文章目录
- 一、Seata的核心概念讲解
- [二、Spring jdbc事务与Seata事务区别](#二、Spring jdbc事务与Seata事务区别)
-
- [1. 作用范围与架构层级](#1. 作用范围与架构层级)
- [2. 核心实现原理](#2. 核心实现原理)
- [3. 数据一致性与隔离性](#3. 数据一致性与隔离性)
- [4. 代码侵入性与配置](#4. 代码侵入性与配置)
- [5. 异常处理与边界情况](#5. 异常处理与边界情况)
- 总结对比表
- 三、Seata中事务4种模式的区别:TA、TCC、SAGA、XA
- [四、分布式事务 TCC 模式下的经典"三座大山"](#四、分布式事务 TCC 模式下的经典“三座大山“)
-
- [1. 空回滚 (Null Rollback)](#1. 空回滚 (Null Rollback))
-
- [问题场景:Cancel 比 Try 先到,或者 Try 根本没执行](#问题场景:Cancel 比 Try 先到,或者 Try 根本没执行)
- [Seata 的解决方案:`tcc_fence_log` 表](#Seata 的解决方案:
tcc_fence_log表)
- [2. 悬挂 (Suspend)](#2. 悬挂 (Suspend))
-
- [问题场景:Cancel 先执行了,Try 后到(网络延迟导致的"迟到")](#问题场景:Cancel 先执行了,Try 后到(网络延迟导致的“迟到”))
- [Seata 的解决方案:状态标记 `SUSPENDED`](#Seata 的解决方案:状态标记
SUSPENDED)
- [3. 幂等 (Idempotence)](#3. 幂等 (Idempotence))
-
- 问题场景:重复提交或回滚
- [Seata 的解决方案:状态机控制](#Seata 的解决方案:状态机控制)
- 总结:一张表解决所有问题
- [五、AT + TCC的混合使用](#五、AT + TCC的混合使用)
-
- [典型适用场景 (Use Cases)](#典型适用场景 (Use Cases))
-
- [场景一:电商下单(扣库存 + 删购物车 + 加积分)](#场景一:电商下单(扣库存 + 删购物车 + 加积分))
- [场景二:金融转账(余额支付 + 记账)](#场景二:金融转账(余额支付 + 记账))
- 场景三:混合数据源操作
- 坑
-
- [1. 全局锁与业务锁的"死锁"风险(最致命的坑)](#1. 全局锁与业务锁的“死锁”风险(最致命的坑))
- [2. AT 和 TCC 的回滚机制完全不同,混合使用容易导致开发者对"一致性"的误判。](#2. AT 和 TCC 的回滚机制完全不同,混合使用容易导致开发者对“一致性”的误判。)
- [3. 超时与悬挂(Hanging)的复杂性](#3. 超时与悬挂(Hanging)的复杂性)
- 六、SAGA模式
-
- [SAGA 模式的使用场景](#SAGA 模式的使用场景)
-
- [1. 跨系统的长周期业务(分钟级到天级)](#1. 跨系统的长周期业务(分钟级到天级))
- [2. 涉及大量非数据库资源的操作](#2. 涉及大量非数据库资源的操作)
- [3. 业务流程经常变更的柔性系统](#3. 业务流程经常变更的柔性系统)
- [Saga 模式的 **"骨架"**](#Saga 模式的 “骨架”)
- [SAGA 选型决策树](#SAGA 选型决策树)
在复杂的微服务系统中,单一的事务方案往往无法满足所有需求。Seata 提供的 AT、TCC、Saga、XA 及 Spring JDBC 事务模式,它们并非互斥,而是可以互补的积木,能够根据业务场景的差异灵活组合、按需选型,真正实现 "一致性、性能、开发效率"三者间的平衡。
一、Seata的核心概念讲解
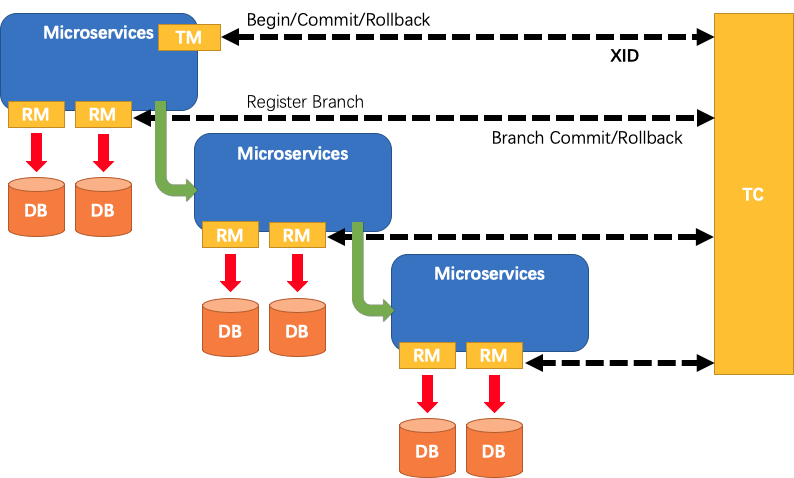
要深入理解 Seata,必须先掌握它的三大角色 、核心概念 以及全局事务的生命周期。
核心角色
Seata 的架构由 1 个 Server 端 和 2 个 Client 端组成。
| 角色 | 全称 | 定位 | 核心职责 |
|---|---|---|---|
| TC | Transaction Coordinator (事务协调者) | Server 端 (独立部署) | 维护全局事务和分支事务的状态; 驱动全局提交或回滚; 管理全局锁。 |
