今天遇到的这个问题很特别,所有的数据都在一列。
开始的时候,我通过python代码实现了把这一列数据通过一行一行的读取,然后按照固定的行数为一条记录,重新保存到新的数组。最后遍历这个新的数组,把每行数据写入新的文件。
python
#coding:utf-8
contents=[]
with open("UOM20260127P1-P60.txt","r",encoding="utf-8") as whole_file:
for line in whole_file.readlines():
contents.append(line)
whole_file.close()
new_contents=[]
one_line = ""
p = 0
for content in contents:
p=p+1
one_line = one_line +";"+ content
one_line = one_line.replace("\n","")
if(p==8):
new_contents.append(one_line)
one_line=""
p=0
with open("new_uom.txt","w",encoding="utf-8") as wfile:
for con in new_contents:
wfile.writelines(con)
wfile.writelines("\n")
wfile.close()如下所示,原始文本与新生成的文本。

新生成的文本,每个字段之间增加了分号分隔符";"这个数据导入到excel就很方便了。
在这种方式实现一列转多行之后,我觉着excel本身应该也有办法,只不过我们不知道而已,结果这个办法还真让我找到了。下面就是详细的过程。
1、所有数据复制到excel,就是一列数据。
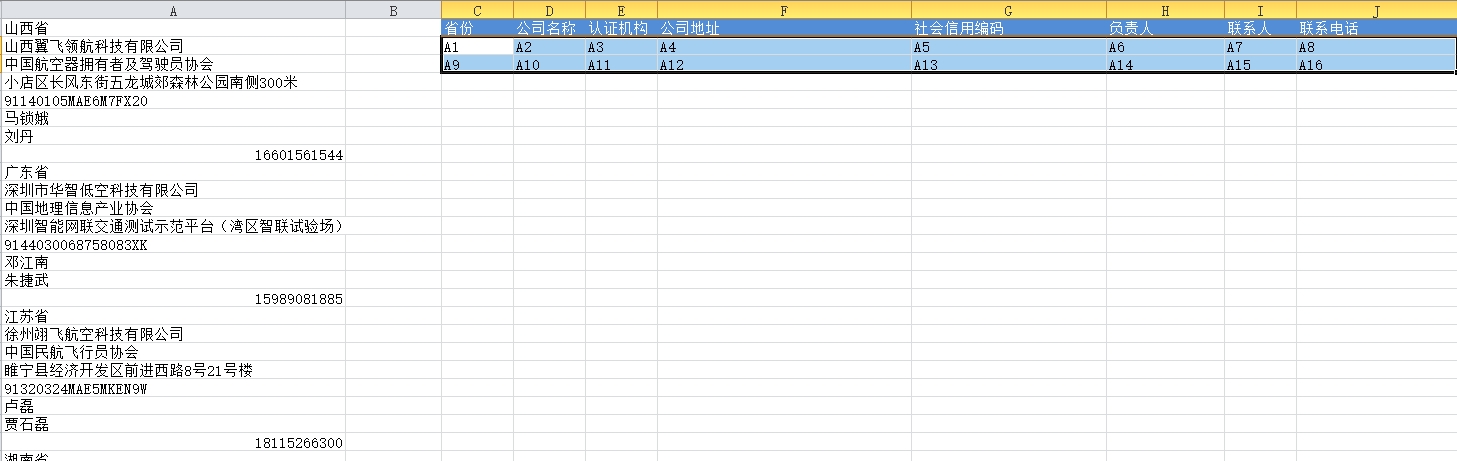
2、在当前工作簿制作一个新的表格,然后按照数据的排列结构,通过指定列值的方式把这个表格填满。
手动输入两列之后,可以通过鼠标拉取的方式,将整个表格全部填满。
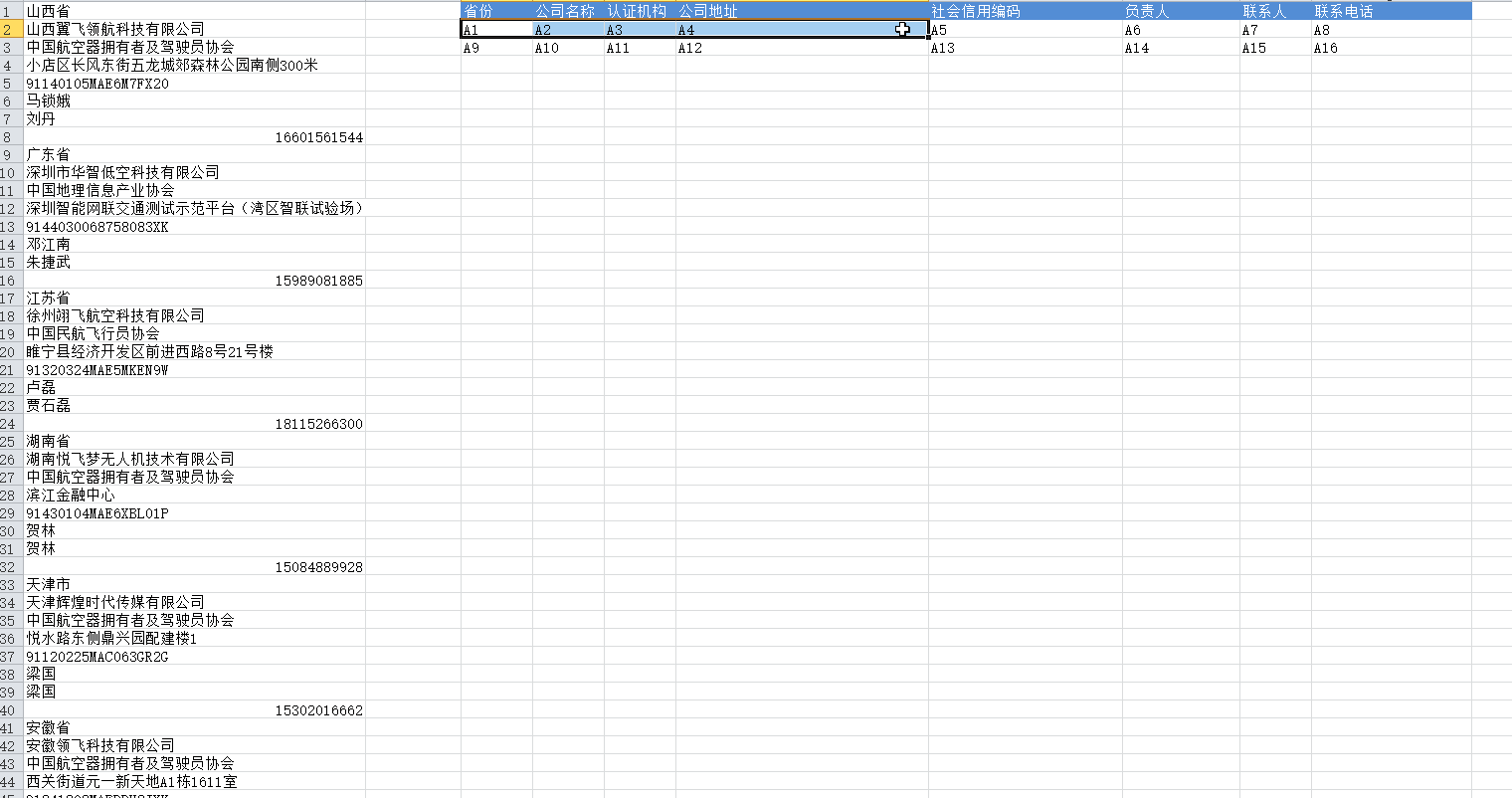