1. 摘要
提出问题:
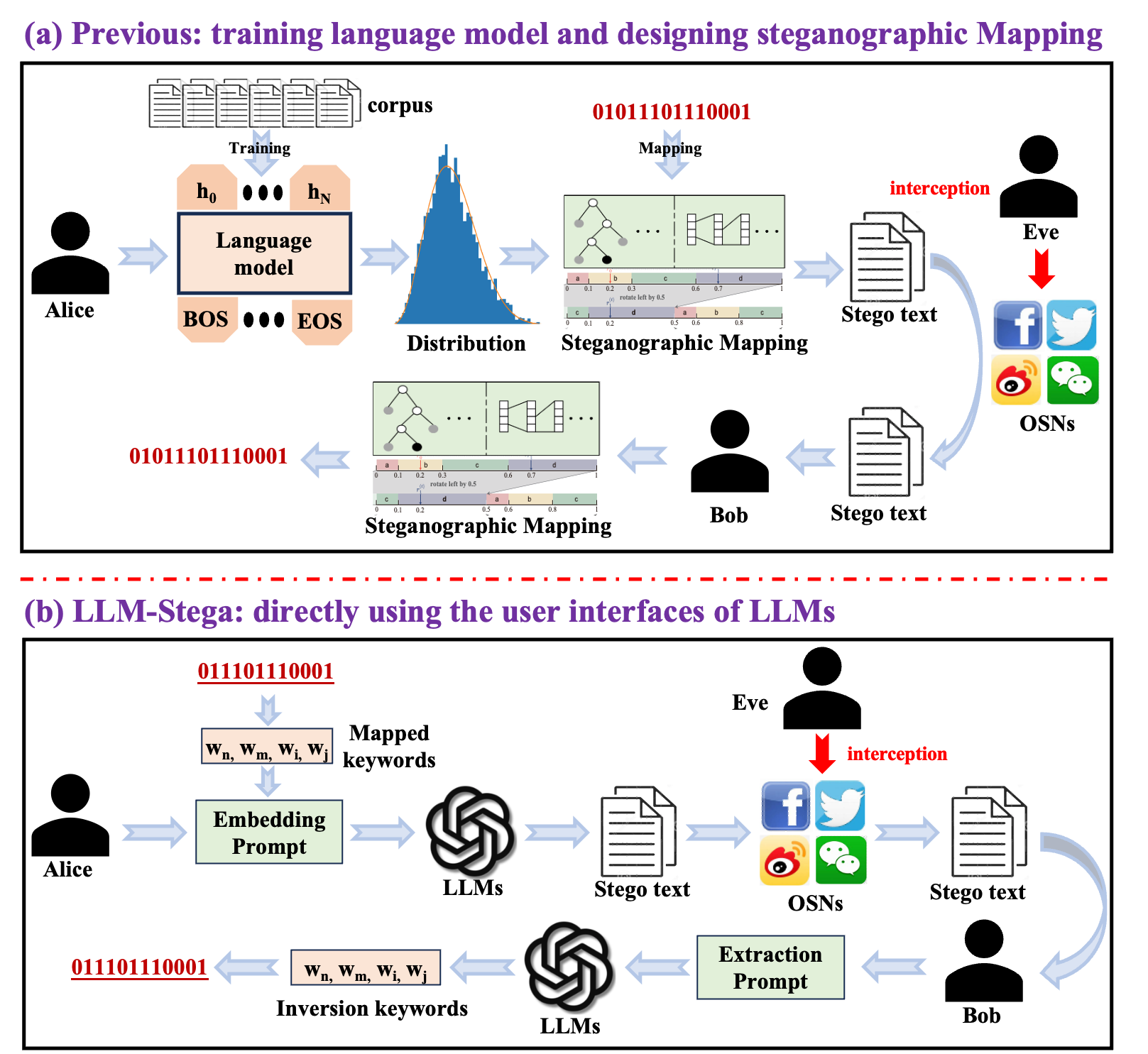
现有生成式文本隐写大多是"白盒范式":需要共享语言模型、训练词表以及逐步采样概率分布,才能建立"比特↔词/概率"的隐写映射。但在大模型(LLM)实际使用中,用户通常只能通过黑盒 API / UI 访问,拿不到词表与采样概率;同时,传统映射往往会扰动原始采样分布,带来安全风险与可检测性问题。
解决问题:
论文提出 LLM-Stega :一种直接基于 LLM 用户界面(UI) 的黑盒生成式文本隐写方法。核心做法是:构造并优化"关键词集合",设计加密的隐写映射 把秘密比特映射到关键词索引;再通过拒绝采样(reject sampling)+ 反馈式提示词优化,保证关键词可被准确抽取,同时保持生成文本语义丰富、自然流畅。
2. 论文方法
LLM-Stega 的整体流程由4部分组成:关键词集构建 → 加密隐写映射 → 隐写文本生成(提示词驱动)→ 秘密提取(提示词驱动)。
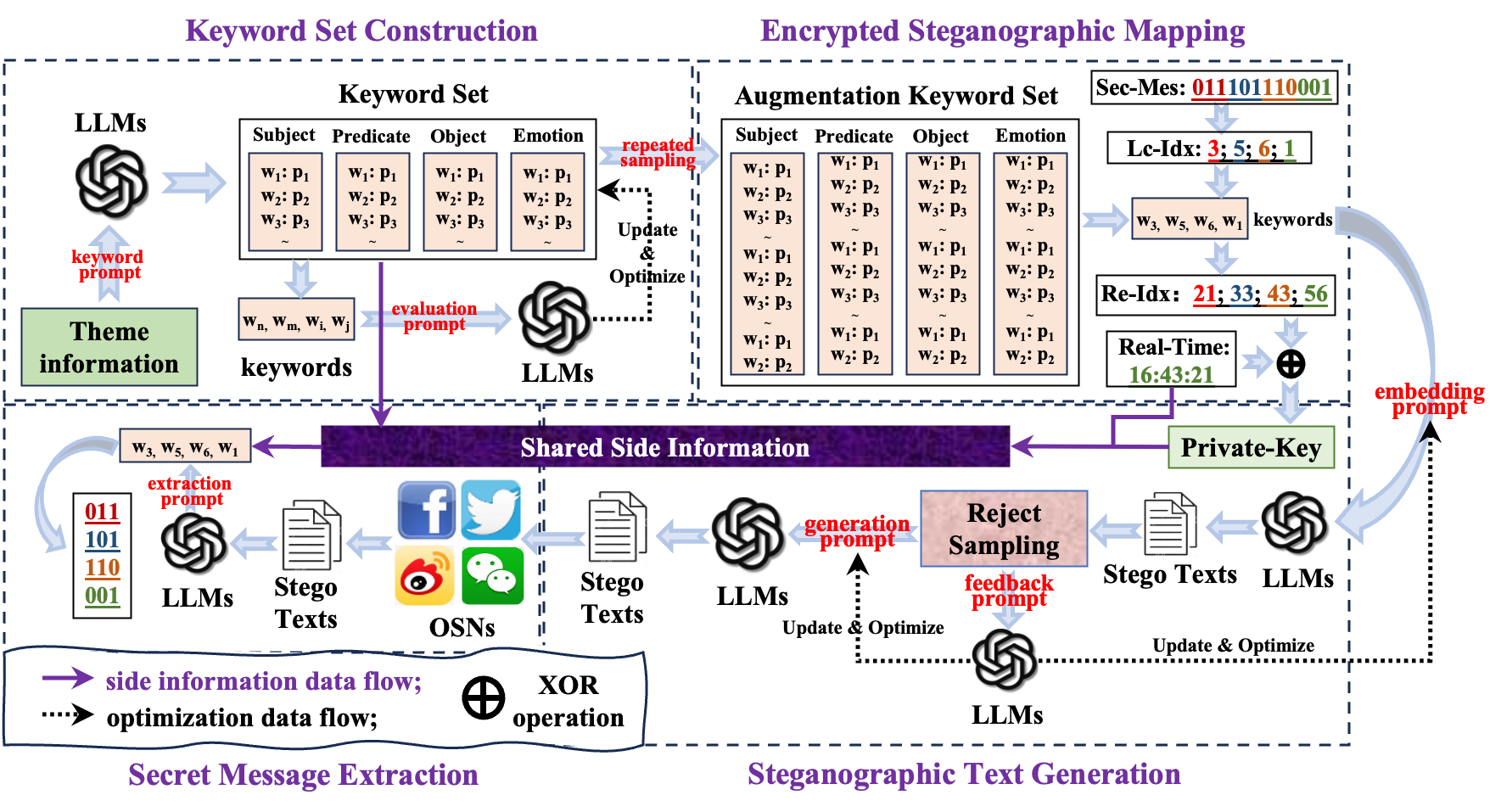
1.关键词集构建(Keyword Set Construction)
- 在黑盒条件下无法访问 LLM 的词表/概率,因此作者改为构建一个可控的"关键词集合"来承载秘密信息。
- 每句文本选择 4 类关键词:subject / predicate / object / emotion。其中 emotion 子集给出 3 类情感词;其他子集各给出 16 个高概率词及其概率。
