
前言
在 Linux 系统编程中,"一切皆文件" 和 "缓冲区" 是两个贯穿始终的核心概念。前者构建了 Linux 系统资源访问的统一模型,让键盘、显示器、网卡等设备都能通过文件接口操作;后者则是提升 IO 效率的关键,协调了高速 CPU 与低速外设的性能差异。
很多开发者在使用文件 IO 时,只知道调用
fopen、write等接口,却不理解 "为什么键盘能当文件读""为什么printf需要fflush才能确保输出"。本文将从底层原理出发,深入拆解 "一切皆文件" 的实现机制和缓冲区的核心逻辑,带你从 "会用" 升级到 "懂原理",甚至能手动封装一个简易的 IO 库。下面就让我们正式开始吧!
一、深入理解 Linux "一切皆文件":不止是哲学,更是技术实现
提到 Linux 的 "一切皆文件",很多人会把它当作一句抽象的设计哲学。但实际上,这是一套严谨的技术实现 ------ 通过统一的文件模型,将磁盘文件、硬件设备、进程、管道等所有系统资源,都抽象为 "文件",并提供一套标准的 IO 接口(open、read、write、close)进行操作。
1.1 "一切皆文件" 的核心优势:一套接口操作所有资源
"一切皆文件" 的设计带来了一个巨大的好处:开发者只需掌握一套 IO 接口,就能操作系统中的绝大部分资源。比如:
- 读取磁盘文件内容,用
read;- 从键盘获取输入,用
read;- 向显示器输出内容,用
write;- 给网络套接字发送数据,用
write;- 查看进程状态(
/proc/[pid]/status),本质也是读取 "进程文件"。
举个直观的例子,我们可以用同样的cat命令查看磁盘文件和系统信息:
bash
# 查看磁盘文件
cat test.txt
# 查看CPU信息(/proc/cpuinfo是内核动态生成的虚拟文件)
cat /proc/cpuinfo
# 查看内存使用情况
cat /proc/meminfo这三个操作的底层都调用了**read**系统调用,但访问的资源完全不同 ------ 磁盘、CPU、内存。这就是 "一切皆文件" 的魅力:屏蔽了不同资源的底层差异,提供了统一的访问方式。
1.2 底层实现:三个关键结构体撑起统一模型
"一切皆文件" 的实现,核心依赖内核中的三个关键结构体:task_struct(进程控制块)、file(文件元数据)、file_operations(文件操作函数集合)。它们的关系的是:进程通过文件描述符找到file结构体,file结构体通过file_operations找到对应资源的具体操作方法。
1.2.1 核心结构体解析(内核源码级)
我们以 Linux 内核 3.10 版本为例(可通过uname -a查看内核版本),三个结构体的定义位置如下:
task_struct(进程控制块):/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/sched.hfile(文件元数据):/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/fs.hfile_operations(文件操作集合):/usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/fs.h
1. file结构体:描述打开文件的元数据
file结构体存储了一个打开文件的核心信息,无论是磁盘文件还是键盘设备,一旦被打开,内核都会创建一个file结构体:
cpp
struct file {
// 指向文件操作函数集合的指针(核心)
const struct file_operations *f_op;
// 文件当前读写位置
loff_t f_pos;
// 文件引用计数(多个进程可共享一个file结构体)
atomic_long_t f_count;
// 文件打开标志(如O_RDONLY、O_APPEND)
unsigned int f_flags;
// 文件访问模式(只读、只写、读写)
fmode_t f_mode;
// 关联的inode节点(存储文件的磁盘属性)
struct inode *f_inode;
// 其他成员省略...
