
大家好,我是 Ai 学习的老章
前文介绍了:DeepSeek-OCR 2 来了,让 AI 也能像人一样,带着逻辑去看图
之前 DeepSeek-OCR、HunyuanOCR、PaddleOCR 扎堆开源的时候,我已经把环境搞的很好了
# DeepSeek-OCR 本地部署(上):CUDA 升级 12.9,vLLM 升级至最新稳定版
# DeepSeek-OCR 本地部署(下):vLLM 离线推理,API 重写,支持本地图片、PDF 解析
没想到遇到 DeepSeek-OCR 2 还是栽了跟头 😓
部署这玩意太费劲了,主要是 vLLM 还没有支持,用 transfomers 还有一大堆依赖,还依赖底层 gcc,然后还有更底层的 GLIBC,这些底层环境不敢乱动,升级来也非常麻烦,gcc 升级,我找到了用 conda 新建环境的方式,但是 GLIBC 就没招了,最后还是老老实实选择了本地编译,耗时,但最后成功了。
详细介绍过程之前,先看几个大家关心的问题
1、部署需要 8.5GB 显存
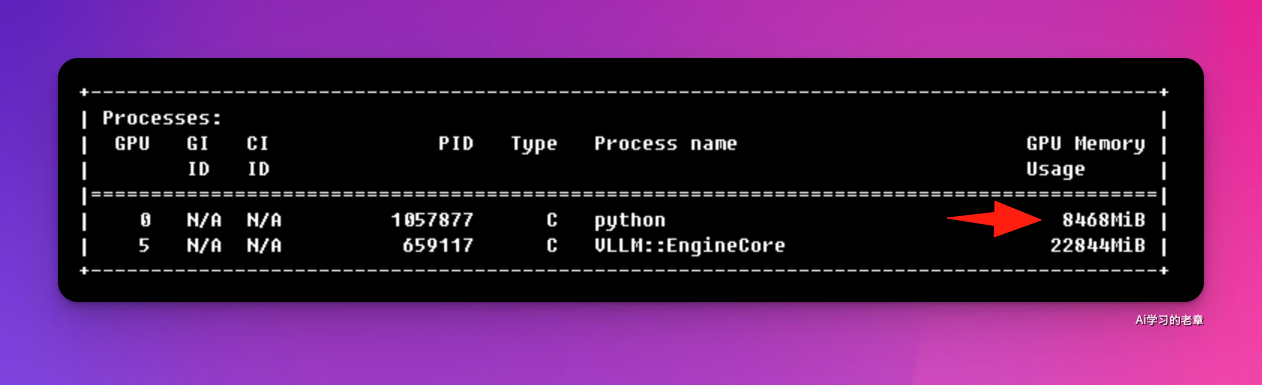
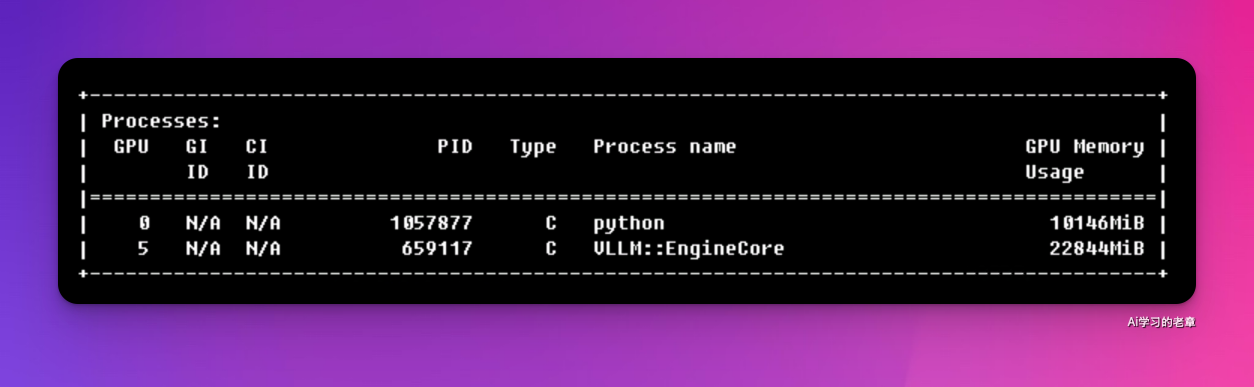
运行 OCR 任务,显存占用来到 10Gb
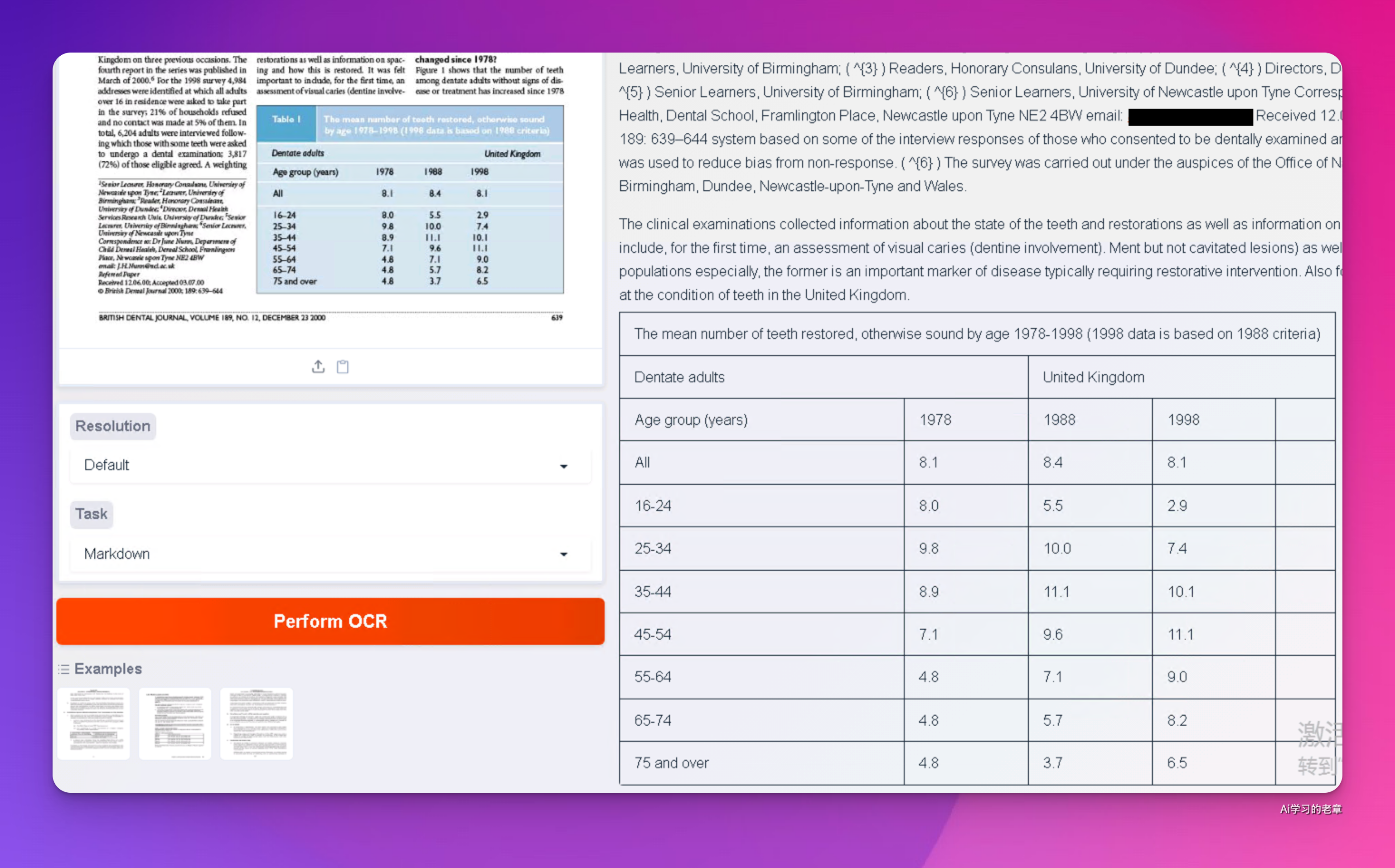
2、准确性,我觉得还不错,下面这个测试配图是我最常用的用例
尤其是右下角的表格,无线、表头嵌套,合并单元格、背景色各种干扰
有点难度,PaddleOCR 处理起来也瑕疵:吴恩达最新公开课《文档 AI》,PaddleOCR 实战,笔记
3、耗时 20 秒+,难道是我 4090 显卡不给力吗?我也测试了线上,挺快的,不过线上那个貌似运行在 H200,不知道 vLLM 支持后会不会好一些。
在线体验
再劝大家一下,尽量别折腾本地部署了,推荐俩在线体验:
