线程栈
在Linux系统中,没有很明确的线程的概念,只有轻量级进程的概念,所以操作系统给我们提供的系统调用,并不能够直接给我们创建线程,只能给我们创建轻量级进程。这个系统调用接口就是clone。

-
fn指定子任务的执行入口函数。新创建的任务会从该函数开始运行,函数返回时子任务结束。简而言之就是你要让创建的新线程执行什么函数,就将哪个函数的地址填入到这里即可
-
child_stack指向子任务使用的栈空间。由于 Linux 栈向低地址增长,该参数通常指向栈空间的高地址。
所以这个系统调用要求我们必须手动的为子任务分配栈空间,这是相当危险的,而我们的pthread库中提供的方法在底层都是封装了这个系统调用接口。所以我们就不需要直接使用这个系统调用接口,只需要使用pthread库给我们提供的默认的方法即可,这样就可以避免让像我这样的手残党去手动分配栈空间,增大了容错率。
-
flags用于指定子任务与父任务共享的资源类型,是
clone的核心参数。通过不同标志位组合,可以创建进程或线程。 -
arg传递给子任务入口函数的参数,用于初始化子任务的运行环境。
现在我们都清楚pthread就是一个用户态的第三方库,那么我们在程序中要使用这个第三方库是如何使用的呢?没错就是动态链接的方式加载pthread库,就和我们之前动态库制作的那篇博客是一样的,这个pthread就是通过页表建立虚拟地址到物理地址的映射关系,这样我们就可以在我们的程序中正常调用pthread库给我们提供的接口函数,又因为pthread是一个共享库,所以他就会被加载到进程虚拟地址空间的共享区。
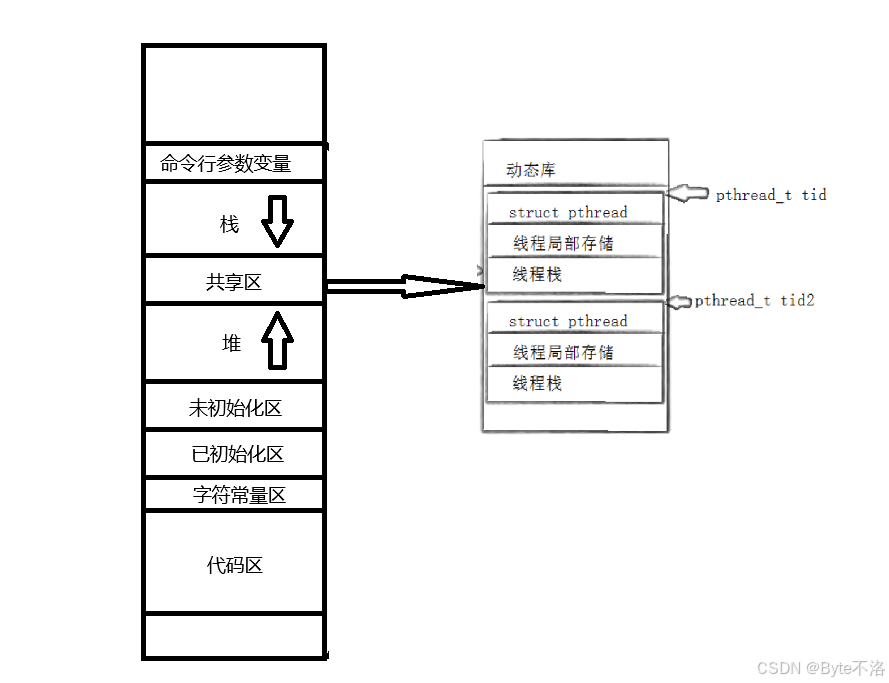
除了主线程之外,主线程创建的其他线程都需要独立的栈空间,因为我们在给线程分配任务的时候,在这个线程栈中可以保存函数调用过程中的局部变量,返回值地址以及临时的数据,要是所有创建的新线程都共享同一个栈空间,很容易就会造成数据覆盖等问题,所以线程栈是线程私有的资源,而其他代码区,数据区以及堆空间都是共享的,而这个pthread库维护的这个线程栈最后会通过系统调用clone中的第二个函数参数child_stack传递给内核,这样我们就可以成功创建线程,也保证了线程栈的独立性,又因为pthread在用户态中帮助我们维护了线程栈,并且最后通过系统调用帮助线程申请栈空间,所以线程栈的位置于pthread共享区映射的区域在虚拟地址空间上相邻,因此常常理解为共享区。
现在我们就来见一见一个简单的多线程的程序。
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <string>
#include <vector>
struct threadDate
{
std::string threadname;
};
void *threadRoutine(void *args)
{
threadDate *td = (threadDate *)args;
int count = 5;
while (count--)
{
printf("pid:%d, tid:%lx, threadname:%s\n", getpid(), pthread_self(), td->threadname.c_str());
sleep(1);
}
return nullptr;
}
int main()
{
std::vector<pthread_t> tids;
for (int i = 0; i < 5; i++)
{
pthread_t tid;
threadDate *td = new threadDate;
