目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-Transformer架构1-整体介绍、Transformer架构2-自注意力、Transformer架构3-嵌入和位置编码,欲渐进,请循序
- 本文重点介绍Transformer架构中的多种注意力,它们在编码器堆栈和解码器堆栈中都有用到
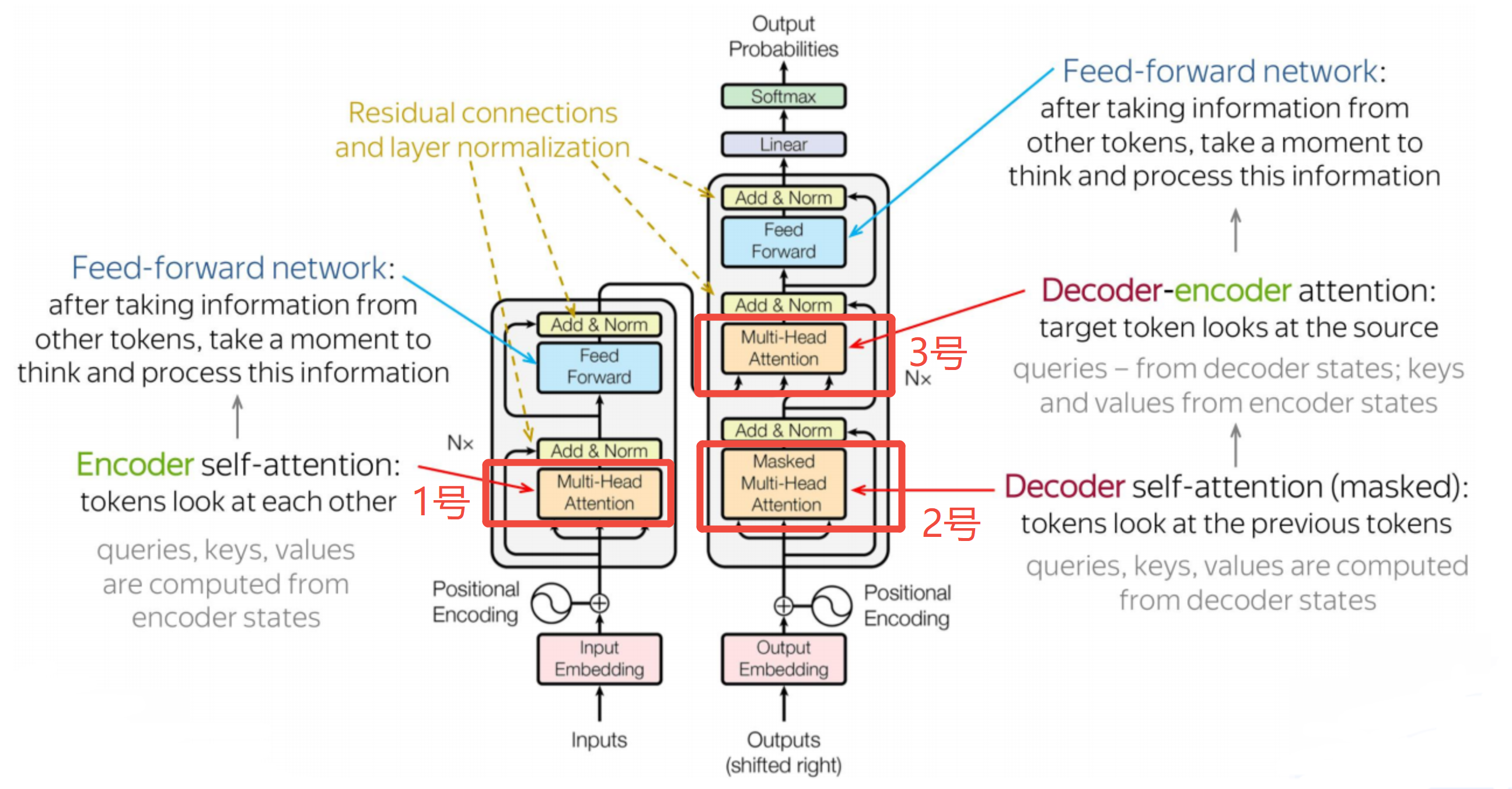
概述
在前文Transformer架构2-自注意力中,讲到上图中的1号、2号注意力都是自注意力,而在详细架构图中,他们又被描述为多头注意力、掩码注意力等。诸多概念容易让人混淆,必须澄清:这些注意力的类型并非互斥,他们只是从不同的角度对注意力机制进行的分类
-
按Q、K、V的不同来源分类:
- 自注意力:Q、K、V来自同一个序列
- 交叉注意力:Q、K、V来自不同的序列,上图3号编码器-解码器注意力是一种具体的交叉注意力,它的Q来自解码器(的输出序列),K、V来自编码器(的输出序列)
-
按Q、K、V的数量分类
- 多头注意力:将 Q、K、V 投影到多个子空间,并行计算多个注意力,然后拼接
- 单头注意力:只有一个注意力头,即只有一组Q、K、V
-
按信息可见性进行分类
- 掩码注意力 :通过掩码矩阵限制某些 token 对之间的注意力权重(通常设为 -∞),使其在 softmax 后接近 0。目的是控制信息流动,防止信息泄漏。架构图中,2号注意力是掩码注意力的一个子类-因果掩码注意力,它只能看到当前及之前的 token(因为解码器下一刻的输出还不知道)
