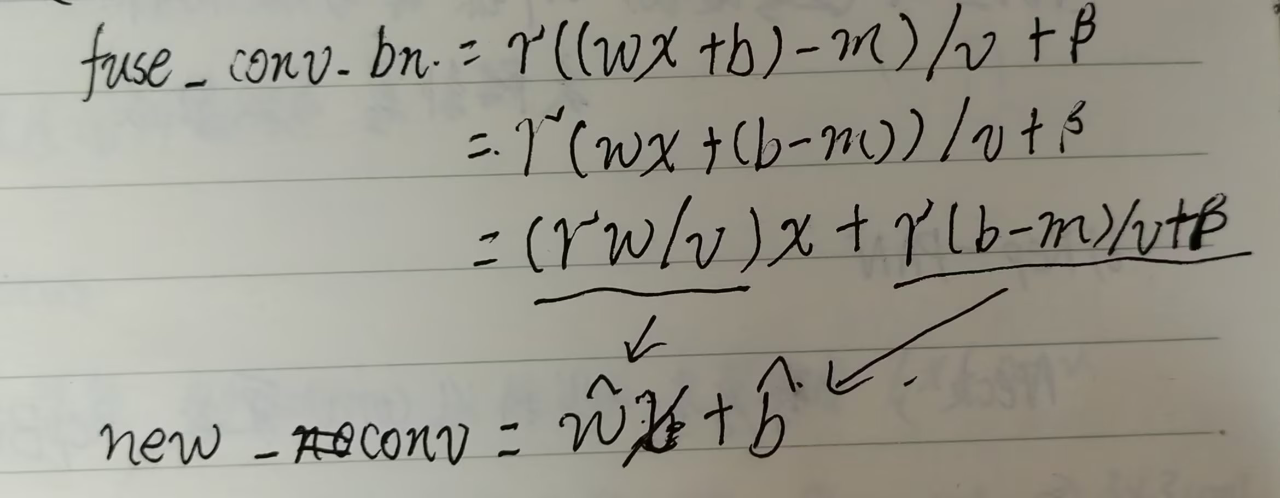仅提供创新说明,不提供细节
文章目录
- [MobileNet 系列](#MobileNet 系列)
-
- [MobileNet V1](#MobileNet V1)
- [MobileNet V2](#MobileNet V2)
- [MobileNet V3](#MobileNet V3)
- [ShuffleNet 系列](#ShuffleNet 系列)
-
- [ShuffleNet V1](#ShuffleNet V1)
- [ShuffleNet V2](#ShuffleNet V2)
- GhostNet
- [EfficientNet 系列](#EfficientNet 系列)
-
- [EfficientNet - 训练极慢(因为深且大)](#EfficientNet - 训练极慢(因为深且大))
- EfficientNetV2
- RepVGG
MobileNet 系列
MobileNet V1
-
核心贡献:"深度可分离卷积" 作为轻量化网络的基础算子。
-
传统卷积计算量大
-
深度可分离卷积:先对输入通道独立 K × K K×K K×K 卷积;再 1×1 逐点卷积
-
计算量对比
text深度可分离卷积计算量 = K×K×C_in×H×W + C_in×C_out×H×W 标准卷积计算量 = K×K×C_in×C_out×H×W 节省比例 ≈ 1/C_out + 1/(K×K)当K=3, C_out=256时,理论计算量减少约8-9倍!
-
-
网络结构
- 几乎全部由深度可分离卷积块堆叠而成。
- 每个块:深度卷积 → BN → ReLU → 逐点卷积 → BN → ReLU
- 引入两个超参数:
- 宽度乘子α:等比例缩减每层通道数(0.25, 0.5, 0.75, 1.0)
- 分辨率乘子ρ:降低输入图像分辨率
-
局限性
- 深度卷积计算密度低:尤其是在早期层,特征图大但通道数少时,硬件利用率低。
- ReLU激活函数导致信息丢失:在低维特征中使用ReLU会造成不可逆的信息损失。
MobileNet V2
-
倒残差结构
-
传统残差:先降维,再卷积,最后升维
-
倒残差快:先升维,再卷积,最后降维
输入 → 1x1卷积升维 → ReLU6 → 深度卷积 → ReLU6 → 1x1卷积降维面试:"为什么V2的倒残差结构有效?"