| TM | Transaction Manager (事务管理器) | Client 端 (代码注解) | 定义全局事务的边界(开启、提交、回滚); 通常由业务服务中的 @GlobalTransactional 注解实现。 开始全局事务、提交或回滚全局事务。 |
| RM | Resource Manager (资源管理器) | Client 端 (数据源代理) | 管理分支事务处理的资源 与TC通信以注册分支事务和报告分支事务的状态 驱动分支事务提交或回滚。 |
核心概念
- XID (Transaction ID)
- 定义:全局唯一的事务ID。
- 作用:它是贯穿整个微服务调用链的"身份证"。TM 开启事务时生成,通过 RPC/RMI 透传给下游服务,RM 靠它来注册分支事务。
- Global Transaction (全局事务)
- 定义:由 TM 发起的分布式事务整体。
- 行为:它本身不直接操作数据,而是通过 XID 协调下属的所有分支事务。
- Branch Transaction (分支事务)
- 定义:隶属于某个全局事务的本地事务。
- 形态:每个参与分布式事务的微服务(RM)都会将自己的本地操作注册为一个分支事务。一个全局事务由多个分支事务组成。
- Transaction Group (事务分组)
- 定义 :逻辑上的资源分组(如
my_test_tx_group)。 - 作用:实现多环境隔离(开发/测试/生产)。不同分组的 TC 集群互不干扰。
- 定义 :逻辑上的资源分组(如
全局事务生命周期
一个典型的分布式事务(以 AT 模式为例)的生命周期如下图所示: 详细介绍参见Seata 源码
1. 开启全局事务 (Begin)
- 发起者 :TM(标注了
@GlobalTransactional的服务)。 - 动作:向 TC 发送 RPC 请求,申请开启一个全局事务。
- 结果 :TC 生成一个全局唯一的 XID,并返回给 TM。
2. XID 传播 (Propagation)
- 动作:TM 将 XID 绑定到当前线程上下文(ThreadLocal)。
- 透传:在调用下游服务(RPC/HTTP)时,Seata 的过滤器会自动将 XID 放入请求头中,传递给下游服务。
3. 分支注册 (Registration)
- 发起者:RM(下游服务的数据源代理)。
- 动作 :下游服务收到请求后,解析出 XID。RM 在执行本地 SQL 前,会向 TC 发送注册请求,将当前的本地事务注册为一个分支事务。
- 关键点 :TC 会为该分支事务分配一个
branch_id,并检查全局锁是否冲突。
4. 本地事务执行 (Local Execution)
- 动作 :
- AT 模式 :RM 拦截 SQL,生成
before_image和after_image并写入undo_log表,然后提交本地事务(释放数据库锁,但持有全局锁)。 - TCC 模式 :执行业务自定义的
Try方法。
- AT 模式 :RM 拦截 SQL,生成
5. 全局决议 (Commit/Rollback)
- 发起者:TM。
- 动作 :当所有业务逻辑执行完毕,TM 根据是否有异常,向 TC 发起 全局提交 或 全局回滚 的决议。
- 协调 :
- 提交 :TC 异步通知所有 RM 删除
undo_log(AT 模式)或执行Confirm(TCC 模式)。 - 回滚 :TC 通知所有 RM 根据
undo_log回滚数据(AT 模式)或执行Cancel(TCC 模式)。
- 提交 :TC 异步通知所有 RM 删除
二、Spring jdbc事务与Seata事务区别
结合了 Spring JDBC 的底层原理与 Seata 的分布式事务机制,从作用范围、实现原理、数据一致性、异常处理 等维度针对两者核心区别对比进行了梳理:
1. 作用范围与架构层级
- Spring JDBC 事务(本地事务)
- 范围 :局限于单个 JVM 进程 和单个数据库实例。
- 层级 :工作在 DAO 层 ,本质上是对 JDBC
Connection的封装。 - 依赖:完全依赖于数据库自身的事务能力(如 MySQL 的 InnoDB 引擎)。
- Seata 事务(分布式事务--跨多个数据源)
- 范围 :跨越多个微服务进程 和多个数据库实例。