1, https://deepseek-ocr-v2-demo.vercel.app/
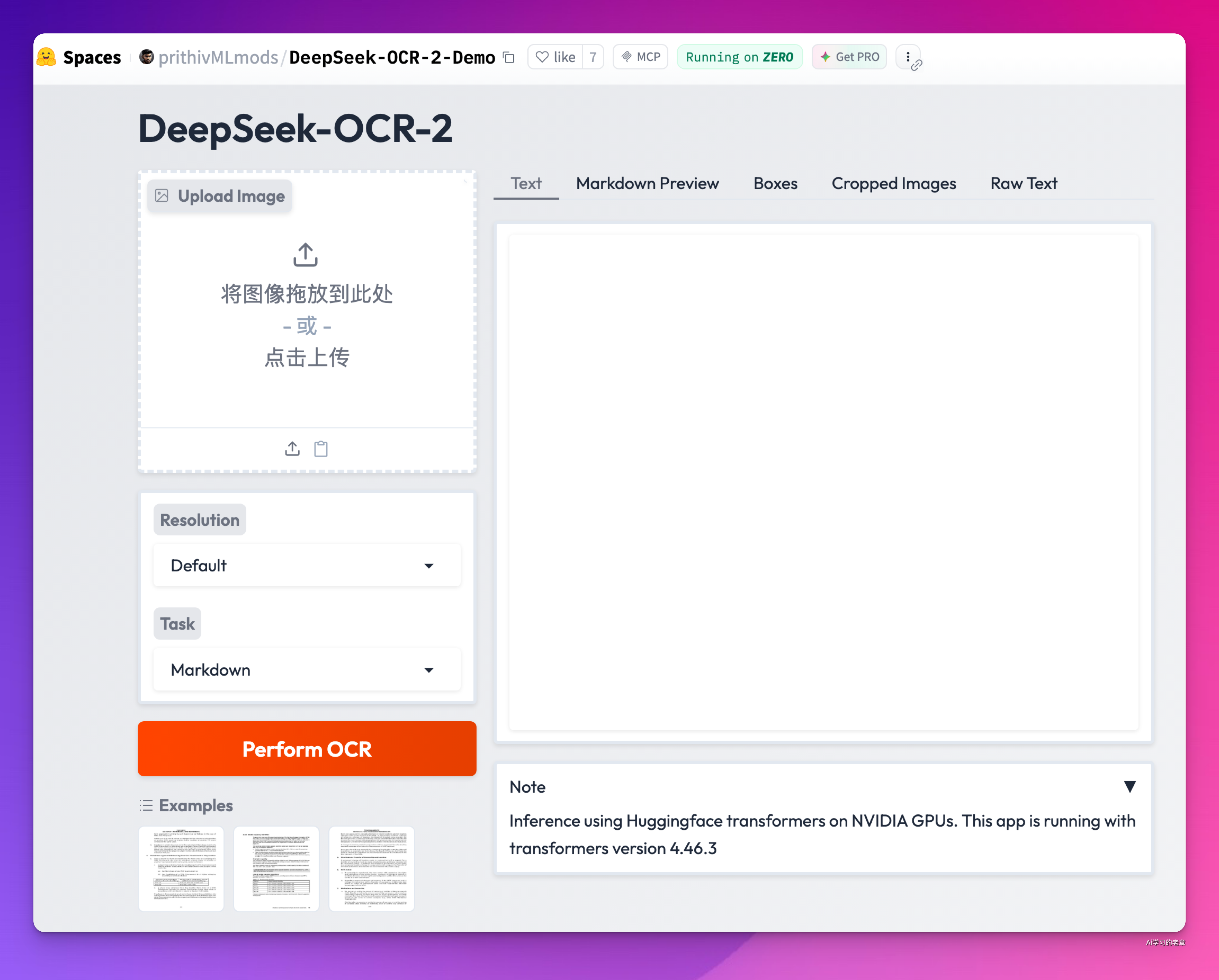
2, https://huggingface.co/spaces/prithivMLmods/DeepSeek-OCR-2-Demo
不听劝请继续--本地部署
我看了几个教程
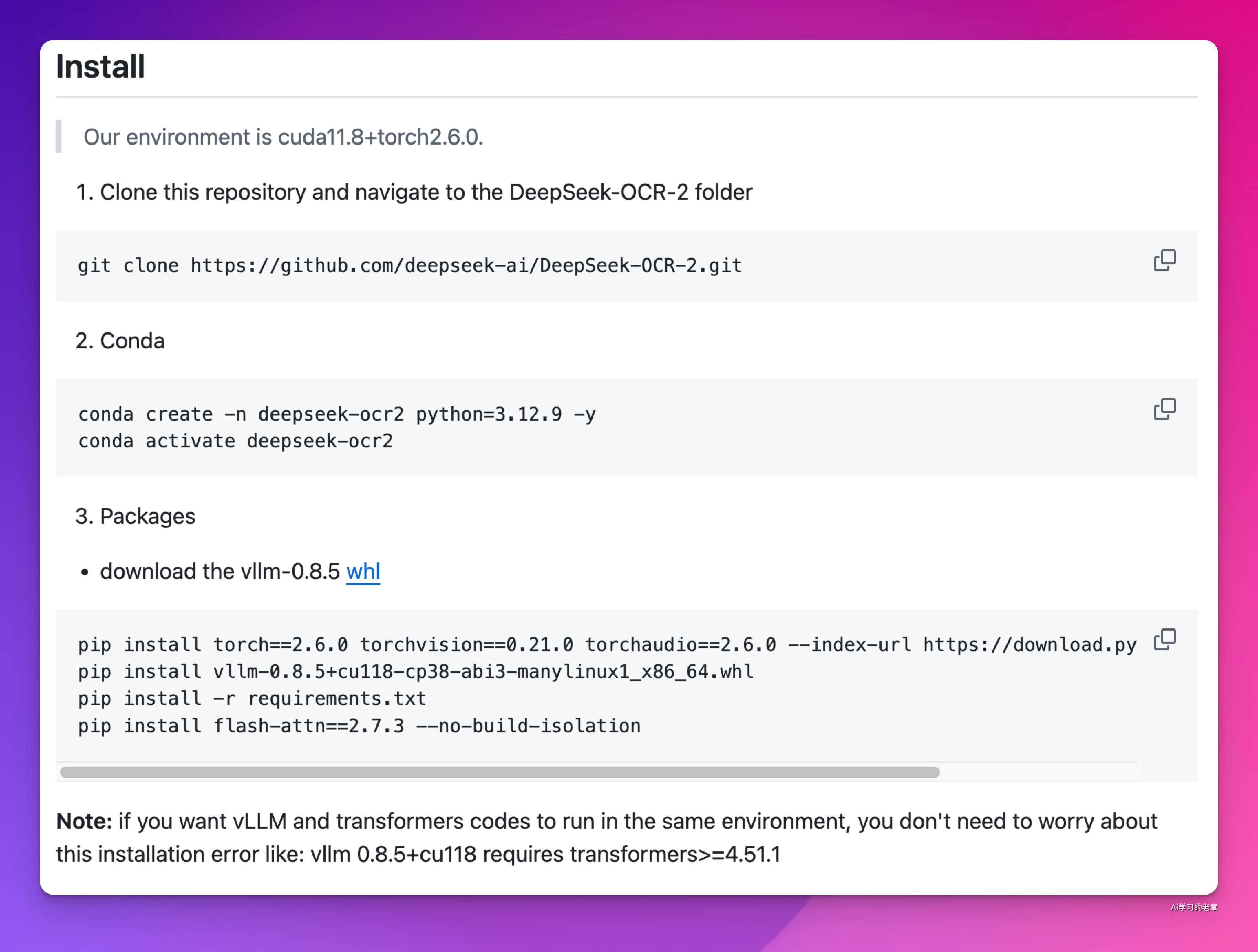
1、deepseek-ai 官方文档
https://github.com/deepseek-ai/DeepSeek-OCR-2/tree/main
完全照着操作不出幺蛾子应该没问题,毕竟官方验证过,我遇到的幺蛾子就是 gcc 版本低,我用 conda 升到了 11x,然后中间去看了别的教程
安装:
推理

2, Unsloth "DeepSeek-OCR 2: How to Run & Fine-tune Guide"
