图片轮廓提取

这是一柄扇子,我们将对它进行轮廓提取
python
import cv2
import numpy as np
fan = cv2.imread('fan.jpg') # 读取原图
fan = cv2.resize(fan,(640,480)) # 调整图片尺寸
fan = cv2.rotate(fan, cv2.ROTATE_90_COUNTERCLOCKWISE)#顺时针旋转90度
fan_gray = cv2.cvtColor(fan,cv2.COLOR_BGR2GRAY) # 转换为灰度图
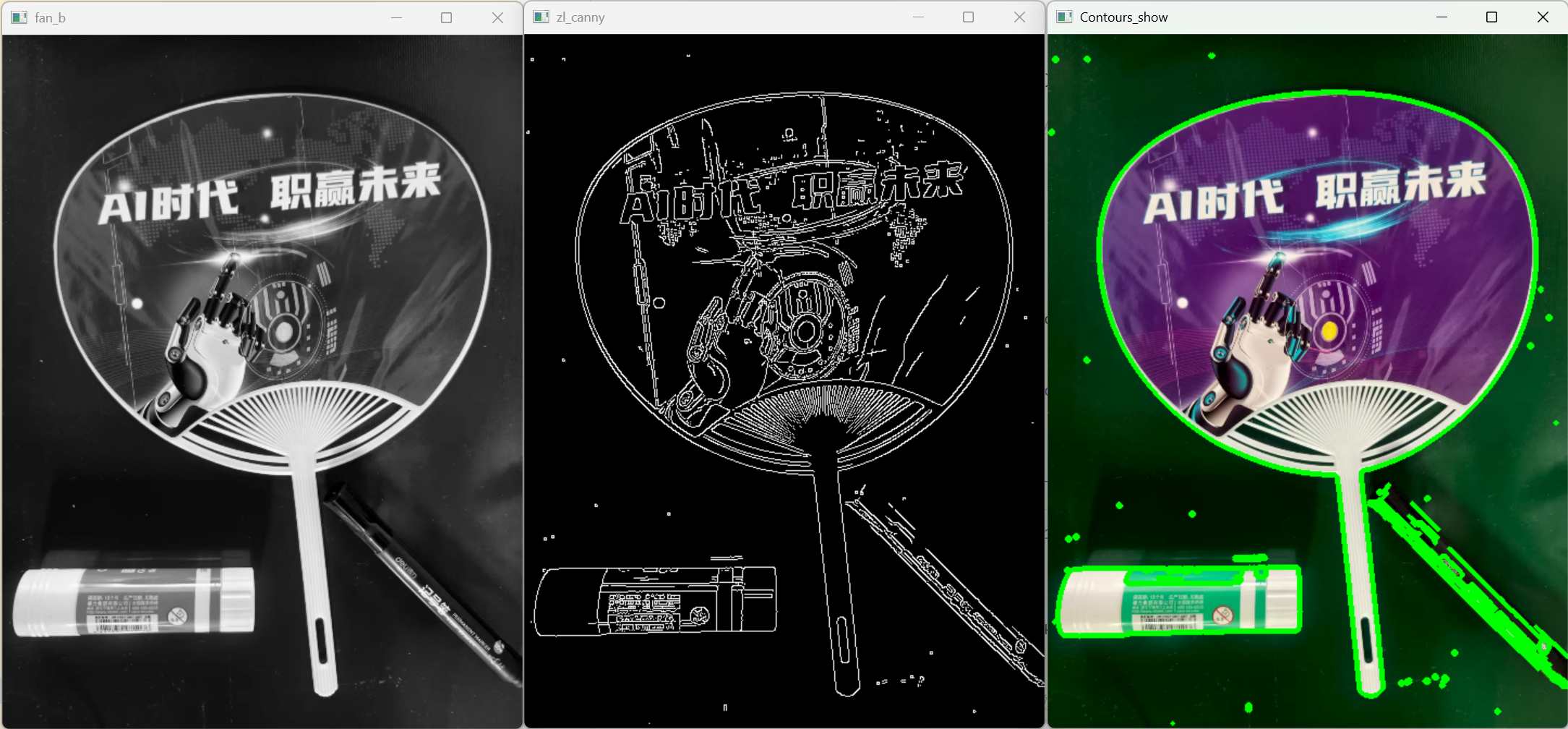
cv2.imshow('fan_b', fan_gray)
cv2.waitKey(0)
zl_canny = cv2.Canny(fan_gray,100,150) #Canny边缘检测
cv2.imshow('zl_canny', zl_canny)
cv2.waitKey(0)
_,contours, hierarchy = cv2.findContours (zl_canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
image_copy = fan.copy()
image_copy = cv2.drawContours(image=image_copy, contours=contours, contourIdx=-1, color=(0, 255, 0), thickness=3)#绘制轮廓
cv2.imshow('Contours_show', image_copy)
cv2.waitKey(0)
cnt = sorted(contours, key=cv2.contourArea, reverse=True)[0] # 选取最大积的轮
mask = np.zeros(fan_gray.shape,dtype="uint8") # 创建一个黑色掩模
cv2.drawContours (mask, contours=[cnt], contourIdx=-1, color=255, thickness=-1) # 最大轮
cv2.imshow('mask', mask)
cv2.waitKey(0)
thresh_mask_and = cv2.bitwise_and(fan, fan, mask=mask) # 按掩模提取图片
cv2.imshow('thresh_mask_and', thresh_mask_and)
cv2.waitKey(0)
cv2.imwrite( 'shanzi.png', thresh_mask_and)# 保存提取的图片解析:
python
fan = cv2.imread('fan.jpg') # 读取原图
fan = cv2.resize(fan,(640,480)) # 调整图片尺寸
fan = cv2.rotate(fan, cv2.ROTATE_90_COUNTERCLOCKWISE)#顺时针旋转90度cv2.imread('fan.jpg'):从当前目录读取名为fan.jpg的图片,返回的fan是一个三维 NumPy 数组(高度 × 宽度 × 通道数,OpenCV 默认通道顺序是 BGR 而非 RGB)。cv2.resize(fan,(640,480)):将图片统一调整为 640×480 像素,避免原图尺寸过大 / 过小影响后续处理。cv2.rotate(...):注意代码注释有误,cv2.ROTATE_90_COUNTERCLOCKWISE是逆时针旋转 90 度 (顺时针旋转 90 度应使用cv2.ROTATE_90_CLOCKWISE),目的是调整图片方向至便于处理的角度。
python
fan_gray = cv2.cvtColor(fan,cv2.COLOR_BGR2GRAY) # 转换为灰度图
cv2.imshow('fan_b', fan_gray)
cv2.waitKey(0)cv2.cvtColor(...):将彩色 BGR 图转换为灰度图,fan_gray是二维数组(高度 × 宽度),灰度图能减少计算量,是边缘检测、轮廓提取的前置步骤。cv2.imshow('fan_b', fan_gray):创建名为fan_b的窗口显示灰度图。cv2.waitKey(0):等待用户按下任意键后继续执行(参数 0 表示无限等待),方便查看每一步处理结果