- 层级 :工作在 RPC/服务调用层,是一个独立的中间件(由 TC、TM、RM 三部分组成)。
- 依赖 :不完全依赖数据库的分布式能力,而是通过自己的 Undo Log 或 TCC 补偿逻辑来实现回滚。
2. 核心实现原理
- Spring JDBC
- 机制 :基于 AOP 代理 。它通过
DataSourceTransactionManager拦截方法,在方法执行前调用Connection.setAutoCommit(false),执行成功后调用commit(),异常时调用rollback()。 - 回滚手段 :利用数据库原生的 Undo Log 进行物理回滚。
- 机制 :基于 AOP 代理 。它通过
- Seata (以 AT 模式为例)
- 机制 :基于 两阶段提交 (2PC) 的演变 。
- 一阶段 :业务 SQL 和 Undo Log (数据镜像)在同一本地事务中提交。此时数据已真实更新,但 Seata 会持有全局锁。
- 二阶段 :
- 提交:异步快速删除 Undo Log。
- 回滚:根据 Undo Log 中的镜像,生成反向 SQL 进行补偿更新(覆盖数据)。
- 回滚手段:应用层通过 SQL 撤销数据,而非数据库内部回滚。
- 机制 :基于 两阶段提交 (2PC) 的演变 。
3. 数据一致性与隔离性
- Spring JDBC
- 一致性 :提供 强一致性 (ACID)。
- 隔离性:依赖数据库的隔离级别(如可重复读、串行化),通过数据库锁(行锁、表锁)实现。
- Seata
- 一致性 :AT 模式提供最终一致性(二阶段提交是异步的);XA 模式提供强一致性(但性能差)。
- 隔离性 :
- 读隔离 :Seata AT 模式默认是"读未提交"(Read Uncommitted),为了保证一致性,通常需要使用
SELECT FOR UPDATE来申请全局锁。 - 写隔离 :通过 全局锁 防止脏写,而不是数据库原生的锁。
- 读隔离 :Seata AT 模式默认是"读未提交"(Read Uncommitted),为了保证一致性,通常需要使用
4. 代码侵入性与配置
- Spring JDBC
- 注解 :使用
@Transactional。 - 配置 :配置普通的
DataSource(如 HikariCP)和DataSourceTransactionManager。 - 侵入性:低,通常只需加注解。
- 注解 :使用
- Seata
- 注解 :全局入口使用
@GlobalTransactional,分支事务通常仍保留@Transactional。 - 配置 :必须配置
DataSourceProxy(数据源代理)和 Seata 的TransactionManager,且需要独立部署 Seata Server (TC)。 - 侵入性:中等。AT 模式对业务代码无侵入(但需建表),TCC/Saga 模式需要编写补偿逻辑。
- 注解 :全局入口使用
5. 异常处理与边界情况
- Spring JDBC
- 异常:处理数据库约束异常(如唯一键冲突)、连接超时等。
- 边界:只关注单库的 ACID,不考虑网络分区或跨服务调用失败。
- Seata
- 异常 :需处理复杂的分布式特有问题:
- 空回滚:Try 未执行,Cancel 先到了。
- 业务悬挂:Cancel 执行了,迟到的 Try 才来。
- 幂等性:网络重试导致的重复提交。
- 边界:必须考虑网络故障、TC 服务宕机、分支事务状态不一致等极端情况。
- 异常 :需处理复杂的分布式特有问题:
总结对比表
| 维度 | Spring JDBC 事务 | Seata 事务 (AT 模式) |
|---|---|---|
| 本质 | 数据库本地事务的封装 | 分布式事务协调器 |
| 核心机制 | JDBC Connection + 数据库锁 | 两阶段提交 + Undo Log + 全局锁 |
| 一致性 | 强一致性 (ACID) | 最终一致性 |
| 回滚方式 | 数据库 Undo Log 物理回滚 | 应用层反向 SQL 补偿 |
| 注解 | @Transactional |
@GlobalTransactional (入口) |
| 配置组件 | DataSource + DataSourceTransactionManager |
DataSourceProxy + Seata Server |
