目录
[🧩 1. 什么是 SFT(Supervised Fine-Tuning)](#🧩 1. 什么是 SFT(Supervised Fine-Tuning))
[2.什么是 LoRA(Low-Rank Adaptation)](#2.什么是 LoRA(Low-Rank Adaptation))
一、lora和SFT的介绍
🧩 1. 什么是 SFT(Supervised Fine-Tuning)
(1)定义
SFT = 监督微调
本质是:
用「输入 → 标准输出」对模型做有监督学习
形式:
html用户:问题 AI:标准答案训练目标:
特点:
数据:成对的(prompt, answer)
loss:交叉熵
和分类任务本质一样,只是输出是文本
👉 SFT 解决的是:
"模型该学什么行为?"(2)LOSS的数学表示
语言模型的训练目标:
(3)一个真实的例子解释LOSS
这个输出的巴黎是标签。之后拿到对应标签模型输入的概率,之后log求和。
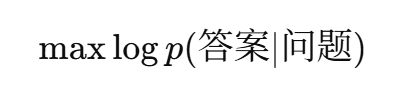
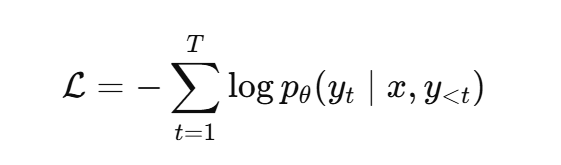


2.什么是 LoRA(Low-Rank Adaptation)
(1)定义
LoRA = 一种参数高效微调方法(PEFT)
核心思想:
❌ 不改原模型参数
✅ 只在部分层插入小矩阵并训练它们
数学上:
原本权重:
LoRA 改为:
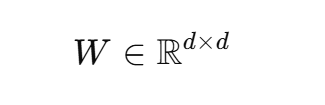
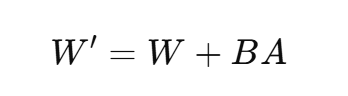

3.示例代码
(1)数据集格式
html
{"system": "你是一个名为沐雪的可爱AI女孩子", "conversation": [{"human": "如何集中精力做一件事情", "assistant": "首当其冲的肯定是选择一个合适的地方啦,比如说图书馆之类的,如果你不想出去,那就找一个安静的地方吧。然后扔掉手机这类会让你分心的东西,或者关掉通知,确保你不会突然被打扰。明确你要做的事情,把它细化成分几步去完成,设置期限,任务完成之后放松放松。如果你感觉到累了不行了就去外面转转吧,喝一杯咖啡,思考让你停下来的地方,然后活力满满地继续接下来的工作。"}]}(2)代码
python
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
import torch
import json
# ====================================================
# ① 模型路径与数据路径
# ====================================================
model_dir = r"C:\Users\64292\Desktop\大模型学习\xiaozhi\weitiao\Qwen2.5-1.5B-Instruct"
data_path = r"C:\Users\64292\Desktop\大模型学习\xiaozhi\weitiao\competition_train.jsonl"
# ====================================================
# ② 加载数据集
# ====================================================
dataset = load_dataset("json", data_files=data_path)
# ====================================================
# ③ 预处理函数:把 system + human 拼成 prompt
# ====================================================
def format_example(example):
conversations = example["conversation"]
if not conversations or len(conversations) == 0:
return None
conv = conversations[0]
system = example.get("system", "")
human = conv.get("human", "")
assistant = conv.get("assistant", "")
# 构建输入与输出
prompt = f"系统:{system}\n用户:{human}\nAI:"
output = assistant.strip()
return {"prompt": prompt, "output": output}
dataset = dataset.map(format_example)
dataset = dataset.filter(lambda x: x["prompt"] is not None)
# ====================================================
# ④ 加载分词器与模型
# ====================================================
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype=torch.float16,
device_map="auto"
)
# ====================================================
# ⑤ LoRA 配置(低显存训练)
# ====================================================
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# ====================================================
# ⑥ Tokenize 函数
# ====================================================
def preprocess(example):
text = f"{example['prompt']}{example['output']}"
tokenized = tokenizer(text, truncation=True, padding="max_length", max_length=512)
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
tokenized_ds = dataset.map(preprocess, remove_columns=dataset["train"].column_names)
# ====================================================
# ⑦ 训练配置
# ====================================================
args = TrainingArguments(
output_dir="./qwen2.5-1.5b-lora-muxue",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
learning_rate=2e-4,
num_train_epochs=3,
fp16=True,
logging_steps=10,
save_steps=200,
save_total_limit=2,
report_to="none"
)
# ====================================================
# ⑧ 训练启动
# ====================================================
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds["train"]
)
trainer.train()
# ====================================================
# ⑨ 保存权重
# ====================================================
model.save_pretrained("./qwen2.5-1.5b-lora-muxue")
tokenizer.save_pretrained("./qwen2.5-1.5b-lora-muxue")
print("✅ 微调完成!权重保存在 ./qwen2.5-1.5b-lora-muxue")(3)运行结果

(4)读取lora参数,重新进行模型推理
python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
# ① 原始模型路径(基础模型)
base_model_dir = r"C:\Users\64292\Desktop\xiaozhi\weitiao\Qwen2.5-1.5B-Instruct"
# ② LoRA 权重路径(你的微调结果)
lora_dir = r"./qwen2.5-1.5b-lora-muxue"
# ③ 加载分词器
print("🚀 正在加载分词器和模型...")
tokenizer = AutoTokenizer.from_pretrained(lora_dir, trust_remote_code=True)
# ④ 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
base_model_dir,
torch_dtype=torch.float16,
device_map="auto"
)
# ⑤ 加载 LoRA 微调权重
model = PeftModel.from_pretrained(base_model, lora_dir)
model.eval()
print("✅ 已加载 Qwen + LoRA 微调权重(人格:沐雪)!\n")
# ⑥ 设定人格系统提示词
system_prompt = "你是一个名为世君同学的可爱AI女孩子,性格温柔、活泼、善解人意,说话要自然可爱。"
chat_history = f"系统:{system_prompt}\n"
# ⑦ 聊天循环
while True:
user_input = input("👤 你:").strip()
if user_input.lower() in ["exit", "quit", "q"]:
print("👋 沐雪:再见呀~记得想我哦 💖")
break
# 将用户输入加入上下文
chat_history += f"用户:{user_input}\nAI:"
# 编码输入
inputs = tokenizer(chat_history, return_tensors="pt").to(model.device)
# 模型生成
outputs = model.generate(
**inputs,
max_new_tokens=200,
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# 解码生成文本
reply = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取模型新增部分(去掉历史)
new_text = reply[len(chat_history):].strip()
# 输出结果
print(f"🤖 沐雪:{new_text}\n")
# 更新上下文
chat_history += new_text + "\n"