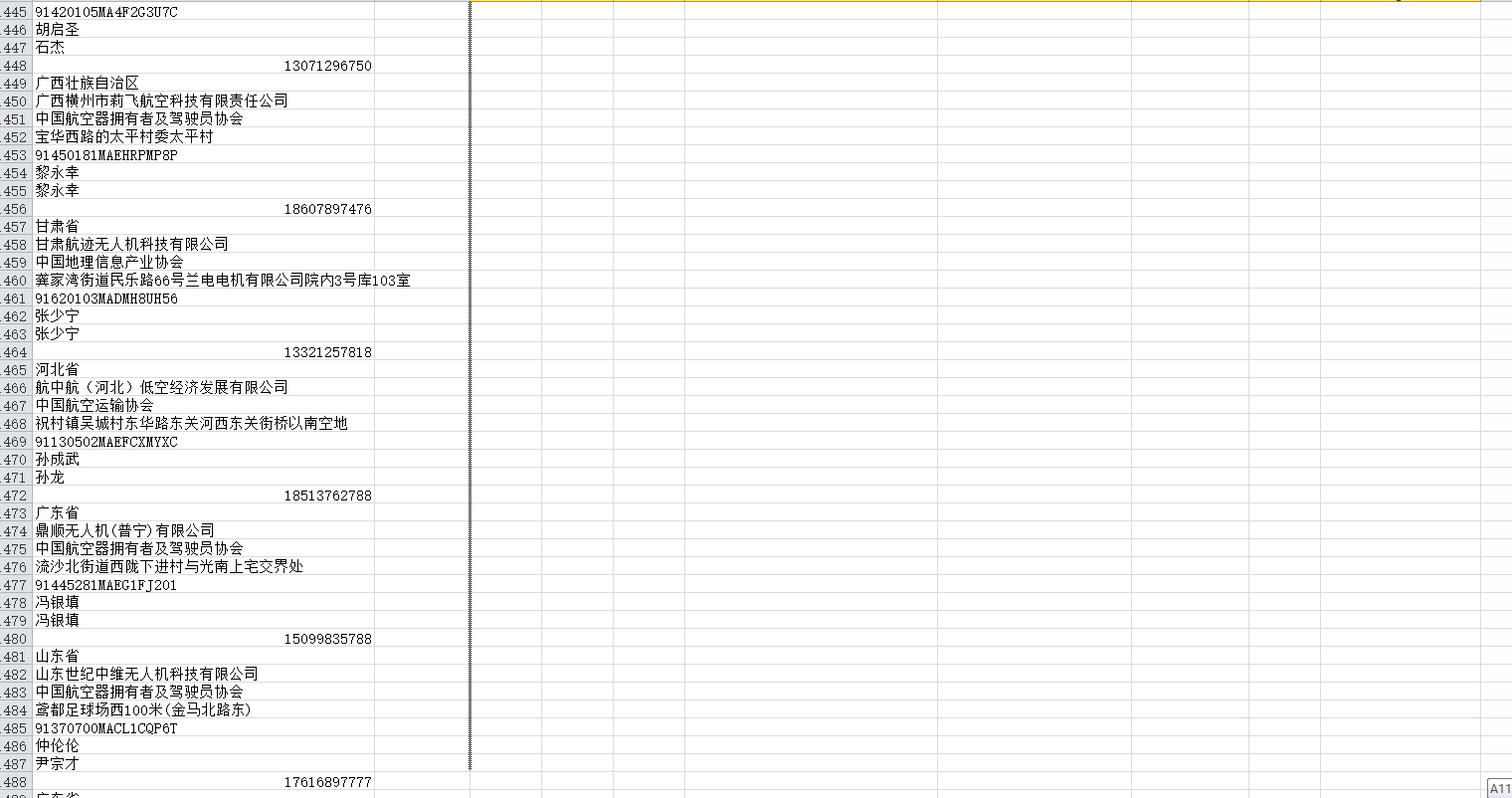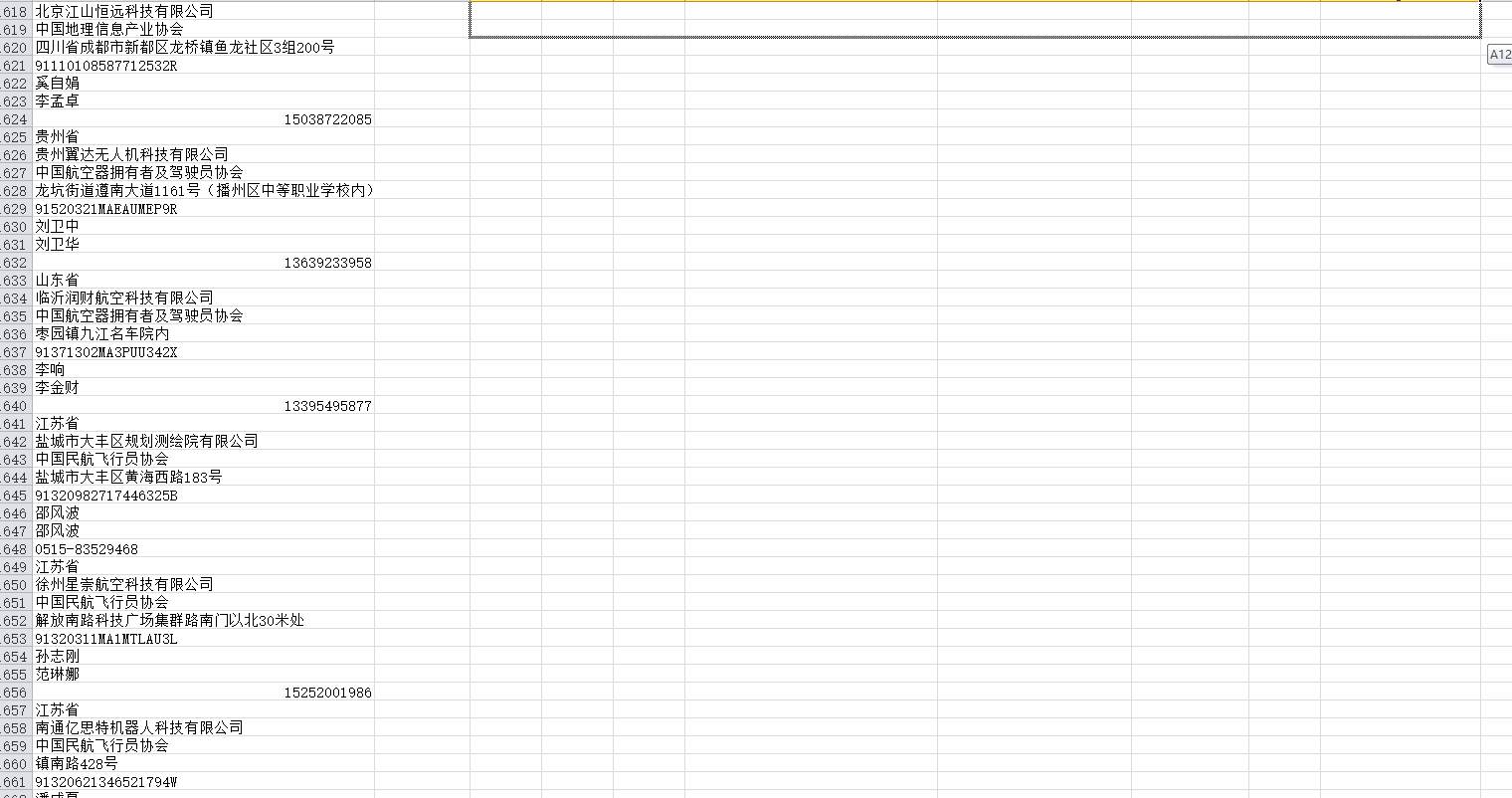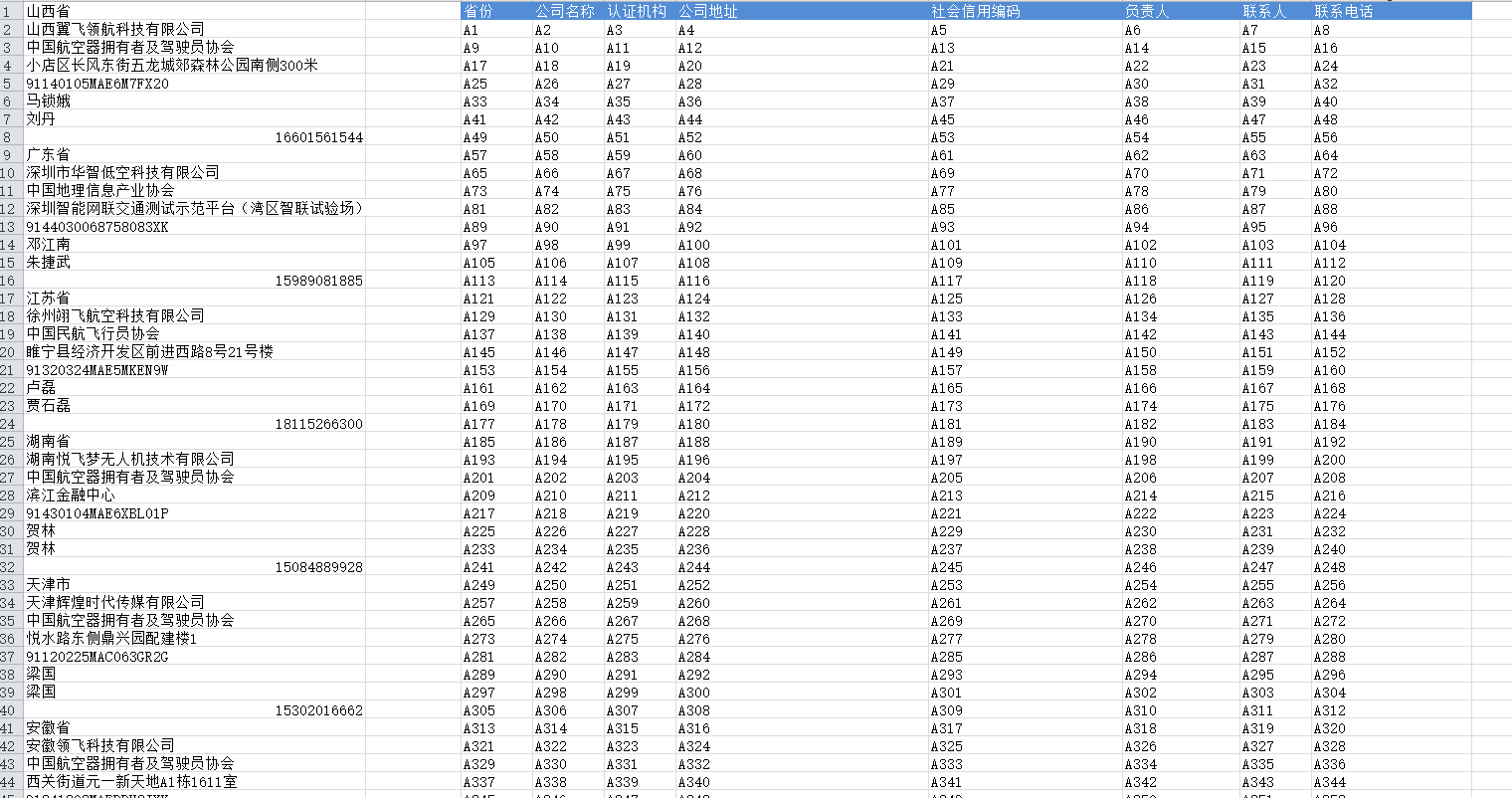
这里可以多拉取一些行,以覆盖所有数据。
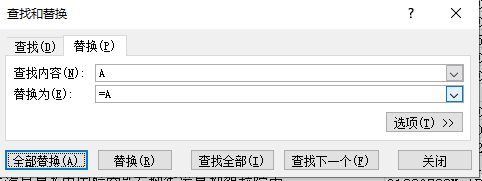