| 适用场景 | 单体应用、单数据库微服务 | 跨服务、跨数据库的微服务架构 |
| 一句话总结: | ||
| Spring JDBC 事务是"单兵作战"的武器,管好自己连接的那一个数据库; | ||
| Seata 是"联合作战"的指挥官,协调多个 Spring JDBC 事务(或其他资源)共同进退。 |
三、Seata中事务4种模式的区别:TA、TCC、SAGA、XA
Seata 的四种事务模式(AT、TCC、SAGA、XA)本质上是为了解决不同场景下的分布式事务问题。它们在代码侵入性 、一致性强度 、性能 和适用场景上有显著区别。
为了让你更直观地理解,总结了一个核心对比表,随后详细拆解每种模式。
核心对比一览表
| 特性 | AT 模式 (默认推荐) | TCC 模式 | SAGA 模式 | XA 模式 |
|---|---|---|---|---|
| 代码侵入性 | 无侵入 (仅注解) | 高侵入 (需写3个接口) | 中侵入 (需写补偿逻辑) | 无侵入 (仅注解) |
| 一致性 | 最终一致性 | 最终一致性 | 最终一致性 | 强一致性 |
| 性能 | ⭐⭐⭐⭐ (一阶段提交) | ⭐⭐⭐⭐ (无数据库锁) | ⭐⭐⭐ (长流程) | ⭐ (锁持有到第二阶段) |
| 实现原理 | 两阶段 + 自动生成回滚日志 | 两阶段 + 手动预留/确认/取消 | 长事务 + 补偿回滚 | 两阶段提交协议 |
| 适用场景 | 通用微服务 (CRUD) | 复杂业务/非数据库资源 | 长流程/异步化业务 | 金融核心/强一致要求 |
详细模式解析
1. AT 模式 (Automatic Transaction)
- 定位 :默认推荐,对业务无侵入的通用解决方案。
- 核心原理 :
- 一阶段 :你执行 SQL 修改数据时,Seata 会通过数据源代理,自动生成一条
undo_log记录(包含修改前后的镜像)。业务数据和回滚日志在同一个本地事务中提交。 - 二阶段 :
- 提交 :异步删除
undo_log。 - 回滚 :根据
undo_log中的镜像,生成反向 SQL 恢复数据。
- 提交 :异步删除
- 一阶段 :你执行 SQL 修改数据时,Seata 会通过数据源代理,自动生成一条
- 优点 :开发几乎不用改代码,只需加
@GlobalTransactional注解。 - 缺点 :依赖数据库(目前支持 MySQL, Oracle, PostgreSQL 等),且
undo_log表会带来轻微性能损耗。 - 适用:绝大多数基于关系型数据库的微服务场景。
- 目标:在分布式全局事务中,通过数据库层面"行锁 + undo_log 回滚信息"保证分支事务的可回滚性与并发一致性
- 关键机制 :
- 在全局事务中,客户端拦截 SQL 并收集 undo 信息(before/after image 或逆向 SQL),保存在ConnectionContext(内存)。
- 提交时先向 TC 注册分支(branchRegister),把 undo_log 刷入业务库,然后提交本地 DB;失败则在 Phase‑2 回滚时通过 undo_log 恢复数据。
- 回滚时(Phase‑2),RM 从 undo_log 读取并执行逆向 SQL,然后删除对应 undo_log 记录。
undo_log表结构
目前支持mysql、pg、kingbase、dm、sqlserver、oracle等传统关系型数据库
sql
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
ALTER TABLE `undo_log` ADD INDEX `ix_log_created` (`log_created`);2. TCC 模式 (Try-Confirm-Cancel)
- 定位 :高性能、灵活的业务自定义模式。
- 核心原理 : TCC 模式将一个分布式业务操作拆成三步,需要开发者手动实现三个逻辑:
- Try:预留/准备资源(不做最终提交),尝试执行。检查业务规则,并预留资源(如:冻结库存)
- Confirm:真正提交(释放预留并完成业务):确认执行。真正提交业务(如:扣减冻结的库存)。通常要求 Confirm 一定成功。
- Cancel:回滚/释放预留(如果失败或超时):取消执行。释放预留的资源(如:解冻库存)。
