文章目录
-
- [一、什么是 Top-K 问题(大数据场景)](#一、什么是 Top-K 问题(大数据场景))
- 二、为什么不用排序?
- [三、Top-K 最大值 ------ 小根堆(最常用)](#三、Top-K 最大值 —— 小根堆(最常用))
- [四、Top-K 最小值 ------ 大根堆(最常用)](#四、Top-K 最小值 —— 大根堆(最常用))
一、什么是 Top-K 问题(大数据场景)
Top-K:在海量数据中,找出最大(或最小)的 K 个元素
典型场景:
- 搜索引擎:最热的 K 个关键词
- 日志分析:访问次数最多的 K 个 IP
- 排行榜:分数最高的 K 个用户
- 实时流数据(数据量巨大,不能一次性加载)
二、为什么不用排序?
假设数据量 N = 10^9,K = 100

核心思想:只维护 K 个候选,而不是全部数据
三、Top-K 最大值 ------ 小根堆(最常用)
时间 & 空间复杂度:
- 建堆:O(K)
- 遍历 N 个元素,每次最多一次调整:O(log K)
- 总时间:O(N log K)
- 空间:O(K)
算法流程:
给定一个超大数据集(或数据流),找出最大的 K 个数
约束条件(Top-K 成立的前提):
- N 很大,K 很小
- 数据可能是流式的,不能一次性加载
- 只关心结果集合,不要求排序
只维护"当前最大的 K 个元素",并且随时能快速淘汰其中最小的那个
为什么是「小根堆」
Top-K 最大值,本质是什么?
假设已经选出了 K 个候选:
cpp
[?, ?, ?, ?, ?] ← K 个数当新数据 x 到来时,你只关心一件事:x 能不能进入这 K 个最大值集合?
判断条件:
- 先放入前 K 个元素 → 建小根堆
- 如果 x ≤ 当前最小的候选 → 一定进不了 Top-K
- 如果 x > 当前最小的候选 → 替换它
最后堆中剩下的,就是最大的 K 个数,所以必须 O(1) 拿到「当前 K 个数里最小的那个」
小根堆恰好满足:

算法流程(逐步拆解)
步骤 1:初始化小根堆(容量 ≤ K)
- 前 K 个元素直接入堆
- 构成一个小根堆
此时:
cpp
堆顶 = 当前 Top-K 中的最小值步骤 2:遍历剩余数据(关键逻辑)
对每一个新元素 x:
情况 A:堆未满
cpp
push(x)情况 B:堆已满
cpp
if (x > heap.top()) {
pop(); // 淘汰最小的
push(x); // 加入更大的
}
else {
// x 太小,直接丢弃
}步骤 3:遍历结束
- 堆中剩下的 K 个元素
- 就是全局最大的 K 个值
- 不保证有序(需要可再排序)
堆在内部到底发生了什么?
cpp
index: 0 1 2 3 4
value: [3, 6, 8, 10, 9]小根堆性质:
cpp
parent <= left child
parent <= right child代码实现:
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
// Top-K 最大值
vector<int> topKMax(const vector<int>& data, int K) {
priority_queue<int, vector<int>, greater<int>> minHeap;
for (int x : data) {
if (minHeap.size() < K) {
minHeap.push(x);
} else if (x > minHeap.top()) {
minHeap.pop();
minHeap.push(x);
}
}
vector<int> result;
while (!minHeap.empty()) {
result.push_back(minHeap.top());
minHeap.pop();
}
return result;
}四、Top-K 最小值 ------ 大根堆(最常用)
问题定义
在海量数据(或数据流)中,找出最小的 K 个值
约束依然是:
- N 很大,K 很小
- 数据可能是流式的
- 不允许全量排序
Top-K 最小值,用一个"容量为 K 的大根堆",堆顶保存当前 K 个最小值里"最大的那个"
为什么一定是「大根堆」
Top-K 最小值的本质
假设你已经维护了一组候选:
cpp
[ ?, ?, ?, ?, ? ] ← K 个"最小候选"当新元素 x 到来,你只关心一件事:x 能不能进入"最小的 K 个数"集合?
判断条件是:
- 如果 x >= 当前候选中的最大值→ 它不可能是 Top-K 最小
- 如果 x < 当前候选中的最大值→ 它更"小",应该替换掉那个最大的
所以必须随时 O(1) 拿到当前 K 个候选中"最大的那个"
大根堆恰好满足:
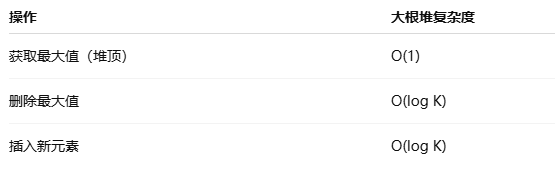
算法整体流程
步骤 1:初始化大根堆(容量 ≤ K)
- 前 K 个元素直接入堆
- 堆顶 = 当前 K 个最小值中的"最大值"
步骤 2:遍历剩余数据(核心判断)
对每一个新元素 x:
情况 A:堆未满
cpp
push(x)情况 B:堆已满
cpp
if (x < heap.top()) {
pop(); // 淘汰"最不小"的那个
push(x); // 加入更小的
}
else {
// x 太大,直接丢弃
}步骤 3:结束
- 堆中剩下的 K 个元素
- 即全局最小的 K 个值
- 顺序不保证
大根堆内部发生了什么?
堆的结构(数组表示)
cpp
index: 0 1 2 3 4
value: [9, 6, 8, 3, 4]大根堆性质:
cpp
parent >= left child
parent >= right child代码实现:
cpp
vector<int> topKMin(const vector<int>& data, int K) {
priority_queue<int> maxHeap;
for (int x : data) {
if (maxHeap.size() < K) {
maxHeap.push(x);
} else if (x < maxHeap.top()) {
maxHeap.pop();
maxHeap.push(x);
}
}
vector<int> result;
while (!maxHeap.empty()) {
result.push_back(maxHeap.top());
maxHeap.pop();
}
return result;
}