原文:https://unsloth.ai/docs/models/deepseek-ocr-2
介绍了 nightly 版本 vllm 拉起 DeepSeek-OCR 2 的方法以及微调教程,
微调部分有现成的 ipynb,让其具备阿拉伯文识别能力:
https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Deepseek_OCR_2_(3B).ipynb
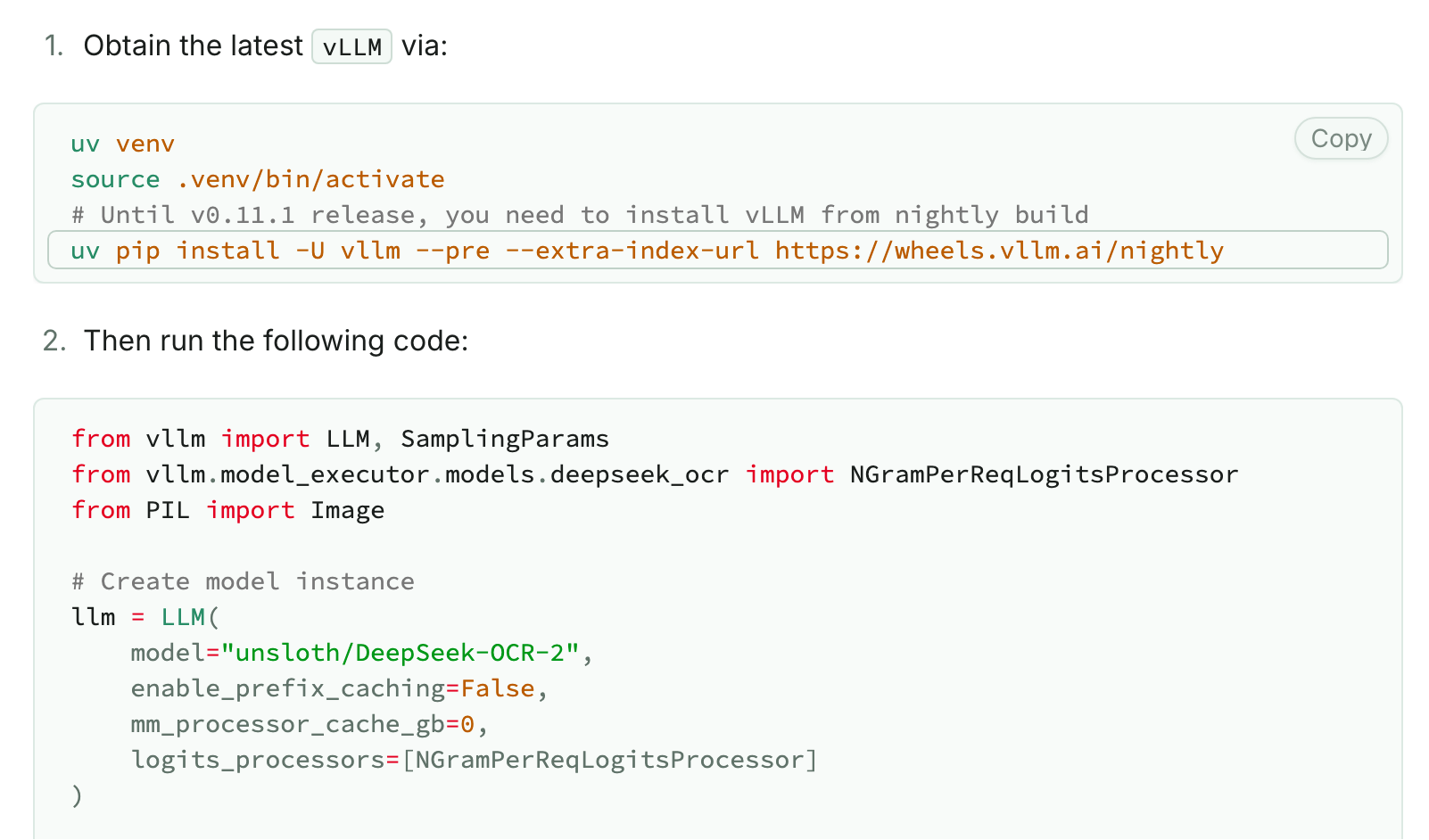
这个我没跑起来,可能是因为 unsloth 提供的模型是修改过的(为了与最新的 transformers 兼容),但是我是从 deepseek-ai/DeepSeek-OCR-2 官方下载的模型文件,后面没再尝试。
3, https://huggingface.co/spaces/prithivMLmods/DeepSeek-OCR-2-Demo