- 优点 :性能极高(Try 阶段只预留资源,不长期持有数据库锁),支持非数据库资源(如 Redis、MQ、第三方接口)。
- 缺点 :代码侵入性大,需要为每个业务写三套逻辑。需要处理幂等 、空回滚 、悬挂三大难题(Seata 1.5.1+ 提供了 TCC Fence 自动解决)。
- 适用:对性能要求极高、涉及非事务性资源(如 Redis)、复杂业务流程(如电商下单)。
- 适合场景 :
- 业务需要显式的"预留 + 确认/取消"流程(例如库存预扣、航班座位预留、分布式消息事务等)
- 无法或不想依赖 DB 行级 undo_log(AT 模式)来回滚,但业务能实现幂等的 Confirm/Cancel 操作
- 不适合场景:无法实现幂等或无状态的 confirm/cancel;或 Try 无法做到资源隔离/预留
tcc fence log
目前支持mysql、pg、oracle、oceanbase关系型数据库
sql
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT 'status(tried:1;committed:2;rollbacked:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;3. SAGA 模式
- 定位 :长事务解决方案,适合由多个子事务组成的复杂流程。
- 核心原理 :
- 将一个大事务拆分为多个按顺序执行的本地事务。
- 如果某个步骤失败,SAGA 会按照相反的顺序,执行之前所有步骤的补偿操作(Compensate)。
- 通常通过状态机来定义流程和对应的补偿逻辑。
- 优点:服务间解耦,适合长时间运行的业务(如订单履约、物流调度)。
- 缺点:业务逻辑需要拆分,开发复杂度较高。在回滚时,中间状态可能已被其他服务读取(弱一致性)。
- 适用:业务流程长、涉及多个服务、允许异步执行的场景。
表定义
4. XA 模式
- 定位 :传统的强一致性解决方案。
- 核心原理 :基于标准的 XA 协议(两阶段提交)。
- 一阶段 :所有分支事务执行 SQL,但不提交(数据库持有行锁)。
- 二阶段:TC 通知所有分支提交或回滚。
- 优点 :强一致性(ACID),只要事务提交,数据立即一致。理论最严谨。
- 缺点 :性能差(因为一阶段完成后,锁会一直持有到二阶段结束,阻塞其他事务)。
- 适用:对一致性要求极高、无法接受任何中间状态的场景(如银行核心账务系统)。
注意:需要数据库实现了XA接口,目前仅支持 MySQL, Oracle and MariaDB
选型建议
- 首选 AT 模式:如果你的业务是标准的 CRUD,基于 MySQL/Oracle/PG,且对性能要求不是变态级的,AT 模式是最佳选择(开发成本最低)。
- 性能瓶颈选 TCC:如果并发极高,或者涉及 Redis/文件存储等非数据库资源,或者业务逻辑复杂无法用 SQL 直接描述,请使用 TCC。
- 长流程选 SAGA:如果业务流程长达几分钟甚至几小时(如请假审批流、供应链流转),请使用 SAGA。
- 金融级强一致选 XA:如果你是做银行转账核心系统,绝不允许"转账中"的状态被看到,且愿意牺牲性能来换取绝对一致性,请使用 XA。
四、分布式事务 TCC 模式下的经典"三座大山"
空回滚、悬挂、幂等是分布式事务 TCC 模式下的经典"三座大山" 。它们通常由网络不稳定(超时、重传、乱序)引起。
Seata 在 1.5.1 版本之前,这些问题需要开发者自己通过建表、写逻辑来解决,代码侵入性很强。但从 Seata 1.5.1 版本开始 ,引入了 TCC Fence(TCC 篱笆)机制 ,通过一个统一的事务控制表 tcc_fence_log在框架层面(而非业务代码层面)完美解决了这三个问题。
1. 空回滚 (Null Rollback)
问题场景:Cancel 比 Try 先到,或者 Try 根本没执行
想象一下:全局事务开始了,但因为网络抖动或机器宕机,Try 方法根本没执行成功(比如 RPC 调用失败了)。但是,全局事务超时了,TC(事务协调者)决定回滚,于是发起了 Cancel 调用。
- 后果 :如果 Cancel 方法不做判断,直接执行"解冻库存"逻辑,而实际上库存根本没冻结(Try 没执行),这就会导致资损(比如库存变成负数,或者多退了钱)。
- 本质:Cancel 方法需要判断:"我对应的 Try 执行了吗?"
