本文档为伪分布式大数据环境(1台虚拟机:hadoop)中Hadoop组件的功能测试教程,涵盖Hadoop服务启停、HDFS文件操作、MapReduce任务运行等核心测试场景。严格遵循视频操作流程,详细说明每个步骤的操作要点、执行命令及预期结果,助力高效完成Hadoop组件可用性及核心功能验证。
一、前期准备:环境基础信息
测试前需确认环境配置符合要求,避免因基础环境问题导致测试流程中断:
- 虚拟机配置:1台虚拟机(命名为hadoop),已完成伪分布式Hadoop部署
- 系统账号:优先使用hertz账号(密码:hertz);特殊操作需使用root账号(密码:1)
- 工具准备:Mobaxterm远程连接工具(已安装并可正常使用)、本地浏览器(如Chrome、Edge)
二、Hadoop测试详细步骤
步骤1:确认虚拟机启动状态
操作说明:启动虚拟机,等待系统加载完成,直至出现登录页面。
预期结果:虚拟机正常启动,显示系统登录界面,无启动报错。
步骤2:使用Mobaxterm连接虚拟机
操作说明:打开本地Mobaxterm工具,按照伪分布式部署教程中的详细步骤建立与虚拟机的远程连接。
核心操作要点:
- 新建远程连接,选择SSH连接方式
- 输入虚拟机IP地址(需提前确认正确)
- 选择登录账号类型(默认为普通用户)
预期结果:Mobaxterm连接成功,进入连接等待登录状态。
步骤3:输入账号密码完成登录
操作说明:在Mobaxterm连接成功后的登录界面,依次完成账号和密码输入。
具体操作:
- 当终端显示账号输入提示时,输入:hertz
- 回车后,终端显示密码输入提示,输入:hertz(密码输入时默认不显示明文)
- 再次回车确认
预期结果:登录成功,终端界面显示当前登录用户及主机信息(如hertz@hadoop \~$)。
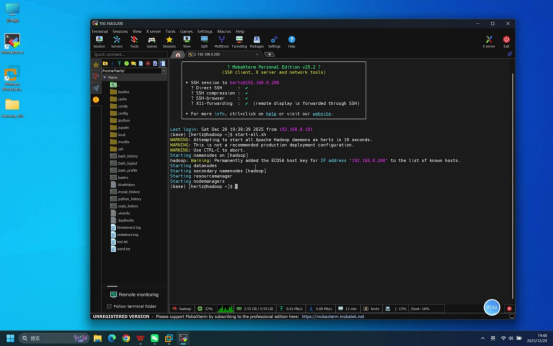
步骤4:启动Hadoop相关服务
操作说明:在登录成功的Mobaxterm终端中,执行Hadoop服务启动命令,启动HDFS和YARN相关服务。
