
元提示 m1 和 m2 的设计对 PromptAgent 至关重要,分别指导了动作生成和状态转移 - 奖励函数 R: 衡量生成的状态(prompt)的质量,用于评估新生成的提示在验证集上的性能
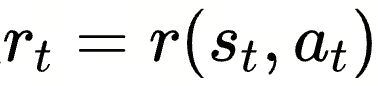
Prompt 优化的目标是找到最优的自然语言 prompt P*,使得奖励函数 R 的结果(例如准确率、F1 等)最大
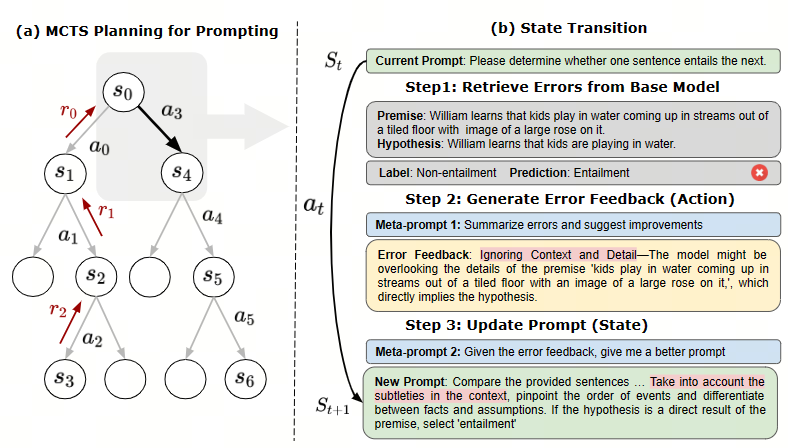
图(a) 展示 PromptAgent 算法的核心:
将 MCTS 规划算法引入提示优化,通过构建树状结构来策略性探索提示空间
每个节点表示一个状态(提示),每条边表示状态间的转移动作
通过错误反馈生成有洞察力的动作,并利用 MCTS 来优先探索那些有希望获得高回报的路径
图(b) 展示 PromptAgent 的工作流程,给定一个当前状态(prompt):
- 基础模型先在任务数据集上收集预测错误
- 优化器模型根据错误总结得到错误反馈作为动作
- 优化器模型再根据错误反馈更新提示,过渡到下一状态
通过这种基于错误反馈的试错迭代,PromptAgent 可以有效地将领域知识引入到提示生成中
LLM 标注器(LLM Annotator)
利用大语言模型(LLM)的语义理解与生成能力,对文本、对话等数据执行标注任务(如分类、实体识别、对话意图标注等)的工具/模块
核心:通过提示工程驱动,可实现自动/辅助标注、降低人工成本,同时适配弱监督与多模态场景
本质:
以 LLM 为核心标注主体,替代/辅助人工标注员,通过自然语言指令(Prompt)完成标签生成、映射与去噪的系统
常见于数据预处理、模型微调与弱监督学习流程
区别传统标注工具:
无需编写复杂规则(如正则),直接通过语义理解处理模糊概念(如 "是否包含联系方式"),且支持零样本/少样本快速适配新任务
概念
弱监督、强监督
两种主流形态
形态 核心特点 典型场景 代表工具/框架
LLM驱动的标注工具 可视化平台+AI 预标注,人工审核修正 对话数据标注/多模态标注 LabelLLM、Label Studio(集成LLM插件)
LLM自动标注模块 纯代码化批量标注,支持多模型共识与去噪 大规模文本分类/弱监督训练 LLM-Auto-Labeler、Snorkel+LLM
典型工作流程
数据输入:准备未标注文本 / 对话数据(如用户query、新闻文本)
提示设计:编写任务说明(如 "情感分类:正面 / 负面 / 中性")+ 示例(少样本)
标注生成:LLM 输出标签(如 "正面")及置信度
结果后处理:映射标签、去噪(如多模型投票、Label Model)、人工校验(可选)
标签导出:输出结构化标注数据(如 JSON、CSV)用于模型训练
关键优势与局限
优势
提效降本:自动预标注可将效率提升数倍,减少人工重复劳动
灵活适配:通过 Prompt 快速切换任务(如从情感分析到命名实体识别)
语义理解强:处理复杂语义(如歧义句、领域术语)优于规则驱动标注
局限
标注噪声:LLM 可能生成错误标签,需要去噪或人工校验
成本与延迟:大规模调用 API 存在费用,本地部署需要硬件资源
一致性波动:不同 Prompt 或模型版本可能导致标注结果差异
应用场景
大模型微调数据准备(如对话意图、多轮对话标注)
弱监督学习(如 Snorkel 框架中用 LLM 替代规则标注器)
内容审核与元数据标注(如文本分类、敏感信息识别)
多模态数据标注(如结合 LLM 实现图文 / 音文数据的语义标签生成)
