目录
set和get
set和get是Redis最基础的指令,
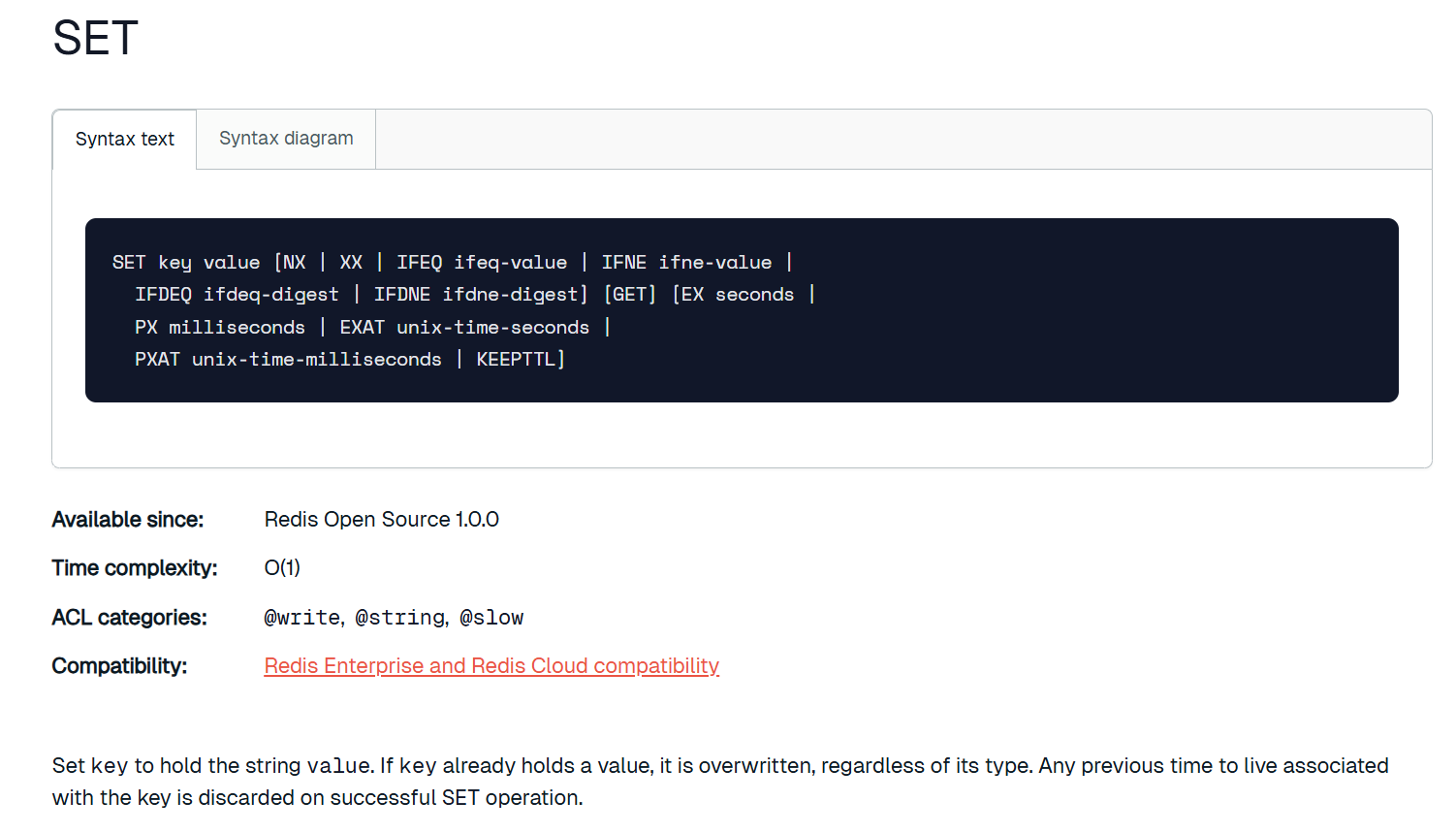
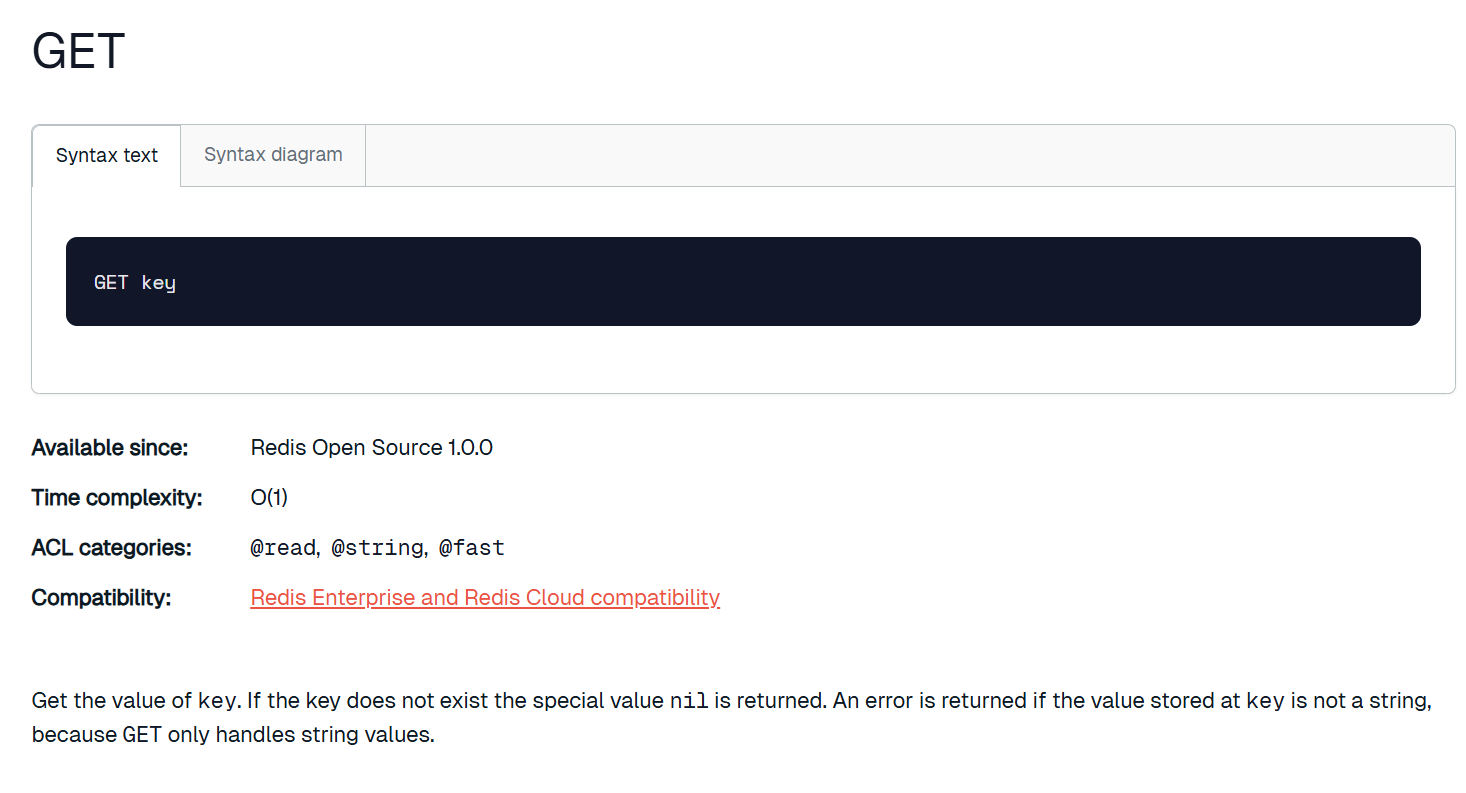
set用来设置键值对,get用来获取指定键对应的值。Redis的键值对以哈希表的形式存储,其中键是字符串类型,值可以是多种数据结构类型,当然我们这里使用set的话那key和value都是字符串类型,如果要设置特殊的数据结构类型就要用到专门的命令。两个指令的时间复杂度都是O(1),哈希表的增改查都是O (1)。
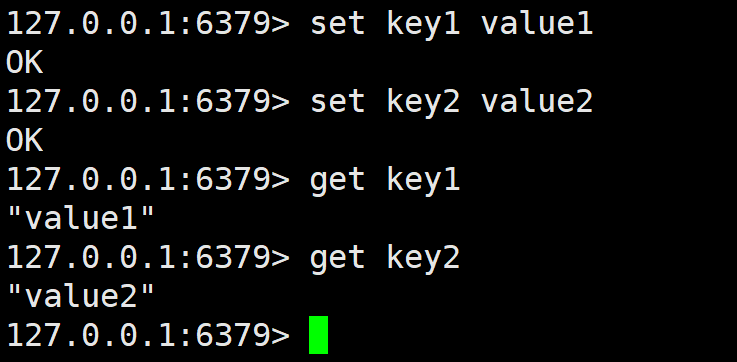
set的如果是一个没存在过的键,那么就会创建一个新的,如果是存在的,那么就会修改那个键对应的值。
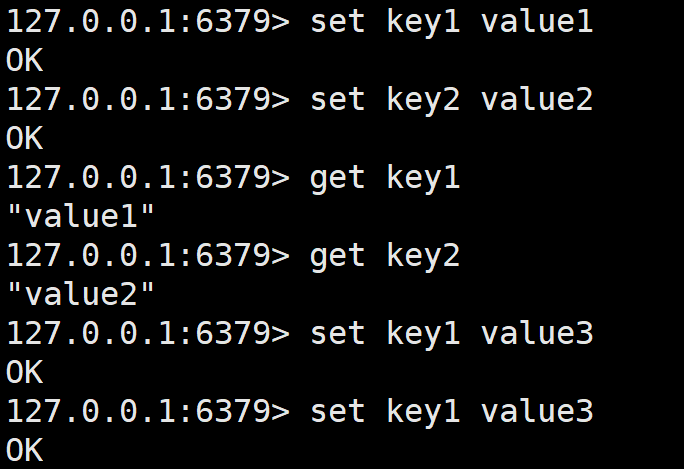
get的键如果存在会返回对应的值,这个值是打双引号的,在Redis中,字符串可以不加引号,也能加引号(单引号双引号都行)。如果get的键不存在,那么就会返回nil,意思和null一样,就是空的意思。

Redis的指令和MySQL一样,可以大写也可以小写,默认tab补全的话就是大写,但我们一般小写,看得舒服一点。
keys