python
zl_canny = cv2.Canny(fan_gray,100,150) #Canny边缘检测
cv2.imshow('zl_canny', zl_canny)
cv2.waitKey(0)cv2.Canny(...):对灰度图做 Canny 边缘检测,参数 100 是低阈值 、150 是高阈值 ,算法会筛选出图像中明显的边缘(边缘处像素值为 255,非边缘为 0),返回的zl_canny是二值图(只有黑 / 白)。
python
_,contours, hierarchy = cv2.findContours (zl_canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)cv2.findContours(...):从二值边缘图中提取轮廓(轮廓是连续的边缘像素组成的曲线,代表物体的边界)。
- 参数 1:输入的二值图(zl_canny);
- 参数 2:
cv2.RETR_EXTERNAL:只提取最外层轮廓(忽略内部小轮廓,比如风扇叶片间的空隙); - 参数 3:
cv2.CHAIN_APPROX_SIMPLE:压缩轮廓点(比如用 4 个点表示矩形,而非所有像素点),节省内存; - 返回值:
_是轮廓检测的阈值(无用),contours是所有轮廓的列表(每个轮廓是像素坐标数组),hierarchy是轮廓的层级关系。
python
image_copy = fan.copy()
image_copy = cv2.drawContours(image=image_copy, contours=contours, contourIdx=-1, color=(0, 255, 0), thickness=3)#绘制轮廓
cv2.imshow('Contours_show', image_copy)
cv2.waitKey(0)fan.copy():复制原图(避免直接修改原图),用于绘制轮廓展示。cv2.drawContours(...):在复制的图片上绘制所有轮廓:contourIdx=-1:绘制所有轮廓(指定数值则只绘制对应索引的轮廓);color=(0,255,0):轮廓颜色为绿色(BGR 顺序);thickness=3:轮廓线宽度为 3 像素;
- 展示绘制轮廓后的图片,能直观看到提取的轮廓位置。
python
cnt = sorted(contours, key=cv2.contourArea, reverse=True)[0] # 选取最大面积的轮廓
mask = np.zeros(fan_gray.shape,dtype="uint8") # 创建一个黑色掩模
cv2.drawContours (mask, contours=[cnt], contourIdx=-1, color=255, thickness=-1) # 最大轮廓填充白色
cv2.imshow('mask', mask)
cv2.waitKey(0)这部分是掩膜的核心创建步骤:
sorted(contours, key=cv2.contourArea, reverse=True)[0]:- 按轮廓面积(
cv2.contourArea计算)从大到小排序,取第一个([0]),即风扇主体的轮廓(排除小的干扰轮廓)。
- 按轮廓面积(
np.zeros(fan_gray.shape,dtype="uint8"):- 创建与灰度图尺寸完全相同的数组,所有元素初始值为 0(对应黑色),数据类型为
uint8(OpenCV 图像的标准类型,取值 0-255),这就是初始掩膜(全黑)。 - 掩膜的本质:是一张和原图尺寸一致的二值图,
0(黑)表示 "屏蔽区域",255(白)表示 "保留区域"。
- 创建与灰度图尺寸完全相同的数组,所有元素初始值为 0(对应黑色),数据类型为
cv2.drawContours (mask, contours=[cnt], ..., color=255, thickness=-1):- 仅将最大轮廓(风扇主体)绘制到掩膜上;
color=255:绘制颜色为白色;thickness=-1:特殊值,表示填充整个轮廓内部(而非只画轮廓线);- 最终掩膜效果:只有风扇主体区域是白色(255),其余区域都是黑色(0)。
- 展示掩膜,能看到白色区域就是要保留的风扇部分。
python