快速上手示例(文本情感分类)
准备数据:"今天天气真好!", "这服务太差了"
编写 Prompt:"请对以下句子进行情感分类,标签为正面 / 负面 / 中性:1. 今天天气真好!2. 这服务太差了"
调用 LLM(如 GPT-3.5):输出标签 "正面", "负面"
后处理:校验标签并导出为训练集
示例
py
import os
import pandas as pd
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import ChatDashScope
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 加载环境变量
load_dotenv()
class LLMAnnotator:
"""LLM文本分类标注器(带多模型共识+标签去噪)"""
def __init__(self, task_desc, labels, few_shot_examples=None):
"""
初始化标注器
:param task_desc: 标注任务描述(如"情感分类")
:param labels: 标签列表(如["正面", "负面", "中性"])
:param few_shot_examples: 少样本示例(可选)
"""
self.task_desc = task_desc
self.labels = labels
self.few_shot = few_shot_examples or []
self.prompt = self._build_prompt()
# 初始化多模型
self.models = {
"gpt-3.5": ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
"ernie-4.0": ChatDashScope(model="ernie-4.0", temperature=0) # 文心一言4.0
}
self.output_parser = StrOutputParser()
def _build_prompt(self):
"""构建标注提示词(少样本+清晰指令)"""
prompt_template = f"""
你是专业的{self.task_desc}标注员,需严格按照要求完成标注:
1. 标注任务:{self.task_desc}
2. 可选标签:{','.join(self.labels)}
3. 标注规则:仅输出标签本身,不添加任何解释、标点或额外内容
4. 示例参考:
"""
# 添加少样本示例
for idx, (text, label) in enumerate(self.few_shot):
prompt_template += f"\n 文本{idx+1}:{text}\n 标签{idx+1}:{label}"
prompt_template += "\n\n请标注以下文本:\n文本:{text}\n标签:"
return ChatPromptTemplate.from_template(prompt_template.strip())
def _single_model_annotate(self, text, model_name):
"""单模型标注(带异常处理)"""
try:
chain = self.prompt | self.models[model_name] | self.output_parser
label = chain.invoke({"text": text}).strip()
