目录
[1. 索引的本质](#1. 索引的本质)
[2. 索引的核心作用](#2. 索引的核心作用)
[二、底层原理:MySQL 为何选择 B + 树作为索引结构](#二、底层原理:MySQL 为何选择 B + 树作为索引结构)
[1. 候选数据结构对比](#1. 候选数据结构对比)
[2. B + 树的核心特点](#2. B + 树的核心特点)
[3. B + 树在 MySQL 中的实际应用](#3. B + 树在 MySQL 中的实际应用)
[1. 按存储结构分类](#1. 按存储结构分类)
[(1)聚集索引(Clustered Index)](#(1)聚集索引(Clustered Index))
[(2)非聚集索引(Secondary Index)](#(2)非聚集索引(Secondary Index))
[2. 按功能分类](#2. 按功能分类)
[(1)主键索引(Primary Key)](#(1)主键索引(Primary Key))
[(2)唯一索引(Unique Index)](#(2)唯一索引(Unique Index))
[(3)普通索引(Normal Index)](#(3)普通索引(Normal Index))
[(4)复合索引(Composite Index)](#(4)复合索引(Composite Index))
[(5)全文索引(Fulltext Index)](#(5)全文索引(Fulltext Index))
[1. B + 树索引的优势](#1. B + 树索引的优势)
[2. 聚集索引与非聚集索引的核心区别](#2. 聚集索引与非聚集索引的核心区别)
[3. 索引使用的关键原则](#3. 索引使用的关键原则)
[(2)复合索引的 "最左前缀原则"](#(2)复合索引的 “最左前缀原则”)
[(3)索引的 "优缺点" 与使用边界](#(3)索引的 “优缺点” 与使用边界)
一、索引是什么
1. 索引的本质
MySQL 的索引是一种排好序的数据结构,它通过特定规则组织数据表中的记录,指向数据行的物理位置,从而实现快速定位和访问数据。
类比生活场景:索引就像汉语字典的目录 ------ 无需逐页查找,通过拼音、笔画等索引就能快速定位目标汉字;数据库中无需全表扫描,通过索引就能直接找到数据所在位置,大幅提升查询效率。
2. 索引的核心作用
核心目标:提升数据检索效率(查询操作占比远高于增删改,索引对查询的优化效果最显著)。
辅助价值:排序时可直接利用索引的有序性,避免额外排序操作。
二、底层原理:MySQL 为何选择 B + 树作为索引结构