- 为避免随机组合导致逻辑混乱、语义模糊,作者用 LLM 通过"评估提示词"对关键词组合进行打分/筛选,并据此优化关键词的采样概率,让后续生成更自然。
2.加密隐写映射(Encrypted Steganographic Mapping)
- 直接用有限关键词编码会导致容量与安全性不足,因此先按优化后的概率进行重复采样扩增 ,形成"扩增关键词集",再用关键词在扩增集中的位置索引来编码秘密比特。
- 论文给出一个容量配置:subject/predicate/object 从 16 扩到 2 18 2^{18} 218;emotion 从 3 扩到 2 10 2^{10} 210,合计可编码 3 × 18 + 10 = 64 3\times18+10=64 3×18+10=64 bits(每句)。
- 为防止固定索引暴露,作者引入 One-Time Password 思路:用"关键词重复次数"和"发布时间(日期/时/分)"的二进制做 XOR 得到私钥,从而提升对手截获映射表后的破解难度。
3.隐写文本生成与秘密提取(UI 级提示词 + 拒绝采样反馈优化)
- Alice 选出承载比特的关键词后,通过 embedding prompt 利用 LLM 生成包含这些关键词的 stego text。
- Bob 通过 extraction prompt 让 LLM 从 stego text 中"抽取关键词",再结合共享侧信息(关键词集、OTP 机制、发布时间等)解码出秘密。