td->threadname = "thread-" + std::to_string(i);
pthread_create(&tid, nullptr, threadRoutine, td);
tids.push_back(tid);
}
for (int i = 0; i < 5; i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}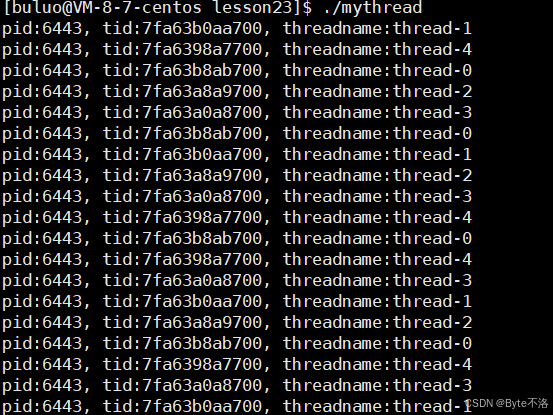
可以看到,通过这样的方式我们就创建了一批多线程,现在我们就通过这个代码来验证一下是否每一个线程都有一个独立的栈结构。
void *threadRoutine(void *args)
{
int test = 1;
threadDate *td = (threadDate *)args;
int count = 5;
while (count--)
{
printf("pid:%d, tid:%lx, threadname:%s, test:%d , &test:%p\n", getpid(), pthread_self(), td->threadname.c_str(), test, &test);
test++;
sleep(1);
}
return nullptr;
}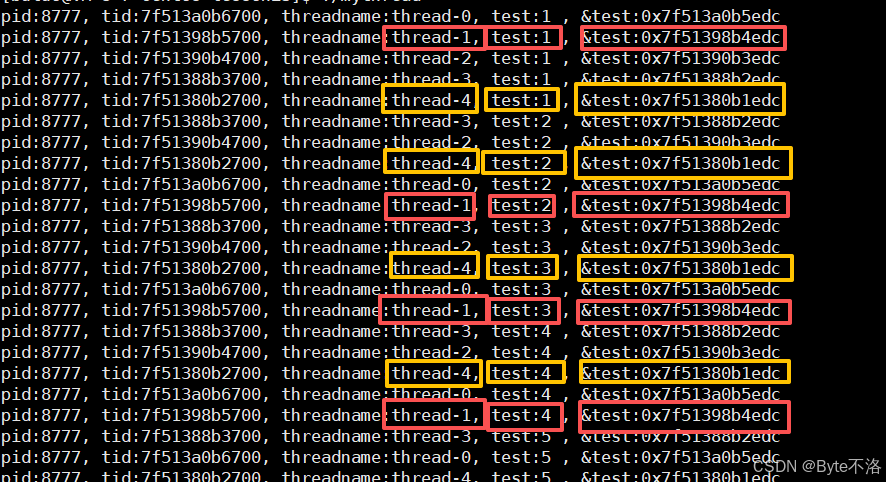
可以看到我们在线程执行的函数中创建了一个局部变量test,从结果中我们可以看到,每一个线程中的局部变量test都是从1开始的,并且每一个test的地址都是不一样的,所以这就证明了每一个线程都有一个独立的线程栈,线程栈是互不干扰的。
现在我们再来验证一下对于全局数据,每一个线程都是可以访问,并且全局数据对每一个线程都是共享的。
int value = 10;
void *threadRoutine(void *args)
{
threadDate *td = (threadDate *)args;
int count = 5;
while (count--)
{
printf("pid:%d, tid:%lx, threadname:%s, value:%d , &value:%p\n", getpid(), pthread_self(), td->threadname.c_str(), value, &value);
sleep(1);
}
return nullptr;
}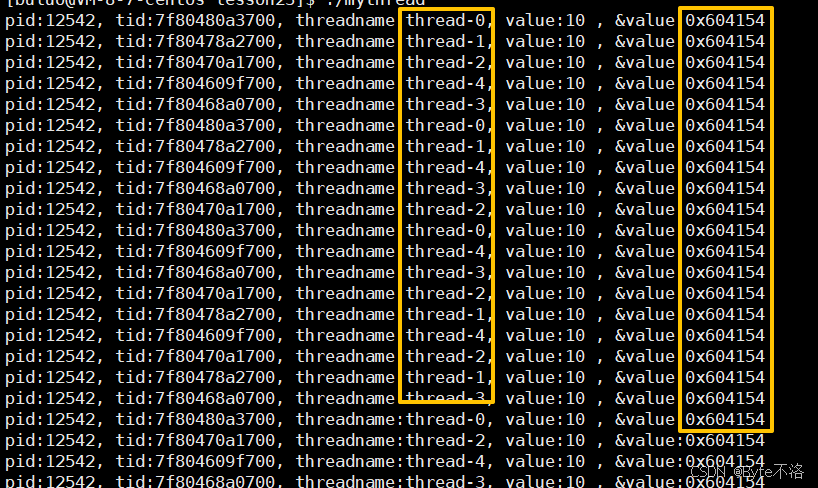
可以看到每一个线程都可以访问到这个全局变量value,并且可以看到每一个线程访问的value都是同一个地址,现在我们就了解了,对于全局数据区的数据,对每一个线程都是共享的。
但是现在有有一个问题就是如果我定义一个局部变量,这个局部变量的生命周期只在函数的作用域内,生命周期太短了,但是定义一个全局变量,所有的线程都会和我共享这个全局变量,那么有没有一种既是全局的,又独属于线程的变量呢?这个就是__thread,__thread 是 GCC 提供的线程局部存储机制,每个线程拥有独立的变量副本,这样就使全局变量在线程间互不干扰。只需要在定义全局变量前加__thread即可。
__thread int value = 10;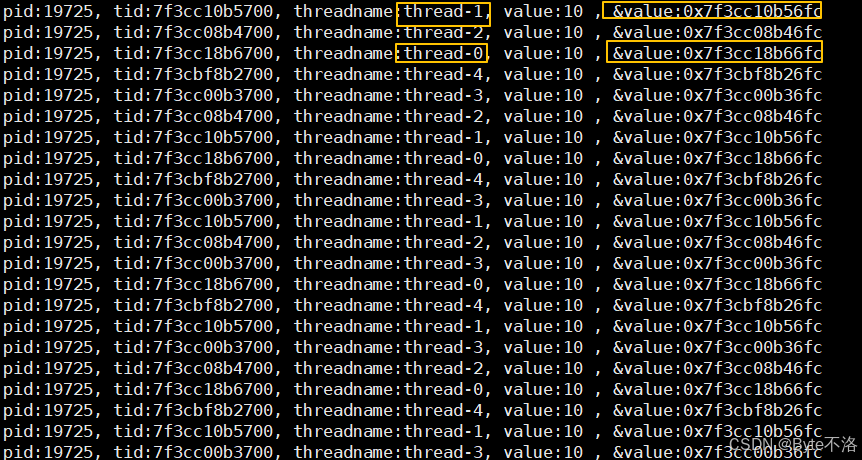
这样我们明显可以看到,在全局变量前加__thread之后,每个线程的都拥有了一个独属于自己的全局变量,这个全局变量只属于自己。这样就实现了在全局数据区也有独属于自己的一个数据。
线程分离