Seata 的解决方案:tcc_fence_log 表
Seata 引入了一张表 tcc_fence_log。
- Try 阶段 :只要 Try 方法一执行成功,Seata 就会往这张表里插入一条记录,状态标记为
TRIED - Cancel 阶段 :在执行 Cancel 逻辑前,先查这张表。
- 如果查不到记录 ➜ 说明 Try 根本没执行(或者执行失败了)。
- 动作 :直接空回滚(什么都不做,直接返回成功),避免资损。
2. 悬挂 (Suspend)
问题场景:Cancel 先执行了,Try 后到(网络延迟导致的"迟到")
空回滚的"孪生兄弟"。
场景是:Try 方法调用时网络拥堵,导致全局事务超时,TC 发起了 Cancel。Cancel 执行完了,全局事务结束了。但是,那个拥堵的 Try 请求终于到达了服务器,并且成功执行了(预留了资源)。
- 后果 :资源被预留了(比如库存冻结了),但后续再也没有 Confirm 或 Cancel 来释放它。这笔资源就永久"悬挂" 在那里,既不能用也不能退。
- 本质:Try 方法需要判断:"在我来之前,是不是已经有人(Cancel)把事务给结束了?"
Seata 的解决方案:状态标记 SUSPENDED
- Cancel 阶段 :当 Cancel 执行时,如果发现
tcc_fence_log表里没有记录(即空回滚场景),Seata 不仅不报错,反而会插入一条状态为SUSPENDED的记录。 - Try 阶段 :当那个"迟到"的 Try 到来时,它首先会检查
tcc_fence_log表。- 如果发现状态是
SUSPENDED➜ 说明这个全局事务已经被取消了。 - 动作 :Try 方法拒绝执行,直接返回失败。从而防止资源被错误地预留。
- 如果发现状态是
3. 幂等 (Idempotence)
问题场景:重复提交或回滚
在网络超时或抖动时,TC 可能没收到 RM(资源管理器)的确认响应,于是 TC 会重试发送 Confirm 或 Cancel 指令。
- 后果:如果你的 Cancel 方法写的是"扣减库存 100",第一次执行成功了,第二次重试又执行一次,库存就扣了 200。这就是严重的数据错误。
- 本质:Confirm/Cancel 必须保证"无论调用多少次,结果一致"。
Seata 的解决方案:状态机控制
- 状态记录 :
tcc_fence_log表里有一个status字段。 - 执行流程 :
- Confirm/Cancel 执行前 :检查表里是否有记录且状态是否已经是
COMMITTED或ROLLBACKED。 - 如果是 :直接返回成功,不再执行业务逻辑。
- 如果不是 :执行业务逻辑,执行成功后将状态更新为
COMMITTED或ROLLBACKED。
- Confirm/Cancel 执行前 :检查表里是否有记录且状态是否已经是
总结:一张表解决所有问题
Seata 1.5.1+ 通过 tcc_fence_log 这张表,利用数据库的唯一索引和状态字段,完美闭环了这三个问题:
| 问题 | 触发原因 | Seata 的防御手段 | 核心逻辑 |
|---|---|---|---|
| 空回滚 | Try 失败/未执行,Cancel 先到 | 查状态 | Cancel 执行前查表,无记录则直接返回(防资损)。 |
| 悬挂 | Try 迟到,Cancel 已执行 | 插标记 | Cancel 空回滚时插一条 SUSPENDED 记录;Try 到来时若发现此标记,则拒绝执行。 |
| 幂等 | 网络重试导致多次调用 | 状态机 | Confirm/Cancel 执行前先看状态,已完结则不再执行业务代码。 |
实操建议 :
如果你使用的是 Seata 1.5.1 及以上版本,只需要在 @TwoPhaseBusinessAction 注解中配置 useTCCFence = true,并建好 tcc_fence_log 表,框架就会自动帮你处理上述所有逻辑,你只需要关注业务本身即可。