# 标签去噪:仅保留合法标签,非法则返回None
return label if label in self.labels else None
except Exception as e:
print(f"模型{model_name}标注失败:{e}")
return None
def annotate(self, texts, consensus_threshold=1):
"""
批量标注(多模型共识)
:param texts: 待标注文本列表
:param consensus_threshold: 共识阈值(≥该数量模型标签一致则采用)
:return: 标注结果DataFrame
"""
results = []
for text in texts:
# 多模型标注
model_labels = {name: self._single_model_annotate(text, name) for name in self.models}
# 统计标签频次
label_counts = {}
for label in model_labels.values():
if label:
label_counts[label] = label_counts.get(label, 0) + 1
# 共识判断
final_label = None
for label, count in label_counts.items():
if count >= consensus_threshold:
final_label = label
break
# 无共识则标记为待人工审核
results.append({
"text": text,
"gpt-3.5_label": model_labels["gpt-3.5"],
"ernie-4.0_label": model_labels["ernie-4.0"],
"final_label": final_label if final_label else "待人工审核"
})
return pd.DataFrame(results)
def export_results(self, df, save_path):
"""导出标注结果为CSV"""
df.to_csv(save_path, index=False, encoding="utf-8")
print(f"标注结果已导出至:{save_path}")
# -------------------------- 测试示例 --------------------------
if __name__ == "__main__":
# 1. 定义标注任务(情感分类)
task_desc = "电商评论情感分类"
labels = ["正面", "负面", "中性"]
# 2. 少样本示例(提升标注准确性)
few_shot = [
("这款商品质量超好,性价比绝了!", "正面"),
("物流太慢了,一周都没到,差评", "负面"),
("商品收到了,和描述一致", "中性")
]
# 3. 初始化标注器
annotator = LLMAnnotator(task_desc, labels, few_shot)
# 4. 待标注文本
texts = [
"今天天气真好!",
"这服务太差了,再也不买了",
"快递速度还可以,包装一般",
"123456" # 无意义文本,测试标签过滤
]