现在有一个问题就是当我们创建新的线程之后,我们的主线程就需要调用pthread_join函数调用进行阻塞式等待创建的新的线程结束,这样就会导致我们的主线程无法正常的工作,毕竟我们需要让主线程回收新线程的退出结果,那么有没有那么一种情况就是我创建新线程之后,我根本不关心它的退出结果,只要它完成任务之后,自动释放线程资源就好了,这样我们的主线程就可以继续往下执行了?当然是有的,这个就是线程分离。
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <string>
#include <vector>
struct threadDate
{
std::string threadname;
};
__thread int value = 10;
void *threadRoutine(void *args)
{
pthread_detach(pthread_self());
threadDate *td = (threadDate *)args;
int count = 5;
while (count--)
{
printf("pid:%d, tid:%lx, threadname:%s, value:%d , &value:%p\n", getpid(), pthread_self(), td->threadname.c_str(), value, &value);
sleep(1);
}
return nullptr;
}
int main()
{
std::vector<pthread_t> tids;
for (int i = 0; i < 3; i++)
{
pthread_t tid;
threadDate *td = new threadDate;
td->threadname = "thread-" + std::to_string(i);
pthread_create(&tid, nullptr, threadRoutine, td);
tids.push_back(tid);
}
for (int i = 0; i < 3; i++)
{
int n = pthread_join(tids[i], nullptr);
if (n == 0)
{
printf("pthread wait success\n");
}
else
{
printf("pthread wait failed\n");
}
}
return 0;
}
可以看到,由于我们对每一个线程都进行了分离,然后主线程就不需要再等待新线程,只需要执行自己的任务即可,所以当我们的主线程执行结束之后,我们的整个程序也就终止了,所以我们也就等不到创建的新线程结束,所以我们进行线程分离的时候,也是要保证主线程在新线程之后退出,不然我们就等不到新线程运行结束了。这就是线程分离。
线程的互斥
大部分情况下,线程使用的数据都属局部变量,变量的地址在线程栈空间,其他线程是很难获取到这种变量的,但是有时候,很多变量都需要线程间共享,虽然通过共享,可以很简单的完成线程间的交互,但是当多个线程并发操作的时候,难免就会带来一些问题,有什么问题呢?我们现在通过一个简单的多线程抢票的程序,来看看会出现什么问题。
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <string>
#include <vector>
int tickets = 100;
class threadDate
{
public:
threadDate(int num)
{
threadname = "thread-" + std::to_string(num);