- 难点在于:LLM 提取并非严格算法,可能抽错。为此提出基于 reject sampling 的反馈优化机制:若抽取关键词与目标不一致,则用 feedback prompt 让 LLM解释错误原因,并迭代优化 embedding / generation / extraction prompts,直到无误(算法1)。作者称实验里两次拒绝采样即可确保逐句的正确提取。

3. 实验结果
实验设置与对比方法
- 使用 GPT-4 的 UI 来实现黑盒隐写(两类主题:娱乐新闻、科幻电影影评)。
- 对比:Arithmetic Coding(不同 bpw 版本)、ADG、Discop;并额外实现 Discop+LLaMA2 来验证"仅换大模型但仍白盒映射"是否足够。
主要量化结果
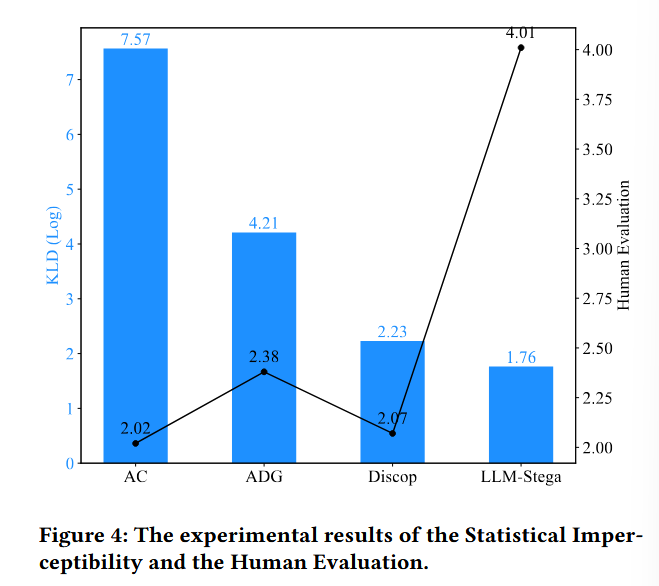
- 容量(Embedding Capacity):LLM-StegaEN 达到 5.93 bpw,LLM-StegaRSciM 为 4.81 bpw;在长度接近自然新闻句长的同时取得更高容量。
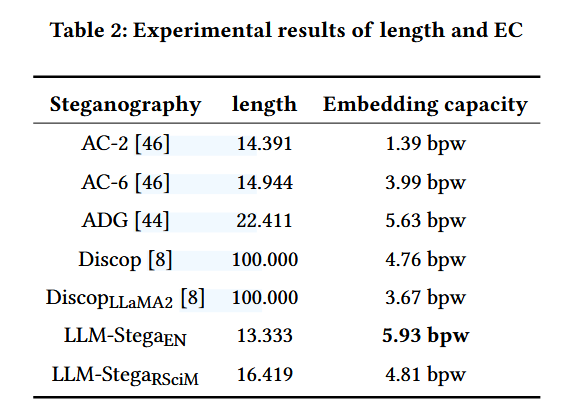
- 抗隐写分析(Anti-steganalysis):对 LS-CNN / BiLSTM-Dense / BERT-FT 三种分析器,LLM-Stega 的检测准确率接近 50%(如 51.55%、49.20%、50.00%),意味着更接近"随机猜测",隐蔽性更强。
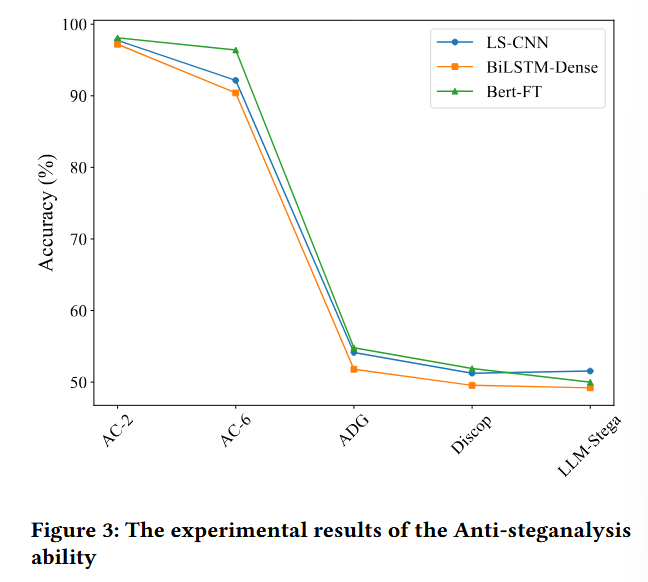