keys命令可以返回所有满足样式(pattern)的 key,也就是搜索符合要求的keys。
支持如下统配样式:
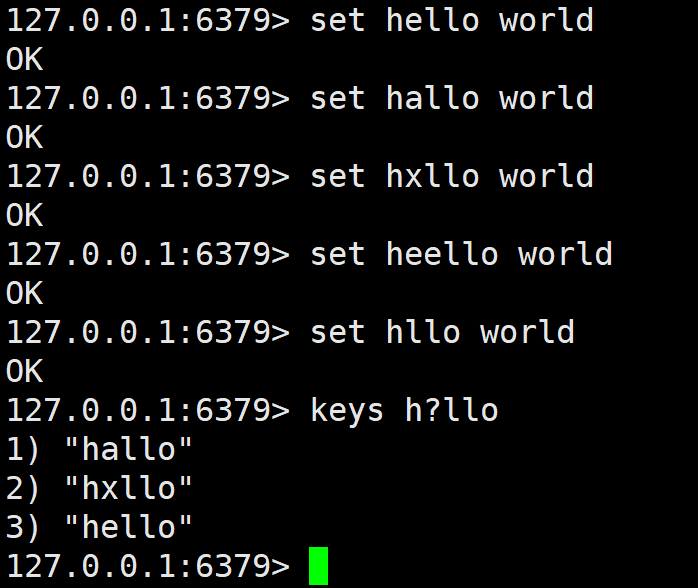
h?llo matches hello, hallo and hxllo
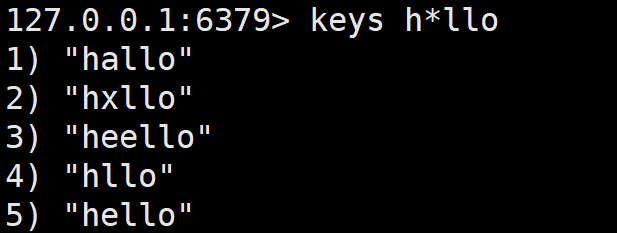
h*llo matches hllo and heeeello
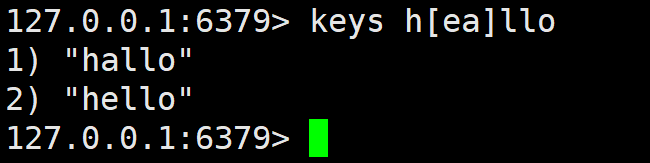
h[ae]llo matches hello and hallo, but not hillo
h[^e]llo matches hallo, hbllo, ... but not hello
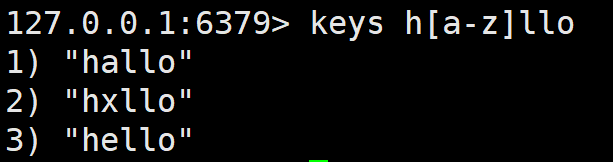
h[a-b]llo matches hallo and hbllo
? :?支持通配任意单个字符(仅 1 个,不能多也不能少),但是多字符或空则不行。
* :支持通配0个或任意多个任意字符(无长度限制)。
\[\] :匹配括号内的任意单个字符(字符集匹配)。
\^ :匹配括号内以外的任意单个 字符(反向字符集)。

a-b :匹配指定范围内的任意单个 字符(连续字符集,支持字母 / 数字)。