};其中最核心的是**f_op指针,它指向file_operations**结构体 ------ 这个结构体是 "一切皆文件" 的关键,封装了该文件的所有操作方法。
2. file_operations结构体:统一的操作函数接口
file_operations是一个函数指针集合,包含了read、write、close等所有文件操作的接口。不同类型的文件(磁盘文件、键盘、网卡)会实现自己的read、write方法,然后通过file结构体的f_op指针关联起来。
简化后的**file_operations**定义如下:
cpp
struct file_operations {
// 模块所有者(驱动开发相关)
struct module *owner;
// 改变文件读写位置
loff_t (*llseek) (struct file *, loff_t, int);
// 读操作(核心)
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
// 写操作(核心)
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
// 异步读
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
// 异步写
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
// 关闭文件
int (*release) (struct inode *, struct file *);
// 其他操作(如ioctl、mmap等)省略...
};关键逻辑 :当我们调用read(fd, buf, len)系统调用时,内核会:
- 通过文件描述符
fd,找到进程**files_struct**中的file结构体;- 调用**
file->f_op->read**方法,执行该文件的具体读操作;- 不同类型的文件,**
read**方法的实现完全不同:
- 磁盘文件 :
read方法会调用磁盘驱动,从磁盘读取数据到内存;- 键盘 :
read方法会调用键盘驱动,等待用户输入并返回数据;- 网卡 :
read方法会调用网卡驱动,从网卡缓冲区读取网络数据。
这就是 "一切皆文件" 的底层实现:统一的接口(read/write)+ 不同的实现(file_operations),屏蔽了硬件差异。
3. task_struct与files_struct:进程与文件的关联
每个进程都有一个**task_struct(进程控制块),其中包含一个指向files_struct的指针,files_struct**存储了进程打开的所有文件描述符:
cpp
// 进程控制块
struct task_struct {
// 指向进程的文件表
struct files_struct *files;
// 其他成员省略...
};
// 进程文件表
struct files_struct {
// 文件描述符数组(fd是数组下标)
struct file __rcu *fd_array[NR_OPEN_DEFAULT];
// 其他成员省略...
};结合之前的知识,整个关联链路是:进程(task_struct) → files_struct → fd_array[fd] → file → file_operations → 具体操作(read/write)
1.3 实战验证:不同资源的文件操作
我们通过代码验证:无论是磁盘文件、键盘(标准输入)还是显示器(标准输出),都可以用**read/write**系统调用操作。
实战 1:读取键盘输入(标准输入 fd=0)
cpp
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
char buf[1024];
printf("请输入内容(按回车结束):");
fflush(stdout); // 刷新缓冲区,确保提示语立即显示
// 从键盘(fd=0)读取数据,本质是调用键盘的read方法
ssize_t read_len = read(0, buf, sizeof(buf) - 1);
if (read_len < 0) {
perror("read error");
return 1;
}
buf[read_len] = '\0'; // 添加字符串结束符
printf("你输入的内容:%s", buf);
return 0;
}编译运行:
bash
gcc -o read_keyboard read_keyboard.c
./read_keyboard运行结果:
请输入内容(按回车结束):hello 一切皆文件!
你输入的内容:hello 一切皆文件!实战 2:向显示器输出(标准输出 fd=1)
cpp
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
const char *msg = "向显示器输出:hello write!\n";
// 向显示器(fd=1)写入数据,调用显示器的write方法
ssize_t write_len = write(1, msg, strlen(msg));
if (write_len < 0) {
perror("write error");
return 1;
}
printf("实际写入字节数:%zd\n", write_len);
return 0;
}编译运行:
bash
gcc -o write_display write_display.c
./write_display运行结果:
向显示器输出:hello write!