thresh_mask_and = cv2.bitwise_and(fan, fan, mask=mask) # 按掩模提取图片
cv2.imshow('thresh_mask_and', thresh_mask_and)
cv2.waitKey(0)
cv2.imwrite( 'shanzi.png', thresh_mask_and)# 保存提取的图片这部分是掩膜的核心应用步骤:
cv2.bitwise_and(fan, fan, mask=mask):cv2.bitwise_and是按位与运算,规则是:只有两个对应像素都为非 0 时,结果才非 0;- 这里传入两个
fan(原图),再指定mask=mask:- 掩膜中白色区域(255) :执行
fan & fan,结果就是原图的像素值(保留); - 掩膜中黑色区域(0):无论原图像素是多少,结果都为 0(屏蔽,变成黑色);
- 掩膜中白色区域(255) :执行
- 最终效果:只有掩膜白色区域对应的风扇主体被保留,其余区域变为黑色,实现了 "抠图"。
cv2.imwrite(...):将抠取后的结果保存为shanzi.png。
掩膜的核心总结
1. 掩膜(mask)的本质
- 掩膜是和原图尺寸一致的二值图像(只有 0 和 255),是 OpenCV 中 "精准筛选像素" 的核心工具:
0(黑色):表示该位置的像素需要被屏蔽 / 丢弃;255(白色):表示该位置的像素需要被保留 / 显示。
2. 这段代码中掩膜的作用流程
- 创建全黑掩膜 → 2. 填充目标轮廓为白色 → 3. 通过按位与运算,只保留掩膜白色区域的原图像素。
3. 掩膜的常见应用场景
- 图像抠图(如本例提取风扇主体);
- 区域限定(只处理图像中特定区域,比如只检测某块区域的人脸);
- 图像融合(只替换图片中指定区域的内容)。
运行结果:

视频动态物体识别:
python
import cv2
#经典的测试视频
cap = cv2.VideoCapture('test.avi')
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS,(3,3))
fgbg = cv2.createBackgroundSubtractorMOG2()
while True:
ret, frame = cap.read() #ret:True表示正常读取到图像,frame:从视频中获取当前一帧图片
if not ret:
break
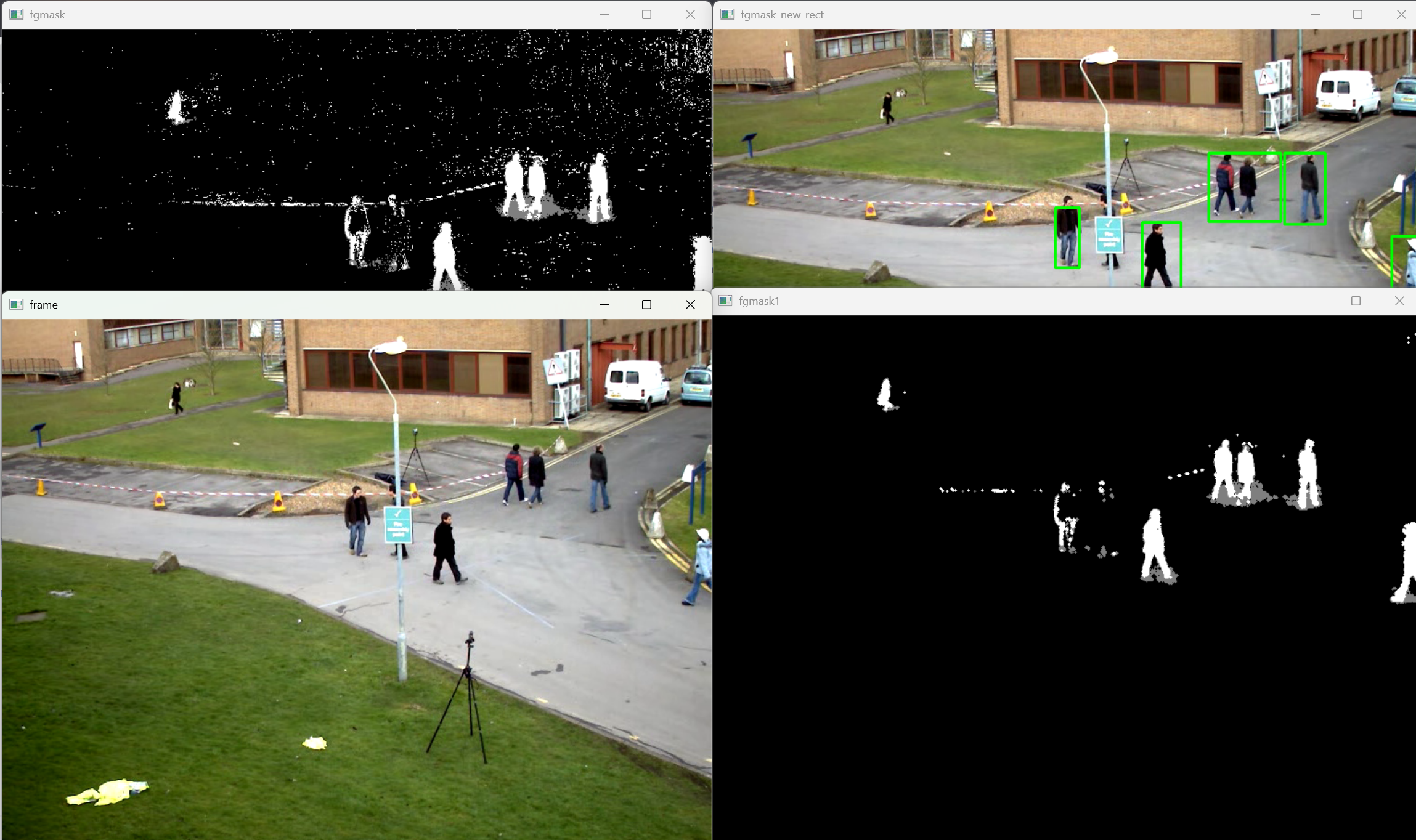
cv2.imshow('frame', frame)
fgmask = fgbg.apply(frame) #视频处理
cv2.imshow('fgmask', fgmask)
fgmask_new = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel) #开运算去噪点,先腐蚀后膨胀。
cv2.imshow('fgmask1', fgmask_new)
_,contours, h = cv2. findContours(fgmask_new, cv2.RETR_EXTERNAL, cv2. CHAIN_APPROX_SIMPLE)
for c in contours:
#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
# 找到一个直矩形
x, y, w, h = cv2.boundingRect(c)
# 画出这个矩形
fgmask_new_rect = cv2.rectangle(frame,(x, y),(x + w, y + h),(0, 255, 0),2)
cv2.imshow('fgmask_new_rect', fgmask_new_rect)
k = cv2.waitKey(60)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()运行结果
解析:
python
#经典的测试视频
cap = cv2.VideoCapture('test.avi')cv2.VideoCapture():创建视频捕获对象,参数可以是视频文件路径(如test.avi)、摄像头索引号(0 表示默认摄像头)。cap对象会逐帧读取视频内容,后续通过cap.read()获取每一帧图像。- 注意:如果视频文件路径错误(比如文件不存在、路径带中文),
