指针指向
指针
main.cpp
#include <iostream>
#include <memory>
#include "mclog.h"
#include "byte_tmp.h"
// 使用 str 的地址,推荐
void print(const std::string &str)
{
std::cout << "打印内容: " << str << std::endl;
}
// 复制了 str 会变慢,不推荐
void print_copy(std::string str)
{
std::cout << "打印内容: " << str << std::endl;
}
// 获取返回值,推荐
int add(int a, int b)
{
return a + b;
}
// 引用,不推荐
void add_ref(int &a, int &b)
{
a += b;
}
// 指针,不推荐,这是一种将参数当作返回值的做法
void add_ptr(int *a, int *b)
{
*a += *b;
}
int main(int argc, char **argv)
{
MCLOG("计算方式")
{
// 传参数,实际为复制
int a = 10;
int b = 20;
int c = add(a, b);
MCLOG($(a) $(b) $(c));
}
{
// 传引用,实际为地址
int a = 10;
int b = 20;
add_ref(a, b);
MCLOG($(a) $(b));
}
{
// 传指针,实际为地址
int a = 10;
int b = 20;
add_ptr(&a, &b);
MCLOG($(a) $(b));
}
MCLOG("\n参数传递大小")
{
std::string str;
int a = 10;
int *ptr_a = &a;
MCLOG($(sizeof(str)) $(sizeof(a)) $(sizeof(ptr_a)));
print("hello");
print_copy("hello");
}
MCLOG("\n指针指向")
{
int a = 10;
int b = 20;
int ref_a = a;
int *ptr = nullptr;
MCLOG($(a) $(b) $(ref_a) $(ptr));
// 获取到 a 的地址
ptr = &a;
// 从 ptr 提取数据赋值给 c 变量后使用
// 等效 int c = a;
int c = *ptr;
MCLOG($(a) $(b) $(ref_a) $(ptr) $(*ptr) $(c));
// 改为获取 b 赋值给 c 变量
// 等效 c = b;
ptr = &b;
c = *ptr;
MCLOG($(a) $(b) $(ref_a) $(ptr) $(*ptr) $(c));
// 指向 a 并从 c 获取值
// 等效 a = c;
ptr = &a;
*ptr = c;
MCLOG($(a) $(b) $(ref_a) $(ptr) $(*ptr) $(c));
}
MCLOG("\n指针寻指")
{
// ptr 地址推进步长为 4 ,buf 的总长度为 40
int *ptr = nullptr;
int buf[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
// 获取指定位置
ptr = &buf[2];
MCLOG($(*ptr));
// 向前推进 2 个位置,因为数组的数据是连续的,向前推进还在数据地址内
// 推进的步长为 4 * 2
ptr += 2;
MCLOG($(*ptr));
// 转为大块内存
long long *ptrll = reinterpret_cast<long long *>(ptr);
std::string str_bit = print_byte<long long>(*ptrll);
MCLOG($(*ptrll));
MCLOG($(str_bit));
/*
分析 ptrll 指向的二进制 str_bit
0000000000000000000000000000011000000000000000000000000000000101
00000000 00000000 00000000 00000110 00000000 00000000 00000000 00000101
6 5
ptrll 内存顺序是从高往底,指向的是 5 6 两个数字地址,ptrll 等于 buf[4] buf[5] 两块内存的合并
*/
// 大块内存推进 1 个位置,之后转为小内存
// 推进的步长为 8 * 1
// ptrll 推进之后指向 buf[6] buf[7] ,转为 ptr 之后指向 buf[6] 从低到高转为小内存
// ptrll 推进 1 等于 ptr 推进 2,因为 ptrll 的地址长度是 ptr 的一倍