具体命令:
- 一键启动所有服务:start-all.sh
预期结果:终端无报错提示,依次显示各服务(NameNode、DataNode、ResourceManager、NodeManager等)的启动日志信息。
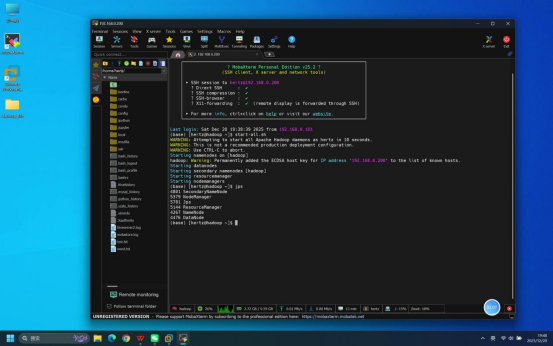
步骤5:执行jps命令验证进程状态
操作说明:服务启动完成后,在终端中输入jps命令,查看当前运行的Java进程。
具体命令:jps
预期结果:终端输出进程列表,包含以下核心进程,说明Hadoop服务启动正常:
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
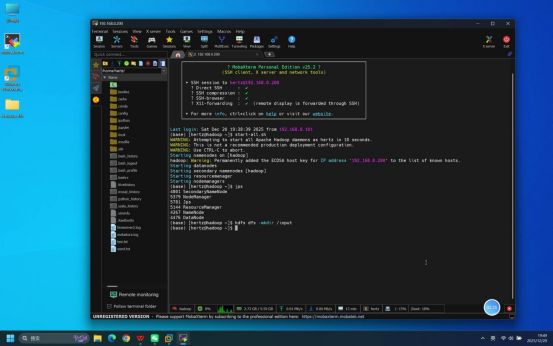
步骤6:创建HDFS输入目录
操作说明:在终端中执行HDFS命令,创建/input目录,用于后续存储待处理文件。
具体命令:hdfs dfs -mkdir /input
预期结果:命令执行无报错,/input目录在HDFS根路径下创建成功。
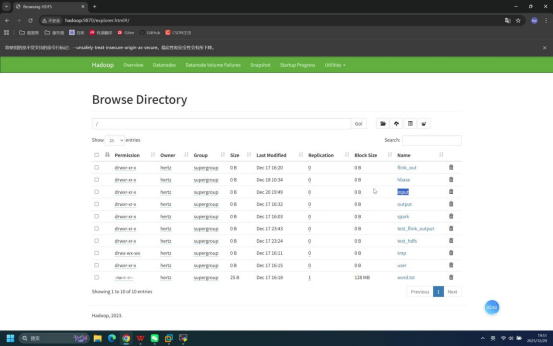
步骤7:浏览器访问HDFS WebUI验证目录
操作说明:打开本地浏览器,输入HDFS WebUI访问地址,查看刚创建的/input目录。
具体操作:
- 打开浏览器(如Chrome)
- 地址栏输入:hadoop:9870
- 进入页面后,点击左侧「Utilities」→「Browse the file system」
预期结果:浏览器成功加载HDFS文件系统页面,可在根路径下看到创建的/input目录。
步骤8:创建测试文本文件
操作说明:在终端中执行命令,先删除已存在的word.txt文件(若有),再创建新的word.txt并写入测试内容。
具体命令:rm -f word.txt && echo "hello hadoop" >> word.txt && echo "hello word" >> word.txt
