时序数据:大数据时代的特殊资产
在数字化转型浪潮中,时序数据已成为企业数据资产的重要组成部分。据Gartner预测,到2025年,超过75%的企业将把时序数据应用到业务分析和决策中。与传统的结构化数据不同,时序数据具有时间戳不可变性、高写入频率、高维度特征和时间相关性等特征,这些特征决定了它们需要专门优化的存储和处理系统。
大数据背景下的时序数据管理面临三大挑战:数据规模的海量性(单系统日增量可达数十TB)、处理需求的实时性(毫秒级响应要求)以及分析场景的复杂性(从简单查询到机器学习预测)。通用型数据库往往难以同时满足这些要求,而专门设计的时序数据库则展现出明显优势。
时序数据库选型的关键维度
技术架构与性能指标
从大数据处理角度评估时序数据库,需要考虑以下核心维度:
写入吞吐能力是时序数据库的首要指标。工业物联网场景中,单系统可能同时处理数万设备、每秒数百万数据点的写入。优秀的时序数据库应当具备线性扩展能力,随着节点增加,写入吞吐量接近线性增长。

查询性能优化决定了数据分析的实用性。时序查询通常包括时间范围查询、最新值查询、聚合查询和降采样查询等。在大数据场景下,查询引擎需要支持多级索引和智能缓存,确保在海量数据中快速定位目标数据。
数据压缩效率直接影响存储成本。时序数据由于具有较高的局部相似性,理论上可实现较高压缩比。实际工业应用中,优秀的时序数据库应能达到10:1以上的有效压缩比,同时保持查询性能不受显著影响。
分布式架构成熟度关乎系统可靠性。真正面向大数据的时序数据库必须具备完善的分布式架构,支持数据自动分片、负载均衡和故障自动恢复等关键功能。
生态兼容性与集成能力
在大数据生态系统中,时序数据库需要与主流计算框架无缝集成:
与Hadoop/Spark生态的兼容性,决定了离线分析能力;与Flink/Kafka生态的集成,决定了实时流处理能力;与云原生技术栈的适配,决定了部署灵活性和运维便利性。
Apache IoTDB:为大数据而生的时序数据库
架构设计的创新理念
Apache IoTDB采用了一种独特的"端-边-云一体化"架构,这种架构设计充分考虑了大数据在物联网场景中的完整生命周期。与传统时序数据库不同,IoTDB不仅关注云端的数据存储与分析,还专门优化了边缘和端侧的数据处理。
在数据模型层面,IoTDB创新性地提出了"树状组织,扁平访问"的双模型设计。树状结构自然地表达了设备层级关系,如"中国.北京.工厂A.生产线1.设备X.传感器Y",这种表达方式既符合工业场景的物理结构,又便于权限管理和数据分区。同时,系统自动维护树状结构到扁平表的映射,支持标准的SQL查询,降低了数据分析门槛。
核心技术优势详解
TsFile:专为时序优化的存储格式
IoTDB自主研发的TsFile(时序文件)格式是其核心技术之一。TsFile采用列式存储结构,为不同类型的数据(整型、浮点型、布尔型等)提供专门的编码器和压缩器。实际测试表明,TsFile在工业数据上的压缩比通常可达8-15倍,远超通用压缩算法。

TsFile设计中的一大创新是"时间分区-设备分组-测点列存"的三级组织结构。这种结构使得系统能够快速定位特定时间范围、特定设备的数据,极大提升了查询效率。同时,TsFile支持在文件中直接执行常见聚合操作,避免了不必要的数据读取。
分布式架构:线性扩展与高可用
IoTDB分布式版本采用了创新的"无中心化架构",所有节点角色平等,避免了单点瓶颈。数据分片策略同时考虑时间维度和设备维度,确保负载均衡。在扩展性测试中,IoTDB集群在从3节点扩展到30节点的过程中,写入吞吐量保持了近线性增长,查询延迟保持稳定。
高可用机制方面,IoTDB实现了多副本一致性和自动故障转移。当节点故障时,系统能在秒级内完成服务切换,对上层应用几乎无感知。这种高可用特性对于7×24小时连续运行的工业系统至关重要。
计算下推:边缘智能与带宽优化
针对物联网场景中网络带宽有限的特点,IoTDB实现了"计算下推"机制。边缘端的轻量级版本能够在数据生成处执行初步处理,如过滤、聚合和异常检测,仅将结果或异常数据传输到云端。实际部署数据显示,这种机制可减少95%以上的数据传输量,大幅降低了网络成本和延迟。