ptrll++;
ptr = reinterpret_cast<int *>(ptrll);
MCLOG($(*ptr));
// 修改指向地址的数据,改变二进制数据为 15 这个数字
*ptrll = 0b0000000000000000000000000000111100000000000000000000000000001111;
for (int i = 0; i < (sizeof(buf) / sizeof(int)); i++)
{
std::cout << buf[i] << " ";
}
std::cout << std::endl;
}
MCLOG("\n分配空间")
{
// 分配空间,不推荐,需要手动释放,忘记就会内存泄露
int *ptr_a = new int(10);
int *ptr_b = new int(20);
// 智能指针,推荐,不用手动释放
std::shared_ptr<int> sp_a = std::make_shared<int>(10);
std::shared_ptr<int> sp_b = std::make_shared<int>(20);
MCLOG($(*ptr_a) $(*ptr_b) $(ptr_a) $(ptr_b));
MCLOG($(*sp_a) $(*sp_b) $(sp_a) $(sp_b));
// 销毁
delete ptr_a;
delete ptr_b;
}
MCLOG("\n垃圾代码")
{
int buf[3][3][3]{
{{1, 2, 3}, {10, 20, 30}, {100, 200, 300}},
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
{{7, 8, 9}, {70, 80, 90}, {700, 800, 900}},
};
int *pl1 = &buf[0][0][0];
int (*pl2)[3] = &buf[0][0];
int (*pl3)[3][3] = &buf[0];
// 垃圾代码
(pl1 = *((pl2 = *(++pl3)) += 2))++;
MCLOG($(*pl1) $(*pl2[0]) $(*pl3[0][0]));
pl1 = &buf[0][0][0];
pl2 = &buf[0][0];
pl3 = &buf[0];
// 等效代码
pl3++;
pl2 = pl3[0];
pl2 += 2;
pl1 = pl2[0];
pl1++;
MCLOG($(*pl1) $(*pl2[0]) $(*pl3[0][0]));
// 等效代码,直接定位到 [2-1][3-1][1]
pl1 = &buf[0][0][0];
pl1 += 3 * (2 + 3) + 1;
MCLOG($(*pl1));
/*
代码分析
数据范围
{{1, 2, 3}, {10, 20, 30}, {100, 200, 300}},
^
pl1
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
{{7, 8, 9}, {70, 80, 90}, {700, 800, 900}},
执行: ++pl3
等价: pl3 += 1
数据范围
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
^
pl1
执行: (pl2 = *(++pl3)) += 2
等价: pl2 += 2
数据范围
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
^
pl1
执行: (pl1 = *((pl2 = *(++pl3)) += 2))++
等价: pl1 += 1
数据范围
{400, 500, 600}
^
pl1
*/
// 遍历
MCLOG("遍历结果");
for (int a = 0; a < 3; a++)
{
for (int b = 0; b < 3; b++)
{
for (int c = 0; c < 3; c++)
{
std::cout << buf[a][b][c] << " ";
}
std::cout << std::endl;
}
}
}
return 0;
}打印结果
计算方式 [/home/red/open/github/mcpp/example/16/main.cpp:39]
[a: 10] [b: 20] [c: 30] [/home/red/open/github/mcpp/example/16/main.cpp:45]
[a: 30] [b: 20] [/home/red/open/github/mcpp/example/16/main.cpp:52]
[a: 30] [b: 20] [/home/red/open/github/mcpp/example/16/main.cpp:59]