回答:"本质上是信息瓶颈理论的体现。先在高维空间进行特征变换(深度卷积),可以避免信息损失;最后在低维空间保持线性,避免ReLU的破坏。这类似'编码-处理-解码'的过程,中间的处理阶段在高维进行更有效。"
-
-
线性瓶颈
-
关键:在低维空间中使用ReLU会造成严重的信息丢失。
-
方案:在降维的1x1卷积后不使用非线性激活(保持线性)。
text最后一个1x1卷积后:不加ReLU! 这保留了更多的信息流回残差连接。
-
-
ReLU6
使用ReLU6(max(0, min(x, 6)))替代ReLU。
目的:在低精度计算时(如float16)保持数值稳定性,同时引入一个上限。
-
完整的MobileNetV2块
bash输入 (低维) ↓ 1x1卷积升维 → ReLU6 (扩张,通常6倍) ↓ 3x3深度卷积 → ReLU6 ↓ 1x1卷积降维 → Linear (注意:无激活!) ↓ 残差连接(如果输入输出维度相同)
MobileNet V3
-
架构搜索方法
- 组合搜索:同时搜索网络结构和每一层的配置(卷积类型、核大小、通道数等)。
- 平台感知搜索:直接在目标硬件(如手机CPU)上测量延迟,作为搜索的优化目标。
-
引入注意力机制:SE模块轻量化版: 倒残差块末尾加压缩-激励模块(通道缩减率从16降到4)。
-
重新设计激活函数
-
h-swish:近似于swish(x * sigmoid(x)),计算更友好。
texth-swish(x) = x * ReLU6(x+3) / 6
策略:只在深层使用h-swish(特征图小,计算量小),浅层仍用ReLU6。
-
-
重新设计网络头尾
- 头部(第一层)优化:
- V2:32 通道 3x3 标准卷积。
- V3:减少到 16 通道,并使用hard-swish激活。
- 尾部(最后部分)优化:
- 移除V2中昂贵的最后一层1x1卷积。引入新的高效特征提取模块。
- 头部(第一层)优化:
-
V3的Block结构(结合了所有优化)
输入 ↓ 1x1卷积升维 → h-swish/ReLU6 ↓ 深度卷积 → h-swish/ReLU6 ↓ SE注意力(轻量版) ↓ 1x1卷积降维 → Linear ↓ 残差连接
问:"V3的NAS具体怎么做的?"
答:"使用了平台感知NAS:1)用MnasNet方法在ImageNet上搜索基础架构;2)在此基础上手动优化头尾层和激活函数;3)关键是在搜索时直接以手机CPU的实际延迟作为奖励函数,而不是只优化FLOPs。"
ShuffleNet 系列
ShuffleNet V1
-
核心创新点:解决"分组卷积"的副作用
- 问题:分组卷积,不同组之间的特征信息无法交流
- 方案:给出 "通道混洗" 操作;在通道维度上"重组"。
-
ShuffleNet V1基本单元:
text输入 → 1x1分组卷积 → 通道混洗 → 3x3深度可分离卷积 → 1x1分组卷积 → 与捷径连接相加 -
不足:由于FLOPs没有考虑内存访问成本和并行度,实际在硬件(如手机CPU)上的速度并不总是和FLOPs成比例。
ShuffleNet V2
- 四大设计准则(G1-G4)
G1: 输入输出通道数相同时,内存访问成本最低
G2: 过度的分组卷积,会增加MAC。
G3: 过度的网络碎片化:GoogleNet、Inception等网络有很多"支路"(多路径结构)
G4: 减少逐元素操作:ReLU、Add、AddBias等逐元素操作,内存访问量很大。 - 两种基本单元:
-
下采样单元(空间尺寸减半,通道数加倍)
输入 │ ├───────────────┐ ↓ │ Split(通道切分两半) │ │ │ ├→ 分支1:恒等映射 → Concat(与分支2输出合并) │ │ └→ 分支2: │ 3x3 DWConv(步长2)│ 1x1 Conv │ → 通道混洗 ←───────┘用一个通道分割代替了V1中的通道相加,符合G4(减少逐元素Add操作)。
-
常规单元(空间尺寸和通道数不变)
输入 │ ├───────────────┐ ↓ │ 通道混洗 │ │ │ ├→ 分支1:恒等映射 → 通道混洗 → Add │ │ └→ 分支2: │ 1x1 Conv │ 3x3 DWConv │ 1x1 Conv │ → 通道混洗 ←───────┘采用"分割-处理-拼接"的结构,避免Add操作,符合G4。
-
GhostNet
-
核心洞察:特征图的冗余性