MySQL 支持多种数据结构作为索引基础,但最终选择B + 树作为默认索引结构。要理解这一点,需先对比其他候选结构的优缺点:
1. 候选数据结构对比
|------------------|------------------|--------------------------|
| 数据结构 | 优点 | 缺点 |
| HASH | 单值查询速度快(O (1)) | 不支持范围查询、排序操作 |
| 二叉搜索树 | 中序遍历有序 | 最坏情况树高为 N(O (N)),IO 次数过多 |
| AVL / 红黑树(平衡二叉树) | 树高平衡(O (logN)) | 二叉结构导致树高仍较高,IO 次数较多 |
| N 叉树 | 降低树高,减少 IO 次数 | 非叶子节点存储数据,空间利用率低 |
| B + 树(最终选择) | 树高最低、支持范围查询、性能均衡 | |
2. B + 树的核心特点
- 非叶子节点仅存索引信息,不存真实数据;所有真实数据都存储在叶子节点。
- 叶子节点构成有序双向链表 ,天然支持范围查询(如
between and、order by)。- 相同数据量下树高最低,磁盘 IO 次数最少(数据库性能瓶颈是磁盘 IO,减少 IO 即提升性能)。
- 查找任一元素的时间复杂度均为 O (logN),性能均衡,无极端情况。

3. B + 树在 MySQL 中的实际应用
MySQL 中数据存储的最小单元是页(Page),默认大小 16KB,页与页之间通过双向链表连接,页内数据通过单向链表组织。
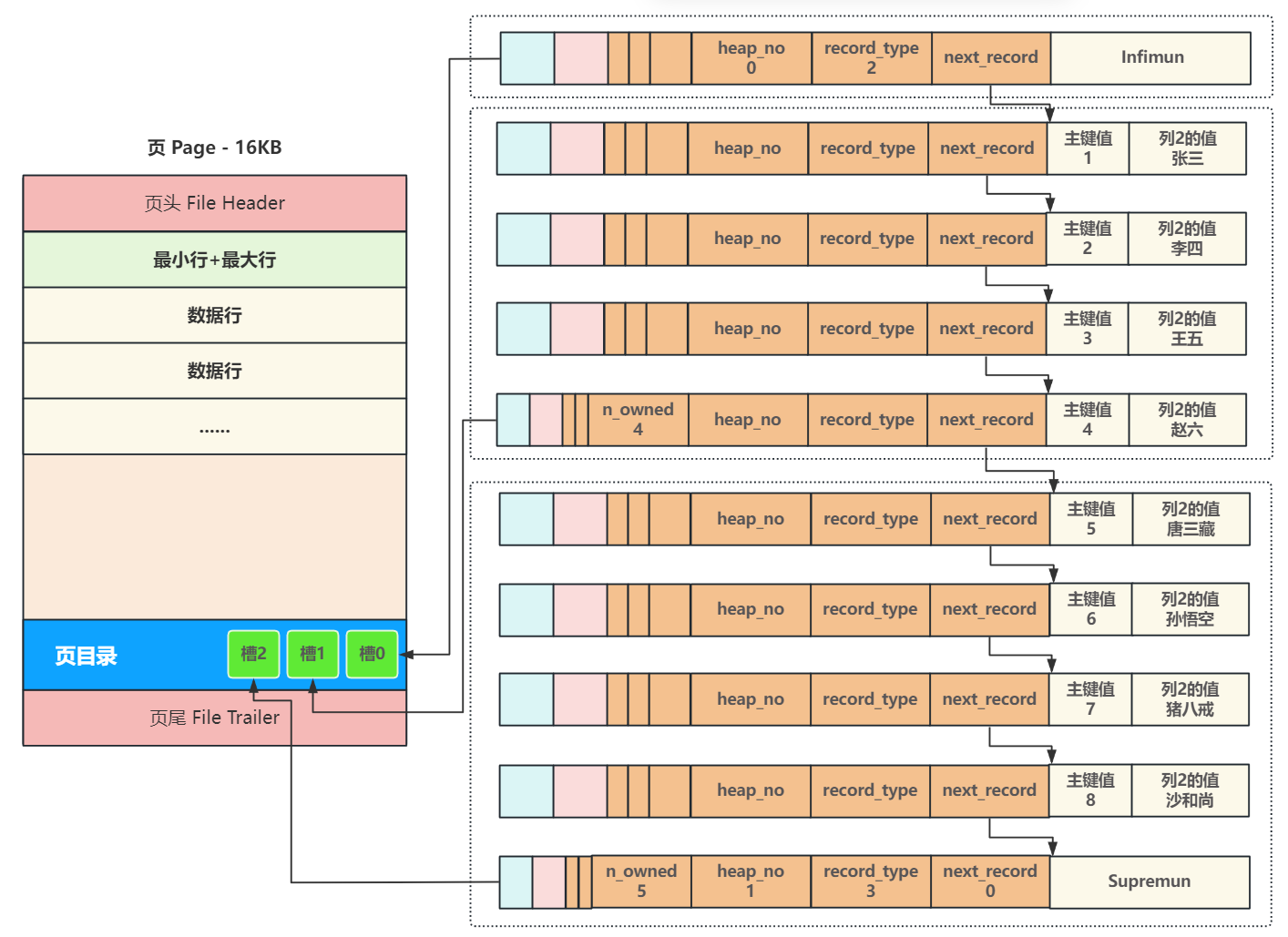
B + 树与页结构的结合逻辑:
- B + 树的非叶子节点对应 "索引页",存储索引键和下一级页的地址(8 字节主键 + 6 字节页地址 = 14 字节 / 条,16KB 页可存约 1170 条索引)。
- B + 树的叶子节点对应 "数据页",存储完整的行数据(16KB 页可存约 16 条 1KB 大小的行数据)。
- 检索过程:从根节点开始,通过索引键比较定位到子节点页,最终在叶子节点页中找到目标数据。例如三层 B + 树可存储约 2190 万条数据,仅需 3 次磁盘 IO 即可完成检索。
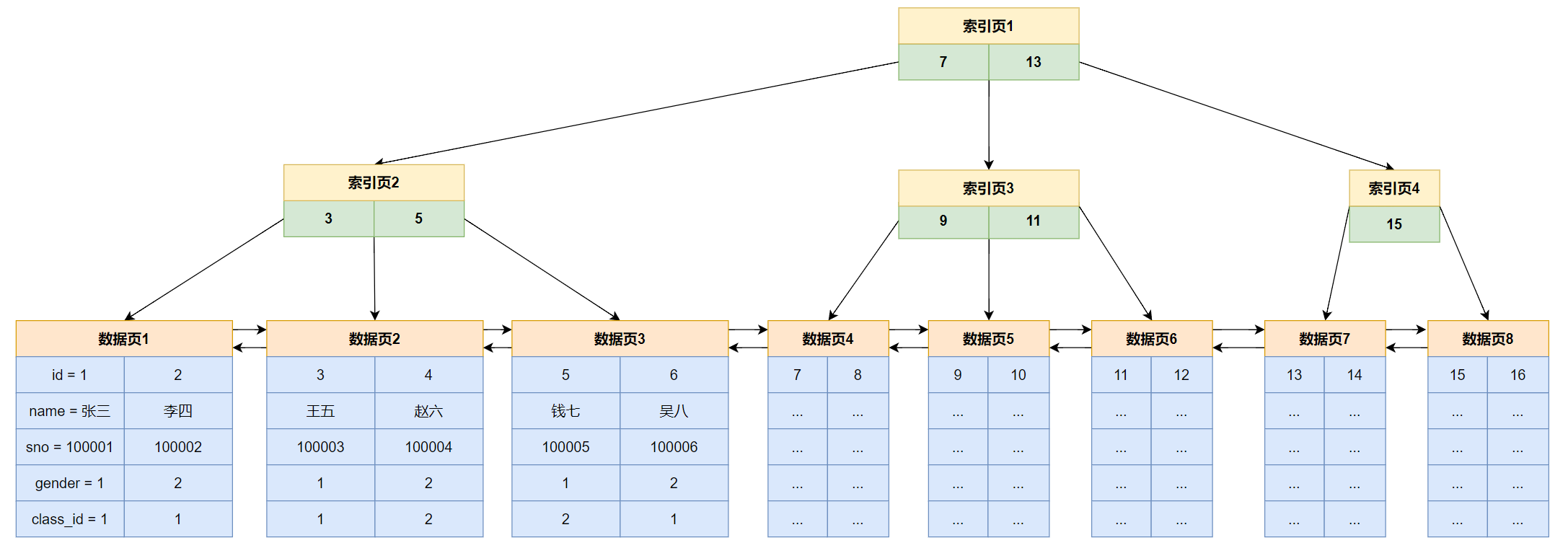
三、索引分类:
MySQL 的索引按功能和存储方式可分为多种类型,核心分类如下:
1. 按存储结构分类
(1)聚集索引(Clustered Index)
**核心特点:**索引与数据 "聚簇" 存储,索引结构即数据存储结构,叶子节点直接存储完整行数据
生成规则:
表有主键时,主键索引即为聚集索引;
无主键时,选择第一个非空唯一索引作为聚集索引;
既无主键也无合适唯一索引时,MySQL 自动生成 6 字节 ROW_ID 作为隐藏聚集索引。
**优势:**查询主键时无需回表,直接获取完整数据。
(2)非聚集索引(Secondary Index)
**核心特点:**索引与数据分离存储,叶子节点存储 "索引键 + 主键值",需通过主键值回表查询完整数据(此过程称为 "回表")。
**常见类型:**普通索引、唯一索引、全文索引、复合索引等。
**注意:**非聚集索引依赖聚集索引,删除聚集索引会导致所有非聚集索引失效。
2. 按功能分类
(1)主键索引(Primary Key)
特点:唯一且非空,自动成为聚集索引。
创建方式:
sql
-- 方式1:建表时指定
CREATE TABLE t_test_pk (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
-- 方式2:建表后修改
ALTER TABLE t_test_pk2 ADD PRIMARY KEY (id);(2)唯一索引(Unique Index)
特点:索引列值唯一(允许 NULL 值),可避免重复数据。
创建方式:
sql
CREATE TABLE t_test_uk (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) UNIQUE -- 建表时创建
);
-- 建表后添加
ALTER TABLE t_test_uk2 ADD UNIQUE (name);(3)普通索引(Normal Index)
特点:最基础的索引类型,无唯一性限制,仅用于提升查询效率。
创建方式:
sql
-- 方式1:建表时指定
CREATE TABLE t_test_index (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
sno VARCHAR(10),
INDEX (sno)
);
-- 方式2:单独创建并指定索引名
CREATE INDEX idx_sno ON t_test_index2(sno);(4)复合索引(Composite Index)
特点:基于多列创建的索引,遵循 "最左前缀原则"(查询需匹配索引列的左起顺序)。
适用场景:频繁按多列组合查询(如**
WHERE sno = '1001' AND class_id = 2**)。
创建方式:
sql
CREATE TABLE t_test_composite (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
sno VARCHAR(10),
class_id BIGINT,
INDEX idx_sno_class (sno, class_id) -- 复合索引:sno在前,class_id在后
);(5)全文索引(Fulltext Index)
特点:基于文本列(CHAR、VARCHAR、TEXT)创建,用于全文搜索(如关键词匹配)。
限制:仅 MyISAM 和 InnoDB 引擎支持。
四、原理与优化
1. B + 树索引的优势
- 磁盘 IO 效率高:树高低(三层树可存 2000 万 + 数据),查询仅需 3 次 IO。
- 支持范围查询:叶子节点有序链表,可快速遍历区间数据。
- 性能均衡:任一元素查询时间复杂度均为 O (logN),无极端情况。
- 空间利用率高:非叶子节点仅存索引信息,一页可存储更多索引条目。
2. 聚集索引与非聚集索引的核心区别

3. 索引使用的关键原则
(1)索引覆盖:避免回表的高效查询
当查询的列刚好是索引列(或复合索引的所有列)时,无需回表,直接从索引中获取数据,称为 "索引覆盖"。
回表查询是指非聚集索引查询时,叶子节点仅存主键,需通过主键再次查询聚集索引获取完整数据的过程。避免方式:①使用索引覆盖(查询列仅包含索引列);②将高频查询列纳入复合索引。
示例:复合索引**
idx_sno_class(sno, class_id)** ,查询**SELECT sno, class_id FROM t_test WHERE sno = '1001'**,直接通过索引返回结果,无需回表。
(2)复合索引的 "最左前缀原则"
复合索引的查询需匹配左起顺序,否则无法命中索引。
示例:索引**
idx_sno_class(sno, class_id)**:
- 命中索引:
WHERE sno = '1001'、WHERE sno = '1001' AND class_id = 2;- 未命中索引:
WHERE class_id = 2、WHERE sno LIKE '%1001'。
(3)索引的 "优缺点" 与使用边界
优点:提升查询效率(从全表扫描 O (N) 到 O (logN))、支持排序和分组;
缺点:占用额外存储空间、增删改操作需维护索引(降低写入效率);
禁忌:不要过度建索引(一张表建议不超过 5 个)、不要在低频查询列建索引、不要在大字段(如 TEXT)建索引。