cap会初始化失败,后续cap.read()会返回(False, None)。
python
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS,(3,3))cv2.getStructuringElement():创建形态学操作的结构元素(核) ,用于后续的开运算。- 参数 1:
cv2.MORPH_CROSS:十字形结构元素(也可以选矩形MORPH_RECT、椭圆形MORPH_ELLIPSE); - 参数 2:
(3,3):结构元素的尺寸为 3×3 像素;
- 参数 1:
- 结构元素的作用:形态学操作(腐蚀 / 膨胀)时,用这个核去扫描图像像素,决定像素的保留 / 替换规则,3×3 是最常用的小核,既能去噪又不会过度破坏目标轮廓。
python
fgbg = cv2.createBackgroundSubtractorMOG2()cv2.createBackgroundSubtractorMOG2():创建 MOG2 背景减除器对象。- 核心原理:MOG2(Mixture of Gaussians 2)是一种经典的背景建模算法,它会自动学习视频的背景模型 (静态区域),并将每一帧中与背景差异大的区域判定为前景(运动物体)。
- 优势:无需手动标注背景,能自适应光照变化、背景轻微抖动等场景,是视频运动检测的首选算法之一。
python
while True:
ret, frame = cap.read() #ret:True表示正常读取到图像,frame:从视频中获取当前一帧图片
if not ret:
breakwhile True:无限循环,逐帧处理视频;cap.read():读取视频的下一帧,返回两个值:ret:布尔值,True表示成功读取帧,False表示视频读取完毕(或出错);frame:当前帧的图像数组(BGR 格式,三维数组:高度 × 宽度 × 通道);
if not ret: break:如果读取失败(比如视频播放完),跳出循环,结束处理。
python
cv2.imshow('frame', frame)创建名为frame的窗口,实时显示视频的原始帧,方便对比原始画面和检测结果。
python
fgmask = fgbg.apply(frame) #视频处理
cv2.imshow('fgmask', fgmask)fgbg.apply(frame):将当前帧传入背景减除器,执行背景减除操作,返回fgmask(前景掩膜)。fgmask是二值图(二维数组):像素值 255 表示 "前景(运动物体)",0 表示 "背景(静态区域)";- 注意:此时的掩膜可能包含大量小噪点(比如光影变化、视频压缩噪点),直接用会导致轮廓检测出错。
- 展示前景掩膜,能直观看到算法识别的运动区域。
python
fgmask_new = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel) #开运算去噪点,先腐蚀后膨胀。
cv2.imshow('fgmask1', fgmask_new)cv2.morphologyEx():执行形态学操作,这里是开运算(MORPH_OPEN) 。- 开运算的定义:先腐蚀(Erode) → 后膨胀(Dilate) ;
- 腐蚀:用结构元素扫描图像,将像素值替换为核内的最小值,能 "吃掉" 小的亮区域(噪点),收缩前景轮廓;
- 膨胀:用结构元素扫描图像,将像素值替换为核内的最大值,能恢复前景轮廓的大小(弥补腐蚀的收缩);
- 核心作用:去除小噪点,同时保留大的前景区域的形状和大小,是视频前景处理的必备步骤;
- 开运算的定义:先腐蚀(Erode) → 后膨胀(Dilate) ;
fgmask_new是优化后的前景掩膜,噪点被清除,运动目标的轮廓更清晰。
python
_,contours, h = cv2.findContours(fgmask_new, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)cv2.findContours():从优化后的二值掩膜中提取轮廓(轮廓是前景区域的边界曲线)。- 参数 1:输入的二值图(fgmask_new);
- 参数 2:
cv2.RETR_EXTERNAL:只提取最外层轮廓(忽略内部小轮廓,比如目标物体内部的空洞); - 参数 3:
cv2.CHAIN_APPROX_SIMPLE:压缩轮廓点(比如用 4 个点表示矩形,而非所有像素点),节省内存; - 返回值:
_是阈值(无用),contours是所有轮廓的列表(每个轮廓是像素坐标数组),h是轮廓的层级关系。
python
for c in contours:
#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
# 找到一个直矩形
x, y, w, h = cv2.boundingRect(c)
# 画出这个矩形
fgmask_new_rect = cv2.rectangle(frame,(x, y),(x + w, y + h),(0, 255, 0),2)这是目标框选的核心逻辑:
for c in contours:遍历所有提取到的轮廓;perimeter = cv2.arcLength(c,True):计算单个轮廓的周长,参数True表示轮廓是闭合的(运动目标的轮廓都是闭合的);if perimeter > 188:筛选周长大于 188 的轮廓 ------ 目的是排除开运算后仍残留的微小噪点轮廓(比如 10 像素周长的小亮点),188 是经验阈值(可根据视频场景调整);x, y, w, h = cv2.boundingRect(c):计算轮廓的最小外接矩形 :x,y:矩形左上角的像素坐标;w,h:矩形的宽度和高度;
cv2.rectangle(frame,(x, y),(x + w, y + h),(0, 255, 0),2):在原始帧上绘制矩形框:frame:绘制的目标图像(原始帧);(x,y):矩形左上角;(x+w,y+h):矩形右下角;(0,255,0):矩形颜色为绿色(BGR 顺序);2:矩形线宽为 2 像素;- 注意:
cv2.rectangle会直接修改传入的frame数组,fgmask_new_rect其实就是修改后的frame。
python
cv2.imshow('fgmask_new_rect', fgmask_new_rect)展示绘制了矩形框的视频帧,能实时看到运动目标被绿色框标注的效果。
python
k = cv2.waitKey(60)
if k == 27:
breakcv2.waitKey(60):等待 60 毫秒,返回按下的键盘按键的 ASCII 码(如果没按键,返回 - 1);- 60 毫秒的等待是为了控制视频播放速度(约 16 帧 / 秒),避免播放过快;
if k == 27:27 是 ESC 键的 ASCII 码,按下 ESC 键则跳出循环,结束程序。
python
cap.release()
cv2.destroyAllWindows()cap.release():释放视频捕获对象占用的资源(比如文件句柄、摄像头资源);cv2.destroyAllWindows():关闭所有 OpenCV 创建的窗口,避免程序退出后残留窗口。
- 阈值调整:
perimeter > 188是经验值,如果检测不到目标,可减小阈值;如果框选了太多噪点,可增大阈值; - 视频路径:确保
test.avi在程序运行目录下,或使用绝对路径(如D:/video/test.avi); - OpenCV 版本:代码中
cv2.findContours返回 3 个值(_,contours,h),是 OpenCV 3.x/4.x 的写法;如果是 2.x 版本,返回 2 个值(contours,h),需去掉前面的_; - 结构元素:
(3,3)的十字核可替换为(5,5)的矩形核,去噪效果更强,但可能会模糊小目标的轮廓。 - 这段代码的核心是MOG2 背景减除 + 开运算去噪 + 轮廓检测 + 矩形框选,实现视频运动目标的实时检测;
- 开运算(先腐蚀后膨胀)是关键的去噪步骤,能有效过滤前景掩膜中的微小噪点;
- 轮廓周长筛选(
perimeter > 188)是排除干扰、精准框选目标的核心阈值手段,需根据实际场景调整。
光流估计:
python
import numpy as np
import cv2
#打开视频文件
cap = cv2.VideoCapture('test.avi')
# 随机生成颜色,用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))
# 读取视频的第一帧
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
