大家好我是小明,今天消学习集合,这是我已经学习过的总结。
文章目录
- [1. List相关面试题](#1. List相关面试题)
-
- [1.1 数组](#1.1 数组)
- 1.2ArrayList底层原理是什么??
- [1.3 LinkedList相关面试题](#1.3 LinkedList相关面试题)
- [2. HashMap面试题](#2. HashMap面试题)
-
- 2.1哈希表底层原理
- [2.2 HashMap的put方法具体流程](#2.2 HashMap的put方法具体流程)
- [2.3 hashMap的寻址算法是什么??](#2.3 hashMap的寻址算法是什么??)
总体学习大纲
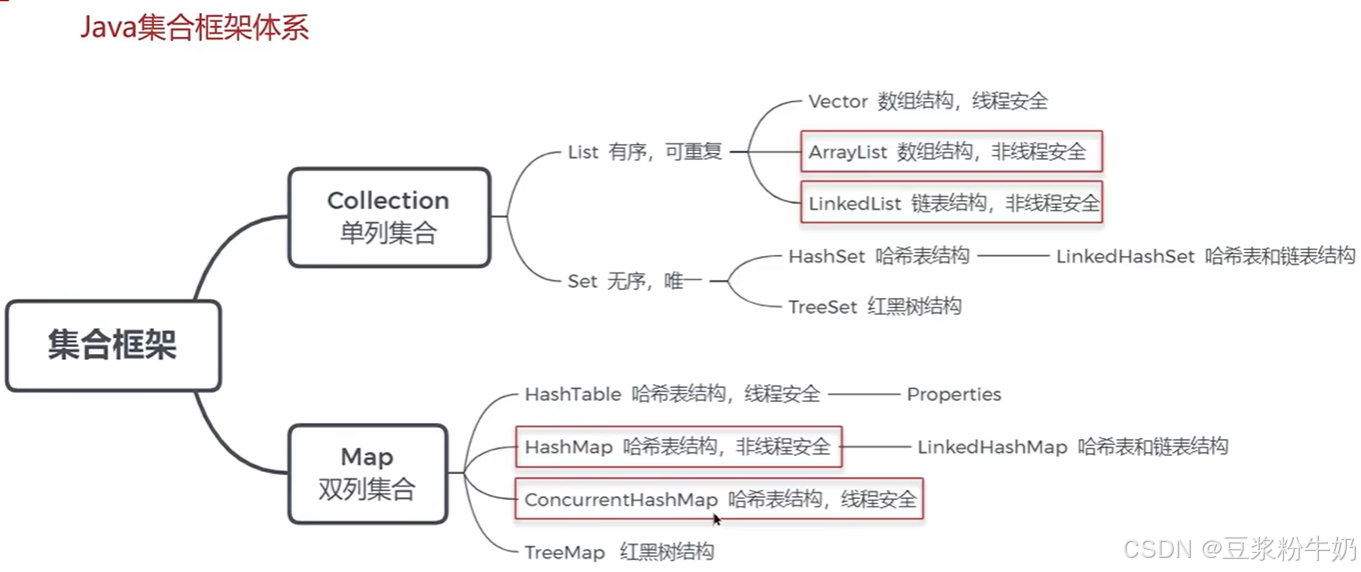
1. List相关面试题
1.1 数组
数组是用一种连续的内存空间 来存储 相同数据类型 的线性结构
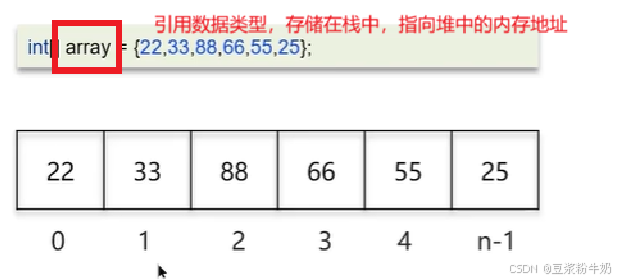

为啥数据索引从0开始呢,假如从1开始不行吗?
- 在根据数组索引获取元素的时候,会用索引和寻址公式来计算内存所对应的元素数据,寻址公式是:数组的首地址 + 索引乘以存储数据的类型大小
- 如果数组的索引从 1 开始,寻址公式中,就需要增加一次减法操作,对于 CPU 来说就多了一次指令,性能不高。
总结:
- 数组是用一种连续的内存空间 来存储 相同数据类型 的线性结构
- 数组下标从0开始
- 通过下标查询时间复杂度O(1),查找(未知元素,未知下标)时间复杂度O(n),查找(未知元素,未知下标,元素排序)时间复杂度O(logn)
- 插入和删除数据需要数据挪动,时间复杂度O(n)
自定义排序:
实现Comparator(比较器)接口的compare方法
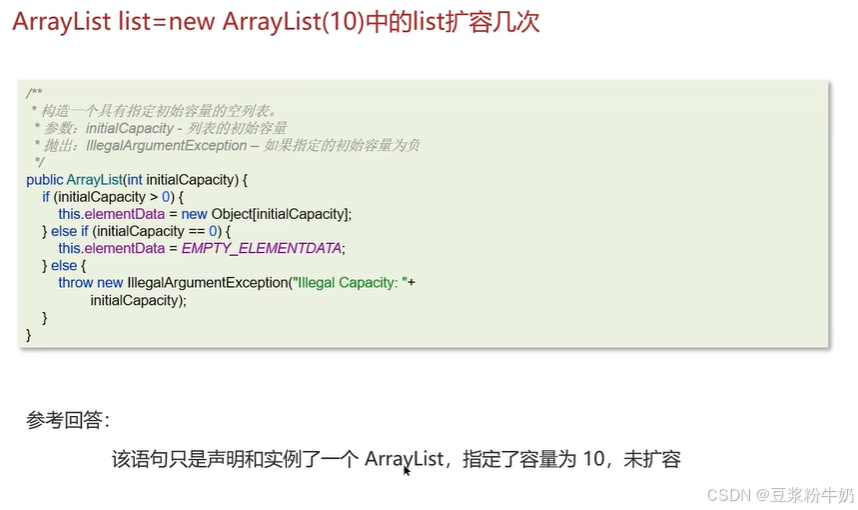
1.2ArrayList底层原理是什么??
下面是是基本代码