实际写入字节数:25实战 3:读取虚拟文件(/proc/uptime)
/proc/uptime是内核生成的虚拟文件,存储系统运行时间,我们可以用read读取它:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main() {
// 打开虚拟文件/proc/uptime
int fd = open("/proc/uptime", O_RDONLY);
if (fd < 0) {
perror("open error");
return 1;
}
char buf[128];
ssize_t read_len = read(fd, buf, sizeof(buf) - 1);
if (read_len < 0) {
perror("read error");
close(fd);
return 1;
}
buf[read_len] = '\0';
printf("系统运行时间:%s", buf);
close(fd);
return 0;
}编译运行:
bash
gcc -o read_proc read_proc.c
./read_proc运行结果:
系统运行时间:12345.67 87654.32其中第一个数字是系统总运行时间(秒),第二个是空闲时间。
这三个实战充分说明:无论是硬件设备(键盘、显示器)还是虚拟文件(/proc/uptime),都可以通过统一的open、read、write接口操作 ------ 这就是 "一切皆文件" 的实战体现。
下面用一张图片总结一下:
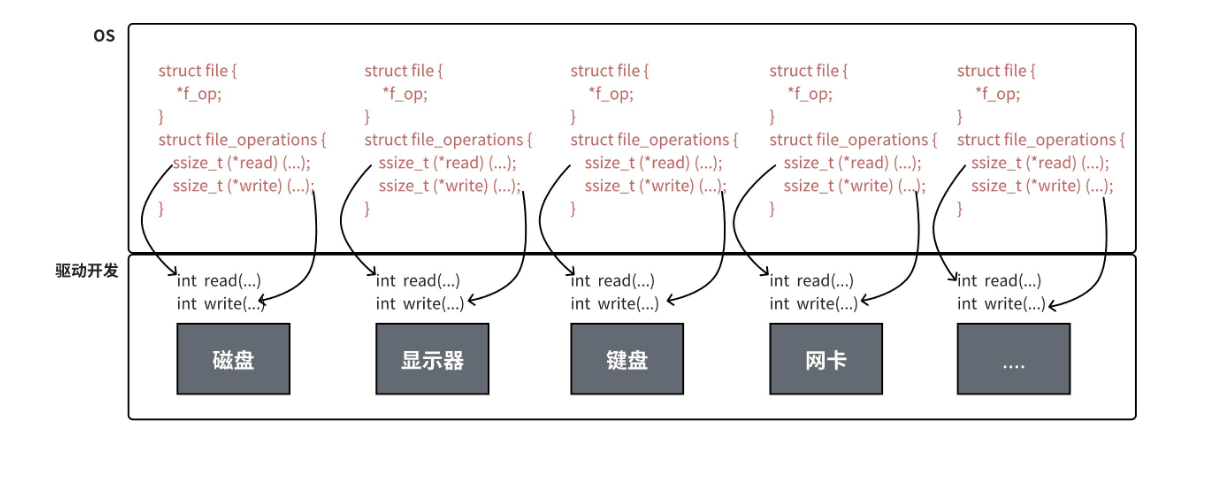
上图中的外设,每个设备都可以有自己的read、write,但⼀定是对应着不同的操作方法。但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只用file便可调取 Linux 系统中绝大部分的资源。这就是"linux下⼀切皆文件"这一思想的的核心理解。
二、缓冲区:IO 效率的 "隐形加速器"
理解了 "一切皆文件",我们再来看 IO 效率的核心 ------ 缓冲区。很多开发者都遇到过这样的问题:用**printf输出内容,有时候能立即显示,有时候却要等程序结束才显示;用fwrite**写文件,数据明明调用了函数,却没写入磁盘。这些问题的根源,都是缓冲区在 "作祟"。
2.1 什么是缓冲区?