说明:该命令通过&&串联,依次完成删除旧文件、写入两行文本的操作。
预期结果:命令执行无报错,在当前用户目录下成功创建word.txt文件,且文件包含两行测试文本。
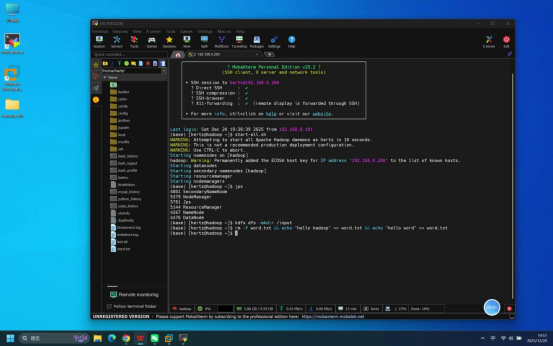
步骤9:上传测试文件至HDFS输入目录
操作说明:执行HDFS上传命令,将本地创建的word.txt文件上传至HDFS的/input目录。
具体命令:hdfs dfs -put word.txt /input
预期结果:命令执行无报错,word.txt文件成功上传至HDFS的/input目录。
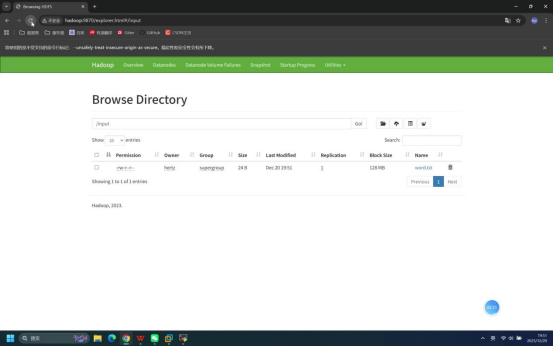
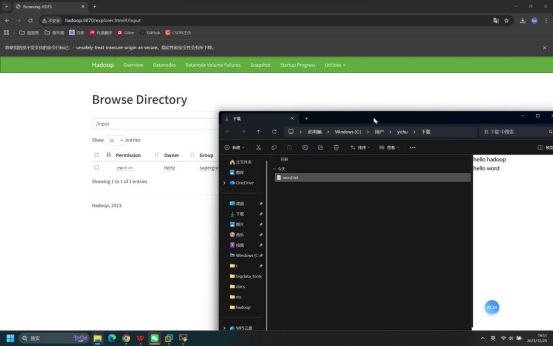
步骤10:浏览器验证文件并下载
操作说明:回到浏览器的HDFS WebUI页面,查看/input目录下是否新增word.txt文件,并下载该文件验证内容。
具体操作:
- 在HDFS WebUI的/input目录页面,确认显示word.txt文件
- 点击word.txt文件名称,选择「Download」下载文件至本地
- 打开下载后的文件
预期结果:
- 浏览器/input目录下成功显示word.txt文件
- 下载后的文件打开后,包含"hello hadoop"和"hello word"两行文本
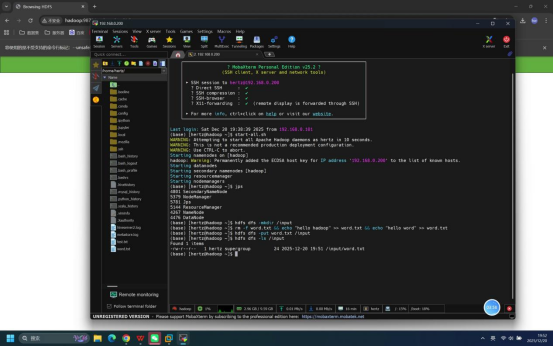
步骤11:查看HDFS输入目录文件列表
操作说明:在终端中执行HDFS命令,查看/input目录下的文件列表,再次验证文件上传情况。
具体命令:hdfs dfs -ls /input
预期结果:终端输出/input目录下的文件信息,包含word.txt文件的名称、大小、修改时间等。
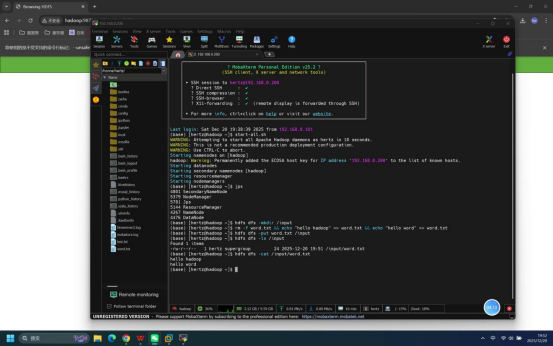
步骤12:查看HDFS中测试文件内容
操作说明:在终端中执行HDFS命令,查看HDFS上/input/word.txt文件的内容。