#定义特征点检测参数
feature_params=dict(maxCorners=100,# 最大角点数量
qualityLevel=0.3,#角点质量的阈值
minDistance=7) # 最小距离,用于分散角点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
#**:关键字参数解包,用于将字典解包为关键字参数。
# 创建一个与当前帧大小相同的全零掩模,用于绘制轨迹
mask = np.zeros_like(old_frame)
lk_params = dict(winSize=(15, 15), # 窗口大小
maxLevel=2) #金字塔层数
while True:
# 读取下一帧
ret, frame = cap.read()
# 检查是否成功读取到帧
if not ret:
break
#将当前帧转换为灰度图像
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0 ,None, **lk_params)
good_new = p1[st == 1]
good_old = p0[st == 1]
for i, (new, old) in enumerate(zip(good_new, good_old)):
a,b=new #获取新点的坐标或者[a,b]=new
c,d=old #获取旧点的坐标
a,b,c,d=int(a),int(b),int(c),int(d)#转换为整数
#在掩模上绘制线段,连接新点和旧点
mask = cv2.line(mask,(a, b),(c, d),color[i].tolist(),2)
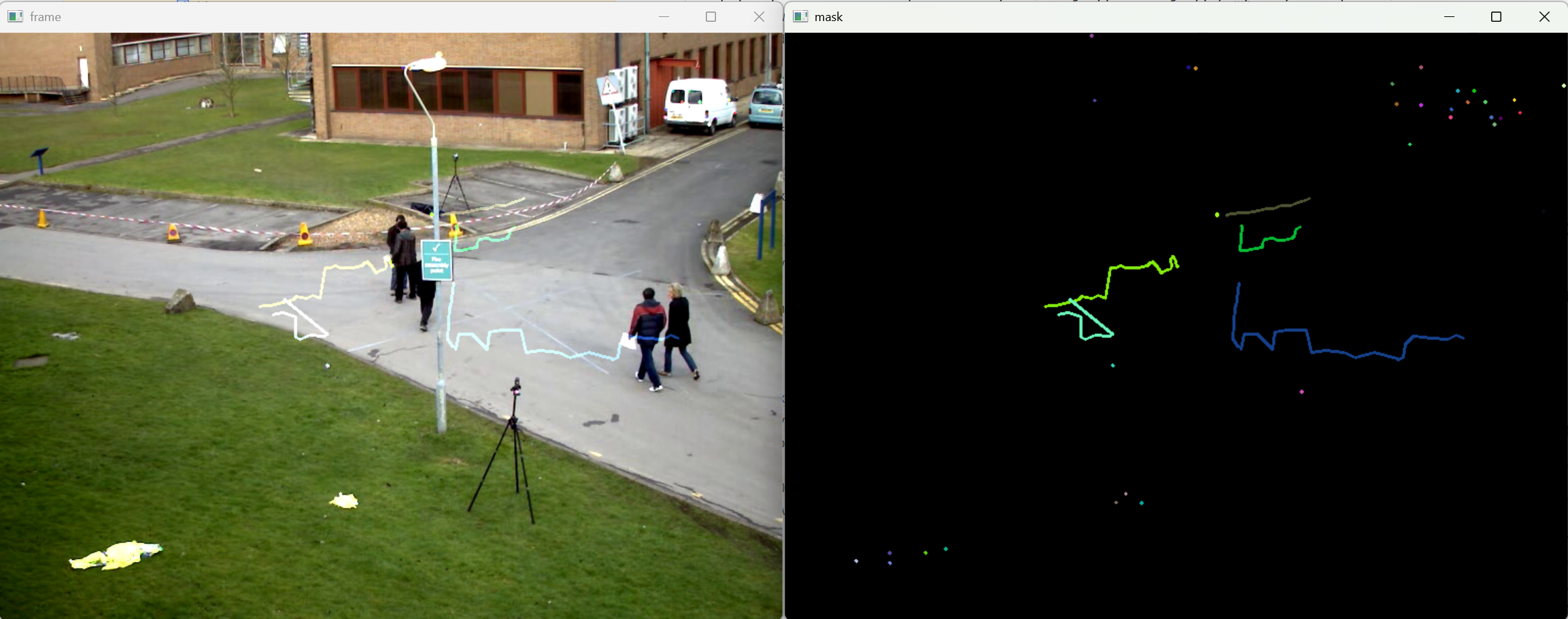
cv2.imshow('mask',mask)
#将掩模添加到当前帧上,生成最终图像
img = cv2.add(frame, mask)
# 显示结果图像
cv2.imshow('frame', img)
#等待150ms,检测是否按下了Esc键(键码为27)#
k = cv2.waitKey(150)
if k == 27:#按下Esc键,退出循环
break
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2) #重新整理特征点为适合下次计算的形状 (38,2)-->(38,1,2)
cap.releaseO
cv2.destroyAllWindows()运行结果:
解析:
python
#打开视频文件
cap = cv2.VideoCapture('test.avi')cv2.VideoCapture('test.avi'):创建视频捕获对象,读取指定的视频文件(test.avi);- 若要读取摄像头,可将参数改为
0(默认摄像头),逻辑完全通用。
python
# 随机生成颜色,用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))np.random.randint(0, 255, (100, 3)):生成 100 组随机颜色(每组 3 个值,对应 BGR 通道,取值 0-255);- 作用:为每个特征点分配唯一的随机颜色,让不同特征点的轨迹更容易区分(最多支持 100 个特征点,与后续
maxCorners=100对应)。
python
# 读取视频的第一帧
ret, old_frame = cap.read()-
读取视频的第一帧,作为跟踪的基准帧 :
-
ret:布尔值,True表示读取成功; -
old_frame:第一帧的彩色图像(BGR 格式,三维数组)。old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
-
-
将第一帧转换为灰度图 (
old_gray); -
原因:特征检测(角点)和光流计算对灰度图即可完成,灰度图是二维数组,计算量远小于彩色图,能提升跟踪效率。
python
#定义特征点检测参数
feature_params=dict(
maxCorners=100, # 最大角点数量:最多检测100个角点
qualityLevel=0.3, # 角点质量的阈值:只保留质量值>0.3的角点(质量值0-1)
minDistance=7 # 最小距离:检测到的角点之间的像素距离≥7,避免角点扎堆