缓冲区是内存中预留的一块存储空间,用于临时缓存输入 / 输出数据。它位于 CPU 和外设(磁盘、键盘、显示器)之间,扮演 "中间代理" 的角色:
- 输出时:程序先将数据写入缓冲区,缓冲区满了或满足特定条件时,再一次性写入外设;
- 输入时:外设先将数据写入缓冲区,程序再从缓冲区读取数据。
缓冲区本质是一块内存,但它的访问速度比磁盘、键盘等外设快几个数量级(内存访问速度通常是磁盘的 1000 倍以上)。通过缓冲区减少与外设的直接交互次数,就能大幅提升 IO 效率。
2.2 为什么需要缓冲区?核心是 "减少系统调用 + 协调速度差异"
引入缓冲区的核心原因有两个:
2.2.1 减少系统调用次数,降低 CPU 开销
系统调用 (如read、write)需要切换 CPU 状态(从用户态到内核态),这个切换过程会消耗大量 CPU 时间。如果没有缓冲区,每次读写一个字节都要调用一次系统调用,效率极低。
比如要写入 1000 个字节到文件:
- 无缓冲区 :需要调用 1000 次
write系统调用,发生 1000 次用户态→内核态切换;- 有缓冲区 :先将 1000 个字节写入缓冲区,再调用 1 次
write系统调用写入磁盘,仅发生 1 次状态切换。
2.2.2 协调高速 CPU 与低速外设的速度差异
CPU 的运算速度是 GHz 级别(每秒数十亿次操作),而磁盘的读写速度是 MB/s 级别(每秒数百万字节),键盘输入速度更是慢到 KB/s 级别。如果没有缓冲区,CPU 会一直等待外设完成操作,造成 "CPU 空转"。
比如用打印机打印文档:
- 无缓冲区:CPU 需要等待打印机打印完每一个字符才能继续工作,效率极低;
- 有缓冲区:CPU 先将整个文档写入打印机缓冲区,然后可以去处理其他任务,打印机再从缓冲区中逐步打印。
2.3 缓冲区的三种类型:全缓冲、行缓冲、无缓冲
标准 IO 库(C 库)提供了三种缓冲类型,不同类型的缓冲区,刷新时机(将缓冲区数据写入外设)不同:
| 缓冲类型 | 适用场景 | 刷新时机 |
|---|---|---|
| 全缓冲 | 磁盘文件 | 1. 缓冲区满;2. 调用fflush;3. 进程结束;4. 关闭文件(fclose) |
| 行缓冲 | 终端(键盘、显示器) | 1. 遇到换行符\n;2. 缓冲区满;3. 调用fflush;4. 进程结束 |
| 无缓冲 | 标准错误流(stderr) | 无缓冲区,数据立即写入外设 |
关键说明:
- 默认情况下,
stdin(标准输入)和**stdout(标准输出)是行缓冲**;stderr(标准错误)是无缓冲 ------ 确保错误信息能立即显示,不会因为缓冲区未刷新而丢失;- 当流重定向到磁盘文件时,行缓冲会自动转为全缓冲。
2.4 实战验证:缓冲区的三种类型与刷新时机
我们通过四个实战案例,彻底搞懂缓冲区的行为。
案例 1:行缓冲(stdout 输出到显示器)
stdout默认是行缓冲,遇到**\n**会立即刷新缓冲区:
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello line buffer 1"); // 无\n,不会立即刷新
sleep(2); // 暂停2秒,屏幕无输出
printf(" -> hello line buffer 2\n"); // 有\n,立即刷新
sleep(2); // 暂停2秒,屏幕显示完整内容
return 0;
}编译运行:
bash
gcc -o line_buffer line_buffer.c
./line_buffer运行现象:
- 前 2 秒:屏幕无任何输出;
- 2 秒后:屏幕立即显示hello line buffer 1 -> hello line buffer 2;
- 再暂停 2 秒,程序结束。

原因 :第一句printf无\n,数据存入行缓冲区;第二句有\n,触发缓冲区刷新,将两部分数据一起输出。
案例 2:全缓冲(stdout 重定向到文件)
当**stdout重定向到文件时,行缓冲转为全缓冲,需缓冲区满或fflush**才会刷新:
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
// 重定向stdout到文件(运行时用 ./full_buffer > log.txt)
printf("hello full buffer 1"); // 存入全缓冲区
printf("hello full buffer 2"); // 存入全缓冲区
sleep(2); // 暂停2秒,文件无内容(缓冲区未满)
fflush(stdout); // 强制刷新缓冲区,数据写入文件
sleep(2); // 暂停2秒,文件已有内容
return 0;
}编译运行:
bash
gcc -o full_buffer full_buffer.c
./full_buffer > log.txt运行现象:
- 前 2 秒:
log.txt为空(缓冲区未刷新);- 执行
fflush后:log.txt出现hello full buffer 1hello full buffer 2;- 程序结束后,缓冲区剩余数据会自动刷新(但此案例中已手动刷新)。