请注意该指令的时间复杂度是O(N),在线上环境需要谨慎使用,因为Redis是单线程模型,如果使用该指令(尤其是keys *,会查询所有的key),可能会扫描过长时间,导致其他操作全被阻塞,严重影响性能,甚至导致软件崩溃。比如Redis经常用于缓存,挡在MySQL前面处理大量的请求,如果此时来个keys *,线上环境Redis中的key非常多,这时就会阻塞住,此时其他Redis的查询操作超时了,就会直接查数据库,那么MySQL面对大量的请求,可能就会崩溃,这时,整个系统就基本瘫痪了。
exists
判断某个key是否存在。
O(1)时间复杂度,因为哈希的查时间复杂度就是O(1)。
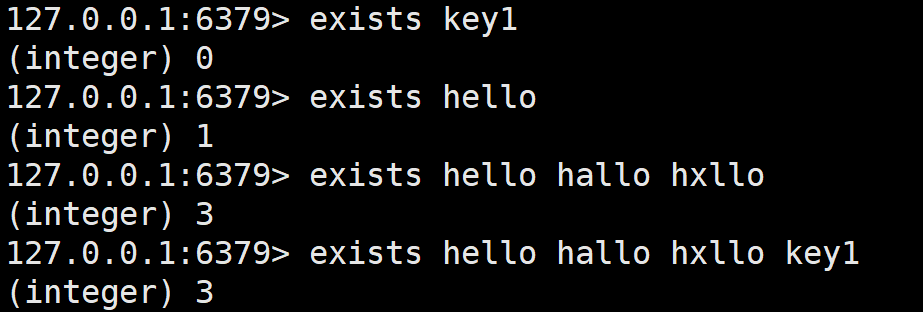
判断的key可以给一个或多个,结果会返回存在的个数。因为Redis是服务端客户端的形式,之间通过网络进行传输数据,一个Redis服务端对所有客户端都可见。那么我们说Redis快,也是有一个参照,我们通常拿其和MySQL进行比较,MySQL跟硬盘打交道,当然慢,但是如果拿Redis和直接在内存中存的变量比,Redis就很慢,因为Redis虽然也存在内存,但是还要通过网络进行数据传输,网络传输的封装和分用会耗费大量时间,所以这种参照下Redis也不快了。我说这些的目的是什么呢?