在机器学习的入门算法里,KNN(k近邻)绝对是最友好的那一个。它没有复杂的训练过程,核心思想用一句话就能讲明白:"物以类聚,人以群分"。最近我跟着兰智数加学院的课程,从理论到代码完整走了一遍KNN的实践,今天就把这个过程和大家分享一下。
一、KNN算法:简单到"不讲道理"的惰性学习
KNN的全称是k-Nearest Neighbors,翻译过来就是"k个最近的邻居"。它的核心逻辑非常朴素:
• 对于一个待分类的数据点,我们先在数据集中找到离它最近的k个邻居。
• 然后看这k个邻居里,哪个类别占比最多,就把这个类别作为当前点的分类结果。
正因为它不需要提前训练模型,而是在预测时才进行计算,所以也被称为"惰性学习算法"。
优点与缺点并存
• 优点:原理简单、代码实现容易,对异常值不敏感,很适合处理稀有事件的分类问题。
• 缺点:当数据量很大时,计算每个点与所有点的距离会非常耗时;如果样本类别不平衡,少数类别的数据很容易被"淹没"。
二、距离计算:KNN的"度量衡"
要找到"最近的邻居",首先要定义"距离"。常见的距离计算方式有两种:
- 欧式距离:这是我们最熟悉的直线距离,公式为

- 曼哈顿距离:想象在城市里沿着街道行走的距离,公式为

在本次室友匹配的案例中,我们使用的是欧式距离,因为它更符合我们对"相似性"的直观感受。
三、sklear安装
Sklearn (Scikit-Learn) 是基于 Python 语言的第三方机器学习库。它建立在 NumPy, SciPy, Pandas 和 Matplotlib库 之上,里面的 API 的设计非常好,所有对象的接口简单,很适合新手上路。
通过命令指令符:
pip3.11 install scikit-learn==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple四、实战:用KNN帮你找到合拍的室友
我们的目标是根据学生的每年旅行里程、玩游戏时间占比、每周消耗冰淇淋量这三个特征,把学生分为"爱学习""一般""爱玩"三类,从而把相似的学生分配到同一个宿舍。
- 数据准备与可视化
首先,我们用Numpy加载数据集datingTestSet1.txt,并用Matplotlib绘制3D散点图,直观地看到不同类别学生的特征分布。
python
import matplotlib.pyplot as plt
import numpy as np
data = np.loadtxt('datingTestSet1.txt')
data_1 = data[data[:,-1] == 1]
data_2 = data[data[:,-1] == 2]
data_3 = data[data[:,-1] == 3]
fig = plt.figure()
ax = plt.axes(projection = "3d")