最后我走了这个,其实核心还是官方文档哪些步骤,只是加了 gradio 前端
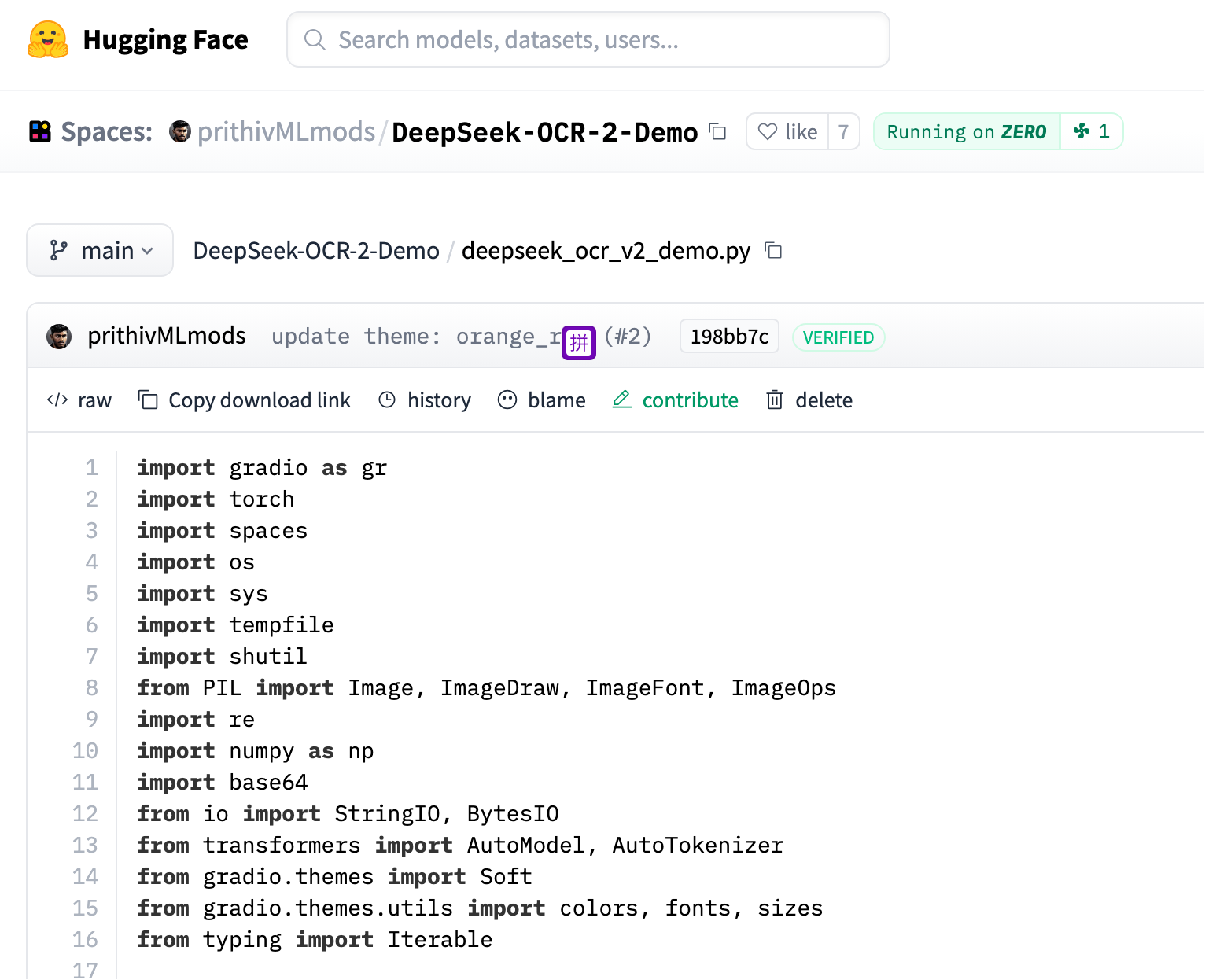
其中最麻烦的是 requirements.txt 里面依赖的安装,特别是 flash-attn 这个大魔王
直接安装 whl 会遇到 gcc 版本低,GLIBC 版本低问题
前者解决方案是用 conda 创建带 gcc 11 的环境,方法如下
后者解决方案是听 deepseek 官方的,老老实实:pip install flash-attn==2.7.3 --no-build-isolation
flash-attn、requirements.txt安装没问题
运行:python deepseek_ocr_2_demo.py --server 0.0.0.0:7860即可
附赠 conda 创建 GCC 11 环境