具体命令:hdfs dfs -cat /input/word.txt
预期结果:终端输出文件内容,显示"hello hadoop"和"hello word"两行文本,与本地文件内容一致。
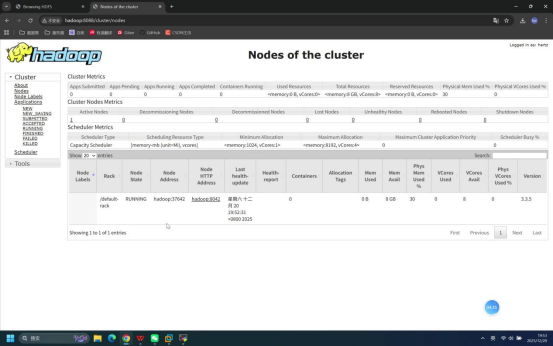
步骤13:浏览器访问YARN WebUI
操作说明:打开本地浏览器,输入YARN WebUI访问地址,查看YARN服务状态。
具体操作:
- 打开浏览器(可新建标签页)
- 地址栏输入:hadoop:8088
预期结果:浏览器成功加载YARN WebUI页面,显示集群节点、资源使用等信息,无服务异常提示。
步骤14:验证HDFS中output目录已存在
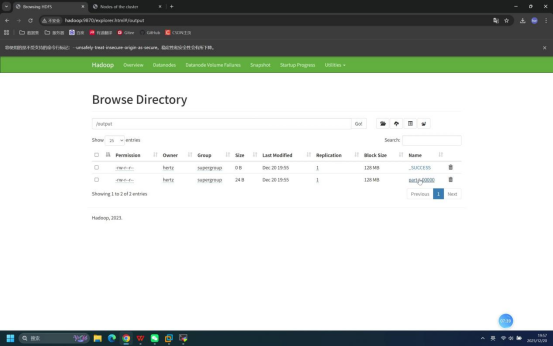
操作说明:回到浏览器的HDFS WebUI页面,查看根路径下是否已存在/output目录(若为重复测试,该目录可能残留)。
预期结果:浏览器HDFS根路径下可看到/output目录。
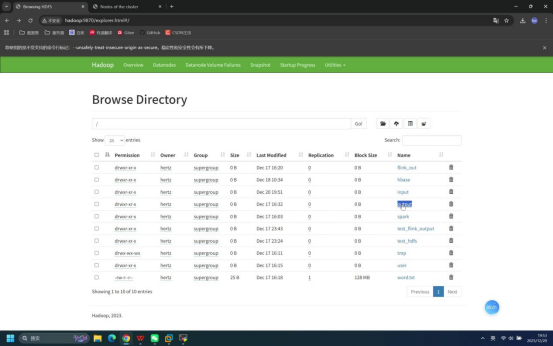
步骤15:删除HDFS中已存在的output目录
操作说明:在终端中执行HDFS删除命令,删除已存在的/output目录,避免影响后续MapReduce任务执行(MapReduce任务要求输出目录不存在)。
具体命令:hdfs dfs -rm -r /output
预期结果:命令执行无报错,HDFS根路径下的/output目录及其内容被彻底删除。
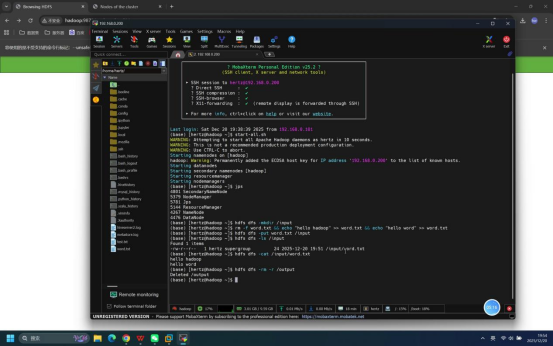
步骤16:执行MapReduce单词计数任务
操作说明:在终端中执行Hadoop自带的单词计数示例程序,对/input目录下的word.txt文件进行单词计数,输出结果至/output目录。
具体命令:hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /input /output
说明:
- $HADOOP_HOME为Hadoop安装目录,通过环境变量自动获取
- *.jar通配符匹配当前Hadoop版本对应的示例程序jar包
- wordcount为单词计数任务名称,/input为输入目录,/output为输出目录
预期结果:终端持续输出任务执行日志,最终显示"Successfully completed"等成功提示,MapReduce任务执行完成。
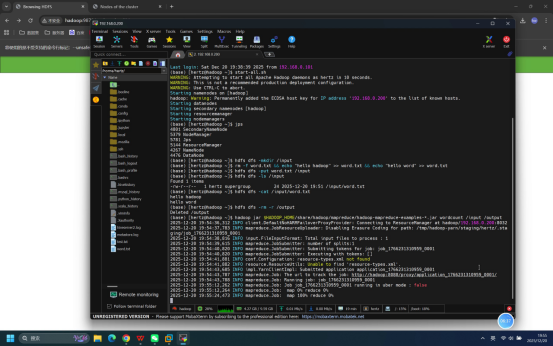
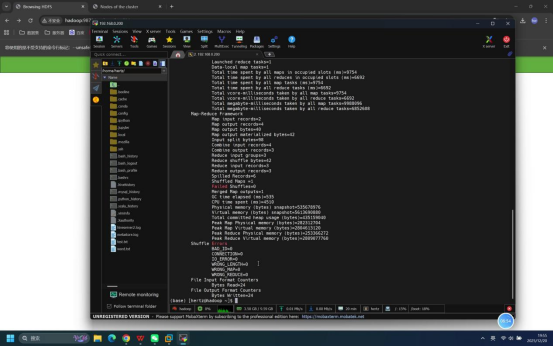
步骤17:查看MapReduce任务结果
操作说明:在终端中执行HDFS命令,查看/output目录下的任务结果文件内容。
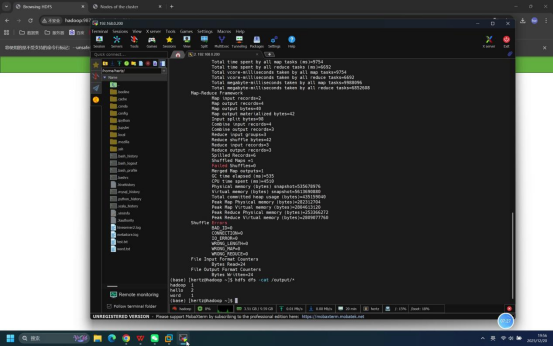
具体命令:hdfs dfs -cat /output/*
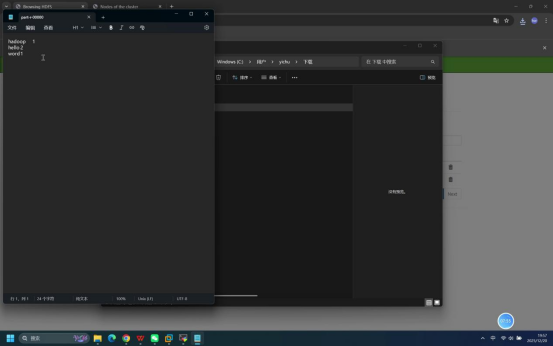
预期结果:终端输出单词计数结果,显示各单词及其出现次数,即:hello 2、hadoop 1、word 1。
步骤18:下载任务结果文件并验证
操作说明:回到浏览器的HDFS WebUI页面,进入/output目录,下载任务结果文件并打开验证内容。
具体操作:
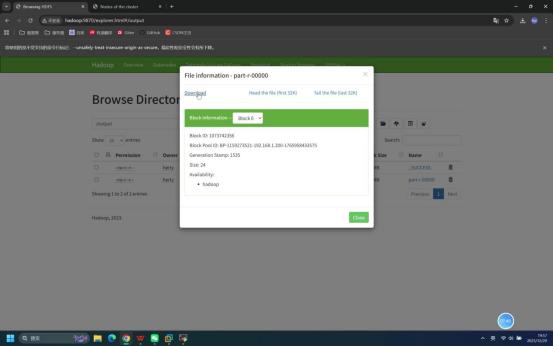
- 在HDFS WebUI中进入/output目录,确认显示part-r-00000等结果文件
- 点击结果文件名称,选择「Download」下载至本地
- 打开下载后的结果文件
预期结果:下载的结果文件中包含正确的单词计数信息,与终端查看的结果一致。
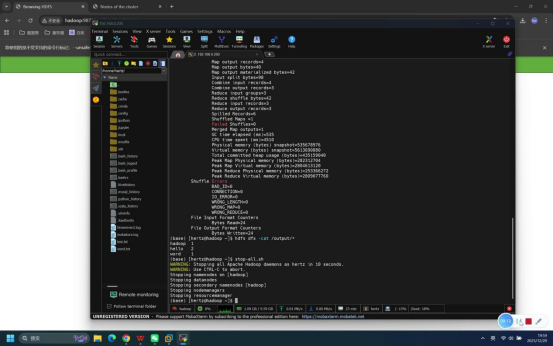
步骤19:关闭Hadoop相关服务
操作说明:测试完成后,在终端中执行Hadoop服务停止命令,关闭所有相关服务。
具体命令:
- 一键关闭所有服务:stop-all.sh
预期结果:终端无报错提示,依次显示各服务的停止日志信息。