这里的exists可以一次查一个,也能一次查多个,那么我们在实际使用时,如果场景合适,应该尽量精简到一条指令来完成,因为一条指令对应一次网络传输,其实这个才是时间开销大户,这样能提高不少效率。
我们在实际使用Redis时,也应当是权衡好利弊才来使用,比如单机架构中,是否要使用Redis,有人会觉得单机架构中Redis没有内存直接使用变量快,所以肯定不用,但是Redis有自己的持久化方案,单机架构用Redis,服务器重启数据也还在,而且未来扩展成分布式也更轻松,所以这也是需要权衡考虑的。
del
删除指定的key。
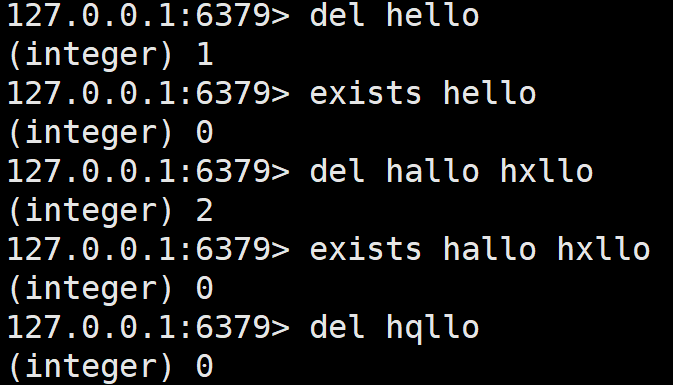
可以删除多个键,返回删除键的个数。
无论什么场景,删除操作都是需要谨慎的,虽然Redis很多时候是作为缓存来使用,但是删除过量数据也会有很大的影响,作为数据库时就更不行了。
expire
为指定的key添加秒级的过期时间(Time To Live TTL)。
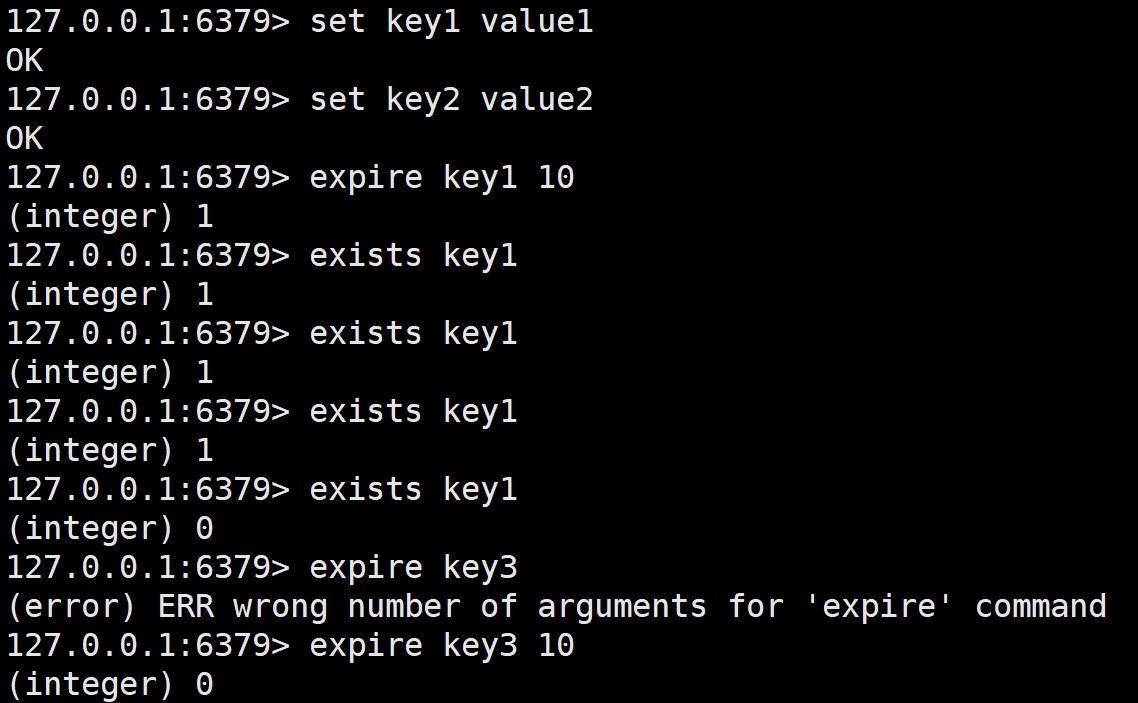
expire设置的时间单位是秒,如果时间粒度想要更细,也能使用pexpire,设置的单位是毫秒。expire设置过期时间成功返回1,失败返回0。
ttl
获取指定 key 的过期时间,秒级。