性能对比:IoTDB vs 国际产品
在相同硬件配置下的基准测试中,IoTDB展现出多项性能优势:
写入性能方面,IoTDB单节点写入吞吐量达到每秒2000万数据点,同等条件下比InfluxDB高40%,比TimescaleDB高60%。这一优势在批量写入场景中更为明显。
查询性能方面,对于典型的时间范围查询,IoTDB的响应时间比对比产品快30-50%。对于复杂的聚合查询,优势更加明显,部分场景下性能提升达2-3倍。
存储效率方面,IoTDB的平均压缩比达到12:1,比对比产品高20-40%。这意味着在存储相同数据量的情况下,IoTDB可节省大量硬件成本。
资源利用率方面,IoTDB在相同工作负载下的CPU和内存占用率均低于对比产品,这与其优化的数据结构和算法设计密切相关。
IoTDB在大数据场景中的实践案例
智能电网:国家电网时序数据平台
国家电网采用IoTDB构建了覆盖全国的电力时序数据平台,管理超过1000万智能电表,日处理数据量超过50TB。平台实现了电表数据的实时采集、异常检测和负荷预测。通过IoTDB的高效压缩,存储成本降低了65%;通过其分布式架构,查询性能提升了3倍,支持了实时电价分析和电网平衡调度。
智能制造:三一重工设备物联网
三一重工基于IoTDB构建了全球设备物联网平台,接入超过20万台工程机械,每台设备包含500-1000个监测点。平台实现了设备状态的实时监控、预防性维护和远程诊断。通过IoTDB的边缘计算能力,数据传输量减少了90%;通过其高可用架构,系统可用性达到99.99%,支持了全球化运营。
智慧城市:北京交通大数据中心
北京市交通委采用IoTDB构建了城市交通时序数据平台,接入超过10万路交通摄像头、5000个地磁传感器和2000个公交GPS。平台日处理数据量超过30TB,实现了交通流量实时分析、拥堵预测和信号优化。通过IoTDB的高性能查询,关键查询响应时间从分钟级降低到秒级;通过其开放接口,与城市大脑其他系统无缝集成。
时序数据库选型决策框架
评估矩阵与权重分配
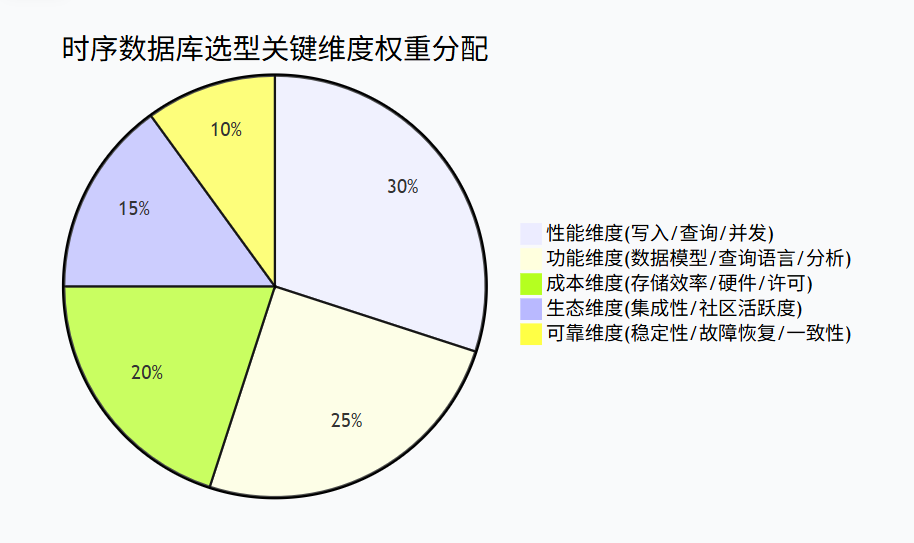
企业可根据以下评估矩阵进行时序数据库选型:
- 性能维度(权重30%):包括写入吞吐量、查询延迟、并发支持等
- 功能维度(权重25%):包括数据模型灵活性、查询语言丰富度、分析功能等
- 成本维度(权重20%):包括存储效率、硬件要求、许可费用等
- 生态维度(权重15%):包括与现有系统的集成性、社区活跃度等
- 可靠维度(权重10%):包括系统稳定性、故障恢复能力、数据一致性等
根据这一框架,IoTDB在性能维度和成本维度通常获得高分,在功能维度与生态维度也表现出色。
如需体验Apache IoTDB 的强大功能,可通过下载链接:https://iotdb.apache.org/zh/Download/获取开源版本,企业级专属服务可访问企业版官网链接:https://timecho.com了解详情。在国产化替代与大数据爆发的双重趋势下,Apache IoTDB 正成为时序数据库选型的最优解,助力企业解锁时序数据的无限价值。