- 统计不可感知性(KLD)与人工评测:图4显示 LLM-Stega 的 KLD 更低、人工流畅/连贯/相关性评分更高(论文结论为整体优于对比方法)。
- 定性示例:表3给出的样例中,LLM-Stega 生成的句子更自然、语法正确且语义连贯;而一些传统方法会出现断裂、乱码或不连贯长段落。

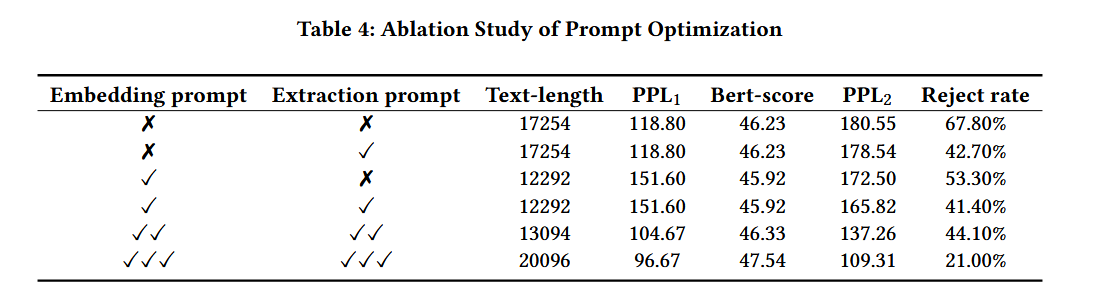
- 消融(提示词优化):Table 4显示从"初步→进一步→深度优化"的迭代后,拒绝率下降、文本质量提升,说明 reject sampling 驱动的提示词优化有效。
4. 前言
传统文本隐写从早期"同义词替换"等修改式方法发展到基于DNN的生成式方法,但现有生成式文本隐写方法普遍依赖白盒(white-box)条件(需要共享语言模型与概率分布),这与当下 LLM 的"高商用价值、黑盒访问为主"的现实矛盾。
因此提出一个新的研究问题:如何在仅能通过 LLM UI/API 的条件下实现安全、可用的生成式文本隐写。
5. 总结
LLM-Stega 的核心贡献可以概括为三点:
1.首次系统探索基于 LLM 用户界面(UI)的黑盒生成式文本隐写;
2.通过关键词集 + 扩增索引编码 + OTP/XOR 加密实现与 LLM 采样过程"解耦"的隐写映射,减少对原始生成分布的扰动;
3.用 reject sampling 的反馈式提示词优化在黑盒场景下兼顾"可准确提取"与"语义自然"。综合实验表明其在容量、安全性与文本质量上整体优于对比方法。