案例 3:无缓冲(stderr)
stderr是无缓冲,数据立即写入外设,无需等待:
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
fprintf(stderr, "hello stderr 1"); // 无缓冲,立即输出
sleep(2); // 暂停2秒,屏幕已显示"hello stderr 1"
fprintf(stderr, " -> hello stderr 2\n"); // 立即输出
sleep(2); // 暂停2秒,屏幕显示完整内容
return 0;
}编译运行:
bash
gcc -o no_buffer no_buffer.c
./no_buffer运行现象:
- 程序启动后立即显示hello stderr 1;
- 2 秒后显示**-> hello stderr 2**;
- 再暂停 2 秒,程序结束。

案例 4:缓冲区与 fork 的 "坑"
当进程调用fork创建子进程时,父进程的缓冲区会被复制到子进程(写时拷贝)。如果缓冲区未刷新,父子进程会各自刷新一次,导致数据重复输出。
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
// 库函数printf(带缓冲区)
printf("hello printf");
// 系统调用write(无缓冲区)
write(1, "hello write\n", strlen("hello write\n"));
pid_t pid = fork();
if (pid == 0) {
// 子进程
printf(" -> child\n");
} else if (pid > 0) {
// 父进程
waitpid(pid, NULL, 0);
printf(" -> parent\n");
}
return 0;
}情况 1:直接运行(stdout 是行缓冲,无 \n 未刷新)
编译运行:
bash
gcc -o fork_buffer fork_buffer.c
./fork_buffer运行结果:
hello write
hello printf -> child
hello printf -> parent原因:
- **
write**是系统调用,无缓冲区,立即输出hello write;- **
printf**无\n,数据存入行缓冲区;- **
fork**后,父子进程各有一份缓冲区副本;- 父子进程分别执行**
printf**,触发缓冲区刷新,导致hello printf输出两次。
情况 2:重定向到文件(stdout 是全缓冲,未刷新)
bash
./fork_buffer > fork_log.txt
cat fork_log.txt运行结果:
hello write
hello printf -> child
hello printf -> parent原因 :全缓冲未刷新,**fork**复制缓冲区,父子进程各自刷新,导致重复输出。
情况 3:添加fflush(stdout)(手动刷新缓冲区)
修改代码,在**fork前添加fflush(stdout)**:
cpp
printf("hello printf");
fflush(stdout); // 手动刷新缓冲区
write(1, "hello write\n", strlen("hello write\n"));运行结果:
hello printfhello write
-> child
-> parent原因 :**fork**前缓冲区已刷新,父子进程无重复数据,hello printf仅输出一次。
这个案例充分说明:库函数(如printf、fwrite)带用户级缓冲区,系统调用(如write、read)无缓冲区。
2.5 FILE 结构体:封装缓冲区与文件描述符
C 库中的**FILE结构体,是缓冲区机制的核心载体。它内部封装了文件描述符(_fileno)和用户级缓冲区**的相关信息,让库函数能通过缓冲区减少系统调用。
FILE 结构体的核心成员(简化版)
FILE结构体定义在/usr/include/libio.h中,核心成员如下:
cpp
struct _IO_FILE {
// 封装的文件描述符(关联内核的file结构体)
int _fileno;
// 读缓冲区相关指针
char *_IO_read_base; // 读缓冲区起始地址
char *_IO_read_ptr; // 读缓冲区当前指针(下一个要读的位置)
char *_IO_read_end; // 读缓冲区结束地址
// 写缓冲区相关指针
char *_IO_write_base; // 写缓冲区起始地址
char *_IO_write_ptr; // 写缓冲区当前指针(下一个要写的位置)
char *_IO_write_end; // 写缓冲区结束地址
// 缓冲区起始地址(统一管理读写缓冲区)
char *_IO_buf_base;
char *_IO_buf_end;
// 其他成员(如刷新标志、锁等)省略...
