1. 核心思想:引入"记忆"
传统的神经网络(如全连接层)假设输入是相互独立的。但语言、视频、股票等数据是序列数据 (Sequence Data),上下文有关联。
- RNN 的突破:在处理当前时刻t的输入时,不仅看当前的输入Xt,还要看上一时刻的隐状态Ht-1
2. 数学模型 (核心公式
RNN 的核心在于隐状态 (Hidden State) 的更新。假设时间步为 t
-
隐状态更新:
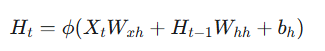
-
输出计算 :
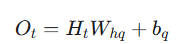
- : 当前时刻的输出(例如预测下一个词的概率分布)。
3. 结构图解:时间展开
可以将 RNN 理解为多个全连接层在时间上串联,但它们共用同一套权重。
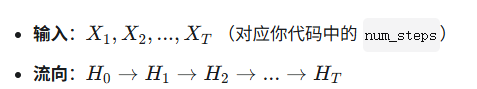
4. 训练方法:BPTT
-
BPTT (Backpropagation Through Time):随时间反向传播。
-
计算梯度时,误差不仅反向传过当前的层,还要沿着时间轴向前回溯,一直传到序列的开始(或截断点)。
5. RNN vs N-gram (对比笔记)
你刚学过 N-gram,两者的区别在于:
-
N-gram:只能看有限的历史(N-1) 阶),参数量随 N指数级爆炸,无法建模长距离依赖。
-
RNN:理论上可以看任意长的历史(信息存储在 H中),参数量固定(权重共享),更适合处理变长序列。
6. 局限性与挑战
虽然 RNN 理论上能记忆长距离信息,但实际上很难训练:
-
梯度消失 (Vanishing Gradient):时间步太长,早期的信息在反向传播中逐渐归零,导致模型"忘掉"了开头的词。
-
梯度爆炸 (Exploding Gradient):梯度指数级增长,导致权重更新过大,模型崩溃。
-
解决爆炸:梯度裁剪 (Gradient Clipping)。
-
解决消失:使用 LSTM 或 GRU (门控机制)。
-