五、AT + TCC的混合使用
AT + TCC 的混合使用 是 Seata 生产环境的"黄金搭档"。
这种混合并非技术上的耦合,而是一种基于业务场景的分层选型 。
核心思想是:让 AT 模式处理"简单的 CRUD",让 TCC 模式处理"复杂的资源预留"。
- 不要试图在同一个服务里同时开启 AT 和 TCC(除非做特殊降级)。
- 应该 在微服务架构层面,根据服务的核心程度 和资源类型 进行选型:
- 非核心、简单 CRUD、快速上线 -> AT。
- 核心资金/库存、需预占资源、高并发 -> TCC 。
通过这种组合,你既不需要为了强一致性去承受全量 TCC 的开发成本,也不需要为了开发效率去承受 AT 模式在核心业务上的数据风险。
典型适用场景 (Use Cases)
这种混合模式在以下场景中是"最佳实践":
场景一:电商下单(扣库存 + 删购物车 + 加积分)
- 购物车 & 积分服务 :使用 AT 模式。因为它们对隔离性要求不高,且逻辑简单。
- 库存服务 :使用 TCC 模式。因为需要防止超卖,必须先"冻结"库存,不能直接扣减。
- 流程 :用户下单 -> AT 事务开始 -> 购物车删除商品(AT) -> 库存冻结(TCC Try) -> 支付回调 -> AT 事务提交 -> 库存扣减(TCC Confirm)。
场景二:金融转账(余额支付 + 记账)
- 记账服务 (Journal) :使用 AT 模式。流水记录一旦生成很难回滚,且是追加写。
- 账户服务 (Account) :使用 TCC 模式 。先
Try预扣金额(检查余额并冻结),支付成功后Confirm实际扣款。 - 流程 :转账请求 -> AT 事务 -> 账户预扣(TCC Try) -> 生成流水(AT) -> 对方入账(AT) -> 账户扣款(TCC Confirm)。
场景三:混合数据源操作
- MySQL 操作 :使用 AT 模式。
- Redis / MQ 操作 :使用 TCC 模式 。因为 AT 模式主要针对关系型数据库,对 Redis 或 MQ 的事务支持较弱。此时可以封装一个 TCC 接口,在
Try中操作 Redis,在Cancel中回滚 Redis。
坑
1. 全局锁与业务锁的"死锁"风险(最致命的坑)
这是 AT 和 TCC 混合时最常见的性能杀手。
- 坑在哪里 :
- AT 模式 依赖 Seata 的全局锁(Global Lock)来保证隔离性。
- TCC 模式 通常在
Try阶段会加业务锁(如数据库行锁、Redis 分布式锁)来冻结资源。
- 避坑 :严格控制全局锁的等待时间(
defaultGlobalTransactionTimeout),或者在 TCC 的Try阶段尽量使用无锁方案(如基于 Redis Lua 的原子操作),避免持有数据库行锁过久
2. AT 和 TCC 的回滚机制完全不同,混合使用容易导致开发者对"一致性"的误判。
- 坑在哪里 :
- AT 是"后置回滚" :数据在一阶段就真实提交了,二阶段回滚是通过
undo_log生成反向 SQL 覆盖数据。 - TCC 是"前置预留":一阶段只是冻结/预留,二阶段才是真实提交或释放。
- AT 是"后置回滚" :数据在一阶段就真实提交了,二阶段回滚是通过
- 数据不一致场景 :
- 假设流程是:
Service A (AT) -> Service B (TCC Try)。 - 如果 AT 成功提交,TCC Try 也成功冻结了资源。
- 此时如果全局事务回滚,AT 会通过反向 SQL 把数据改回去,但 TCC 会执行 Cancel 释放资源。
- 风险 :如果 AT 的反向 SQL 执行失败(如数据库主从延迟、SQL 语法不兼容),而 TCC 的 Cancel 已经成功,会导致业务状态(TCC)已回滚,但记账数据(AT)却没回滚干净,造成资损。
- 假设流程是:
- 避坑:核心资金/库存服务坚决用 TCC,非核心日志/通知服务用 AT。尽量避免"核心数据"由 AT 模式管理。