};
typedef struct _IO_FILE FILE;库函数的 IO 流程(以fwrite为例)
当我们调用**fwrite**写数据时,底层流程是:
- **
fwrite检查FILE**结构体的写缓冲区是否有剩余空间;- 如果有,将数据拷贝到缓冲区 (
_IO_write_ptr指向的位置),并移动**_IO_write_ptr**;- 如果缓冲区满,调用**
write**系统调用(通过_fileno),将缓冲区数据写入内核;- 清空缓冲区,
_IO_write_ptr重置为_IO_write_base。
这个流程的核心是:数据先入用户级缓冲区,再批量写入内核,减少系统调用次数。
三、实战进阶:手动封装一个简易 IO 库(模拟 Glibc)
理解了缓冲区和**FILE结构体的原理后,我们可以手动封装一个简易的 IO 库(my_stdio),模拟 Glibc 的核心功能 ------ 包含mfopen、mfwrite、mfflush、mfclose**四个接口,实现行缓冲和全缓冲机制。
3.1 设计思路
- 定义**
mFILE**结构体,封装文件描述符、缓冲区、刷新模式、缓冲区大小等信息;mfopen:调用open系统调用打开文件,初始化mFILE结构体(设置缓冲区、刷新模式);mfwrite:将数据写入缓冲区,根据刷新模式判断是否需要刷新(行缓冲遇到\n,全缓冲满);mfflush:将缓冲区数据写入内核,清空缓冲区;mfclose:刷新缓冲区,调用close系统调用关闭文件,释放资源。
3.2 完整代码实现
1. 头文件(my_stdio.h)
cpp
#pragma once
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 缓冲区大小(1KB)
#define BUF_SIZE 1024
// 刷新模式
#define FLUSH_NONE 0 // 未设置
#define FLUSH_LINE 1 // 行缓冲(终端)
#define FLUSH_FULL 2 // 全缓冲(文件)
// 自定义FILE结构体
typedef struct {
int fileno; // 封装的文件描述符
char buffer[BUF_SIZE]; // 用户级缓冲区
int buf_size; // 缓冲区中已存储的数据大小
int flush_mode; // 刷新模式(行缓冲/全缓冲)
} mFILE;
// 打开文件(模拟fopen)
mFILE *mfopen(const char *filename, const char *mode);
// 写入数据(模拟fwrite)
size_t mfwrite(const void *ptr, size_t size, size_t nmemb, mFILE *stream);
// 刷新缓冲区(模拟fflush)
void mfflush(mFILE *stream);
// 关闭文件(模拟fclose)
int mfclose(mFILE *stream);2. 实现文件(my_stdio.c)
cpp
#include "my_stdio.h"
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
// 打开文件
mFILE *mfopen(const char *filename, const char *mode) {
int fd = -1;
int flags = 0;
mode_t file_mode = 0666; // 默认文件权限(rw-rw-rw-)
int flush_mode = FLUSH_FULL; // 默认全缓冲
// 解析打开模式
if (strcmp(mode, "r") == 0) {
// 只读模式
flags = O_RDONLY;
} else if (strcmp(mode, "w") == 0) {
// 只写模式,文件不存在则创建,存在则清空
flags = O_WRONLY | O_CREAT | O_TRUNC;
} else if (strcmp(mode, "a") == 0) {
// 追加模式,文件不存在则创建
flags = O_WRONLY | O_CREAT | O_APPEND;
} else if (strcmp(mode, "r+") == 0) {
// 读写模式,文件必须存在
flags = O_RDWR;
} else if (strcmp(mode, "w+") == 0) {
// 读写模式,文件不存在则创建,存在则清空
flags = O_RDWR | O_CREAT | O_TRUNC;
} else if (strcmp(mode, "a+") == 0) {
// 读写模式,文件不存在则创建,写操作追加
flags = O_RDWR | O_CREAT | O_APPEND;