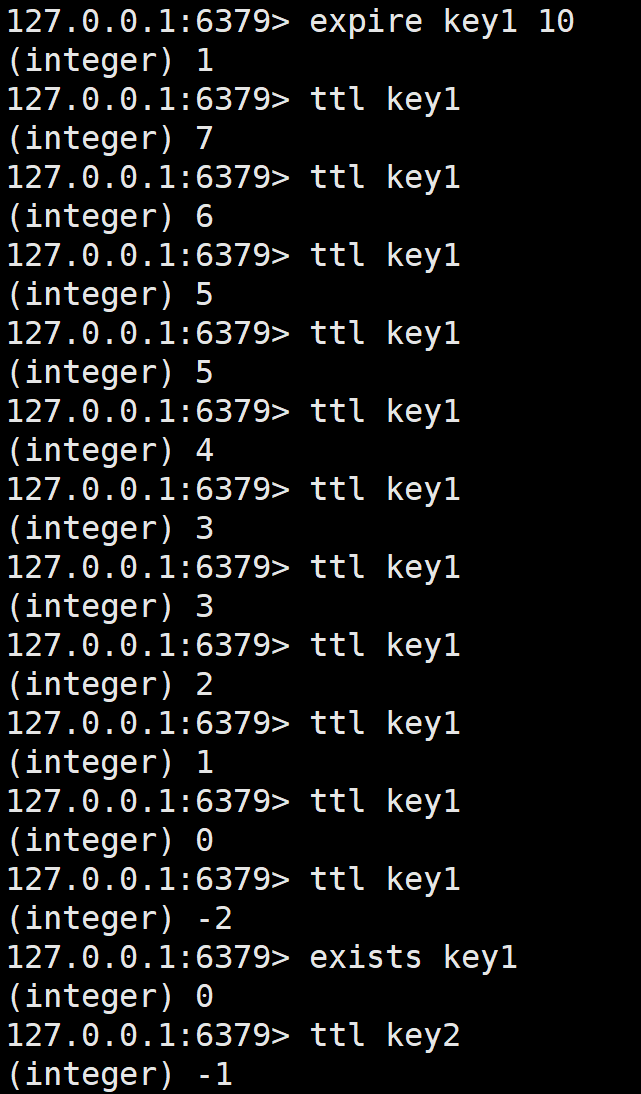
如果想要毫秒级的,可以使用pttl,和pexpire配套。改命令对于没有关联过期时间的返回-1,不存在的键返回-2,正常返回过期时间。
Redis的key的过期策略是怎么实现的
Redis中可能同时存了非常多的key,这些key中可能有一大部分都有过期时间,Redis怎么处理过期key呢?直接遍历吗,不可能,效率太低。Redis整体的策略是:定期删除 + 惰性删除。
定期删除就是每次抽取一部分,验证过期时间,过期了就删除,注意这只是抽取,不是全部,为什么不全部呢?因为要保证这个抽取删除的过程足够快,Redis是单线程程序,主要任务是处理到来的一个个指令,而不是光在那删除过期key。
惰性删除就是一个key已经到过期时间了,但是暂时还没有删除,如果接下来的访问刚好访问到了这个key,那么就触发删除ke的操作,同时返回一个nil。
当然以上的两种机制结合并不能很好的处理过期key,Redis为了处理这个问题,还提供了一系列的内存淘汰策略。
Redis并没有采用定时器的方式实现过期key删除,如果多个key过期,也可通过一个定时器来高效处理过期key。也许不是因为优先级队列和时间轮的方式都要引入多线程,而Redis一开始就决定用单线程搞,所以没有这么做吧。
(1)基于优先级队列的定时器
