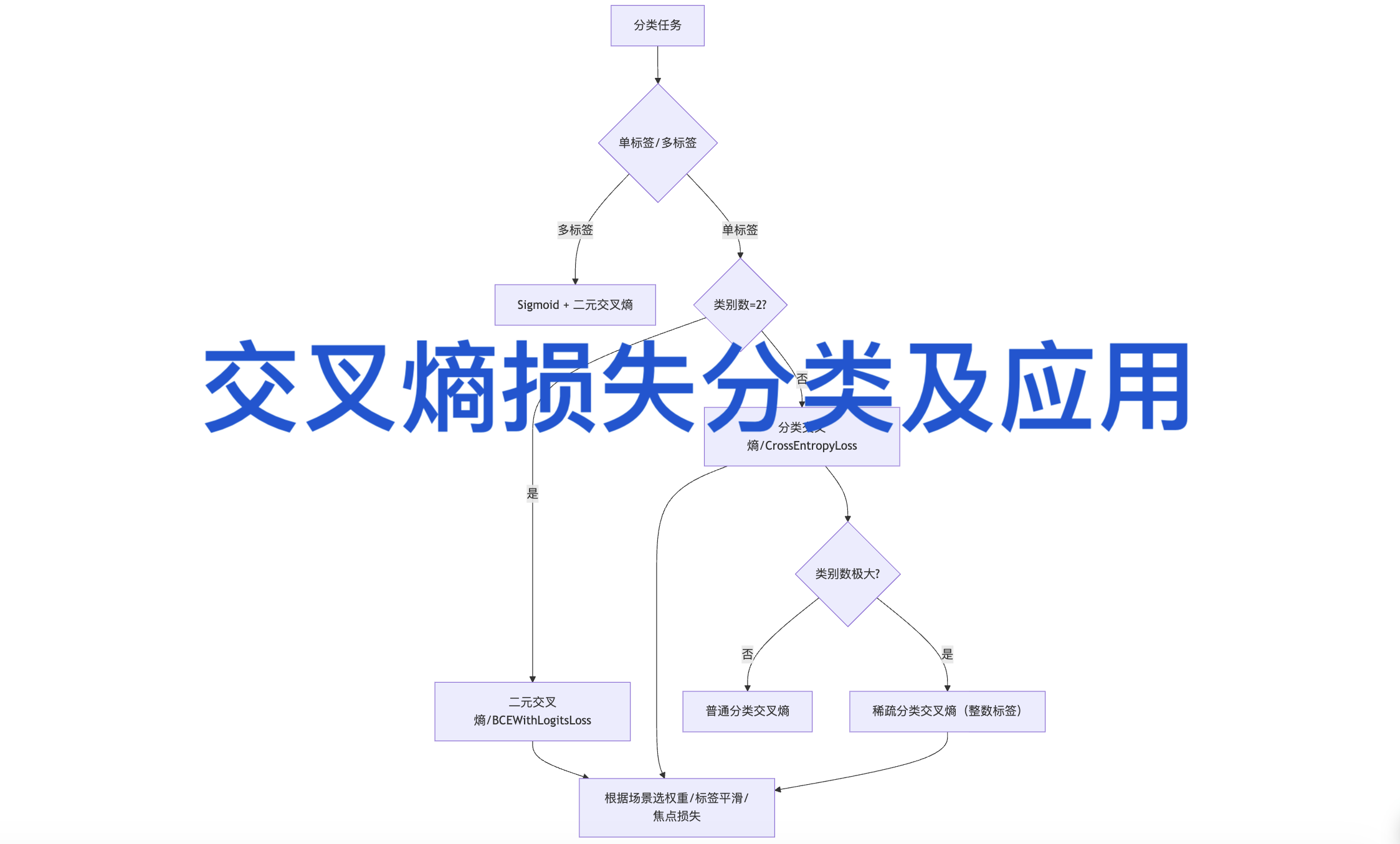
交叉熵损失(Cross-Entropy Loss)是深度学习分类任务中衡量预测分布与真实分布差异的核心损失函数,其分类可依据任务类型和改进变体两大维度划分,不同类别在公式形式、适用场景和实现方式上存在显著差异。
一、按分类任务类型划分
该维度基于样本所属类别数量及标签形式分类,是交叉熵损失最基础的划分方式,直接对应不同的建模需求。
- 二元交叉熵损失(Binary Cross-Entropy Loss, BCE)
适用场景:二分类任务,即样本仅属于两个互斥类别,常见场景包括垃圾邮件检测、疾病阳性/阴性诊断、图像二值分割(如前景与背景分离)、文本垃圾评论识别、金融欺诈交易检测等,每个样本预测结果为属于正类的概率。
数学公式:
L = -1/N ∑(i=1到N) y_i · log(p_i) + (1-y_i) · log(1-p_i)
其中,N 为样本总数,yᵢ ∈ {0,1} 为第 i 个样本的真实标签,pᵢ ∈ (0,1) 为模型预测样本属于正类的概率(需经Sigmoid激活函数输出)。
实现特点:PyTorch中常用 nn.BCEWithLogitsLoss()(内置Sigmoid激活,数值更稳定),无需手动添加激活层;标签为0/1 scalar形式,无需One-Hot编码。 - 分类交叉熵损失(Categorical Cross-Entropy Loss, CCE)
适用场景:多分类任务,样本仅属于多个互斥类别中的一个,典型场景有图像分类(如图像Net数据集的千类分类)、文本情感多类判别(积极/中性/消极)、手写数字识别(MNIST数据集0-9分类)、自然语言处理中的文本主题分类(科技/娱乐/体育等),需输出每个类别的概率分布。
数学公式:
L = -1/N ∑(i=1到N)∑(c=1到C)y_ic · log(p_ic)
其中,C 为类别总数,yᵢc 为One-Hot编码标签(样本 i 属于类别 c 时为1,否则为0),pᵢc 为样本 i 属于类别 c 的预测概率(经Softmax激活归一化)。
实现特点:PyTorch中 nn.CrossEntropyLoss() 内置LogSoftmax与NLLLoss,输入为未归一化的logits(无需手动加Softmax);目标标签支持整数索引形式(无需One-Hot编码),更高效。 - 稀疏分类交叉熵损失(Sparse Categorical Cross-Entropy Loss)
适用场景:多分类任务的优化形式,适用于类别数多、One-Hot编码占用内存大的场景,例如大规模文本分类(如百万级词条分类)、推荐系统中的物品类别预测(商品类别数过万)、语音识别中的音素分类(音素类别数量多),本质与CCE等价,可大幅降低内存开销。