- 非掩码注意力:所有 token 对之间都可以自由计算注意力,无访问限制。如上图中1号和3号都是非掩码注意力
按照上述说明,上图1-3号注意力详细分类如下:
- 1号注意力,属于多头注意力、自注意力、非掩码注意力
- 2号注意力,属于多头注意力、自注意力、掩码注意力
- 3号注意力,属于多头注意力、交叉注意力、非掩码注意力
多头注意力详解
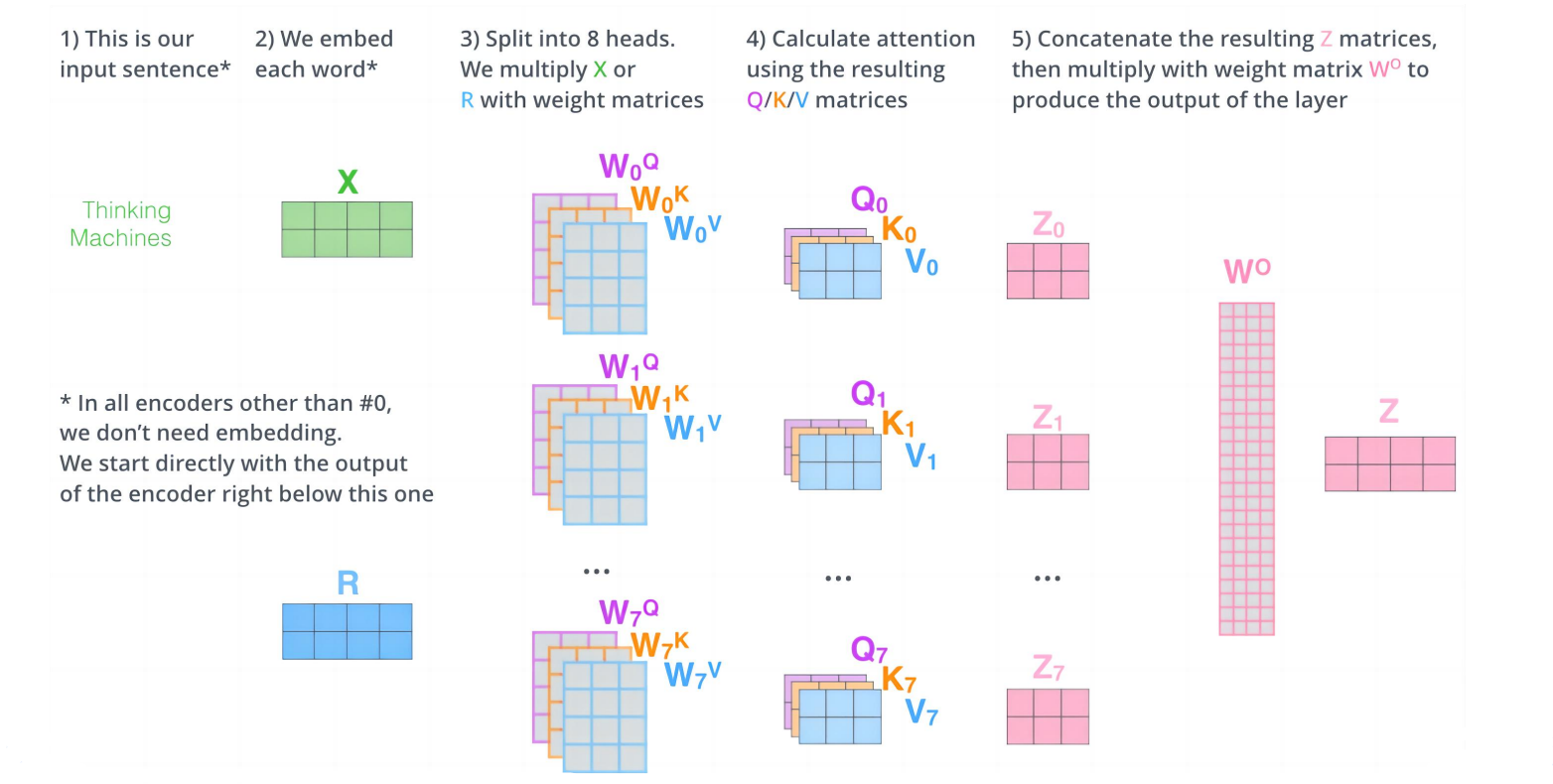
什么是多头注意力
从本质上看:多头注意力是一种将信息的表示空间进行分解的注意力。 它将一个标准的注意力过程分解为多个并行的"头",每个头在不同的表示子空间中学习不同的注意力模式,最后将所有头的输出拼接并线性变换。
从形式上看:多头注意力使用多组 W Q W^Q WQ、 W K W^K WK、 W V W^V WV矩阵,标准单头注意力则仅使用一组。
多头注意力的每个头是什么
每个"头"本质上是一个独立的注意力计算单元,包含三个关键部分:
1. 独立的参数投影Q、K、V
2. 独立的注意力计算过程:
python
head_i = Attention(head_i_Q, head_i_K, head_i_V)- 每个头在自己的子空间中计算注意力权重
- 计算公式相同: s o f t m a x ( Q K T / √ d k ) V softmax(QKᵀ/√d_k)V softmax(QKT/√dk)V
3. 独立的信息聚焦:
不同的头可能会自发地学习关注不同类型的信息:
- 头1 :可能关注语法结构(如主谓关系)
- 头2 :可能关注语义角色(如施事、受事)
- 头3 :可能关注长距离依赖
- 头4 :可能关注局部短语结构
示例(翻译任务:"The animal didn't cross the street because it was too tired"):
头1关注 "it" → "animal" (指代关系)
头2关注 "didn't" → "cross" (否定修饰)
头3关注 "cross" → "street" (动宾关系)
头4关注 "tired" → "animal" (属性描述)多头注意力的优缺点
| 方面 | 优点 | 缺点 |
|---|---|---|
| 🎯 表示能力 | 1. 多视角学习 :同时捕捉语法、语义、指代等多种关系 2. 特征多样性 :类似CNN多滤波器,提取不同模式特征 3. 表达能力增强:超越单头注意力的表示上限 | 1. 冗余风险 :多个头可能学习相似模式,造成参数浪费 2. 协调困难:不同头之间需要良好配合,优化难度增加 |
| ⚡ 计算效率 | 1. 并行加速 :多个头可完全并行计算,GPU利用率高 2. 维度分解 :单头维度降低(d_k = d_model/h),矩阵乘法更高效 3. 复杂度优化:理论复杂度从 O(n²·d_model²) 降至 O(n²·d_model²/h) | 1. 实际开销 :拼接、投影、数据移动增加额外开销 2. 内存消耗 :需存储所有头的中间结果,内存占用显著增加 3. 通信成本:分布式训练时,多头的梯度同步成本高 |