参数传递大小 [/home/red/open/github/mcpp/example/16/main.cpp:62]
[sizeof(str): 32] [sizeof(a): 4] [sizeof(ptr_a): 8] [/home/red/open/github/mcpp/example/16/main.cpp:67]
打印内容: hello
打印内容: hello
指针指向 [/home/red/open/github/mcpp/example/16/main.cpp:73]
[a: 10] [b: 20] [ref_a: 10] [ptr: 0] [/home/red/open/github/mcpp/example/16/main.cpp:80]
[a: 10] [b: 20] [ref_a: 10] [ptr: 0x7fffffffd898] [*ptr: 10] [c: 10] [/home/red/open/github/mcpp/example/16/main.cpp:88]
[a: 10] [b: 20] [ref_a: 10] [ptr: 0x7fffffffd894] [*ptr: 20] [c: 20] [/home/red/open/github/mcpp/example/16/main.cpp:94]
[a: 20] [b: 20] [ref_a: 10] [ptr: 0x7fffffffd898] [*ptr: 20] [c: 20] [/home/red/open/github/mcpp/example/16/main.cpp:100]
指针寻指 [/home/red/open/github/mcpp/example/16/main.cpp:103]
[*ptr: 3] [/home/red/open/github/mcpp/example/16/main.cpp:111]
[*ptr: 5] [/home/red/open/github/mcpp/example/16/main.cpp:116]
[*ptrll: 25769803781] [/home/red/open/github/mcpp/example/16/main.cpp:121]
[str_bit: 0000000000000000000000000000011000000000000000000000000000000101] [/home/red/open/github/mcpp/example/16/main.cpp:122]
[*ptr: 7] [/home/red/open/github/mcpp/example/16/main.cpp:138]
1 2 3 4 5 6 15 15 9 0
分配空间 [/home/red/open/github/mcpp/example/16/main.cpp:149]
[*ptr_a: 10] [*ptr_b: 20] [ptr_a: 0x5555555713d0] [ptr_b: 0x5555555713f0] [/home/red/open/github/mcpp/example/16/main.cpp:159]
[*sp_a: 10] [*sp_b: 20] [sp_a: 0x555555571420] [sp_b: 0x555555571440] [/home/red/open/github/mcpp/example/16/main.cpp:160]
垃圾代码 [/home/red/open/github/mcpp/example/16/main.cpp:167]
[*pl1: 500] [*pl2[0]: 400] [*pl3[0][0]: 4] [/home/red/open/github/mcpp/example/16/main.cpp:181]
[*pl1: 500] [*pl2[0]: 400] [*pl3[0][0]: 4] [/home/red/open/github/mcpp/example/16/main.cpp:193]
[*pl1: 500] [/home/red/open/github/mcpp/example/16/main.cpp:198]
遍历结果 [/home/red/open/github/mcpp/example/16/main.cpp:230]
1 2 3
10 20 30
100 200 300
4 5 6
40 50 60
400 500 600
7 8 9
70 80 90
700 800 900终于来到指针篇了,转为C++的入门系列居然将指针放到怎么后面才讲确实很奇怪,实际上是我考虑再三之后发现其实指针真的没什么可讲的
指针的用法无非就是指向一块内存地址而已,这个内存可以是预设的任何一个类型,然后通过指针简直的使用这个类型
新手可能会觉得指针难,其实只是不了解指针的运行规则而已,只要记住所有的数据都是二进制内存,那指针就没什么难的
数据类型的使用是直接指向,指针类型的使用是间接指针,你要记住,指针是需要依赖一块具体的数据类型的,指针是不能单独存在的,否则便失去了意义