)- 用字典封装
goodFeaturesToTrack(角点检测)的参数,让代码更整洁; - 关键参数解释:
maxCorners:限制特征点数量,避免过多点导致计算卡顿;qualityLevel:过滤低质量角点(比如平坦区域的伪角点),值越小检测到的点越多,但噪声也越多;minDistance:保证角点在图像中分散分布,避免集中在一个小区域。
python
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
#**:关键字参数解包,用于将字典解包为关键字参数。cv2.goodFeaturesToTrack():经典的Shi-Tomasi 角点检测算法 ,从灰度图中提取 "角点"(图像中像素值变化剧烈的点,比如物体边缘、角落,是跟踪的理想特征);- 参数
mask=None:不使用掩膜,检测整张图的角点; **feature_params:字典解包,等价于maxCorners=100, qualityLevel=0.3, minDistance=7,简化参数传递;
- 参数
- 返回值
p0:初始特征点坐标数组,形状为(N, 1, 2)(N≤100,1 是维度占位,2 是 x/y 坐标),例如[[[100, 200]], [[150, 250]]]。
python
# 创建一个与当前帧大小相同的全零掩模,用于绘制轨迹
mask = np.zeros_like(old_frame)np.zeros_like(old_frame):创建和第一帧尺寸、通道数完全相同的全黑图像(像素值 0);- 作用:专门用于绘制特征点的运动轨迹(线段),后续将掩膜叠加到原始帧上,避免直接修改原始帧。
python
lk_params = dict(
winSize=(15, 15), # 窗口大小:计算光流时的搜索窗口,15×15是常用值
maxLevel=2 #金字塔层数:2层金字塔,用于多尺度光流计算(抗尺度变化)
)- 封装 LK 光流算法的参数:
winSize:搜索窗口越大,跟踪越稳定,但计算越慢;maxLevel:金字塔层数,层数越多,能跟踪的运动幅度越大(比如物体快速移动),但计算量增加。
python
while True:
# 读取下一帧
ret, frame = cap.read()
# 检查是否成功读取到帧
if not ret:
break- 进入逐帧处理循环:
cap.read()读取下一帧,ret=False表示视频读取完毕(或出错),跳出循环;frame是当前帧的彩色图像。
python
#将当前帧转换为灰度图像
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)转换为灰度图,用于和基准帧(old_gray)做光流计算。
python
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0 ,None, **lk_params)cv2.calcOpticalFlowPyrLK():核心函数,计算金字塔 LK 光流 (Lucas-Kanade Optical Flow);- 作用:根据基准帧(
old_gray)的特征点(p0),找到当前帧(frame_gray)中对应的特征点(p1); - 参数说明:
old_gray:前一帧灰度图(基准帧);frame_gray:当前帧灰度图;p0:前一帧的特征点;None:无反向验证(简化版);**lk_params:解包光流参数;
- 返回值:
p1:当前帧中匹配到的特征点坐标,形状和p0一致;st:状态数组(0/1),1表示特征点跟踪成功,0表示跟踪失败(比如点移出画面);err:跟踪误差,数值越大表示匹配越不可靠。
- 作用:根据基准帧(
python
good_new = p1[st == 1]
good_old = p0[st == 1]- 筛选出跟踪成功 的特征点:
st == 1:布尔索引,只保留跟踪成功的点;good_new:当前帧的有效特征点,形状为(M, 2)(M≤N,2 是 x/y 坐标);good_old:基准帧对应的有效特征点,形状和good_new一致。
python
for i, (new, old) in enumerate(zip(good_new, good_old)):
a,b=new #获取新点的坐标或者[a,b]=new
