Exception:
org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeout
启动一个大任务的时候报了这个错,怎么都启动不来,之前的反应一般是加资源,但实际上资源已经挺充沛的了,反而可以考虑一手减资源,着重减少tm的数量,可以让tm包括jm启动的更顺利。因为tm多了,如果某些 TM 启动慢、网络延迟、或资源竞争,可能导致:
- 部分 slot 请求超时
- 即使总 slot 够用,但分配不均导致失败
接下来我们看看8个tm和4个tm的差别:
8 个 TM 场景:
-
JobManager 向 8 个 TM 请求 slot
-
如果其中 1-2 个 TM 响应慢 → 超时
-
即使后续 TM 响应了,但已经触发 NoResourceAvailableException
-
可能在不同物理节点上
-
每个节点的 CPU/网络资源被多个服务竞争
-
导致 TM 注册延迟
4 个 TM 场景:
-
只需等待 4 个 TM 响应
-
响应更快、更稳定
-
资源更集中
-
减少节点间的依赖
虽然吞吐降低了,但是确实更容易启动任务了。
修复方案:我降低了并行度,从16降到了12,就顺利启动了。
-ytm 14336 -ys 4 -yn 6 -p 12
其实也可以再加个yn=6的操作。这样会启动 6 个 TM,共 24 个 slot,可以稳定支持并行度为 12 的作业。
回顾下并行度和slot的概念。
1. Slot 总数 = 物理资源上限
TM 数量 × 每 TM 的 slot 数 = 集群能提供的最大并行能力
例如:6 个 TM × 4 slot = 24 个 slot
→ 这是硬件/资源的物理限制
→ 理论上最多支持 24 个任务同时运行
2. 并行度 = 作业的逻辑并行度 = 每个算子有多少个并行实例
parallelism.default: 12
→ 这是告诉 Flink:"我的数据流要分成 12 份处理"
→ 每个算子会创建 12 个并行子任务
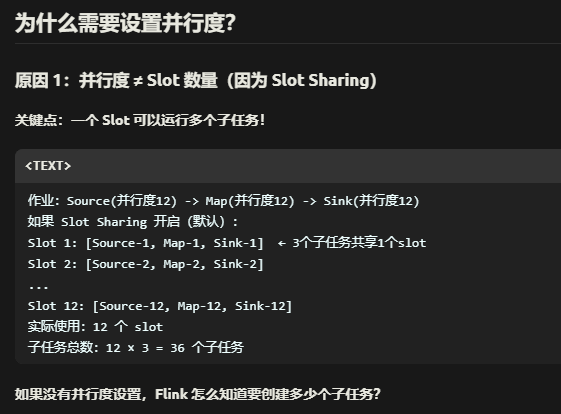
问题1:为什么理论上最多支持24个任务同时运行?不是有槽共享吗?
虽然有槽共享,但是一个slot内往往只分配一个core,所以假如一个slot内有三个算子,三个算子并不是真正并行的!是轮流运行的!但是一个slot分配了多个core,就可以同时运行更多的任务,提高真实并发。
问题2:为什么总slot数必须大于等于我们设置的并行度。
因为我们假如设置了12并行度,6个slot,每个算子会被分成12份,虽然槽共享,但是**同一个算子的不同并行实例不能共享同一个 Slot!**所以这样slot就不够分配了!
综上,所以一般并行度确实等于slot*tm数量,除非你slot或者tm数量给的很多,大于了并行度,这样slot就会有闲置的。