那既然你可以使用数据类型,如 int 这个类型,那有什么到底是不能使用他的指针 int * 的呢,请记住指针一定是指向具体数据,所以 int * 会被提取出 int 所以你就可以正常的使用这个数据了
指针传参
// 函数声明
// 获取返回值,推荐
int add(int a, int b)
{
return a + b;
}
// 引用,不推荐
void add_ref(int &a, int &b)
{
a += b;
}
// 指针,不推荐
void add_ptr(int *a, int *b)
{
*a += *b;
}
// 调用方式
{
// 传参数,实际为复制
int a = 10;
int b = 20;
int c = add(a, b);
MCLOG($(a) $(b) $(c));
}
{
// 传引用,实际为地址
int a = 10;
int b = 20;
add_ref(a, b);
MCLOG($(a) $(b));
}
{
// 传指针,实际为地址
int a = 10;
int b = 20;
add_ptr(&a, &b);
MCLOG($(a) $(b));
}指针最常用的用法就是传参,上面代码中 add 加法将两个整数相加,然后返回结果,这是推荐的做法
add_ref add_ptr 是没有返回值的,因为他们把计算结果都放入了变量 a 中,这里表明了a 和 b 是可以被修改的,因为他们使用了 int * 指针和 int & 引用,他们代表传入的数据是可以改变的
你可能会说这是形参实参,但是我不想提这么复杂而且拗口的名词,我只想说他们传入的是原来的地址或者是复制的新地址
如果传入的是原来的地址,修改它就会改变原来的值,我称为传地址
如果传入的是复制的新地址,修改它也跟原来的地址没关系,我称为传复制
这是一个很简单的道理,我会用复制和地址代表他们传入的是原来的地址还是新复制的地址
变量名,引用,指针实际上都需要指向一块具体存储数据的地址,他们都需要建立在一块有效的地址上,这个块地址有我们声明的数据,区别是变量名和引用可以直接访问,指针只能间接访问
下面的图示会告诉你为什么会这样
变量地址图示
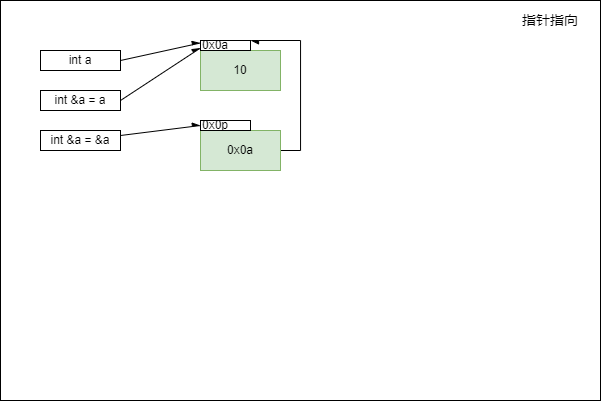
你要知道,在程序中,变量的数据都写到地址上,所以你修改变量等于修改地址,那么修改地址也等于修改了变量,因为变量本身就是那个地址的一个名词,一个别名而已
那么请注意,int a 是地址 0x0a 的别名,这个 0x0a 我是自己乱编的一个代表 a 的地址,int &ref_a = a 引用 ref_a 这个引用实际上地址还是 0x0a ,并没有生成新的空间地址,你明白引用的含义了吗,他就是一个别名而已
int *ptr_a = &a 是将一个指针指向 a,那么他会生成一块新空间地址,现在就有两块地址 0x0p 和 0x0a ,请注意 0x0a 存放的二进制是数字 10,但是 0x0p 存放的二进制是地址 0x0a
指针的空间存储的是地址,这就是为什么指针不能独自存在的原因,它必须要依赖一块具体的数据,否则就失去了意义,因为指针想要访问一块数据,他需要存储这个数据的地址,然后通过数据的地址,间接的访问到这个数据具体的内容
在语法的上,假设 &a = 0x0a | a = 10 ,那么 &ptr_a = 0x0p | ptr_a = 0x0a | *ptr_a = 10 这就是为什么使用指针时都是 *ptr_a 这种形式,这代表执行了两步,找到地址,从地址取数据
入参与出参
// 指针,不推荐,这是一种将参数当作返回值的做法
void add_ptr(int *a, int *b)
{
*a += *b;
}当你知道使用指针是传入地址时,你发现可以改变传入参数 a 的值,它称为入参,如果你将计算结果写入 a 这个参数就会变成返回值的一部分,这会修改外部的值
这是一种入参变出参的做法,通常出参就是运行结果的返回值,你应该保持结果通过返回值传出,而不是通过传入参数传出,非常不好的做法
这种代码会破坏调用者常规认知,调用者以为这个函数没有返回值,不会有结果,实际上却破坏了传入的参数,改变了外部数据,从而引发问题
你需要谨慎的修改入参,请明确表示这个函数会修改入参,否则请不要修改入参,这样可以减少认知错位产生的问题
谨慎修改入参是 编程规范 的重要一步
类型大小
void print(const std::string &str)
{
std::cout << "打印内容: " << str << std::endl;
}在 main.cpp 文件的 参数传递大小 例子部分,我打印了几个类型的大小,其中 std::string 是 32 字节,int 为 4 ,而 int * 为 8,需要注意的是指针和引用总是 8 个字节,以为他们只保持地址,而地址64位计算机地址为 8 字节