3. 超时与悬挂(Hanging)的复杂性
TCC 模式特有的"悬挂"问题,在混合调用时更难排查。
- 坑在哪里 :
- 当 AT 事务调用 TCC 服务时,如果网络出现"抖动"或"超时重试"。
- 场景:AT 发起调用,TCC 的 Try 成功了,但响应包丢了。AT 以为 Try 失败,直接回滚(触发 TCC Cancel)。
- 随后:那个"迟到"的 Try 请求到达(网络恢复),此时 Cancel 已经执行完了。
- 结果 :Try 成功执行(预留了资源),但后续没有 Confirm 也没有 Cancel。这就是悬挂。
- 避坑 :必须开启 Seata 的 TCC Fence(篱笆)机制 (即
tcc_fence_log表)。它能自动拦截这种"迟到"的 Try 请求,防止悬挂。
六、SAGA模式
SAGA 模式是处理长周期事务 和复杂业务流程 的利器,但它也是最容易让开发者"踩坑"的模式,因为它的设计哲学是牺牲隔离性来换取性能和柔性。
SAGA 模式的使用场景
SAGA 的核心公式是:长事务 + 最终一致性 + 补偿机制 。
当你遇到以下场景时,SAGA 往往是比 TCC 或 AT 更好的选择:
1. 跨系统的长周期业务(分钟级到天级)
这是 SAGA 的主场。如果业务流程涉及人工审核、物流运输、第三方回调(如银行转账),耗时可能长达几分钟甚至几天。
- 典型例子:旅游预订(订机票+订酒店+租车)、供应链采购(下单+生产+发货+签收)。
2. 涉及大量非数据库资源的操作
当你的事务不仅操作数据库,还要发短信、发邮件、调用外部 API、操作文件系统时。
- 典型例子:用户注册成功后,发欢迎邮件、初始化用户文件目录、赠送新人积分。
3. 业务流程经常变更的柔性系统
- 典型例子:电商促销流程,可能今天要先发券再扣库存,明天要先抽奖再扣库存。
Saga 模式的 "骨架"
这三张表是Saga 模式的 "骨架" ,解决了 "流程怎么跑" 和 "状态不丢失" 的问题(即可靠性 和幂等性 的底层支撑),保证了事务流程不会断、不会丢。
但 "血肉"(业务表的加减乘除、冻结字段设计)还是需要你来写的,否则就会掉进"脏读/脏写"的坑里。
seata_state_machine_def(Definition) - "流程图纸"- 作用 :它定义了模板。就像编译好的代码,告诉 Seata 一个事务应该长什么样。
- 解决的坑 :流程定义的存储。保证你写的那个 JSON 流程不会丢,服务重启后还能读取到。
seata_state_machine_inst(Instance) - "订单档案"- 作用 :它记录了某一次具体事务的全局上下文。
- 解决的坑 :
- 全局事务追踪 :通过
id或business_key,你可以查到整个事务跑得怎么样了。 - 幂等性基础 :如果同一个
business_key重复提交,框架可以通过查询这张表发现"哎,这个订单号已经有一个实例在跑了",从而拒绝重复提交。
- 全局事务追踪 :通过
seata_state_inst(State Instance) - "执行日志"- 作用 :记录每一个节点的执行细节。
- 解决的坑 :
- 断点续跑 :如果服务在执行某个节点时宕机了,重启后 Seata 会根据这张表里记录的
status,发现某个节点还在RU(运行中)但没有后续日志,就会触发回滚或重试。 - 回溯排查:出了问题,看这张表就能知道是卡在哪个服务调用上了。
- 断点续跑 :如果服务在执行某个节点时宕机了,重启后 Seata 会根据这张表里记录的
SAGA 选型决策树
- 业务流程是否超过 1 分钟? (如物流、审批)
- 是否涉及非数据库操作? (发短信、调第三方)
- 是否能容忍中间状态(脏读)?
都是的情况下,才考虑使用SAGA
SAGA 是一把双刃剑,它能解决长事务的性能问题,但把数据一致性的责任完全交给了业务代码。除非你有把握写好补偿逻辑和处理幂等,否则不要轻易在核心资金链路使用。