- 创建带 GCC 11 的环境
bash
# 创建一个带 gcc 11 的环境
conda create -n gcc11_env -c conda-forge gcc_linux-64=11 gxx_linux-64=11
# 激活环境
conda activate gcc9_env
# 验证
x86_64-conda-linux-gnu-gcc --version小知识 :Conda 的编译器名字通常较长(
x86_64-conda-linux-gnu-gcc),这是为了和系统的 GCC 区分开,避免冲突。
让 gcc 命令直接可用
你可能发现一个问题:直接输入 gcc --version 还是调用的系统旧版本。
这是因为 Conda 为了防止冲突,给编译器加了很长的前缀。要让 gcc 命令直接可用,我们用软链接把那个长名字"伪装"成短名字。
1. 建立软链接
在当前的 (gcc9_env) 环境下执行:
bash
ln -sf $CONDA_PREFIX/bin/x86_64-conda-linux-gnu-gcc $CONDA_PREFIX/bin/gcc
ln -sf $CONDA_PREFIX/bin/x86_64-conda-linux-gnu-g++ $CONDA_PREFIX/bin/g++这会在你当前的 Conda 环境里创建一个名为 gcc 的快捷方式。
2. 验证
现在再检查版本:
bash
gcc --version3. (可选) 设置环境变量
有些编译脚本(如 pip install)不直接调用 gcc,而是读取环境变量 CC 和 CXX。为了保险,建议执行:
bash
export CC=x86_64-conda-linux-gnu-gcc
export CXX=x86_64-conda-linux-gnu-g++如果你想让这个设置永久生效,可以把这两行加到 ~/.bashrc 里。