在数字化时代,我们囤积了大量的影视资源链接(百度网盘、夸克网盘),但它们通常以杂乱的 TXT 文本形式存在。只有链接,没有海报;只有片名,没有评分。
为了解决这个痛点,我开发了**"影迹 AI Editor"**。这是一个纯前端的单页应用(SPA),它利用 DeepSeek 的 AI 能力解析文本,结合 TMDB 的元数据,将冰冷的文字列表瞬间转化为精美的影视海报墙。
本文将从背景、目标、技术方法、核心实现过程、最终效果及总结六个维度,详细剖析这段代码的构建逻辑。
"C:\Users\86182\Downloads\ai_studio_code (37).html"
1. 背景 (Background)
传统的资源整理方式存在以下问题:
- 信息缺失:TXT 文件里只有"文件名+链接",无法直观看到电影的年份、评分、简介或演员阵容。
- 管理困难:难以对资源进行增删改查,容易重复收集。
- 交互体验差:复制链接需要手动操作,无法一键跳转。
我们需要一个工具,既能理解非结构化的文本(识别片名和链接),又能对接全球影视数据库(获取海报和元数据),并且所有数据都要掌握在用户自己手中(本地化存储)。
2. 目标 (Goal)
构建一个**无后端(Serverless)、单文件(Single File)**的 Web 应用,实现以下核心功能:
- AI 智能导入:上传 TXT 文件,利用 LLM(DeepSeek)自动提取片名和不同网盘的链接。
- 元数据自动匹配:根据提取的片名,自动从 TMDB 获取海报、评分、年份、简介及演职员表。
- 增删改查与排重:支持手动搜索添加、删除条目,并具备自动排重机制。
- 本地化存档:支持将整理好的影单导出为带版本号的 JSON 文件,并随时加载恢复。
- 极致 UI:采用暗黑玻璃拟态风格(Glassmorphism),提供沉浸式体验。
3. 方法 (Method)
为了保持项目的轻量化和易部署,技术栈选择了最纯粹的组合:
- 结构与逻辑:HTML5 + 原生 JavaScript (ES6+)。
- 样式框架:Tailwind CSS (CDN 引入) ------ 快速构建响应式和暗黑模式界面。
- 图标库:FontAwesome ------ 提供美观的 UI 图标。
- 交互组件 :SweetAlert2 ------ 替代原生丑陋的
alert,提供优雅的弹窗提示。 - 外部 API :
- DeepSeek API:负责自然语言处理(NLP),从乱码中提取结构化 JSON。
- TMDB API:负责提供影视海报、背景图、演员等元数据。
4. 过程 (Process)
4.1 界面架构与拟态设计
整体采用深色背景(bg-slate-900),核心容器使用 glass-card 类实现毛玻璃效果:
css
.glass-card {
background: rgba(30, 41, 59, 0.7);
backdrop-filter: blur(12px);
border: 1px solid rgba(255, 255, 255, 0.1);
}布局上采用 Flexbox 做导航,Grid 做海报墙(grid-cols-2 sm:grid-cols-3...),确保在移动端和桌面端都有良好的展示。
4.2 核心逻辑一:AI 驱动的文本解析
这是系统的"大脑"。传统的正则提取很难处理各种不规则的文本格式。代码中定义了一个 callDeepSeek 函数,通过 Prompt Engineering 让 AI 帮我们将文本"洗"成 JSON:
javascript
const systemPrompt = `你是一个数据提取助手... 严格返回JSON数组:[{"title": "片名", "baidu_link": "", "quark_link": ""}]...`;
// ... fetch 请求 ...这一步将非结构化数据转化为了标准化的程序可读数据。
4.3 核心逻辑二:元数据融合与排重
拿到 AI 解析的片名后,系统并行调用 TMDB 接口。为了提升匹配准确度,代码做了一个细节处理:
- 清洗片名:移除干扰符(如"-"),提高搜索命中率。
- 智能排序 :搜索结果按
release_date降序排列,优先展示最新上映的版本(例如搜索"三体",优先显示电视剧版而非老旧短片)。 - 防重机制:在添加新条目时,对比全局列表的 TMDB ID 或片名,防止重复添加。
4.4 核心逻辑三:本地化存档系统
为了解决"纯前端无法操作文件系统"的限制,代码实现了一套基于 Blob 和 LocalStorage 的存档机制。
文件名生成算法:
javascript
// 生成 YYYYMMDD + 递增序号 (001, 002...)