核心思路:把所有带过期时间的任务(比如 Redis 里的 key)按照过期时间的早晚作为优先级,放入一个优先级队列中。过期时间越早,优先级越高,会被优先处理。
工作流程:
队列的队首永远是最早要过期的任务,只需要一个扫描线程盯着队首元素即可。
线程会计算当前时间和队首任务过期时间的差值,然后进入等待状态,直到时间快到再被唤醒(不需要频繁检查)。
如果有新任务加入,会唤醒线程,重新检查队首并调整等待时间,避免高频轮询,节省 CPU 开销。
特点:无需遍历所有任务,仅关注队首,性能高效;适合任务过期时间跨度较大的场景。
(2) 基于时间轮的定时器
核心思路:把时间划分为固定粒度的小段(如示例中的 100ms),形成一个环形的 "时间轮",每个时间格子上挂一个任务链表。
工作流程:
一个指针会以固定间隔(如 100ms)在时间轮上移动,每次走到一个格子,就执行该格子链表中的所有任务。
当添加任务时,根据任务的延迟时间计算出它应该落在哪个格子的链表中,等待指针扫到该格子时执行。
对于延迟时间远大于单个格子粒度的任务(如延迟 3000ms),会被放到对应延迟步数的格子中,等待指针多轮扫描后触发。
特点:通过时间分片分散任务压力,适合任务量较大、延迟时间相对均匀的场景;格子粒度和数量可根据实际需求灵活调整。
type
返回key对应的数据类型。