| 🔄 模型性能 | 1. 泛化提升 :类似集成学习效应,减少过拟合 2. 收敛加速 :多路径学习有助于梯度流动 3. 鲁棒性增强:部分头失效时,其他头可补偿 | 1. 僵尸头问题 :部分头学习不到有效模式,成为"死头" 2. 不稳定训练 :多头竞争可能导致训练波动 3. 过参数化:小数据集上容易过拟合 |
| 🔍 可解释性 | 1. 模式可视化 :可分析不同头关注的语义/语法模式 2. 调试友好 :通过头分析定位模型问题 3. 结构洞察:揭示模型学习到的语言学结构 | 1. 解读误导 :注意力权重≠重要性,可能被过度解读 2. 模式混合 :实际中头常学习混合特征,边界模糊 3. 分析复杂度:需要专门工具分析多头注意力模式 |
| 🔧 工程实现 | 1. 模块化设计 :结构清晰,易于实现和扩展 2. 兼容性好 :与各种优化技术(混合精度、梯度检查点)兼容 3. 社区支持:主流框架均有优化实现 | 1. 实现复杂度 :比单头注意力实现更复杂 2. 批处理限制 :不同头可能对批大小敏感 3. 部署挑战:边缘设备上多头计算资源要求高 |
| 📊 资源消耗 | 1. 计算分解 :大矩阵分解为小矩阵,适合硬件优化 2. 灵活配置:可根据资源调整头数 | 1. 参数量增加 :增加约 (3h+1)/4 倍参数(相比单头) 2. 激活值存储 :前向传播需存储多头中间结果,内存峰值高 3. 能耗增加:移动端/边缘设备能耗显著增加 |
