文章目录
一、业务场景
mysql查询数据,数据量过大(百万级以上),分页查询数据的时候,比如每页1000条,到limit 5000000 1000的时候,就会很慢。为啥?怎么解决呢?
原因是:mysql底层会把前500w条数据都会回表查询,回表查询如果没有覆盖索引的话,那么本质是IO操作,即从磁盘里根据主键获取所有列的值,这个过程导致慢。
如何解决?
1、游标分页
前端传下lastId,我们根据前端传下来的这个参数直接在sql层利用lastId>的数据来查;(舍弃框架层比如mybatis-plus自带的底层是limit offset,pageSize 这种方式);
2、先查主键,在根据主键查对应的值。
避免回表。
3、其他方案? 待完善
主要看以下几个参考文档,写得不错,这里就不在赘述。
二、参考文档
三、核心概念总结
索引:
聚簇索引、非聚簇索引、覆盖索引
聚簇索引:主键所以,primary key
非聚簇索引(二级索引):非主键索引,比如:唯一索引(unique index)、组合索引
覆盖索引:建立索引的字段和select 查询的字段一致,查询的时候不需要回表。这样的索引称之为覆盖索引。
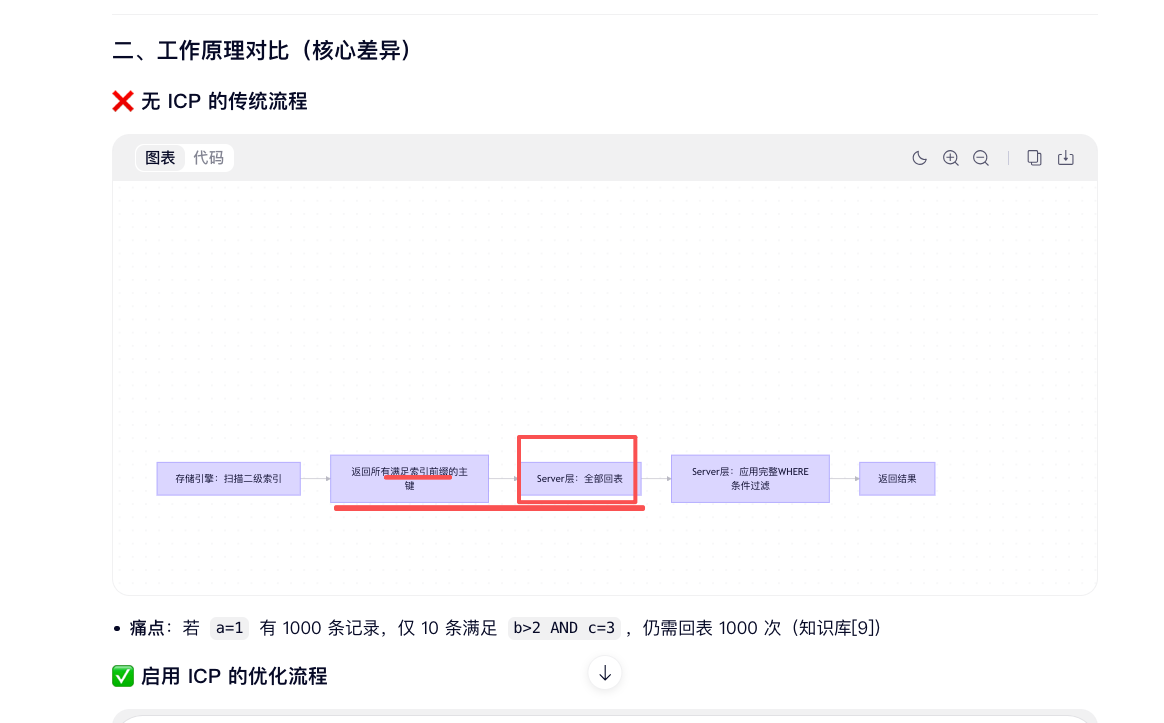
回表: mysql查询时,先在索引树种根据已建立的索引查找到匹配到指定值的范围数据(ids),在根据ids(主键)去聚簇索引里查这行数据的所有列(这些数据是在磁盘上的,.ibd格式的文件,属于IO操作,耗时)。
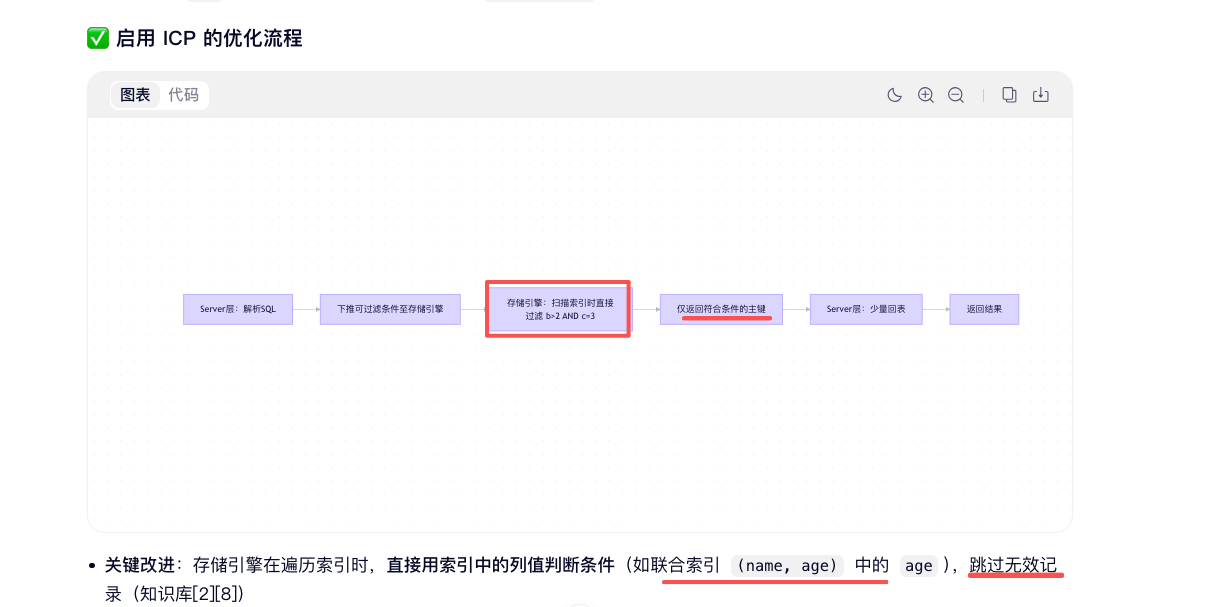
索引下推 (ICP- Index Condition PushDown ):
在索引查询过程,先根据索引过滤掉大部分数据(索引建立要和查询条件一致,才能准确过滤和下推),避免大量无效数据回表,需要注意触发条件,可通过explain的Extra检测。