}
public:
std::string threadname;
};
void *getTicket(void *args)
{
threadDate *td = (threadDate *)args;
while (1)
{
if (tickets > 0)
{
usleep(1000);
printf("%s get a tickets , tickets : %d\n", td->threadname.c_str(), tickets);
tickets--;
}
else
{
break;
}
}
return nullptr;
}
int main()
{
std::vector<pthread_t> tids;
std::vector<threadDate *> thread_datas;
for (int i = 1; i <= 3; i++)
{
pthread_t tid;
threadDate *td = new threadDate(i);
thread_datas.push_back(td);
pthread_create(&tid, nullptr, getTicket, td);
tids.push_back(tid);
}
for (int i = 0; i < 3; i++)
{
pthread_join(tids[i], nullptr);
}
for(auto thread : thread_datas)
{
delete thread;
}
return 0;
}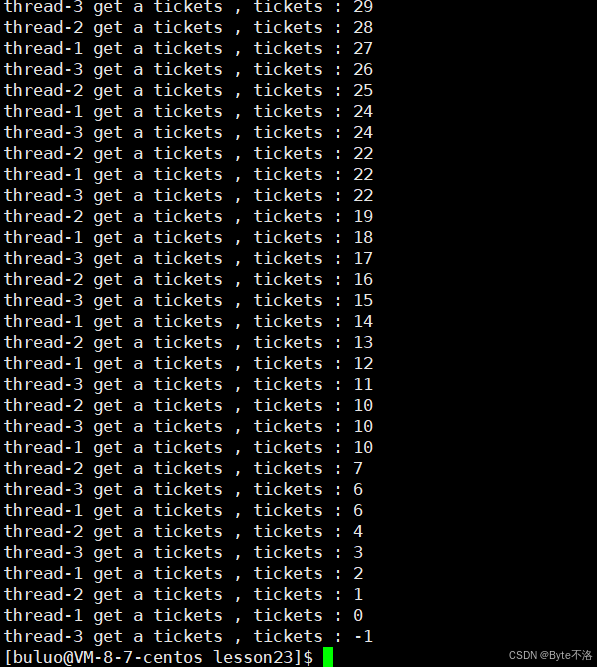
现在我们看到奇怪的情况就是,我们明明在线程的任务中设置当tickets的值为0时就退出,但是现在竟然出现了tickets的值变为-1的情况,并且我们可以看到不同的线程却可以抢到同一张票,这是怎么回事,这其实就是多线程中共享变量的弊端,因为在多线程中对一个共享变量进行++/--的操作是不安全的,因为对一个数进行减一的操作分为以下步骤:
将这个数从内存中取出并放到CPU中的寄存器中。
然后在将寄存器中的这个数通过ALU进行减一。
最后将这个数再放回到内存中。
用汇编语言表示tickets--这一条语句就被分为:
mov eax, x
add eax, 1
mov x, eax
换言之就是一条语句的执行会被分为三部分,因此假如现在有一个线程正在运行,tickets的值为100,并且刚刚将tickets保存到CPU中的寄存器之后,由于线程发生切换,这个时候线程就将自己的上下文数据保存到task_struct中,然后换连一个线程上CPU继续运行,而这个线程完整的执行完这三部,成功将tickets的值改为了99,并保存到内存中,这个时候又发生了线程切换,再次将之前的线程切换到CPU之后,线程将自己task_struct中保存的线程上下文数据恢复到CPU上,这个时候寄存器依旧保存的值是100,继续往下执行后,又将这个值减99,再次保存到内存中,这就是为什么上面我们看到多个线程抢到了同一张票,那为什么最后这个值会变为-1呢?其实也很好理解,当ticket的值为1时,我们在执行tickets是否大于0的时候,一个进程刚刚判断完tickets的值为1,可以进入这个判断语句之后,发生了线程切换,另一个线程切换上来之后,依旧判断tickets的值为1,当这个线程执行完tickets--之后,将这个tickets的值改为0,另一个线程再次被切换之后,这个线程又再次执行了tickets--,所以这个时候tickets的值就变为了-1,这就是多线程对共享数据访问时的弊端。
那么我们应该如何解决这些情况的发生呢?