- 在标准卷积层输出的特征图中,存在大量相似或冗余的特征图对。
- 比如:一些边缘特征图可能只是另一些的简单变换(平移、旋转、缩放等)。
-
核心组件:Ghost模块
- 步骤一:生成"内在特征":用少量的常规卷积(比如原来要10个卷积核,现在只用5个),生成一部分特征图。这些叫内在特征。
- 步骤二:生成"幻影特征":对第一步生成的每个内在特征图,施加一系列廉价的线性操作(比如3x3深度卷积、小尺度池化等),来生成更多的特征图。
-
Ghost模块的优势
参数量和计算量大幅下降:假设原来需要 n 个k×k卷积核,Ghost模块只需要 m 个k×k核 + m*(s-1) 个d×d深度卷积核(d很小,比如3)。当n很大时,节省非常可观。
-
构建GhostNet网络
主干:借鉴了MobileNetV3的反向残差结构 和SE注意力模块(轻量版的通道注意力)。
整体架构:
Stem层(标准卷积)→ 一堆Ghost Bottleneck堆叠 → 全局池化 → 全连接层EfficientNet 系列
EfficientNet - 训练极慢(因为深且大)
核心:不再凭直觉放大网络,而是用一个科学的复合缩放系数,同时缩放深度、宽度和分辨率,实现模型大小与精度的最优权衡。
-
复合缩放公式
深度、宽度、分辨率之间需要平衡缩放,才能达到最优效果。
深度系数:d = α^φ 宽度系数:w = β^φ 分辨率系数:r = γ^φ 约束条件:α · β² · γ² ≈ 2 (其中 α, β, γ 是通过小规模搜索确定的常数,φ 是用户控制的全局缩放系数)公式意义
-
φ 是"计算量预算"的系数。φ 越大,模型整体越大。
通过小实验确定了最优的 α、β、γ 后,可以通过统一的 φ 来获得一系列模型(B0-B7)。
- 例如:如果想把计算量翻倍(2倍),那么深度增加α倍,宽度增加β倍,分辨率增加γ倍,三者联动,且满足 α·β²·γ²≈2。
-
为什么约束是 α·β²·γ²≈2?
因为计算量(FLOPs)约等于:深度d × 宽度w² × 分辨率r²。所以当d、w、r按公式缩放时,FLOPs大约增加 (α·β²·γ²)^φ 倍。让这个基数约等于2,意味着φ每增加1,计算量翻倍。
-
-
"种子模型":EfficientNet-B0:
强化版本的 MobileNetV3 ?采用了神经架构搜索来获得一个最优的小网络。
- 借鉴了 MobileNetV2 的 MBConv(倒残差瓶颈模块),并加入了:
- Squeeze-and-Excitation(SE)注意力模块:放在每个MBConv中,增强通道特征。
- 更激进的深度可分离卷积。
- 使用Swish(x * sigmoid(x))。
- 借鉴了 MobileNetV2 的 MBConv(倒残差瓶颈模块),并加入了:
EfficientNetV2
-
引入新的 MBConv 变体和 Fused-MBConv
-
发现问题:V1的MBConv(深度可分离卷积+SE)在小模型上效率不高,因为深度卷积在早期层计算密度低。
-
解决方案:在早期浅层使用 Fused-MBConv(将深度可分离卷积替换为标准 3x3 卷积),提高计算效率。在深层保留高效的MBConv。
-
-
渐进式训练(Progressive Learning)
核心思想:训练时动态调整图像大小和正则化强度。
- 方法:训练初期用小图像、弱正则化(如Dropout率低),让模型快速学习简单模式;训练后期逐渐增大图像尺寸和正则化强度,让模型适应更精细的特征。
- 好处:大幅缩短训练时间(可达4-7倍)。
-
改进的复合缩放
- V2针对性地对不同阶段的深度/宽度进行非均匀缩放。
- 更倾向于增加深度而非宽度(因为现代加速器对深度更友好)。
| 系列 | 核心算子 | 设计哲学 | 适用场景 |
|---|---|---|---|
| MobileNet | 深度可分离卷积 | "拆解卷积"的数学优化 | 通用移动端任务 |
| ShuffleNet | 分组卷积+通道混洗 | 硬件友好的通道操作 | 需要极致速度的CPU部署 |
| GhostNet | 常规+深度卷积组合 | 特征冗余利用 | 理论计算压缩比优先 |
| EfficientNet | MBConv(基于MobileNetV2) | 系统化复合缩放 | 云端/服务器端最佳精度 |
RepVGG
训练时用多分支的复杂网络获得高精度,推理时通过结构重参数化合并为单路的极简VGG式网络
-
为啥要"返璞归真"?