} else {
fprintf(stderr, "mfopen: invalid mode %s\n", mode);
return NULL;
}
// 打开文件(根据模式判断是否需要第三个参数)
if (flags & (O_CREAT | O_TRUNC | O_APPEND)) {
fd = open(filename, flags, file_mode);
} else {
fd = open(filename, flags);
}
if (fd < 0) {
perror("mfopen: open failed");
return NULL;
}
// 判断是否为终端(终端使用行缓冲,文件使用全缓冲)
if (isatty(fd)) {
flush_mode = FLUSH_LINE;
}
// 分配并初始化mFILE结构体
mFILE *mf = (mFILE *)malloc(sizeof(mFILE));
if (mf == NULL) {
perror("mfopen: malloc failed");
close(fd);
return NULL;
}
mf->fileno = fd;
mf->buf_size = 0; // 缓冲区初始为空
mf->flush_mode = flush_mode;
memset(mf->buffer, 0, BUF_SIZE); // 清空缓冲区
return mf;
}
// 写入数据
size_t mfwrite(const void *ptr, size_t size, size_t nmemb, mFILE *stream) {
if (ptr == NULL || stream == NULL || size == 0 || nmemb == 0) {
return 0;
}
size_t total_bytes = size * nmemb; // 要写入的总字节数
size_t remaining_bytes = total_bytes; // 剩余未写入的字节数
const char *data = (const char *)ptr; // 数据指针
while (remaining_bytes > 0) {
// 计算缓冲区剩余空间
size_t free_space = BUF_SIZE - stream->buf_size;
// 本次要写入缓冲区的字节数(取剩余数据和缓冲区空间的最小值)
size_t write_bytes = (remaining_bytes < free_space) ? remaining_bytes : free_space;
// 将数据拷贝到缓冲区
memcpy(stream->buffer + stream->buf_size, data + (total_bytes - remaining_bytes), write_bytes);
stream->buf_size += write_bytes;
remaining_bytes -= write_bytes;
// 检查是否需要刷新缓冲区
if (stream->flush_mode == FLUSH_LINE) {
// 行缓冲:检查是否有换行符
if (memchr(stream->buffer, '\n', stream->buf_size) != NULL) {
mfflush(stream);
}
} else if (stream->flush_mode == FLUSH_FULL) {
// 全缓冲:检查缓冲区是否满
if (stream->buf_size == BUF_SIZE) {
mfflush(stream);
}
}
}
return nmemb; // 返回成功写入的数据单元个数
}
// 刷新缓冲区
void mfflush(mFILE *stream) {
if (stream == NULL || stream->buf_size == 0) {
return;
}
// 调用write系统调用,将缓冲区数据写入内核
ssize_t write_len = write(stream->fileno, stream->buffer, stream->buf_size);
if (write_len < 0) {
perror("mfflush: write failed");
} else if ((size_t)write_len != stream->buf_size) {
fprintf(stderr, "mfflush: partial write (wrote %zd of %d bytes)\n", write_len, stream->buf_size);
}
// 清空缓冲区
stream->buf_size = 0;
memset(stream->buffer, 0, BUF_SIZE);