这就要求我们必须做到对共享数据进行访问的时候,必须保证只有一个执行流进行访问。也就是保证一个线程在执行tickets--的时候,另外的线程只有等待,等待这个线程执行结束之后,其它的线程才可以对其进行访问,这个办法就是------加锁。
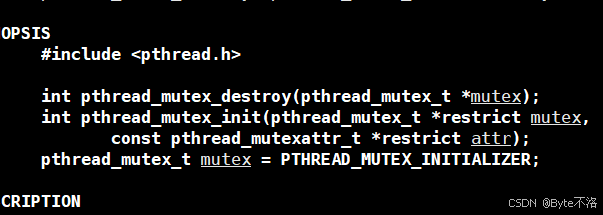
我们先来看看pthread库给我们提供的函数调用接口,然后利用函数调用接口成功解决上面的问题。
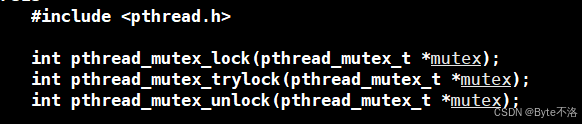
pthread_mutex_init
用于初始化一个互斥锁,在使用互斥锁之前必须先调用该函数。
-
mutex :用于保存初始化后的互斥锁对象,传入一个
pthread_mutex_t变量的地址即可 -
attr :互斥锁的属性参数,大多数情况下直接传
NULL,表示使用默认属性
pthread_mutex_lock
用于加锁,当多个线程竞争同一把互斥锁时,只有一个线程可以成功获得锁,其余线程会被阻塞。
- 如果没有线程获取锁,调用该函数的线程可以立即获得锁
- 如果这个锁已经被其他线程获取,那么再次调用该函数的线程就会被阻塞,知道锁被释放。
pthread_mutex_unlock
用于解锁,释放当前线程持有的互斥锁,使其他阻塞线程有机会继续执行。
-
这个函数只有获取到锁的线程可以调用
-
解锁之后,因为等待锁而被阻塞的线程中有一个会被唤醒。
pthread_mutex_destroy
用于销毁互斥锁,释放与互斥锁相关的系统资源。
void *getTicket(void *args)
{
threadDate *td = (threadDate *)args;
while (1)
{
if (tickets > 0)
{
usleep(1000);
printf("%s get a tickets , tickets : %d\n", td->threadname.c_str(), tickets);
tickets--;
}
else
{
break;
}
}
return nullptr;
}那么现在我们需不需要将这个函数整个都加上锁呢,其实是不需要的,因为在这个函数中不是每一个部分都是共享资源,另外从实质上讲,加锁其实就是用时间换安全的手段,这是什么意思呢?这是因为我们的线程是并发访问的,而并发访问就很容易造成上面这种数据不一致的现象,所以为了安全,我们必须让线程在访问共享资源时进行串行访问(也就是执行临界区的代码时串行执行),也就是每次只允许一个线程进行tickets>0的判断和tickets--的操作,这样就保证了线程不会出现数据不一致的线程,但是这样就会导致线程的执行速率有所下降,所以加锁其实就是用时间换安全,所以为了尽可能的降低效率的减少,我们需要尽可能的缩小加锁的范围,因此我们的临界区域要尽可能的小。
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <string>
#include <vector>
int tickets = 100;
class threadDate
{
public:
threadDate(int num, pthread_mutex_t *mutex)
: mutex_(mutex)
{
threadname = "thread-" + std::to_string(num);
}
public:
std::string threadname;
pthread_mutex_t *mutex_;
};
void *getTicket(void *args)
{
threadDate *td = (threadDate *)args;
while (1)
{
pthread_mutex_lock(td->mutex_);
if (tickets > 0)
{