- ArrayList 底层是用动态的数组(实现自动扩容动态的数组)实现的
- ArrayList 初始容量为 0,当第一次添加数据的时候才会初始化容量为 10
- ArrayList 在进行扩容的时候是原来容量的 1.5 倍(copyOf方法),每次扩容都需要拷贝数组
还有这个

1.3 LinkedList相关面试题
总体复习大纲
查询的平均复杂度O(n),删除的也是O(n)
ArrayLsit和LinkedList的区别是什么??
- 底层数据结构
ArrayList底层是动态数组,LinkedList底层是双向链表
2. 操作数据效率
ArrayList查找时间复杂度是O(1),删除和插入的时间复杂度O(n)
3. 占用内存空间
ArrayList底层是数组,内存连续,比较节省内存
LinkedList双向链表需要存储数据,和两个指针,占用内存更大
4. 线程安全
两个都不是线程安全的
可以使用这两个
List syncArrayList = Collections.synchronizedList(new ArrayList<>());
List syncLinkedList = Collections.synchronizedList(new LinkedList<>());
2. HashMap面试题
2.1哈希表底层原理
散列表(Hash Table),也叫哈希表,是一种通过键(Key)直接访问值(Value)的数据结构,核心是利用哈希函数(Hash Function)将键映射到数组的某个索引位置,从而实现O (1) 时间复杂度的高效增删改查。
哈希碰撞就是不同的键(Key),通过同一个哈希函数计算后,得到了相同的哈希值(数组索引)。
哈希碰撞解决办法??
链表法

把哈希冲突的数据通链表的方式连接起来,但是如果同一个哈希桶的哈希冲突过多,就会出现很长的链表,链表查找的时间为O(n),所以当链表过长时,HashMap 会把链表转成红黑树,进一步优化查询效率。
2.2 HashMap的put方法具体流程
jdk1.8之后
- 参数校验与数组初始化: 首先检查底层数组 table 是否为空或长度为 0,如果是,先执行 resize() 方法初始化数组。
- 计算哈希值,定位数组索引
- 判断当前索引位置是否为空: 如果 tablei == null,直接新建一个普通节点(Node)放入该位置。
- 处理索引位置非空的情况(哈希碰撞):新增链表节点后,判断链表长度是否 ≥ 8,且数组长度 ≥ 64:满足则将链表转为红黑树。
- 触发扩容: 最后判断当前元素数量 size 是否超过阈值(capacity × loadFactor,默认 16×0.75=12):超过则执行 resize() 扩容(数组长度翻倍)。
扩容时所有的元素都重新运算hash值重新放到新的hash表中。jdk1.7是判断是否要扩容在执行put操作,jdk1.8之后是put操作在判断是否要扩容。
2.3 hashMap的寻址算法是什么??
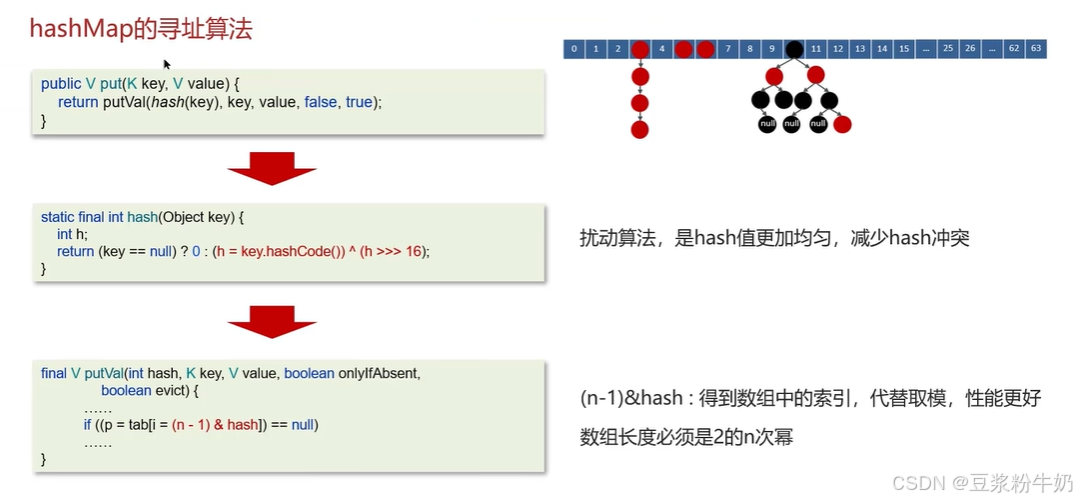
核心结论是 :HashMap 基于「哈希函数 + 位运算」实现寻址,核心公式是 索引 = (数组长度 - 1) & 哈希值,而非传统的取模运算。
好了今天就到这里