c,d=old #获取旧点的坐标
a,b,c,d=int(a),int(b),int(c),int(d)#转换为整数- 遍历每一对匹配成功的特征点:
zip(good_new, good_old):将新 / 旧特征点一一配对;enumerate:同时获取索引i(用于取对应颜色)和点对(new, old);- 提取坐标并转为整数:因为像素坐标是整数,光流计算返回的是浮点数,需转换才能绘制。
python
#在掩模上绘制线段,连接新点和旧点
mask = cv2.line(mask,(a, b),(c, d),color[i].tolist(),2)
cv2.imshow('mask',mask)cv2.line(mask, (a,b), (c,d), color[i].tolist(), 2):在掩膜上绘制轨迹线段;- 参数:
mask:绘制的目标掩膜;(a,b):当前帧特征点坐标(终点);(c,d):基准帧特征点坐标(起点);color[i].tolist():取第i个随机颜色(转列表,适配 OpenCV 的颜色格式);2:线段宽度为 2 像素;
- 注意:
mask会持续累积所有轨迹,所以能看到特征点的完整运动路径; cv2.imshow('mask',mask):单独展示掩膜(纯轨迹),方便调试。
- 参数:
python
#将掩模添加到当前帧上,生成最终图像
img = cv2.add(frame, mask)
# 显示结果图像
cv2.imshow('frame', img)cv2.add(frame, mask):将原始帧和轨迹掩膜叠加(像素值相加),轨迹会覆盖在原始画面上;- 展示叠加后的结果,能直观看到物体运动轨迹。
python
#等待150ms,检测是否按下了Esc键(键码为27)#
k = cv2.waitKey(150)
if k == 27:#按下Esc键,退出循环
breakcv2.waitKey(150):等待 150 毫秒(控制视频播放速度,约 6 帧 / 秒),返回按下的按键码;- 按下 ESC 键(码值 27),跳出循环,结束程序。
python
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2) #重新整理特征点为适合下次计算的形状 (38,2)-->(38,1,2)- 更新基准帧和特征点,为下一帧跟踪做准备:
old_gray = frame_gray.copy():将当前帧灰度图设为新的基准帧;good_new.reshape(-1,1,2):将good_new(形状(M,2))重塑为(M,1,2),匹配cv2.calcOpticalFlowPyrLK要求的输入形状;-1:自动计算维度,保证总元素数不变。
python
cap.releaseO
cv2.destroyAllWindows()- 代码笔误修正 :
cap.releaseO应为cap.release(); cap.release():释放视频捕获对象的资源;cv2.destroyAllWindows():关闭所有 OpenCV 窗口,避免残留。
-
LK 光流的核心原理:
- 假设:相邻帧之间,特征点的像素值不变(亮度恒定)、运动幅度小;
- 作用:通过求解光学流方程,找到特征点在相邻帧中的对应位置,实现运动跟踪;
- 金字塔优化:将图像分层(金字塔),先在低分辨率层跟踪大运动,再在高分辨率层精细调整,解决 "大位移跟踪失败" 的问题。
-
掩膜绘制轨迹的优势:
- 掩膜独立存储轨迹,不会破坏原始帧;
- 掩膜持续累积线段,能保留完整的运动轨迹(而非只显示单帧的位移)。
-
常见问题与优化:
- 轨迹消失 / 混乱:可增大
winSize(如 21×21)、降低qualityLevel(如 0.2),或定期重新检测特征点; - 特征点过少:减小
qualityLevel、增大maxCorners; - 视频卡顿:减小
winSize、降低金字塔层数,或减少特征点数量。
- 轨迹消失 / 混乱:可增大
总结
- 这段代码的核心是Shi-Tomasi 角点检测 + LK 金字塔光流跟踪 + 掩膜轨迹绘制,实现视频特征点的运动轨迹可视化;
cv2.calcOpticalFlowPyrLK()是光流跟踪的核心函数,st == 1筛选有效特征点是保证跟踪准确性的关键;- 轨迹绘制的核心逻辑是:用掩膜累积绘制特征点的位移线段,再叠加到原始帧上,实现轨迹可视化。