usleep(1000);
printf("%s get a tickets , tickets : %d\n", td->threadname.c_str(), tickets);
tickets--;
pthread_mutex_unlock(td->mutex_);
}
else
{
pthread_mutex_unlock(td->mutex_);
break;
}
}
return nullptr;
}
int main()
{
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
std::vector<pthread_t> tids;
std::vector<threadDate *> thread_datas;
for (int i = 1; i <= 3; i++)
{
pthread_t tid;
threadDate *td = new threadDate(i, &mutex);
thread_datas.push_back(td);
pthread_create(&tid, nullptr, getTicket, td);
tids.push_back(tid);
}
for (int i = 0; i < 3; i++)
{
pthread_join(tids[i], nullptr);
}
for (auto thread : thread_datas)
{
delete thread;
}
return 0;
}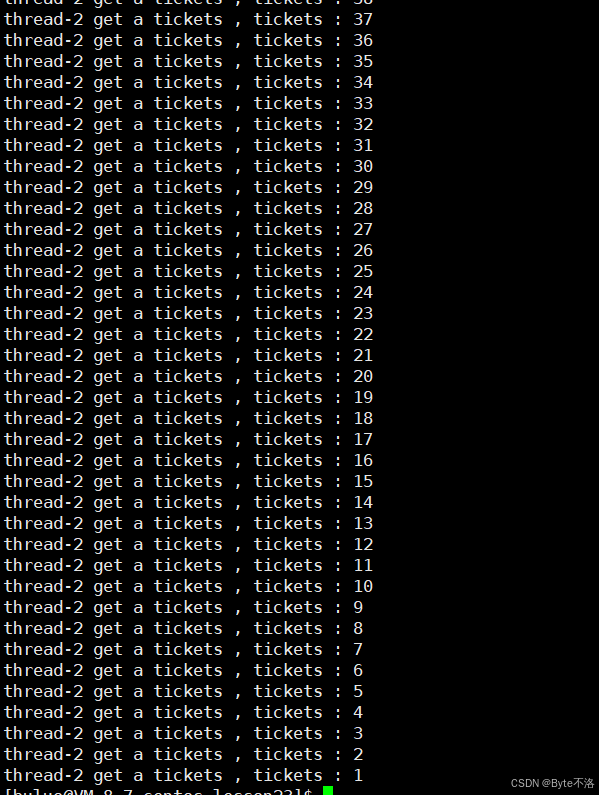
现在可以看到加锁之后,我们的程序终于得到了正确的结果,不再出现票数变为0的情况。但是仔细的同学可能就发现一个问题了,就是这所有的票都被一个线程抢走了,都没有其他线程的事,这是怎么回事呢?其实这是因为线程对锁的竞争能力不同,在这句话的意思其实很好理解,现在CPU上正在运行一个线程,这个线程释放了锁之后,由于这个线程的时间片还没有到,这个线程又继续执行,当它继续执行的时候,其它的线程还处于挂起状态,而这个线程处于运行态,并且又再次申请锁,因此锁又被这个线程拿到了,这样就导致这个线程刚释放锁资源之后又占用了锁,所以其它的线程根本就拿不到锁,也就进入不了临界区,所以会出现上面这种一个线程拿走所有票的情况。
给大家列举一个简单的例子帮助大家理解一下,小时候大家家里估计只有一台电脑,经常就是一堆人抢着玩电脑,那个时候经常玩的一款游戏就是侠盗飞车,一个人抢到这台电脑的时候,剩下的所有人都围着这台电脑,都在等待着这个人离开时候,我好接手继续玩,现在抢到这个电脑的人一直从早上的7点玩到10点了,这个时候他突然想出去上个厕所解个手,刚准备站起离开的时候,看到周围好几个人都在围着他,等待他离开之后他们好接手,看到这样的场景,你心头一想这么多人都在抢这台电脑,这要是我出去上个厕所,回来之后我得等多久才能继续玩上游戏,于是你默默忍着尿意,又悄悄的坐下继续玩,又过了3小时之后,又想上厕所了,但是同样的想法,一旦离开就玩不上了,由于你当前离电脑最近,所以你又坐下继续玩,来来回回,知道最后家长过来关掉电脑让我们睡觉,这样才结束。
玩电脑的这个人就是正在运行的线程,而旁边等待玩电脑的人就是其它阻塞的线程,电脑就是锁,当正在运行的线程释放锁,也就是玩电脑的人想要离开了,但是由于这个线程正在运行,他再次申请锁获得的概念最大,也就是玩电脑的这个人离的最近,所以他想要继续玩游戏很容易,所以这就导致其它的线程一直得不到锁资源,也就是等待玩电脑的人一直玩不到电脑,这就会导致这些线程形成饥饿现象。
所以这种情况一看就是不对的,理应就是当这个正在运行的线程释放锁之后,不能够重新申请锁,必须排到队列的尾部。并且让所有的线程获取锁时,按照一定的顺序进行获取,这也就是------同步。