在函数 print 中,为什么参数是 const std::string &str 这样长一堆呢,是因为我需要将 string 转为引用,这样就可以将调用函数的参数长度从 32 降低到 8 字节,而 const 约束了这个 print 函数不会改变 string 的任何内容,如果没有 const 的引用类型,则默认会改变参数数据
这种降低传入参数字节的做法是很普遍且推荐的,C++需要注重性能,而且本身没有对传入参数优化的机制
假设采用复制的形式传入一个类型,因为你不希望他被修改,它继承了几十层,足足有 1000 byte 大小,他的拷贝构造还需要复制 2000 byte 的数据到堆区,然后我们将它以复制的方式传入函数,那一次调用就要拷贝 1000 + 2000 = 3000 byte 的数据才能将这个类型的数据传入到函数中
而使用 const T& 的形式可以转为引用类型,是固定的 8 字节类型,而且也不会触发拷贝函数,因为是引用而不是复制,有 const 修饰也不会担心数据被修改,那传递这个庞大的类型只需要 8 byte 就足够了,因为只是引用而已
主要注意的是,结构体总是大于 8 byte,但是基本类型如 int 等只有 4 byte ,所以传入他们时不需要刻意的使用 const T& 的引用形式,这样反而会变大成 8 byte 的引用类型
如果想保持这个好习惯,请记住传递任何非基本类型都需要使用 const T& 形式的短字节参数
使用短字节参数是 编程规范 的重要一步
指针指向
int a = 10;
int b = 20;
int ref_a = a;
int *ptr = nullptr;
// 获取到 a 的地址
ptr = &a;
// 从 ptr 提取数据赋值给 c 变量后使用
// 等效 int c = a;
int c = *ptr;
// 改为获取 b 赋值给 c 变量
// 等效 c = b;
ptr = &b;
c = *ptr;
// 指向 a 并从 c 获取值
// 等效 a = c;
ptr = &a;
*ptr = c;在上面的代码中演示了指针指向的问题,请记住指针总是需要指向一块具体数据的,否则指针将没有意义
你只需要知道你到底指向那个数据就行了,新手决定指针难是以为根本没明白指针在干嘛,也不知道指针指向的具体数据,如果你明白你指针指向的数据之后,你就可以把他当成普通变量一样使用了
在上面的例子中,你总是能看到等效代码,你就应该知道 *ptr 本身等效指向的变量本身,如果指向 a 那个 ptr 就等于 a ,那怎么使用 a 就可以怎么使用 ptr 指针
是不是感觉指针其实很简单,没什么难的,以为指针本身也是一种类型而已,一种变量而已,你既然可以使用 int 就可以使用 int ,完全可以把 int 当作 int 来使用
需要注意的是 ptr = &a; 这一行,指针存储的是地址,所以需要存的是 &a 的地址,而不是 a 的数字
指针移动
int *ptr = nullptr;
int buf[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
long long *ptrll = reinterpret_cast<long long *>(ptr);在代码 main.cpp 文件中 指针寻指 的例子来告诉你,指针的移动规律,int *ptr 时移动的是 4 byte ,变成 long long *ptrll 时移动的是 8 byte,也就是说指针是根据类型决定自己每次移动的步长的,如果有类型是 100 byte ,那他的指针移动一次就是 100 byte,指针的这个特性决定了它在相同类型数组下,每次移动都可以指向这个类型的完整数据
在这个例子里,ptr 指针指向 int buf10 来移动,移动一次就等于下一个元素,ptrll 则是 int 的两倍长度,我使用 ptr 转为 ptrll 类型,实际上指向的地址还是在 int buf10 内部,则是需要注意的
你需要知道,指针的类型不重要,指针指向的地址才作重要,指针存储的地址总是 8 byte,所以转变成不管什么类型存储的内容是不变的
我在使用 ptrll 时,打印了指向地址的数据,可以清晰的得出存储的二进制内容就是 int buf10 存储的值,所以你知道你的指针指向那你,你会可以随意操作你的数据,我最后修改 ptrll 指针的二进制数据,也正是 bug 数组的二进制所在的位置
智能指针
// 分配空间,不推荐,需要手动释放,忘记就会内存泄露
int *ptr_a = new int(10);
int *ptr_b = new int(20);
// 智能指针,推荐,不用手动释放
std::shared_ptr<int> sp_a = std::make_shared<int>(10);
std::shared_ptr<int> sp_b = std::make_shared<int>(20);
MCLOG($(*ptr_a) $(*ptr_b) $(ptr_a) $(ptr_b));