在 RepVGG 出现前,主流网络设计似乎陷入了"复杂化竞赛":
网络类型 结构特点 优点 缺点 VGG 纯3x3卷积堆叠 简单、快、内存连续 精度不够高 ResNet 残差连接 解决梯度消失、精度高 多分支、内存不连续 Inception 多路径并行 多尺度特征 极其复杂 DenseNet 密集连接 特征重用 内存消耗大 -
核心思想:结构重参数化
结构重参数化 = 训练一个结构,推理时转换为另一个结构。
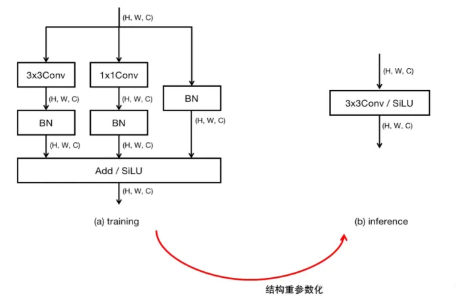
RepVGG的具体做法:
text训练时: 3x3卷积 + 1x1卷积 + 恒等连接(三分支) ↓↓↓ 推理时: 单个3x3卷积(单路)训练阶段的结构(RepVGG Block)
text输入 ├── 分支1:3x3卷积 → BN ├── 分支2:1x1卷积 → BN └── 分支3:恒等连接 → BN(如果输入输出通道数相同) ↓ 三个分支相加 ↓ ReLU激活bash为啥训练时用三分支?(网上说的) 3x3卷积:主体特征提取 1x1卷积:增强非线性(等价于先降维再升维) 恒等连接:提供残差学习,缓解梯度消失 这三个分支共同作用,让网络更容易训练、收敛到更优点。推理阶段的结构(合并后)
text输入 → 单个3x3卷积 → ReLU → 输出- 单个3x3卷积: 是将训练的三个分支合并为单个分支,并非简单保留单个3x3卷积分支
简洁得像VGG!但性能远超VGG。
-
如何合并?(数学推导)
两个关键操作:
: 任何"卷积 → BN"都可以合并为一个带偏置的卷积。
```text 设卷积参数:权重W,偏置b(初始通常为0) BN参数:缩放γ,平移β,均值μ,方差σ² 合并后: 新权重 W' = γ/σ * W 新偏置 b' = γ/σ * (b - μ) + β ```: 三个分支的卷积+BN合并后,可以得到三个独立的卷积核 W₁, b₁(3x3)、W₂, b₂(1x1)、W₃, b₃(恒等)。
: 关键步骤:
* 1、将1x1卷积用零填充为3x3 * 2、将恒等连接视为1x1单位矩阵卷积,同样填充为3x3 * 3、三个3x3卷积逐元素相加: ``` W_final = W₁ + pad(W₂) + pad(W₃) b_final = b₁ + b₂ + b₃ ``` * 4、最终得到单个3x3卷积,其效果完全等价于三个分支的和: 合并过程:
text训练时: 输出 = ReLU( BN(Conv3x3(x)) + BN(Conv1x1(x)) + BN(Identity(x)) ) 推理时(合并后): 输出 = ReLU( Conv3x3_final(x) ) # 数学等价!