现在还有一个问题就是当所有的线程都进行申请锁的时候,这个时候锁也就成为了共享资源,那么如何保证线程访问锁时,锁处于安全呢?这个其实很简单就是在我们申请锁和释放锁的操作时将其设置为原子性操作即可,那么这个锁到底是怎么实现的呢?我们接着往下看。
锁的原理
经过上面的例子,我们现在已经明白了我们在编辑器中写的每一条代码,其实在底层都会被分解为几条机器指令,而我们得CPU在执行机器指令得时候就是原子性的,就是这条机器指令要么就不执行,要执行就一定会执行完毕。因此为了实现锁,大多数的CPU架构提供了swap或exchange指令,该该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性。下图是lock和unlock的伪代码:

加锁和解锁就是通过这样的操作保证原子性的,现在我们将mutex的值认为是1,加锁时将ax寄存器中的值初始化为0,然后将ax寄存器的值和内存中mutex的值进行交换,如果ax的寄存器的值大于0,也就是ax寄存器的值和内存中的mutex的值成功交换,也就是成功获得了锁,这个线程就可以进入临界区,当这个ax的寄存器的值不大于0时,表明这个时候已经有线程获取到了这个锁,这个锁就需要被挂起,那么这个时候就有人问了,这么多操作,这是如何保证原子性的?
假设我们有一个 mutex,初始值为 1。加锁的过程可以理解为:
-
将寄存器(如 x86 中的
AX)初始化为 0; -
将寄存器的值与内存中的
mutex值执行 原子交换; -
判断寄存器的值:
-
如果大于 0,表示交换成功,线程获取到锁,可以进入临界区;
-
如果不大于 0,说明锁已被其他线程占用,该线程需要被挂起等待。
-
为什么这种方式能保证原子性?
假设有两个线程同时尝试加锁:
-
线程 A 执行到寄存器赋值
AX = 0,然后发生线程切换; -
线程 B 获得 CPU,执行交换操作:
-
将自己的寄存器值(0)与内存中的
mutex(1)交换; -
交换后
AX = 1,mutex = 0; -
由于
AX > 0,线程 B 成功获取锁;
-
-
线程 A 再次获得 CPU,恢复寄存器上下文:
-
执行交换操作时,
AX = 0,mutex = 0; -
交换后寄存器依然为 0,线程 A 判断没有获取锁,需要挂起或自旋。
-
通过这个机制,无论线程切换如何发生,原子交换保证了同一时刻只有一个线程能获取到锁,从而保证了临界区的互斥性。
线程的同步
线程同步就是在保证数据安全的情况下,让我们的线程访问资源时具有一定的顺序性。
这是什么意思呢?就是上面多线程抢票的问题,当正在持有锁的线程执行的时候,等待锁资源的线程必须排队等待,不可以像我们围在一起抢电脑玩一样,谁先抢上就是谁的,线程同步要求等待锁的线程一定是具有顺序性的,这样内核在唤醒等待锁线程中的一个就可以了,而不会将全部的线程都唤醒,因为将全部的线程都唤醒之后,CPU就会白白的浪费,得不偿失,所以锁释放之后,只会唤醒一个等待的线程,用最小的唤醒代价换取最高的并发效率。
那么我们如何将我们上面那种混乱抢票的程序修改为有一定顺序性的访问锁资源呢?这个办法就是条件变量。
这个条件变量会维护一个等待队列,当线程申请一个已经被申请走的锁资源时,这个线程就会调用条件变量中的等待接口,将自己加入到这个等待队列中,此时这个线程就会处于挂起状态。如果持有锁的进程释放锁之后,它会通知条件变量,自己已经将这个锁释放掉了,这个时候,条件变量就会在等待队列中唤醒一个等待的线程,这个时候这个被唤醒的锁再次申请锁时就可以获得该锁,继续向下执行临界代码,通过这种方式,线程不会在锁被占用时无意义地反复竞争,而是通过条件变量进入睡眠状态,提高了系统的整体效率。
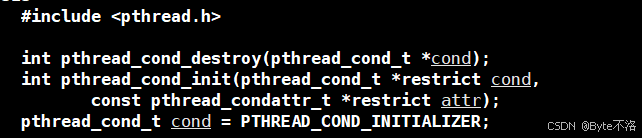


pthread_cond_init
-
cond:指向pthread_cond_t条件变量对象。 -