# 5. 执行标注(共识阈值=1:至少1个模型标注有效则采用)
result_df = annotator.annotate(texts)
# 6. 打印并导出结果
print("标注结果:")
print(result_df)
annotator.export_results(result_df, "llm_annotation_result.csv")MCTS
MCTS 的全称是 Monte Carlo Tree Search,蒙特卡洛树搜索
20世纪40年代,由参与曼哈顿计划(原子弹)科学家斯塔尼斯拉夫.乌拉姆发明
因为乌拉姆叔叔经常在摩纳哥蒙特卡洛赌场输钱而得名
蒙特卡洛法是对数学运算的近似估计
当问题无法通过数学推导被求解时,或当计算机无法在指定时间内得到计算结果时,就要考虑是否可以通过蒙特卡洛法来解决问题
实际工作中,一个误差足够小的近似估计可以被接受,因此蒙特卡洛法有广泛的工业应用
AI 领域,蒙特卡洛方法是蒙特卡洛树搜索 MCTS
用博弈树来表示一个游戏
博弈树的每个节点都代表一个状态,下一个状态的集合构成状态的子节点
任意一个棋盘局面是一个状态,该局面下所有可能的落子情况形成的新局面集合,构成该状态的子节点
如果是简单游戏,可以穷举所有状态,根据穷举结果得到最优解
但事实上却无法这么做,拿围棋来说,其状态数量比可观测宇宙的原子数量还要多
19×19 围棋棋盘有 361 个位置,每位置黑子/白子/空,若不考虑围棋规则,所有可能状态理论上限 3^361,约1.7×10^172种
目前计算机技术达不到这样计算量的穷举能力
根据大数定律,当采样数量足够大时,采样样本可以无限近似地表示原分布
蒙特卡洛搜索就是一种用随机采样来作为近似估计的方法,它通过大量自博弈来寻找最有可能走的节点
蒙特卡洛搜索需要定义一个策略,来选择当前局面下最有可能走的子节点
展开这个子节点,然后基于这个节点完成一次自博弈
最后记录自博弈结果并更新相关数据
重复这个过程,直到满足停止条件
UCT(Upper Confidence Bound applied to Trees,树的上置信界)
是蒙特卡洛树搜索(MCTS)里 "选择(Selection)" 阶段的核心公式
选择策略不能只看胜率,因为很可能节点尽管不好,但随机走子时也可能会赢:
在随机模拟中,差的节点也可能因为运气好而获胜,如何避免被这种偶然成功误导?
MCTS 的模拟(Simulation)阶段,算法会从当前节点随机走子直到游戏结束,并用最终结果(赢/输)来更新节点收益
一个本身不好的节点(比如围棋中的坏棋步),在随机走子中可能因为对手也随机走了更差的棋,导致最终 "赢了"
偶然成功会让该节点的收益 Q_i 虚高,如果只看平均收益(利用项),算法可能错误地认为这个节点是好的
博弈次数小时,胜率指标并不置信,为了解决该问题,定义一个 UCT 公式:
- Qi 是 i 节点赢的次数
- Ni 是 i 节点的访问次数
- C 是常数,用来调节博弈次数所占权重
- T 是总访问次数
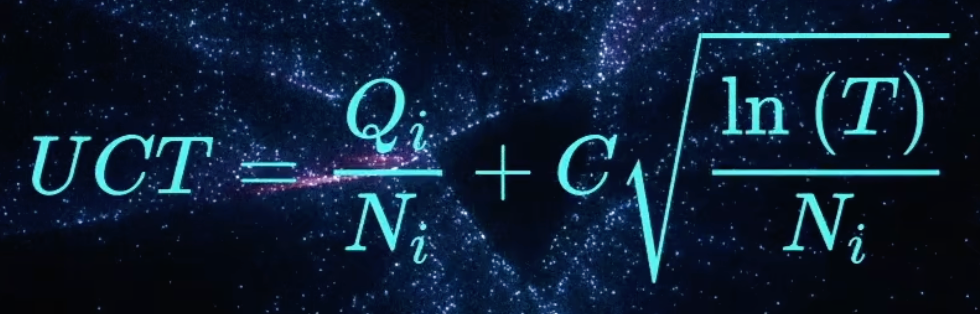
前半部分是胜率,后半部分值随着访问次数的增加,值越来越小
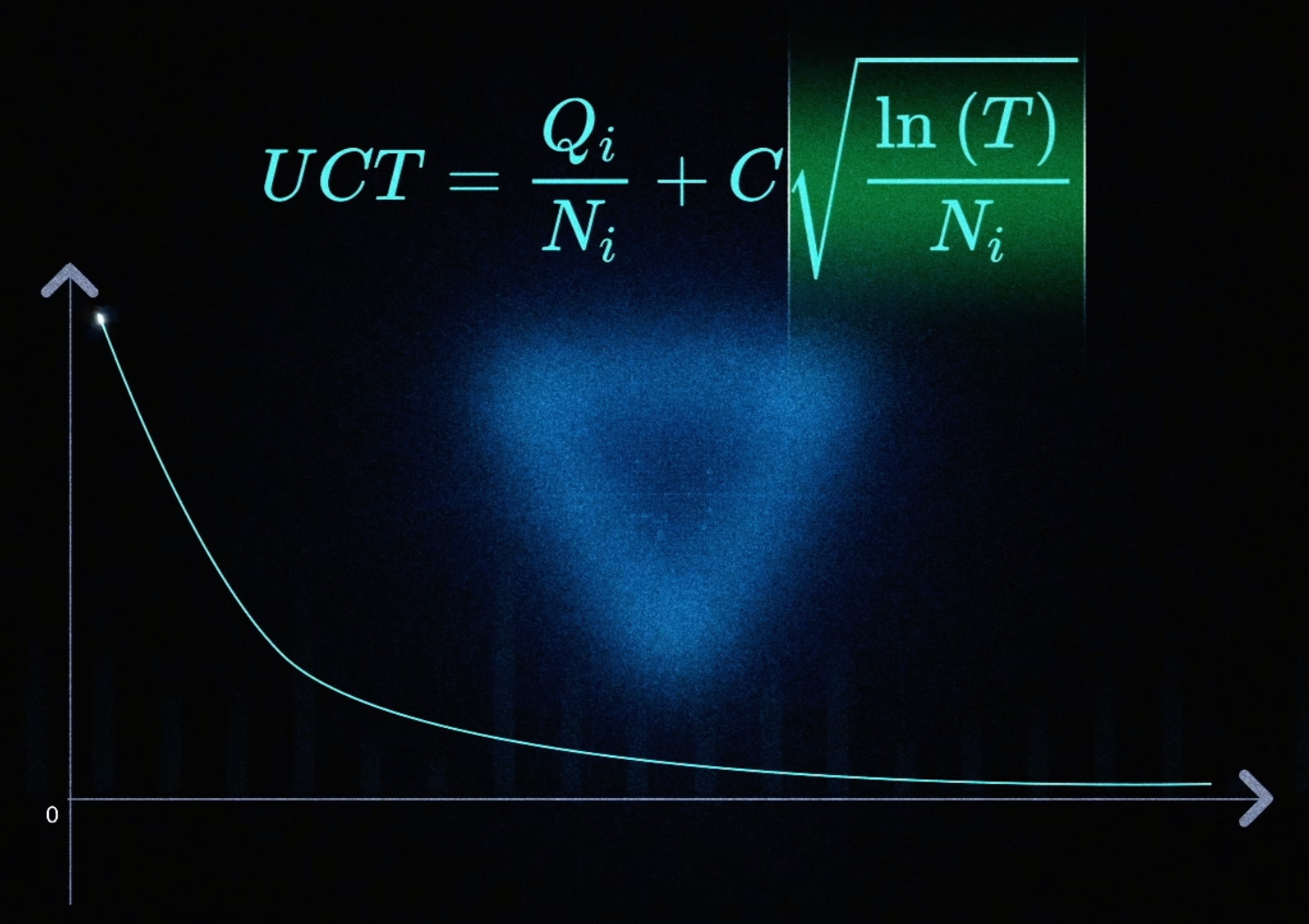
UCT 指导 MCTS 选择还没被统计过的节点,避免"胜率高,置信度低"的问题

不停重复这个自博弈过程,每次都选择 UCT 值最高的那个节点,进行自博弈
重复多次之后,访问次数最多的那个节点就是最佳节点
需要设置蒙特卡洛树搜索的停止条件,比如 10s 之后,或者 100w 次自博弈之后
自博弈次数越多,算法的表现就会越优秀