核心差异:标签直接使用整数类别索引(如类别0/1/2),而非One-Hot向量,可大幅减少内存占用。PyTorch中 nn.CrossEntropyLoss() 可直接支持该标签形式,无需额外转换。
二、按改进变体形式划分
针对基础交叉熵损失在特殊场景(如类别不平衡、难例样本)的局限性,衍生出多种改进变体,优化模型训练效果。
- 加权交叉熵损失(Weighted Cross-Entropy Loss)
适用场景:解决类别不平衡问题,常见于医疗数据(如癌症诊断中阳性样本占比不足5%)、安防监控中的异常事件检测(异常场景极少)、工业质检中的缺陷分类(合格产品占比极高)、不平衡文本分类(稀有主题文本),通过赋予少数类更高权重,避免模型偏向多数类。
实现方式:在基础交叉熵损失中引入类别权重向量 w = w₁, w₂, ..., w_C,PyTorch中可通过 nn.CrossEntropyLoss(weight=weight_tensor) 直接设置,权重需根据类别频率计算(少数类权重更高)。 - 焦点损失(Focal Loss)
适用场景:同时解决类别不平衡和难例样本挖掘问题,核心应用于目标检测领域(如RetinaNet模型解决小目标检测难题)、人脸检测与识别(遮挡/模糊人脸等难例样本)、红外图像目标检测(目标与背景对比度低,难例多)、医学影像分割(微小病灶检测,样本不平衡且难识别)。
核心改进:在二元交叉熵基础上添加调制因子 (1-pᵢ)^γ(γ 为聚焦参数,通常取2),易分样本(pᵢ 接近0或1)损失被大幅衰减,难分样本损失占比提升。 - 标签平滑交叉熵损失(Label-Smoothing Cross-Entropy Loss)
适用场景:缓解模型过拟合和"过度自信"问题,适用于对泛化能力要求高的场景,如图像分类竞赛(提升模型在测试集上的稳定性)、自然语言生成中的分类任务(如文本摘要质量评级)、自动驾驶场景中的目标分类(避免模型对模糊目标误判)、少样本学习中的分类任务(增强模型适应性)。
实现方式:将真实标签从One-Hot硬标签转换为软标签(如正类概率为 1-ε,其余类别均分 ε),PyTorch 1.10+ 中可通过 nn.CrossEntropyLoss(label_smoothing=0.1) 直接设置平滑系数 ε。
三、关键使用注意事项
•激活函数搭配:CCE无需手动加Softmax(损失函数内置),BCE需配合Sigmoid(优先用BCEWithLogitsLoss避免数值不稳定)。
•多标签分类:普通交叉熵不适用,需用Sigmoid+二元交叉熵(每个类别独立判断,允许样本属于多个类别)。
•数值稳定性:避免在输出层添加Softmax后再用CCE,会导致双重归一化,引发梯度消失。
•高维数据适配:图像等高维数据需确保输入维度符合要求(PyTorch中类别维度需在dim=1位置)。