attr:条件变量属性,一般传nullptr使用默认属性。
pthread_cond_wait
-
线程进入等待队列,挂起自己。
-
释放传入的互斥锁
mutex。 -
当条件变量被唤醒时,线程重新获取
mutex,继续执行。
pthread_cond_signal
唤醒等待在 cond 上的一个线程。
pthread_cond_broadcast
唤醒等待在 cond 上的多个线程。
pthread_cond_destroy
销毁条件变量 cond,释放系统资源。
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <string>
#include <vector>
int tickets = 100;
class threadDate
{
public:
threadDate(int num, pthread_mutex_t *mutex, pthread_cond_t *cond)
: mutex_(mutex), cond_(cond)
{
threadname = "thread-" + std::to_string(num);
}
public:
std::string threadname;
pthread_mutex_t *mutex_;
pthread_cond_t *cond_;
};
void *getTicket(void *args)
{
pthread_detach(pthread_self());
threadDate *td = (threadDate *)args;
while (1)
{
pthread_mutex_lock(td->mutex_);
pthread_cond_wait(td->cond_, td->mutex_);
if (tickets > 0)
{
usleep(1000);
printf("%s get a tickets , tickets : %d\n", td->threadname.c_str(), tickets);
tickets--;
pthread_mutex_unlock(td->mutex_);
}
else
{
pthread_mutex_unlock(td->mutex_);
break;
}
}
return nullptr;
}
int main()
{
pthread_mutex_t mutex;
pthread_cond_t cond;
pthread_mutex_init(&mutex, nullptr);
pthread_cond_init(&cond, nullptr);
std::vector<pthread_t> tids;
std::vector<threadDate *> thread_datas;
for (int i = 1; i <= 3; i++)
{
pthread_t tid;
threadDate *td = new threadDate(i, &mutex, &cond);
thread_datas.push_back(td);
pthread_create(&tid, nullptr, getTicket, td);
tids.push_back(tid);
}
while (1)
{
pthread_cond_signal(&cond);
}
for (auto thread : thread_datas)
{
delete thread;
}
return 0;
}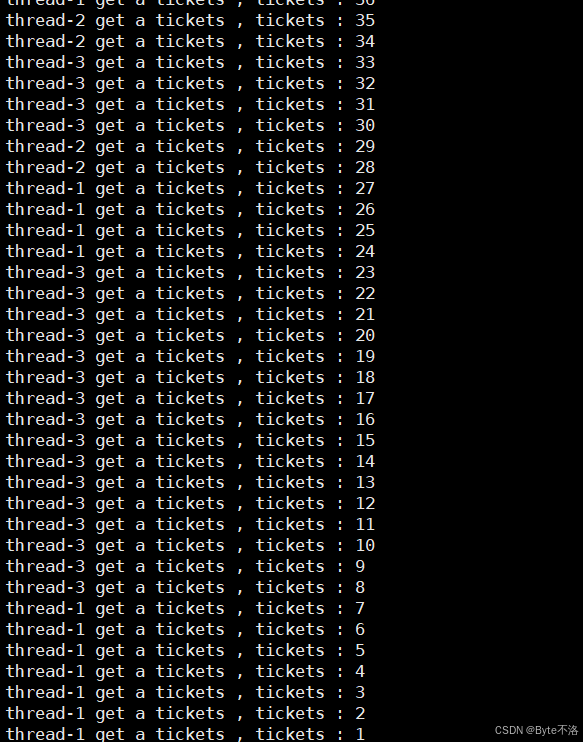
通过这样的方式我们就可以让所有的线程都抢到票,不会让一个线程一直可以抢到票。
但是条件变量的用法并不是这样的(有一定的错误,这是只是让大家看到所有的线程都可以抢到票了),在接下来的一篇博客我们通过生产者消费者模型再来探讨条件变量的正确打开方式。