3、替换表格列值。
点击某一个单元格,选择替换。在替换对话框中将"查找内容"和"替换为"分别输入A和=A,如下所示:
然后点击全部替换,结果如下所示:
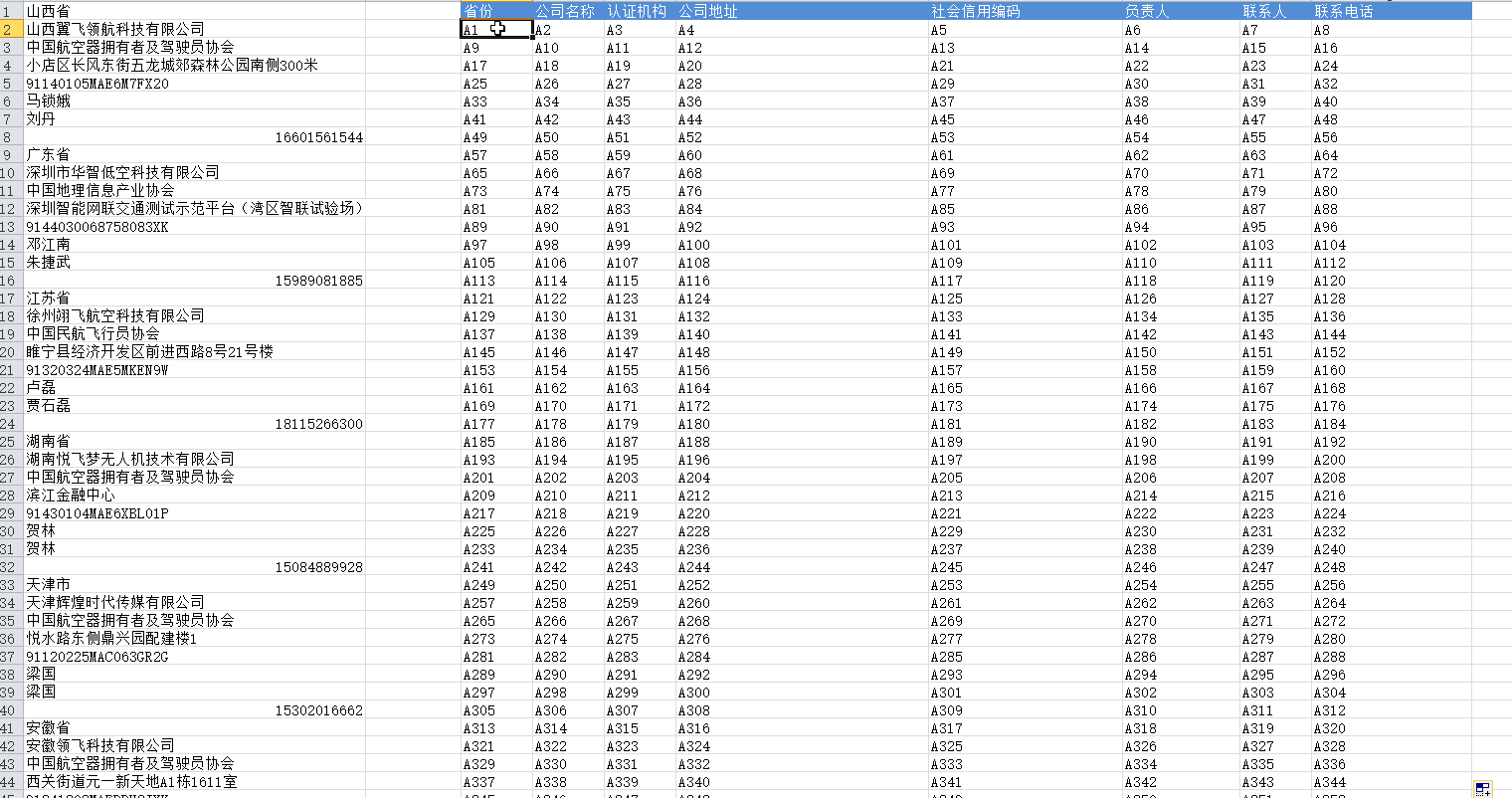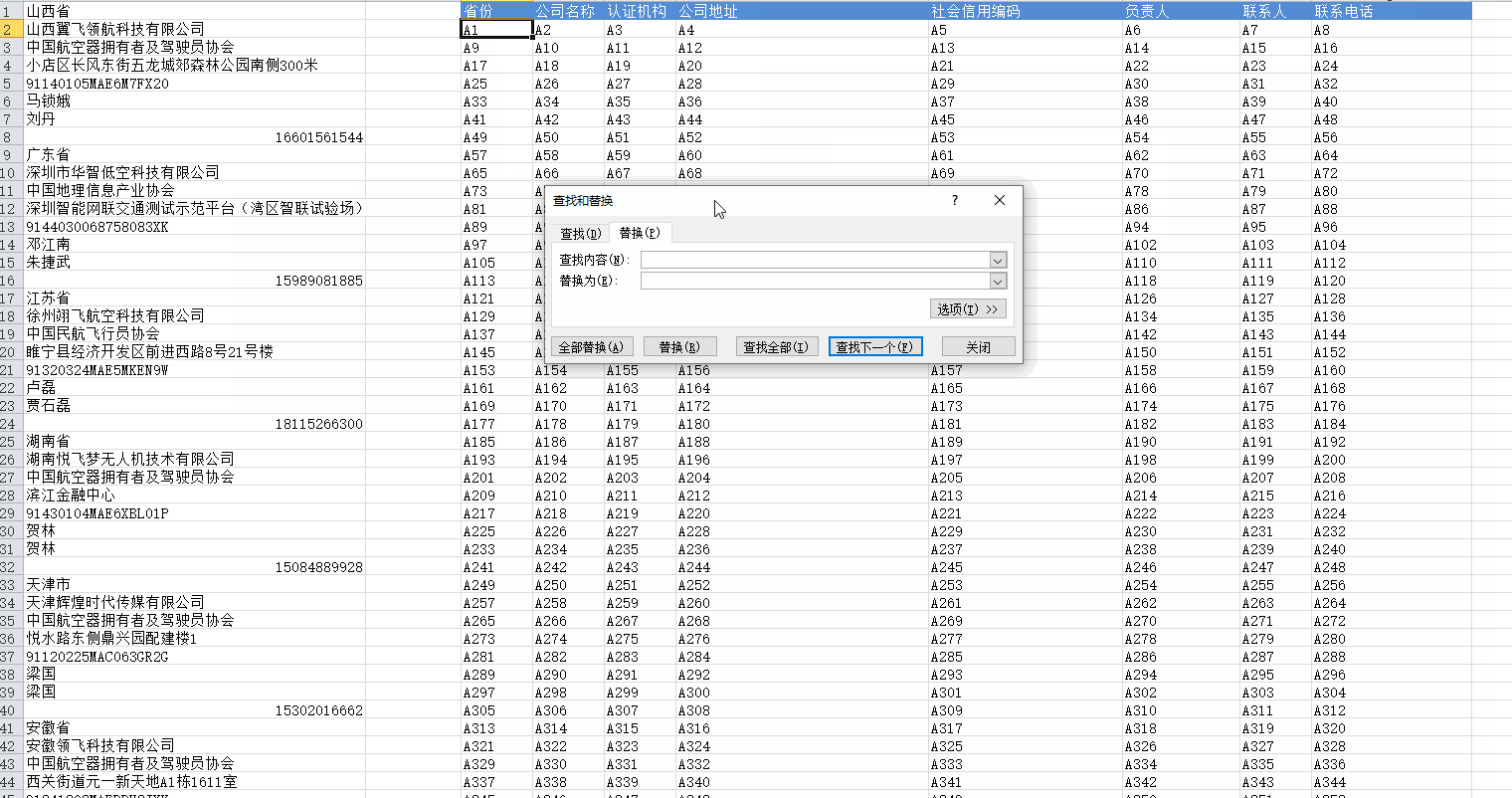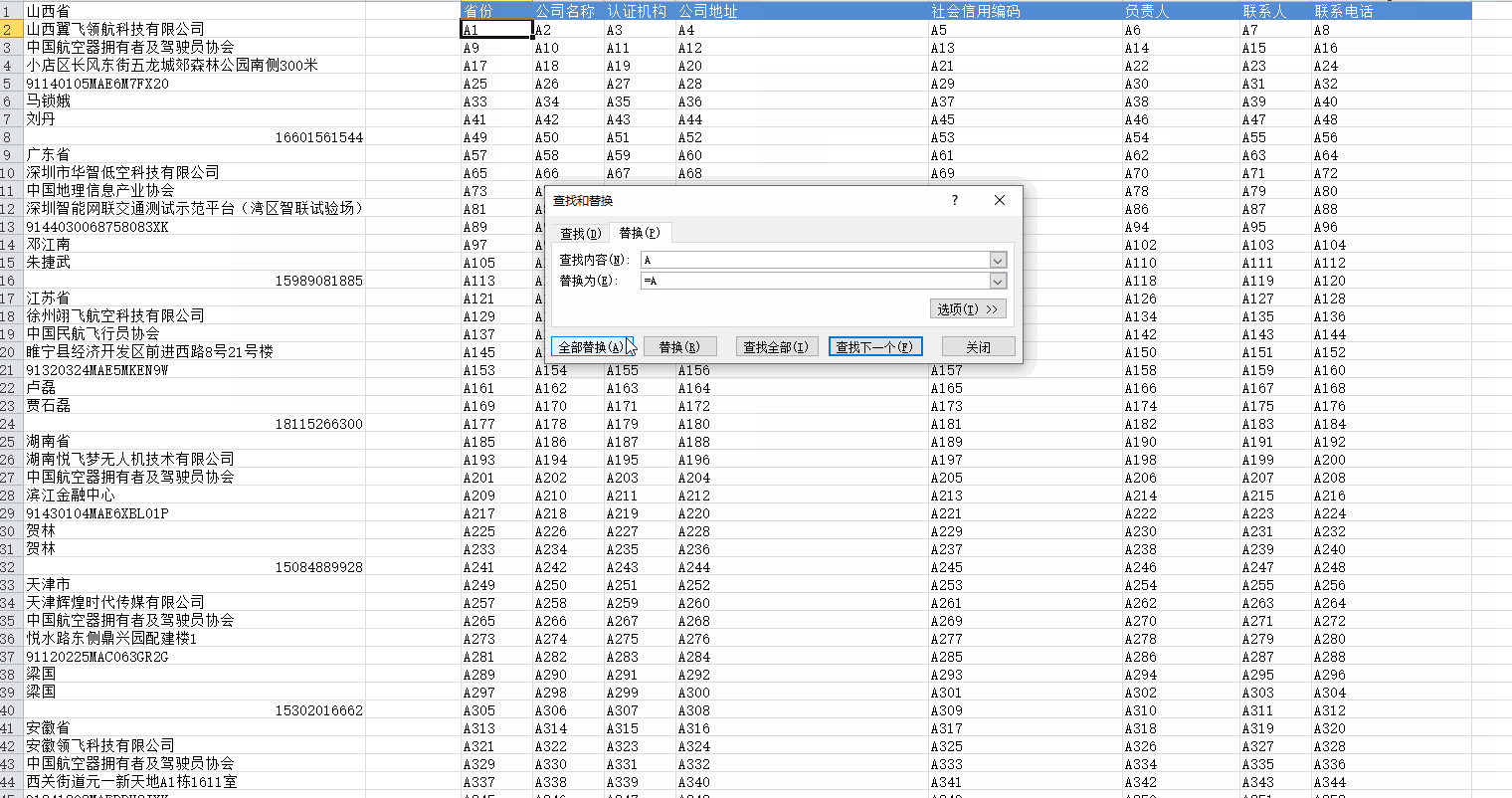