}
// 关闭文件
int mfclose(mFILE *stream) {
if (stream == NULL) {
return -1;
}
// 关闭文件前,刷新缓冲区
mfflush(stream);
// 调用close系统调用关闭文件描述符
int ret = close(stream->fileno);
if (ret < 0) {
perror("mfclose: close failed");
}
// 释放mFILE结构体内存
free(stream);
stream = NULL;
return ret;
}3. 测试文件(main.c)
cpp
#include "my_stdio.h"
#include <stdio.h>
#include <unistd.h>
int main() {
// 测试1:写入终端(行缓冲)
printf("=== 测试行缓冲(终端输出) ===\n");
mFILE *mf_terminal = mfopen("/dev/stdout", "w"); // /dev/stdout是终端
if (mf_terminal == NULL) {
return 1;
}
mfwrite("测试行缓冲1:无换行符", 1, strlen("测试行缓冲1:无换行符"), mf_terminal);
sleep(2); // 暂停2秒,无输出(缓冲区未刷新)
mfwrite(" -> 测试行缓冲2:有换行符\n", 1, strlen(" -> 测试行缓冲2:有换行符\n"), mf_terminal);
sleep(2); // 暂停2秒,已输出(遇到\n刷新)
mfclose(mf_terminal);
// 测试2:写入文件(全缓冲)
printf("\n=== 测试全缓冲(文件输出) ===\n");
mFILE *mf_file = mfopen("test_my_stdio.txt", "w");
if (mf_file == NULL) {
return 1;
}
// 写入小于缓冲区大小的数据(1KB)
const char *msg = "测试全缓冲:写入文件的数据";
mfwrite(msg, 1, strlen(msg), mf_file);
printf("写入数据后,文件暂时无内容(缓冲区未满)\n");
sleep(2); // 暂停2秒,查看文件(为空)
// 手动刷新缓冲区
mfflush(mf_file);
printf("调用mfflush后,文件已有内容\n");
sleep(2); // 暂停2秒,查看文件(有内容)
mfclose(mf_file);
// 测试3:写入大量数据(触发全缓冲刷新)
printf("\n=== 测试全缓冲满刷新 ===\n");
mFILE *mf_big = mfopen("test_big.txt", "w");
if (mf_big == NULL) {
return 1;
}
char big_msg[BUF_SIZE + 100]; // 超过缓冲区大小(1KB+100字节)
memset(big_msg, 'a', sizeof(big_msg));
big_msg[sizeof(big_msg) - 1] = '\0';
mfwrite(big_msg, 1, strlen(big_msg), mf_big); // 缓冲区满,自动刷新
printf("写入大量数据,缓冲区满自动刷新\n");
mfclose(mf_big);
return 0;
}3.3 编译与测试
编译命令
bash
gcc -o test_my_stdio main.c my_stdio.c运行与验证
bash
./test_my_stdio测试现象解析
-
行缓冲测试:
- 前 2 秒:终端无输出(数据存入行缓冲区,无
\n); - 2 秒后:终端输出
测试行缓冲1:无换行符 -> 测试行缓冲2:有换行符(遇到\n刷新)。
- 前 2 秒:终端无输出(数据存入行缓冲区,无
-
全缓冲测试:
- 写入数据后,
test_my_stdio.txt为空(缓冲区未满); - 调用
mfflush后,test_my_stdio.txt出现写入的数据(手动刷新)。
- 写入数据后,
-
全缓冲满刷新:
- 写入 1124 字节(1KB+100 字节),缓冲区满,自动刷新;
test_big.txt中出现大量a字符(缓冲区数据已写入文件)。
这个手动封装的 IO 库,成功模拟了 Glibc 的核心缓冲机制,让我们更深刻地理解了缓冲区的工作原理。
总结
掌握了本文涉及的这些知识点后,你不仅能熟练使用文件 IO 接口,还能解决实际开发中遇到的缓冲区、重定向等疑难问题。后续我们还会深入学习 IO 多路复用(
select/poll/epoll)、网络 IO 等高级主题,敬请期待!如果本文对你有帮助,欢迎点赞、收藏、转发,也欢迎在评论区交流讨论~