ax.scatter(data_1[:,0],data_1[:,1],zs=data_1[:,2],c="#00DDAA",marker="o")
ax.scatter(data_2[:,0],data_2[:,1], zs=data_2[:,2],c="#FF5511",marker="^")
ax.scatter(data_3[:,0], data_3[:,1], zs=data_3[:,2],c="#000011",marker="+")
ax.set(xlabel="Xaxes",ylabel="Yaxes",zlabel="Zaxes")
plt.show()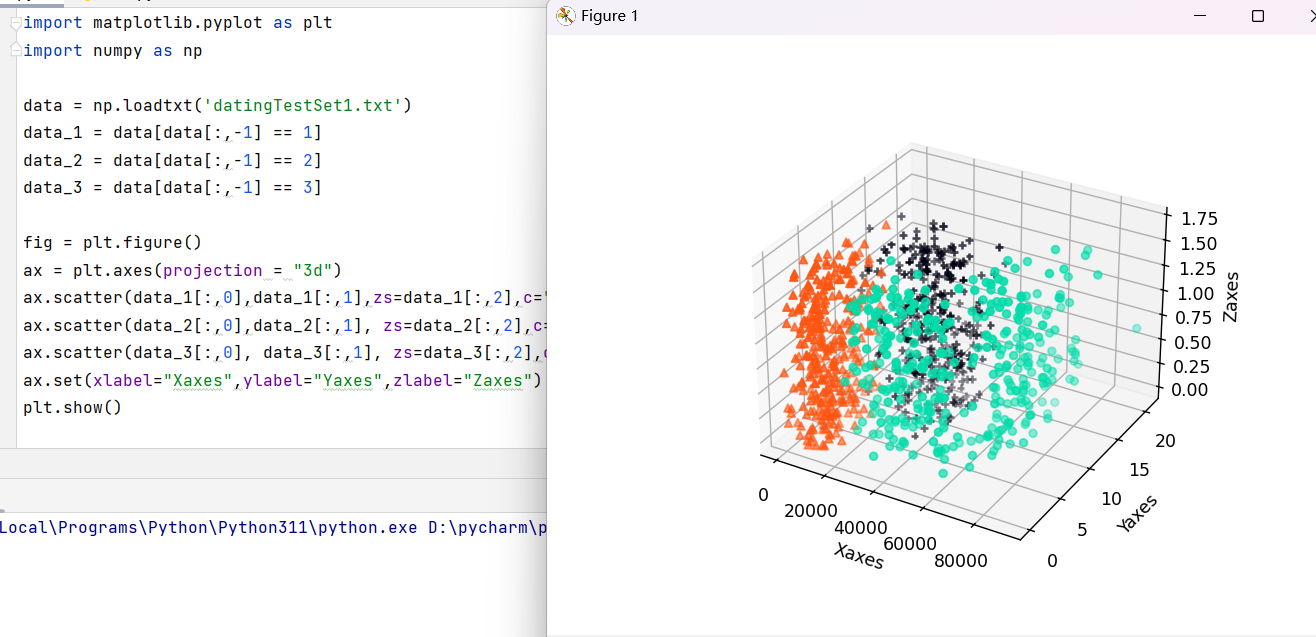
2. 模型训练与评估
接下来,我们使用Sklearn工具包来实现KNN模型。这里有一个关键步骤:特征标准化。因为不同特征的量纲差异很大(比如"旅行里程"是几千公里,而"冰淇淋消耗量"是升),直接计算距离会导致量纲大的特征主导结果。
python
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import scale
train_data = np.loadtxt('datingTestSet2.txt')
test_data = np.loadtxt('datingTestSet3.txt')
train_x = train_data[ :, :-1]
train_y = train_data[ :,-1]
train_x_scaled = scale(train_x)
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(train_x_scaled,train_y)
train_predicted = knn.predict(train_x_scaled)
train_score=knn.score(train_x_scaled,train_y)
print(train_score)
test_x = test_data[ :, :-1]
test_y = test_data[ :,-1]
test_x_scaled = scale(test_x)
test_predicted = knn.predict(test_x)
test_score=knn.score(test_x_scaled,test_y)
print(test_score)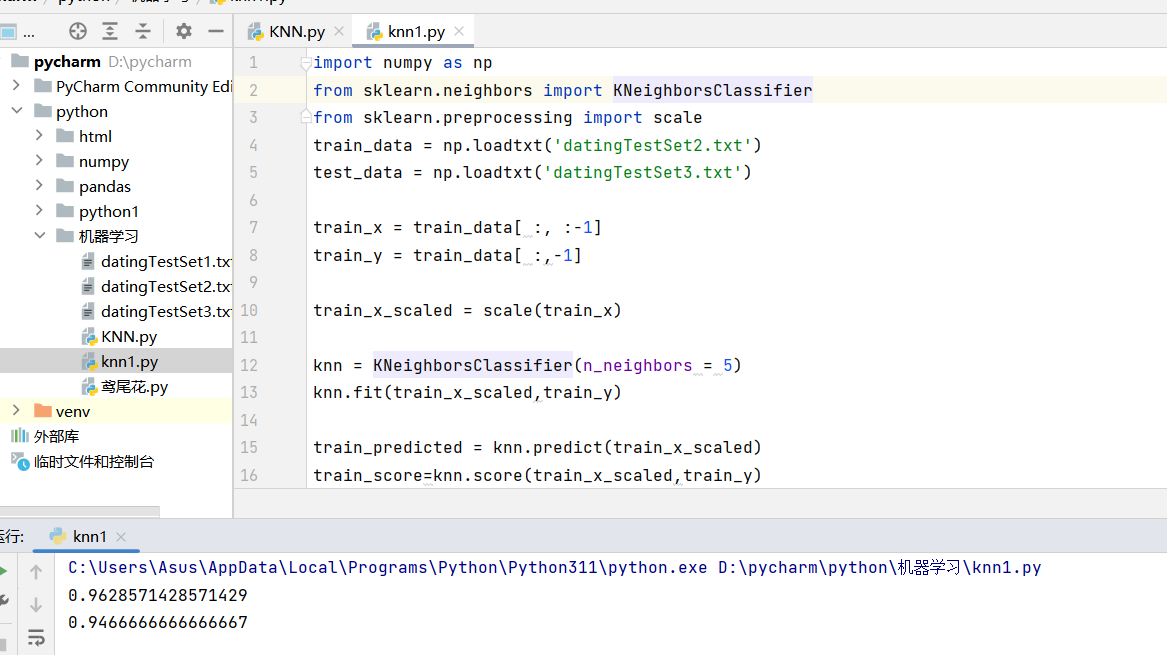
3. 结果与思考
运行代码后,我们可以得到模型在训练集和测试集上的准确率。在这个案例中,k值选择了5,这是一个经验值,你也可以通过交叉验证来找到最优的k值。
整个过程下来,你会发现KNN虽然简单,但在处理这类小样本的分类问题时非常有效。它不需要复杂的数学推导,却能帮我们解决实际问题,非常适合作为机器学习的入门算法。