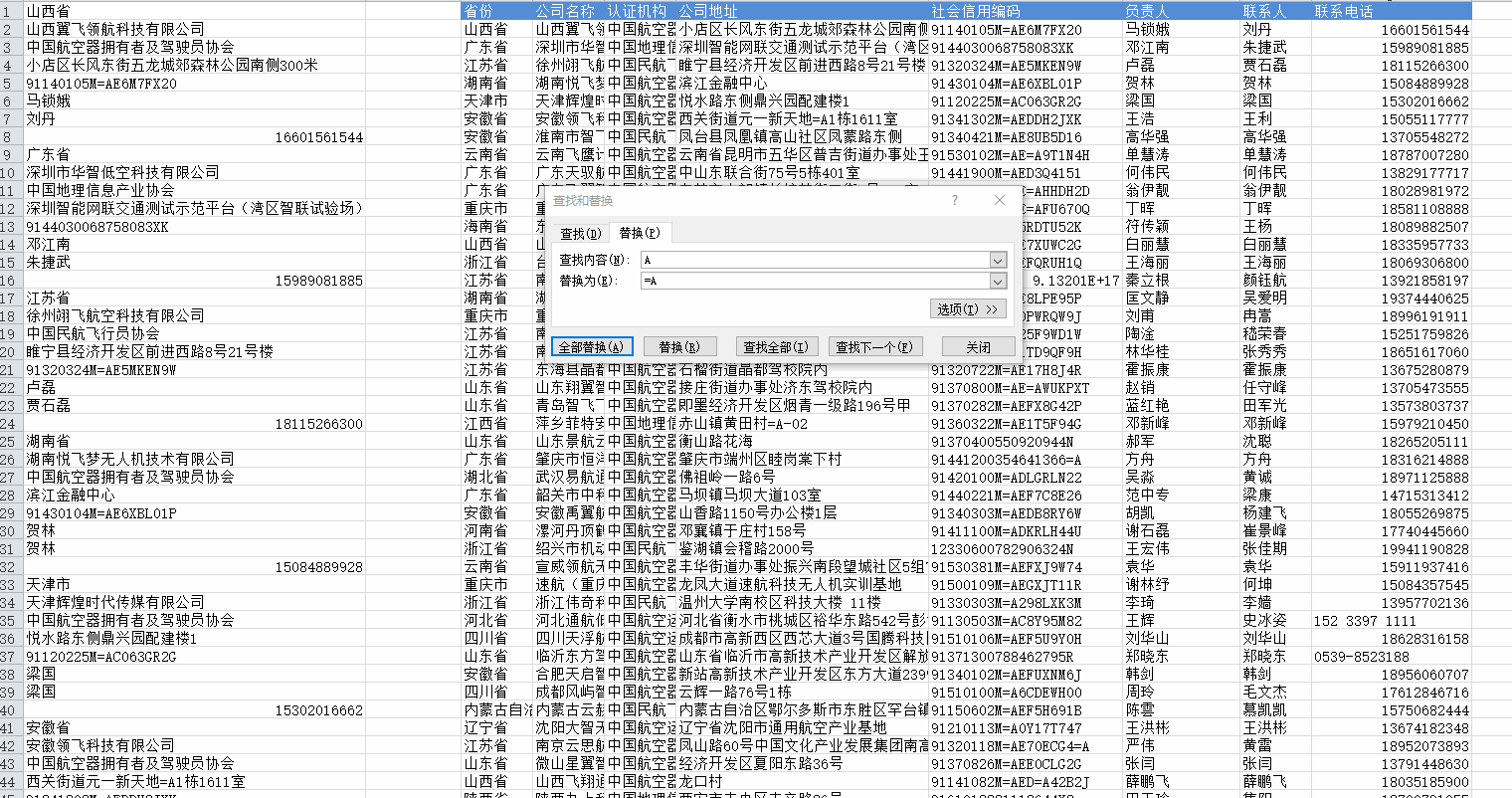
最终的数据:
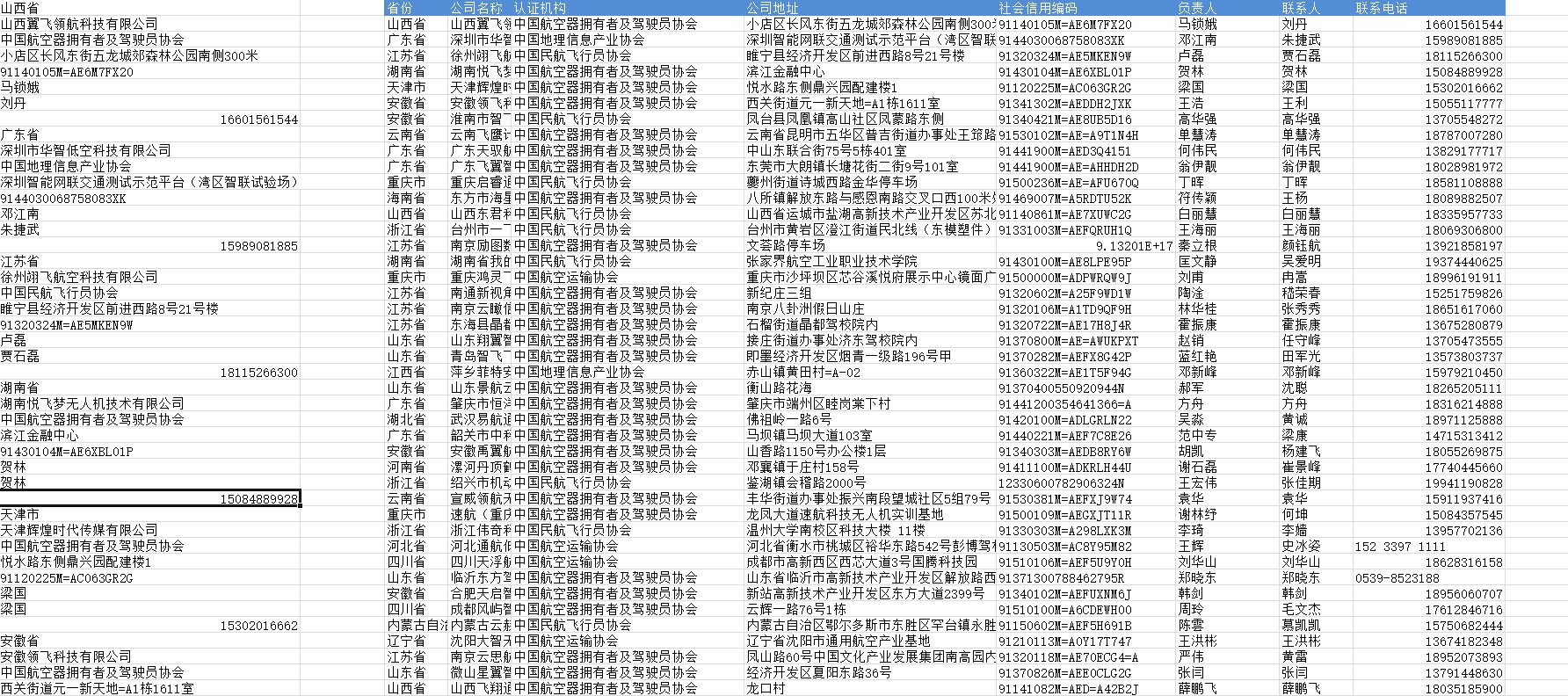
剩下的工作就是把多余的行删除就可以了,另外,因为是替换,所以这里面还会把内容中包含A的内容全部替换为=A。这时候就需要在新生成的数据表格中做个简单的替换就可以了,这个应该没有难度。