let seqKey = `seq_${dateStr}`;
let currentSeq = parseInt(localStorage.getItem(seqKey) || '0') + 1;
const fileName = `${dateStr}${String(currentSeq).padStart(3, '0')}.json`;保存与加载:
- 保存 :将
globalMovieList数组序列化为 JSON 字符串,创建 Blob 对象触发浏览器下载。 - 加载 :使用
<input type="file">和FileReader读取本地 JSON 文件,瞬间恢复应用状态。
4.5 细节打磨:网盘链接的 UI 修复
在早期的版本中,网盘链接显示错位。最终代码通过 Flexbox 完美解决了这个问题:
css
.link-row {
display: flex; /* 启用 Flex 布局 */
justify-content: space-between; /* 两端对齐 */
align-items: center; /* 垂直居中 */
}
.link-input {
flex: 1; /* 占据中间所有剩余空间 */
/* ...省略样式... */
}这确保了左侧图标、中间链接、右侧按钮在同一水平线上井然有序。
5. 结果 (Result)
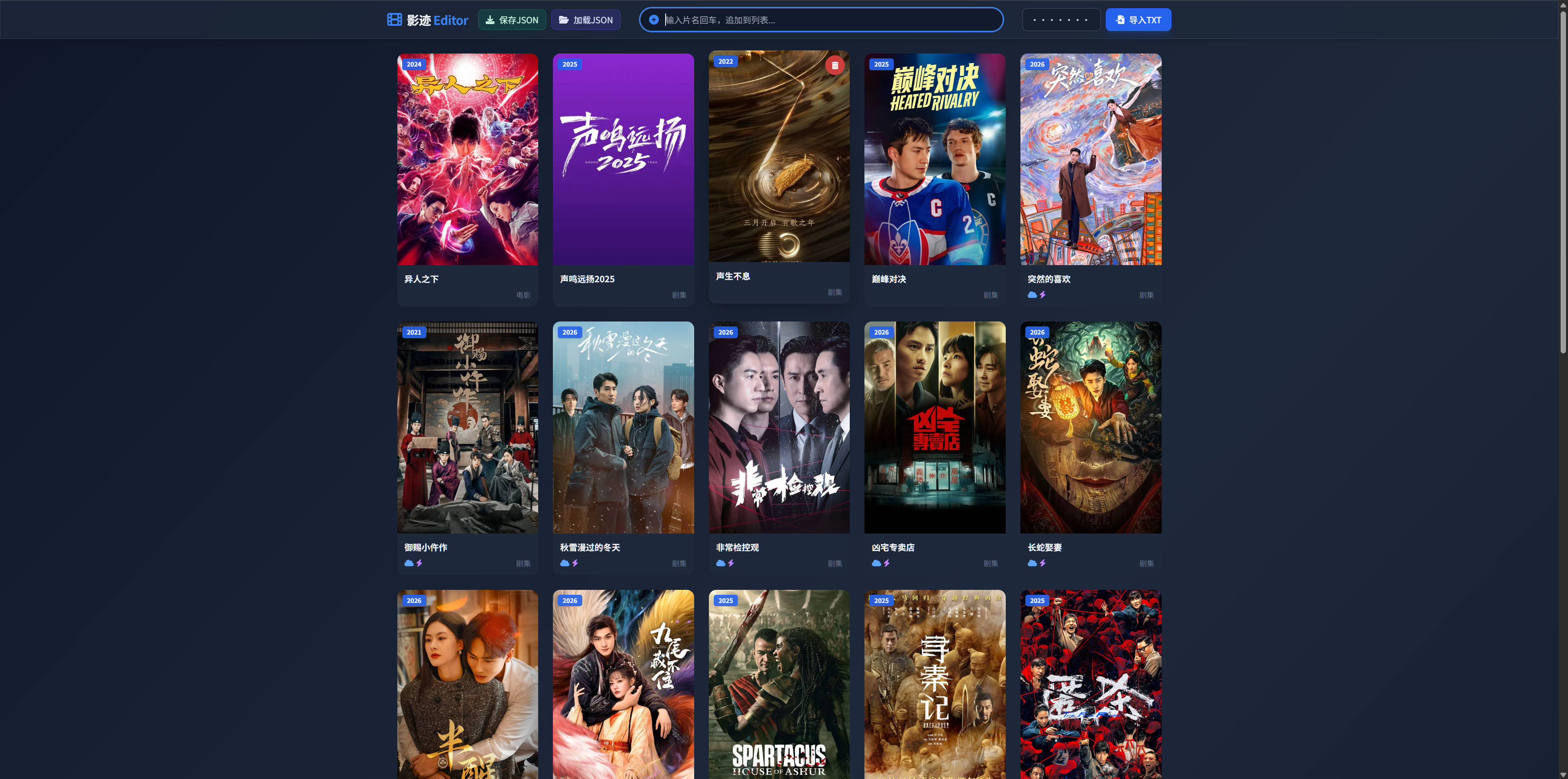
经过上述开发,我们得到了一个功能完备的"影迹 Editor":
- 极速体验 :无需安装 Python 环境或 Node.js 依赖,双击
index.html即可运行。 - 可视化管理:原本枯燥的文本变成了带有评分、年份标签的海报墙。
- 信息聚合:点击海报,不仅能看到剧情简介,还能直接查看演员详细资料,并一键跳转百度/夸克网盘。
- 数据安全 :API Key 存储在本地 LocalStorage,影单数据以 JSON 文件保存在用户硬盘,没有任何数据上传至第三方服务器。
6. 总结 (Conclusion)
这段代码是一个典型的**"大模型落地应用"**微型案例。
- 技术层面:它展示了如何通过简单的 HTML/JS 胶水代码,将强大的 AI 能力(DeepSeek)和垂直领域数据(TMDB)连接起来,解决实际问题。
- 产品层面:它验证了即使没有后端数据库,通过浏览器自身的存储和文件处理能力,也能构建出体验优秀的工具类软件。
影迹 AI Editor 不仅仅是一个播放列表整理工具,它通过技术手段,让每个人都能轻松构建属于自己的私人影视图书馆。未来,我们还可以进一步引入 IndexedDB 提升数据容量,或增加海报本地缓存功能,使其更加强大。