| 🎓 学习动态 | 1. 多目标优化 :不同头可专注不同子任务 2. 避免局部最优:多起点搜索提高找到全局最优概率 | 1. 优化冲突 :不同头的梯度方向可能冲突 2. 学习不平衡 :某些头学习快,某些学习慢 3. 超参数敏感:头数选择对性能影响大,需精细调参 |
掩码注意力详解
什么是掩码注意力
掩码注意力是在注意力计算中,通过一个掩码矩阵强制让某些位置的注意力权重变为零(或接近零),从而限制信息流动方向的注意力机制。
下图分别呈现了1-3号注意力的权重关系特征,其中2号掩码自注意力中,每个token只能向前关注,无法向后关注,因为后面的token还没有生成。
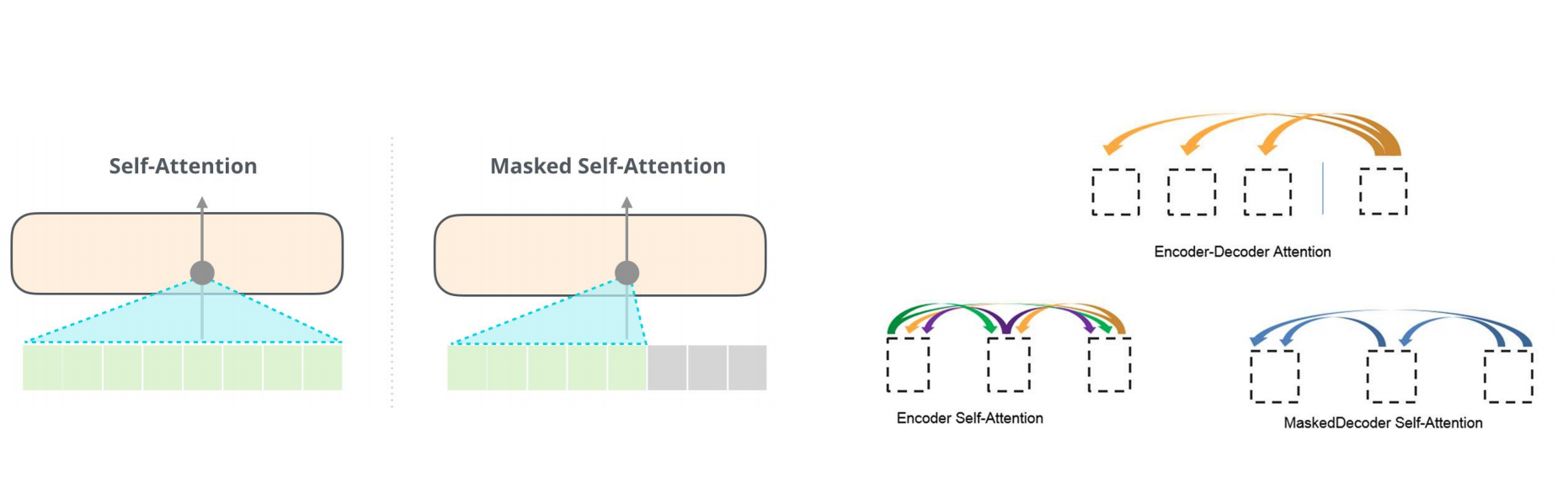
为什么用掩码注意力
- 保证自回归性(因果掩码):防止解码时看到未来信息,确保逐词生成
- 处理变长序列(填充掩码):忽略padding位置,聚焦有效内容
- 预训练任务需求(随机掩码):如BERT的MLM任务,随机遮盖部分token
- 提升计算效率(稀疏掩码):减少注意力计算量,处理长序列
掩码自注意力怎么计算
计算公式如下图:
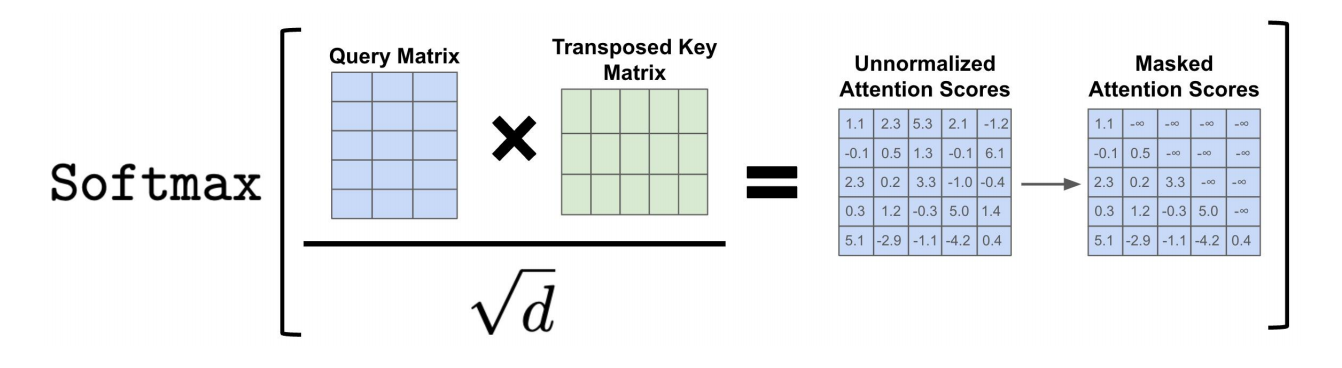
掩码逻辑示意如下:
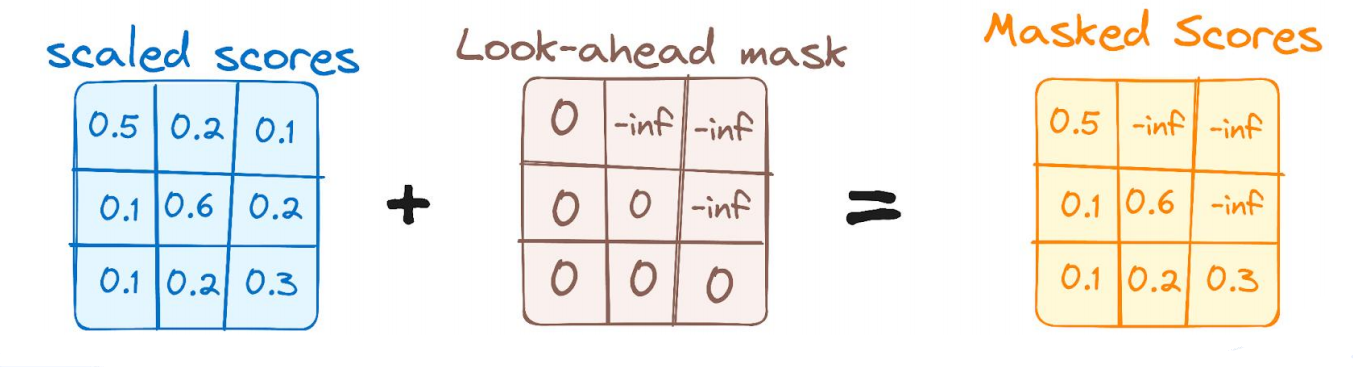
注意:之所以这里用 − ∞ -∞ −∞,是因为后续softmax函数中的 e x e^x ex,当x是 − ∞ -∞ −∞, e x e^x ex趋近于0
编解码注意力
即传统的注意力机制,只是它的K和V来自于编码器的输出,Q来自于解码器自身之前的输出,传统注意力机制的说明,详见前文-注意力机制