MCLOG($(*sp_a) $(*sp_b) $(sp_a) $(sp_b));
// 销毁
delete ptr_a;
delete ptr_b;说到指针,在绝大多数时候的使用都是通过 new 分配的,因为 new 只会返回指针类型,你也必须通过指针去接收
new delete 是从堆区获取和销毁内存,他们的总是成对出现的,如果你忘记 delete 数据,那么你就内存泄露了,则是C++总是说不安全的原因,它需要你自己去 delete 数据
当代码变得复杂只会,你就会发现一个数据什么时候被 delete 是不确定的,然后你又会内存泄露了
什么是内存泄露呢,你要知道从堆区 new 出来的数据是不会释放的,必须手动 delete 才会释放,我们会用一个指针指向这个 new 出来的堆区数据,当内存 new 出来却没有任何指针指向它的时候就是内存泄露
内存泄露就是内存已经分配出来了,但是你却用不了,因为没有指针指向这块内存地址,所以这个块内存即不能使用还不能释放,也不会自己消失,还可能越来越多,然后整个操作系统都会被影响
内存泄露是非常严重的问题,他会慢慢的侵蚀整个操作系统,直到这个泄露的程序进程被停下,然后那些内存才会被操作系统回收
原始指针需要谨慎使用,我推荐你使用智能指针,它可以自己管理堆区数据,他会自己 new delete 数据,不用你关心它何时需要销毁,以及忘记销毁等问题
使用智能指针跟使用普通指针是一样的,这一点不会造成什么负担
但是智能指针不是万能的,它只能帮你管理正常流程的数据销毁,一旦进入到递归,循环,异常,多层嵌套等领域依旧有可能引发内存泄露,不过即使如此智能指针依旧帮你管理了大多数的问题
更多智能指针的使用需要你自行了解
垃圾代码
int buf[3][3][3]{
{{1, 2, 3}, {10, 20, 30}, {100, 200, 300}},
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
{{7, 8, 9}, {70, 80, 90}, {700, 800, 900}},
};
int *pl1 = &buf[0][0][0];
int (*pl2)[3] = &buf[0][0];
int (*pl3)[3][3] = &buf[0];
// 垃圾代码
(pl1 = *((pl2 = *(++pl3)) += 2))++;
/*
代码分析
数据范围
{{1, 2, 3}, {10, 20, 30}, {100, 200, 300}},
^
pl1
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
{{7, 8, 9}, {70, 80, 90}, {700, 800, 900}},
执行: ++pl3
等价: pl3 += 1
数据范围
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
^
pl1
执行: (pl2 = *(++pl3)) += 2
等价: pl2 += 2
数据范围
{{4, 5, 6}, {40, 50, 60}, {400, 500, 600}},
^
pl1
执行: (pl1 = *((pl2 = *(++pl3)) += 2))++
等价: pl1 += 1
数据范围
{400, 500, 600}
^
pl1
*/你能分析出 (pl1 = *((pl2 = *(++pl3)) += 2))++; 这一行代码 pl1 的最终指向吗
我喜欢称呼这种代码为垃圾代码,因为这种代码实际上除了能复杂在一行代码上写完之外没有任何好处
这种垃圾代码非常的难以理解,不仅是新手看起来一脸懵逼,只要不是天天研究这种细枝末节的开发者都很难一下子知道这段代码到底在干嘛,而且这种垃圾代码往往都有更好的等效代码实现一样的功能
不使用垃圾代码是 编程规范 的重要一步
下面有一段等效代码,其实也可以看出等效代码虽然不是直观易懂,但是也是有步骤可循,不至于是无法推理的地步,这也可以看的出来垃圾代码的垃圾程度,因为就算正常写都不好理解的代码,一旦简化之后就会变得更加复杂而不好懂
这种垃圾代码总是出现在指针上,就是因为指针实际指向的是地址而不是具体数据,可定义的灵活性也是非常高,所以才能出现越来越离谱的操作,类似的垃圾代码在宏上也是如此
我的评价是这种垃圾代码不要看,不要浪费时间去分析这种没有意义的东西,如果你想知道是什么含义,应该丢给AI或者让编写的人来解释,上面的垃圾代码就附带来一段解释,不知道你是否能看懂
等效代码
// 垃圾代码
(pl1 = *((pl2 = *(++pl3)) += 2))++;
// 等效代码
pl3++;
pl2 = pl3[0];
pl2 += 2;
pl1 = pl2[0];
pl1++;
// 等效代码,直接定位到 [2-1][3-1][1]
pl1 += 3 * (2 + 3) + 1;项目路径
https://github.com/HellowAmy/mcpp.git